こちらは、ゆるWeb勉強会@札幌 Advent Calendar 2021 の 19日目の記事です。
テーマ
Amazon Neptuneからデータを取得し、
Amplifyで作成したサイトでグラフを表示するまでを試します。
※ハンズオンを終え、もう少し触ってみたい方向けです。細かい手順を省略しています。
- 任意のデータをAmazon Neptuneに保存
- AWS Amplifyで作成したサイトからNeptuneに接続、データ取得
- グラフ表示のライブラリはvis.jsベースのvis-network-react 1.3.6
背景
AWSさんのハンズオンで環境の構築~表示確認までは出来ました。
グラフデータの表示が面白かったので、表示したいグラフデータを少し変更して、表示出来るまでを試してみました。
ハンズオンはこちらです。
コードも用意されているので、流れをつかみたい方にお勧めです。
AWS亀田さんのNeptuneハンズオンです。
Amazon Neptune、AWS Lambda function、Amazon API Gateway、S3の環境を作成し、
S3に配置した静的コンテンツからNeptuneのデータを取得し、グラフデータを表示しています。
JavaScriptのライブラリは無し、グラフ表示のライブラリはvis.js 4.21です。
AWS AmplifyでAmazon Neptuneからデータを取得し表示するサンプルです。
JavaScriptのライブラリはReact、グラフ表示のライブラリはreact-vis-forceです。
グラフ表示ライブラリの設定
今回はvis.jsを使用します。
Reactで作成するため、以下を使用しました。
https://github.com/visjs/vis-network-react
グラフの表示イメージを確認出来るサイトです。
https://visjs.github.io/vis-network/examples/
vis-network-reactのインストール
npm i vis-network-react
ダミーデータの表示
グラフ表示用のコンポーネントに値を渡します。
<VisNetworkReactComponent style={graphStyle} data={data} />
渡すデータは、「ノード:nodes」、「エッジ:edges」という名前で渡します。
ノード(node):別名バーテックス、頂点。点や丸で表現されるエンティティー。「ラベル」を付けて種別を分類することが多い。
エッジ(edge):別名リレーションシップ、辺。ノード間の関係性を表す。方向とタイプを有する。
プロパティ(property):別名、属性。ノードとエッジにおける属性情報。データはkey/value形式で保持される。
import React, { useState, useEffect } from "react";
import { API } from "aws-amplify";
import * as queries from "../graphql/queries";
import VisNetworkReactComponent from "vis-network-react";
const TestPage = () =>{
// dummy vis-network-react
const defaultdata = {
nodes: [
{ id: "user1", label: "佐藤", group: "User" },
{ id: "user2", label: "鈴木", group: "User" },
{ id: "user3", label: "高橋", group: "User" },
{ id: "user4", label: "田中", group: "User" },
{ id: "user5", label: "渡辺", group: "User" },
{ id: "kwd1", label: "AWS", group: "KeyWord", color: "#f7f5db", shape: "box" },
{ id: "kwd2", label: "AWS勉強中", group: "KeyWord", color: "#f7f5db", shape: "box" },
{ id: "kwd3", label: "コンテナ好き", group: "KeyWord", color: "#f7f5db", shape: "box" },
{ id: "kwd4", label: "猫好き", group: "KeyWord", color: "#f7f5db", shape: "box" },
{ id: "kwd5", label: "犬好き", group: "KeyWord", color: "#f7f5db", shape: "box" },
],
edges: [
{ from: "user1", to: "kwd2" },
{ from: "user1", to: "kwd1" },
{ from: "user2", to: "kwd4" },
{ from: "user2", to: "kwd1" },
{ from: "user3", to: "kwd3" },
{ from: "user3", to: "kwd1" },
{ from: "user4", to: "kwd1" },
{ from: "user5", to: "kwd1" },
{ from: "user5", to: "kwd5" },
],
};
const graphStyle = {
width: '600px',
height: '600px',
};
const [data, setData] = useState(defaultdata);
return (
<>
<VisNetworkReactComponent
style={graphStyle}
data={data}
/>
</>
);
}
export default TestPage;
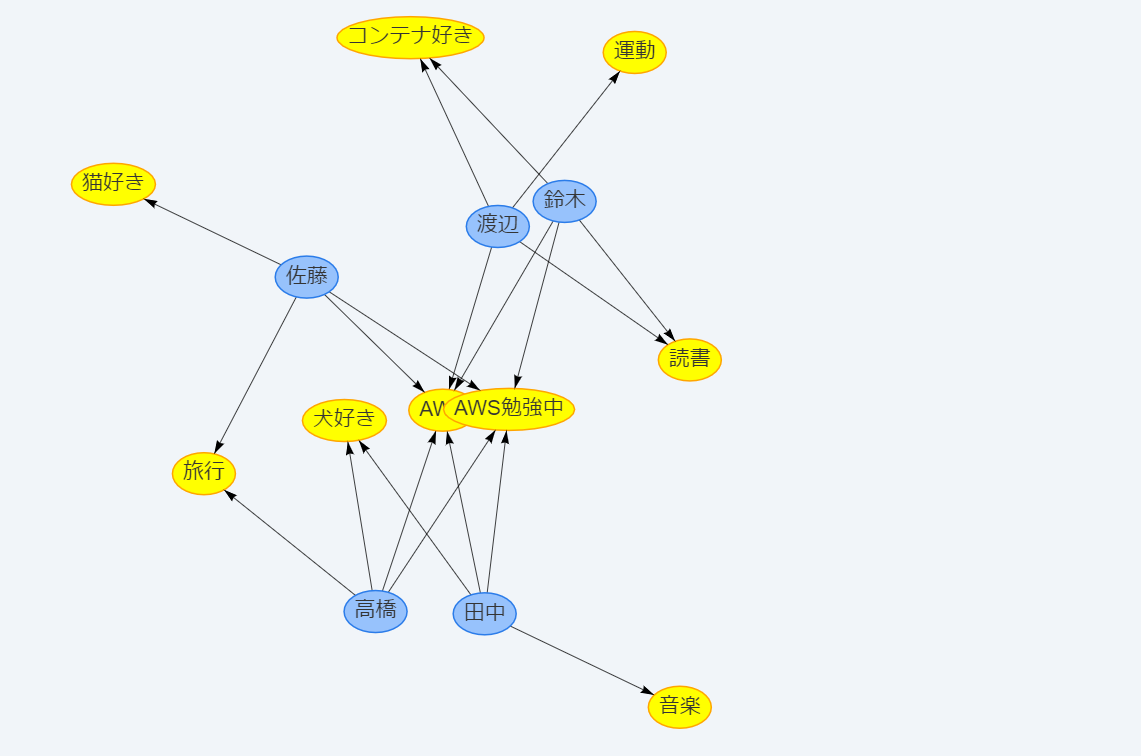
ダミーデータの表示イメージです。
グラフ表示の確認がとれたため、Neptune投入用のデータを作成していきます。
Neptune用グラフデータの作成
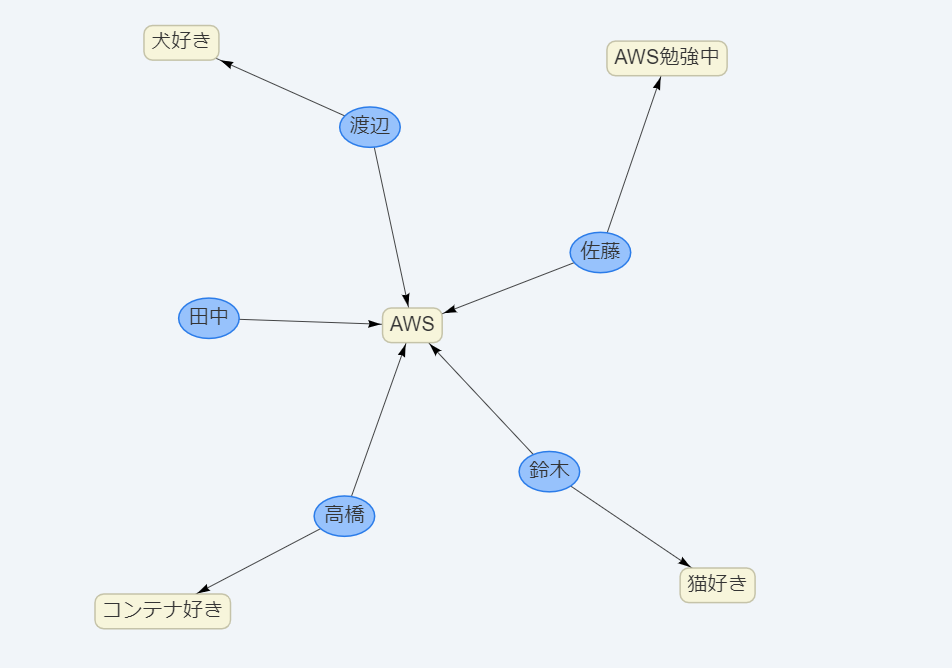
ユーザーと、そのユーザーが興味を持っているキーワードを可視化する想定で
データを作成します。
データ定義
ノード(Vertex)
| ノード名 | 説明 |
|---|---|
| User | ユーザー名 |
| KeyWord | キーワード名 |
エッジ(Edge)
| エッジ名 | Source(矢印の元) | Target(矢印の先) | 説明 |
|---|---|---|---|
| Selected | User | KeyWord | ユーザーが関心のあるキーワード |
ノード(User)のデータ
| 項目名 | データ型 | 説明 | 備考 |
|---|---|---|---|
| ~id | String | ID | 一意 |
| name | String | ユーザー名 | |
| ~label | String | ラベル名 |
ノード(KeyWord)のデータ
| 項目名 | データ型 | 説明 | 備考 |
|---|---|---|---|
| ~id | String | ID | 一意 |
| name | String | キーワード名 | |
| group | String | キーワードグループ | (未使用) |
| ~label | String | ラベル名 |
エッジ(Selected)のデータ
| 項目名 | データ型 | 説明 | 備考 |
|---|---|---|---|
| ~id | String | ID | 一意 |
| ~label | String | ノードのプロパティ(name) | |
| ~from | String | 接続元ノードのid | |
| ~to | String | 接続先ノードのid | |
| date | Date | 登録日付 | 自動入力 |
Neptune投入用のデータ作成
作成し、S3バケットに配置します。
AWS CLIコマンドを実行し、データのバルクロードを行います。
Userノードのサンプル
~id,name:String,~label
"usr1","佐藤",User
"usr2","鈴木",User
"usr3","高橋",User
"usr4","田中",User
"usr5","渡辺",User
Keywordノードのサンプル
~id,name:String,group:String,~label
"kw1","AWS","1",keyWord
"kw2","AWS勉強中","1",keyWord
"kw3","コンテナ好き","1",keyWord
"kw4","猫好き","2",keyWord
"kw5","犬好き","2",keyWord
"kw6","読書","2",keyWord
"kw7","旅行","2",keyWord
"kw8","音楽","2",keyWord
"kw9","運動","2",keyWord
エッジのサンプル
~id,~label,~from,~to,date:Date
1,Selected,"usr1","kw1",
2,Selected,"usr1","kw4",
3,Selected,"usr1","kw2",
4,Selected,"usr1","kw7",
5,Selected,"usr2","kw1",
6,Selected,"usr2","kw2",
7,Selected,"usr2","kw3",
8,Selected,"usr2","kw6",
9,Selected,"usr3","kw1",
10,Selected,"usr3","kw2",
11,Selected,"usr3","kw5",
12,Selected,"usr3","kw7",
13,Selected,"usr4","kw1",
14,Selected,"usr4","kw5",
15,Selected,"usr4","kw2",
16,Selected,"usr4","kw8",
17,Selected,"usr5","kw1",
18,Selected,"usr5","kw3",
19,Selected,"usr5","kw6",
20,Selected,"usr5","kw9",
Neptuneにデータ投入
以下のコマンドを、sourceのファイル名を書き換えて用意したcsvの回数分実行します。
AWS CLI例(AWS Cloud9などでNeptuneと同一VPC内から実行)
curl -X POST \
-H 'Content-Type: application/json' \
https://Neptuneのエンドポイント:8182/loader -d '
{
"source" : "s3://S3バケット名/読み込むcsvファイル名",
"format" : "csv",
"iamRoleArn" : "NeptuneクラスターにアタッチしたIAMロールのARN",
"region" : "リージョン名(東京はap-northeast-1)",
"failOnError" : "FALSE",
"parallelism" : "MEDIUM",
"updateSingleCardinalityProperties" : "FALSE",
"queueRequest" : "TRUE"
}
'
Neptune Notebooksでデータの投入状況を確認
ハンズオンで使用したノートブックからクエリを実行し、
データの投入状況を確認します。
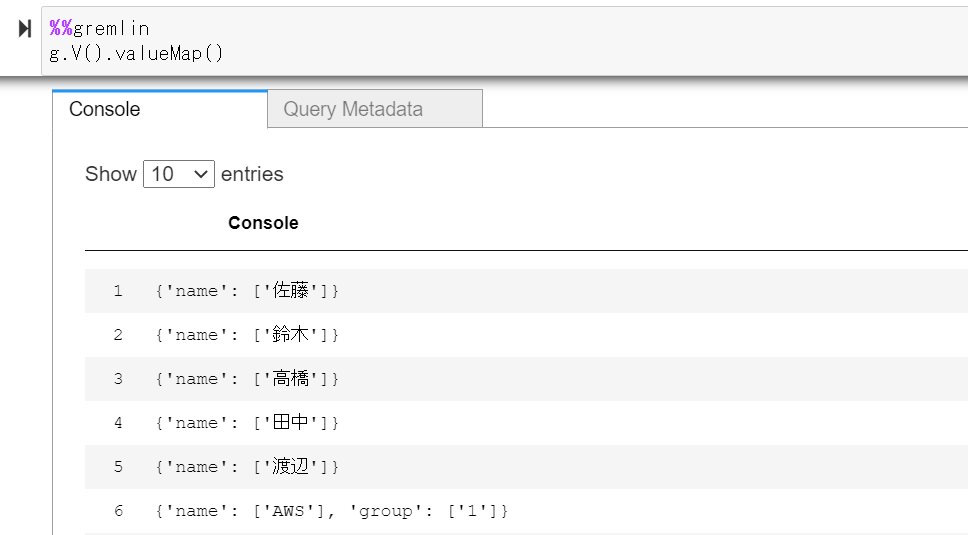
ノードの確認
g.V().valueMap()
エッジの確認
g.E().toList()
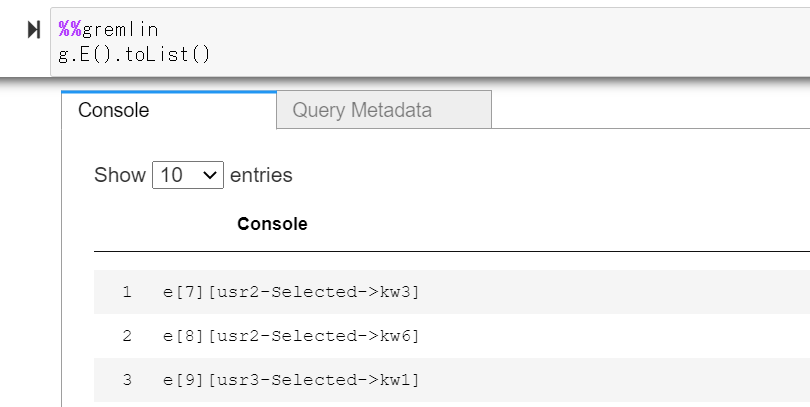
無事登録されていました。
データを削除したい場合
データを削除したい場合は、drop()を実行します。
以下は一括削除のコマンドです。ご注意ください。
g.V().drop().iterate()
g.E().drop().iterate()
データ取得用Lambda関数の作成
ノードとエッジの値を個別に取得し、整形したものをjson形式で返却します。
returnData = { nodes: data_nodes, edges: data_edge }
return JSON.stringify(returnData);
ノードはUser、KeyWordの2種類ありますが、
取得したいプロパティ名をnameに揃えているため、1回で取得します(省エネ)。
const nodes = await g.V()
.limit(100)
.valueMap()
.with_(withTokens)
.toList();
変数に格納する際は、id、labelはそのままでOKでした。
プロパティ(nameなど)は配列になっていたため、name.toString()で値を取得しています。
data_nodes = nodes.map(row => (
{id: row.id, label: row.name.toString(), group: row.label}
));
Lambda関数の全体像です。
const gremlin = require('gremlin');
exports.handler = async event => {
const {DriverRemoteConnection} = gremlin.driver;
const {Graph} = gremlin.structure;
const dc = new DriverRemoteConnection(
`wss://${process.env.NEPTUNE_ENDPOINT}:${process.env.NEPTUNE_PORT}/gremlin`,
{mimeType: 'application/vnd.gremlin-v2.0+json'}
);
const graph = new Graph();
const g = graph.traversal().withRemote(dc);
const withTokens = '~tinkerpop.valueMap.tokens';
try {
let data_nodes = [];
let data_edge = [];
const nodes = await g.V()
.limit(100)
.valueMap()
.with_(withTokens)
.toList();
data_nodes = nodes.map(row => (
{id: row.id, label: row.name.toString(), group: row.label}
));
const edge = await g.E().limit(100).toList();
data_edge = edge.map((r) => {
return {from: r.outV.id, to: r.inV.id};
});
const returnData = { nodes: data_nodes, edges: data_edge };
dc.close();
return JSON.stringify(returnData);
} catch (error) {
console.log('ERROR', error);
dc.close();
}
};
フロントにNeptuneからのデータ取得処理を追加
GraphQLのAPIを使用して接続します。
const [data, setData] = useState({nodes: [], edges: []});
useEffect(() => {
fetchMemberStatus();
}, []);
// neptuneからデータ取得
const fetchMemberStatus = async () => {
const apiData = await API.graphql({
query: queries.getGraphData,
});
setData(JSON.parse(apiData.data.getGraphData));
};
最終的な表示用コードです
import React, { useState, useEffect } from "react";
import { API } from "aws-amplify";
import * as queries from "../graphql/queries";
import VisNetworkReactComponent from "vis-network-react";
const TestPage = () =>{
const graphStyle = {
width: '600px',
height: '600px',
};
const [data, setData] = useState({nodes: [], edges: []});
useEffect(() => {
fetchMemberStatus();
}, []);
// neptuneからデータ取得
const fetchMemberStatus = async () => {
const apiData = await API.graphql({
query: queries.getGraphData,
});
setData(JSON.parse(apiData.data.getGraphData));
};
return (
<>
<VisNetworkReactComponent
style={graphStyle}
data={data}
/>
</>
);
}
export default TestPage;
無事Neptuneから取得したデータが表示されました!
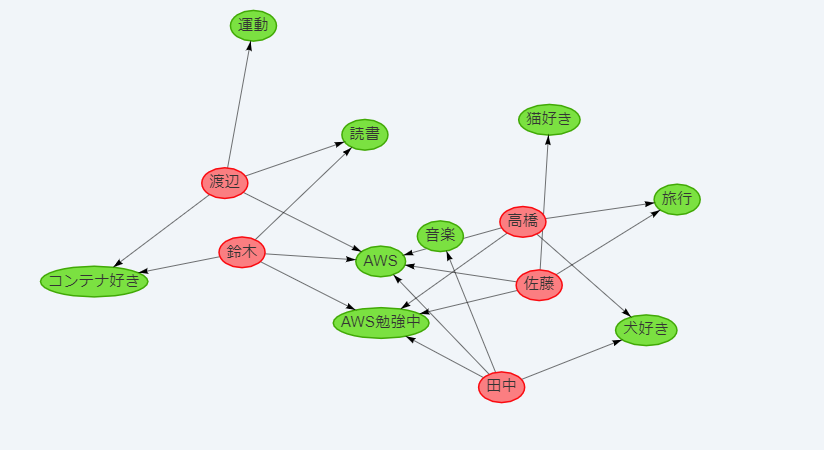
感想
当初はグラフデータのクエリで必要なデータのみ取得するべく、
Gremlinのクエリとにらめっこしていました。
サンプルを見ると、クエリ自体はシンプルだったため、
データの設計が大事だなと思いました。
(気づきポイント)
- 取得するプロパティ名を揃えると、クエリがすっきりする
| ノード名 | 変更前 | 変更後 |
|---|---|---|
| User | userName | name |
| KeyWord | name | name(変更なし) |
変更前:
- 取得項目が異なるため、クエリを分けるか、分岐処理が必要
変更後:
- 1回のクエリで取得可能。判断は別の項目(label)で可能
- 各ノードのidには文字列を含めると管理が容易
| ノード名 | 変更前 | 変更後 |
|---|---|---|
| User | 数値(1,2,3,4,5...) | 文字列+数値(usr1,usr2,usr3,usr4,usr5...) |
| KeyWord | 数値(1,2,3,4,5...) | 文字列+数値(kw1,kw2,kw3,kw4,kw5...) |
変更前:
- Edgeで、from、toのidがUserノードのものか、KeyWordノードのものか判断が難しい
- nodesとしてUserとKeyWordの配列をマージする際に重複してしまう
変更後:
- Edgeで、from、toのidが特定しやすい
- UserとKeyWordの配列をマージしてもidが重複しない
試した後は、後始末を忘れずに。
Neptuneは停止か削除しておきましょう。
東京リージョンではdb.t3.mediumで0.15USD/時間(2021/12/19現在)です![]()
参考資料
お世話になったハンズオン
Amazon Neptune グラフデータ可視化ハンズオン
Amazon NeptuneとAWS Amplifyを利用したグラフアプリケーション開発
Neptuneやデータ構造の検討資料
Amazon Neptune Advanced Design Patterns
20200714 AWS Black Belt Online Seminar Amazon Neptune
Amplifyの資料
Amplify学習リソース集
React アプリケーションの構築
クエリ言語(Gremlin)の資料
TinkerPop Documentation
PRACTICAL GREMLIN: An Apache TinkerPop Tutorial