1. この記事について
メモ的な形でpandasのgroupbyの基本的な操作のおさらいをします.
2. 課題設定 :
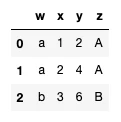
以下のdataframe aに対して,操作Aの操作を加えてdataframeを作成せよ:
import pandas as pd
a = pd.DataFrame([["a",1,2,"A"],["a",2,4,"A"],["b",3,6,"B"]],columns = ["w","x","y","z"])
- 操作A :
- wの値が同じものに関して,
- xに関しては合計を
- yに対しては平均と分散を
- zに対してはそのままの値を
- wのの長さを加えて集約せよ.
- wの値が同じものに関して,
3. データ確認
4. 問題理解
- まず,
zはwごとに値が異なるためそれぞれの集約として考えることができる. - すなわち,基本的に以下の操作で完結する:
a.groupby(["w","z"]).hogehoge
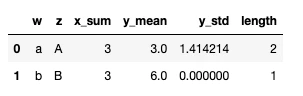
5. 答えの例
以下の操作を加えることで,操作が完結する:
# 1. xの合計
q1 = a.groupby(["w","z"])["x"].sum().reset_index().rename(columns={"x":"x_sum"})
# 2. yの平均と分散
q2a = a.groupby(["w","z"])["y"].mean().reset_index().rename(columns={"y":"y_mean"})
q2b = a.groupby(["w","z"])["y"].std().reset_index().rename(columns={"y":"y_std"}).fillna(0)
q2 = pd.merge(q2a,q2b)
# 3. それぞれの長さ
q3 = a.groupby(["w","z"]).size().reset_index().rename(columns = {0:"length"})
# マージを行う
res_df = q1
lst = [q2,q3]
for i in lst:
res_df = pd.merge(res_df,i)
res_df.head()