はじめに
Watson APIは、モデル作成などすでに済んでいて、すぐに使える非常に便利な仕組みです。
Visual RecognitionのCustom学習機能の学習のしやすさは、一度試したことのある人はご存じと思います。
また、今ではWatson Studioの機能としてVisual Recognition学習サービスも追加され、よりカスタム学習もやりやすくなっています。
しかし、この機能を使った場合でも、認識率の評価に関しては、手作業で行う必要がありました。
この問題を解決するため、Watson Studio上のJupyter Notebookから、Watson Visual RecognitionのAPIを呼び出して、学習から評価まですべて行う仕組みをつくってみました。
(2018-05-15 混同行列のヒートマップ表示を追加しました)
ツール仕様
- 教師データ・検証データとなりうるイメージデータは、分類先クラス別のサブディレクトリに保存します。
- サブディレクトリ名はクラス名と同一とします。
- クラス名を表すサブディレクトリのもう一つ上の階層のサブディレクトリも作ります
- 親の階層からまるごとgzで固めたファイルを作成し、これをツールの入力データとします
- サブディレクトリ配下のイメージデータは、先頭から一定数を学習用データ、一番後ろから一定数を検証データとします。この数についてはツール内のパラメータで設定可能です
- 認識率に関しては、sckit-learnのライブラリを呼び出してPrecision - Recall - F-scoreで評価しています。
- この他混同行列のヒートマップ表示も行ってみました。
ツールのダウンロード元
Github上にアップしてあります。リンク先はこちらです。
ツールの処理内容紹介
詳細は上のJupyter Notebookのコメントを見ていただきたいのですが、処理概要を以下に記載します。
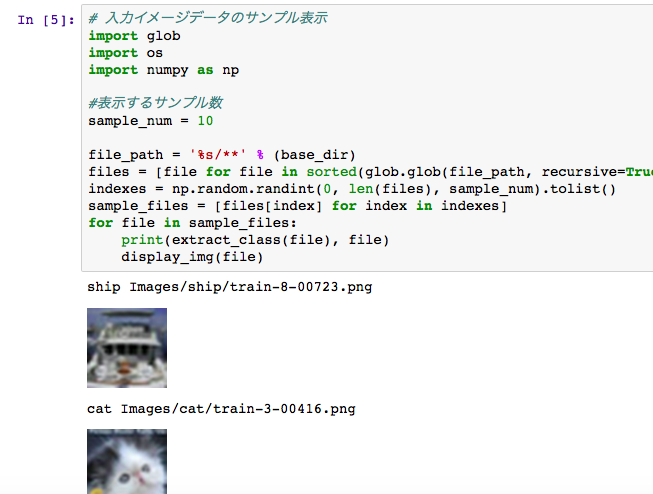
イメージの表示
学習・評価用イメージを表示する関数もツールの機能として持っています。
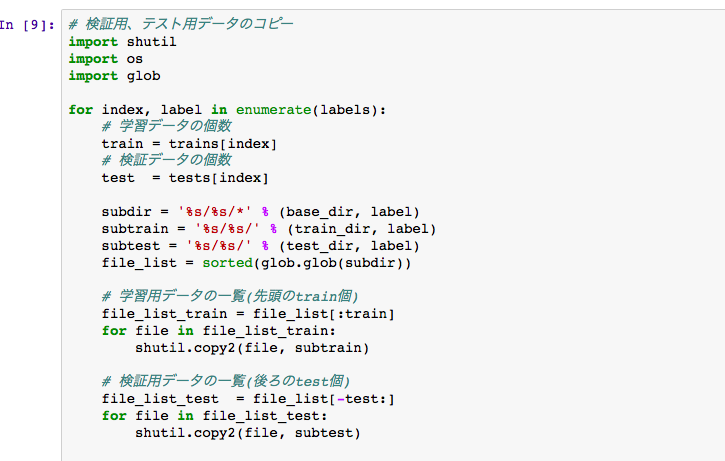
学習用データ作成
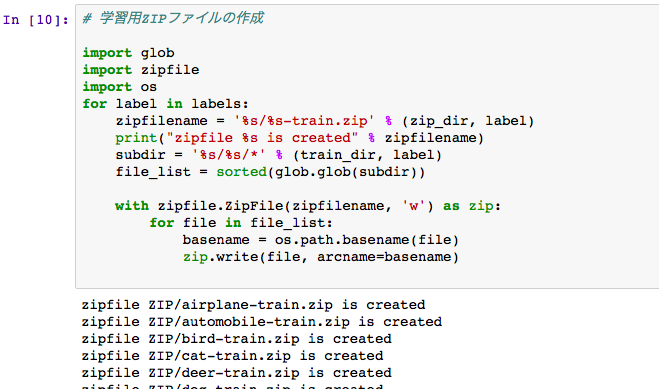
Visual Recognitionでは、学習時に分類クラス毎にzipファイルを作る必要があります。このセルでは、学習用のzipファイルを作ります。

学習用データ、検証用データは、いったん別ディレクトリのファイルをコピーします。
zipファイルは、コピー先から作ります。
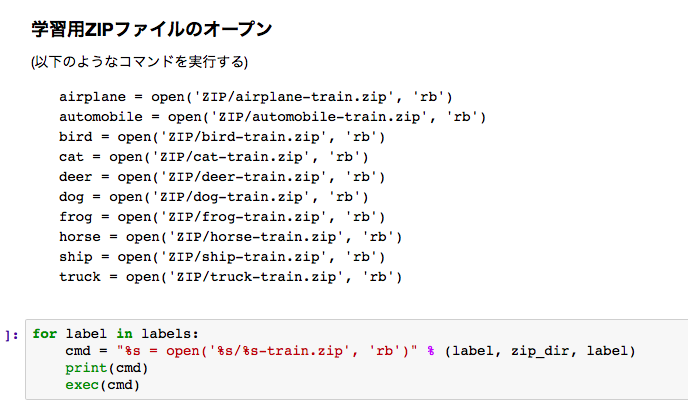
VR API呼出しによる学習
Pythonのexec機能を使って、次のようにzipファイルオープンとAPI呼出しを行っています。

次のループで、学習が終わるのをチェックします。
# トレーニングが完了するまでループ
from datetime import datetime
import pytz
import time
timezone_jst = pytz.timezone('Asia/Tokyo')
classifier = visual_recognition.get_classifier(classifier_id=classifier_id)
status = classifier['status']
print(timezone_jst.localize(datetime.now()), status)
while True:
if status in ['ready', 'fail']:
break
time.sleep(60)
classifier = visual_recognition.get_classifier(classifier_id=classifier_id)
status = classifier['status']
print(timezone_jst.localize(datetime.now()), status)
VR Classifier呼出しによる検証
学習が終わったら、検証データで認識率の確認を行います。
VR classifierの戻りのjsonはかなり複雑で解析が大変なので、解析用関数を事前に定義します。
# VRの戻りデータ解析用関数
def analyze_result(classes):
image = classes['images'][0]
# イメージファイル名
filename = image['image']
# イメージファイル名から正解クラス名を抽出
answer = extract_class(filename)
# 分類結果の取得
vr_classes = image['classifiers'][0]['classes']
# 辞書に結果をまとめる
scores = {}
for item in vr_classes:
scores[item['class']] = item['score']
# scoreがランダムな状態で結果が帰ってくるのでソートをする必要がある
scores2 = sorted(scores.items(), key=lambda x: x[1])[::-1]
# 一番スコアの高いクラス名とその時のスコア
pred, score = scores2[0][0], scores2[0][1]
return filename, answer, pred, score
検証データのファイル数だけClassify APIを呼び出して、結果を上の関数にかけ、解析結果を保存します。
# VRによる分類結果を取得
import glob
results = []
for label in labels:
# テストデータのあるディレクトリ
subdir = '%s/%s/*' % (test_dir, label)
# サブディレクトリ配下のファイル一覧の作成
file_list = sorted(glob.glob(subdir))
# 訓練データの1つ先から検証データ数だけファイル名を取得
for file in file_list:
with open(file, 'rb') as images_file:
# 分類器の呼出し
classes = visual_recognition.classify( images_file,
parameters=json.dumps({'classifier_ids': [classifier_id], 'threshold': 0.0}))
# 分類結果の解析
result = analyze_result(classes)
print(result)
results.append(result)
結果は次のような形式になります。
(分析対象イメージ)、(正解)、(分類結果)、(確信度)
の書式です。
('Test/airplane/train-0-00905.png', 'airplane', 'airplane', 0.384)
('Test/airplane/train-0-00906.png', 'airplane', 'ship', 0.573)
('Test/airplane/train-0-00911.png', 'airplane', 'bird', 0.585)
('Test/airplane/train-0-00927.png', 'airplane', 'frog', 0.726)
('Test/airplane/train-0-00938.png', 'airplane', 'ship', 0.879)
('Test/airplane/train-0-00940.png', 'airplane', 'automobile', 0.833)
('Test/airplane/train-0-00965.png', 'airplane', 'ship', 0.823)
('Test/airplane/train-0-00974.png', 'airplane', 'ship', 0.676)
('Test/airplane/train-0-00983.png', 'airplane', 'ship', 0.855)
('Test/airplane/train-0-00989.png', 'airplane', 'trunk', 0.674)
('Test/automobile/train-1-00917.png', 'automobile', 'trunk', 0.741)
('Test/automobile/train-1-00936.png', 'automobile', 'trunk', 0.656)
('Test/automobile/train-1-00942.png', 'automobile', 'ship', 0.693)
('Test/automobile/train-1-00947.png', 'automobile', 'automobile', 0.871)
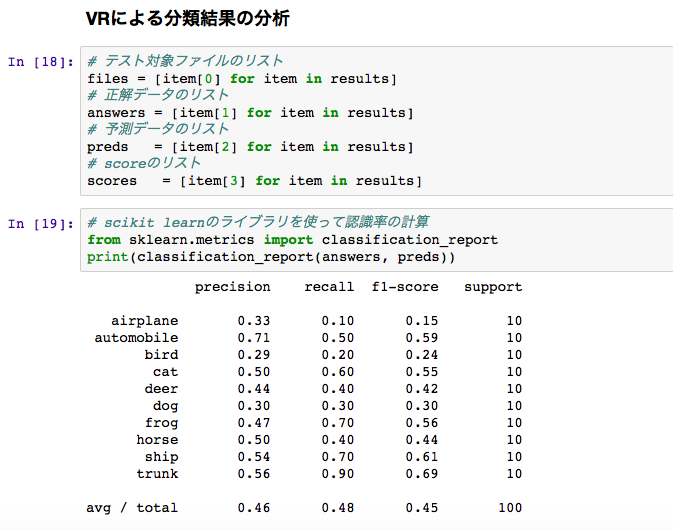
分析
上記のデータをsckit-learnのライブラリにかけて認識率を算出します。
(非常に数字が悪いですが、認識の難しい問題に対して各クラス10件ずつしか学習していないためですので、誤解のなきよう。)
多値分類では、混同行列のヒートマップ表示という手法もあるので、こちらも実装してみました。
# 混同行列
from sklearn.metrics import confusion_matrix
cmx = confusion_matrix(answers, preds, labels=labels)
# ヒートマップ表示
import pandas as pd
import seaborn as sn
import matplotlib.pyplot as plt
import matplotlib.cm as cm
%matplotlib inline
df_cmx = pd.DataFrame(cmx, index=labels, columns=labels)
plt.figure(figsize = (10,7))
sn.heatmap(df_cmx, cmap=cm.GnBu, annot=True)
plt.show()
こんなグラフが表示されるはずです。

おわりに
このツールを使うと、従来と比較して効率よくVisual Recognitionのカスタム学習が可能になると思います。
Watson Studioは、学習データ作成、学習、評価といった、機械学習で必要なタスクをフルライフサイクルでサポートするツールです。
今回ご紹介したサンプルは、そのほんの一例ですが、慣れると非常に便利なツールなので是非一度お試し下さい。