はじめに
SPSSで行うデータ処理を、Pythonで実装するとどうなるのか、試してみました。
(2021-11-01追記)
この記事は、SPSSに関するリレーブログ Modelerデータ加工Tips#21-併買パターン上位5種類の組み合わせを抽出すると関連があります。リンク先の記事も合わせてお読みいただけると幸いです。
問題設定
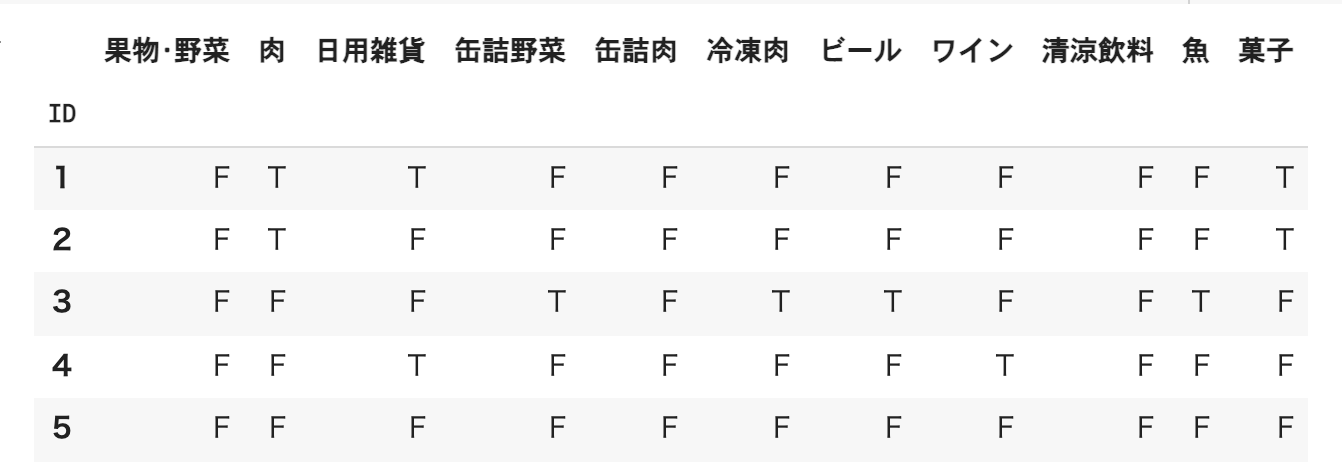
下記のような形式のデータが1000件あります。
実データのリンクはこちら
このデータに対して次の2つの例題を解くことがこの記事の目的です。
例題1:「併買パターンを集計する」
すでに顧客毎にカテゴリ購買有無を示すテーブルができている前提で、カテゴリの併買を集計してください。
こんな結果を出すことが目的です。
例題2: 「併買パターン上位5つのどれかに該当したレコードを抽出する」
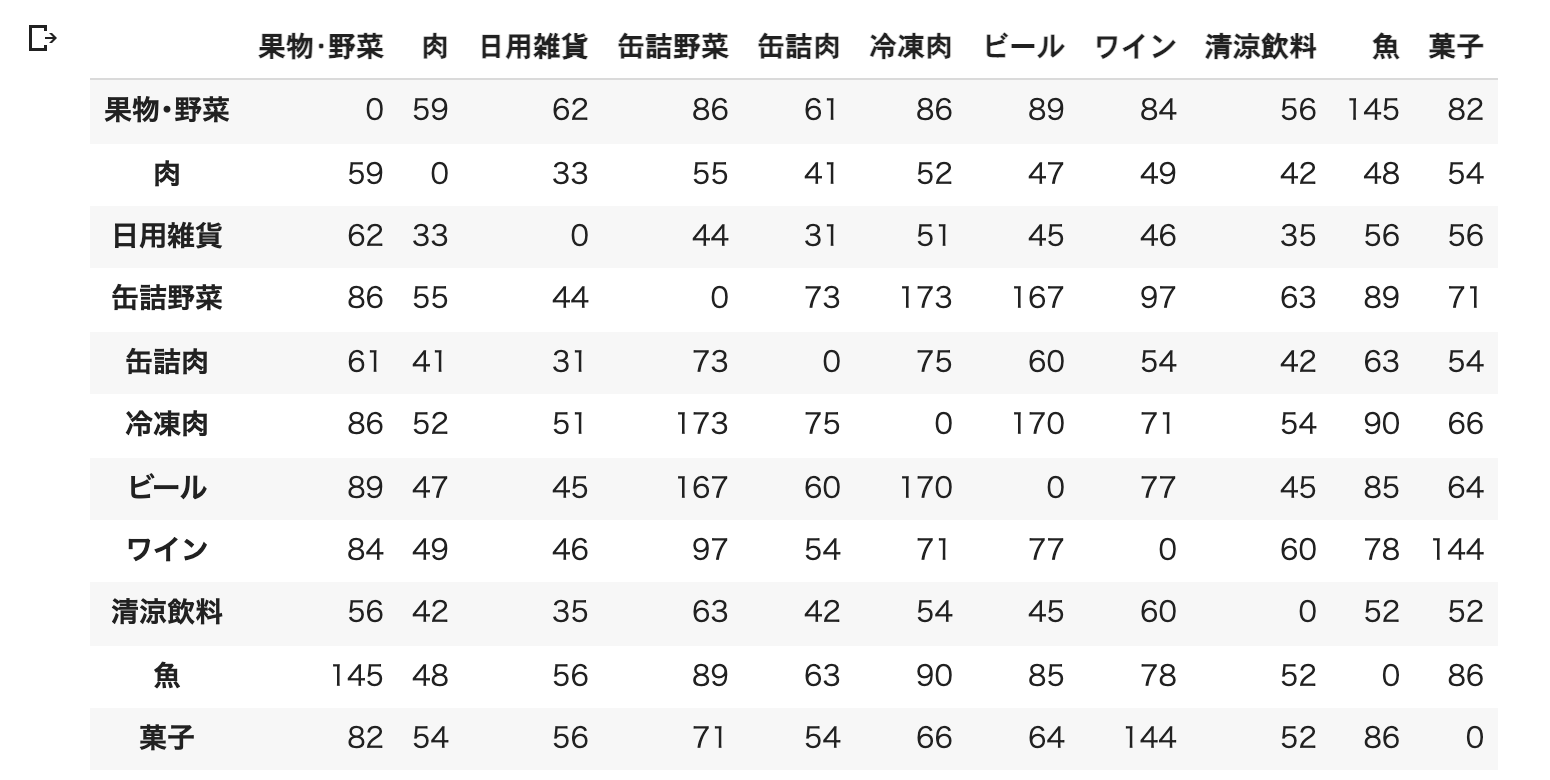
例題1の結果、冷凍肉と缶詰野菜を併買するパターンが最多で、173名でした(例題1の表を参照)。同じように同時に購入されるパターン上位5位を見つけ、そのどれかに該当するレコードを抽出しなさい。
この例題では、次のような結果を出すことが目的になります。
解答
それでは、実際に解いてみます。
共通事前処理
まず、csvデータをデータフレームdfに読み込みます。次に、Pythonで処理がしやすいように、'T', 'F'の値をTrue/Falseに置き換えたデータを df2 とします。
ライブラリインポートなど
NumPyや Pandasなどのライブラリをインポートします。
# 必要ライブラリのimport
import pandas as pd
import numpy as np
# データフレーム表示用関数
from IPython.display import display
# データフレームですべての項目を表示
pd.set_option("display.max_columns",None)
CSVデータ読み込み
github上の csvデータをデータフレーム変数df に読み込みます。
ここで少し工夫している点として、csvの項目のうち、ID列はデータ処理で使わないことがわかっているので、最初からインデックスとして読み込んでいる点です。
# データ読み込み
url = 'https://raw.githubusercontent.com/yoichiro0903n/blue/main/sampledatacross2.csv'
df = pd.read_csv(url, index_col='ID')
display(df.head())
次のような結果になるはずです。
データ整形
このままではデータ処理がやりにくいので、'T' -> True, 'F' -> Falseへの置き換えをし、置き換え後の変数と df2とします。
# 'T'-> True, 'F'-> Falseに変換
df2 = df.replace({'T': True, 'F': False})
# 結果確認
display(df2.head())
次のような結果になります。
解答1
それでは、例題1を解いてみます。
変数初期設定
最初に、項目名リストをIに、項目数を N に、集計用のデータフレームを Sとしてそれぞれ設定します。
# 項目のリスト
I = df2.columns
# 項目数
N = len(I)
# 結果表の初期設定
S = pd.DataFrame(np.zeros((N, N)),
columns=I, index=I, dtype='int64')
カウントアップ
カウントアップは3重のループ処理になります。
df2の各行要素を取り出した後、要素がTrueの項目のみlistとして抽出して、結果をx1とします。
項目数が2以上の場合のみ、項目ペア生成の処理に入ります。この処理自体、2重ループにする必要があります。
# 3重ループで該当要素値をカウントアップ
for i in df2.values:
# 要素がTrueの項目のみ抽出
x1 = I[i].tolist()
# 要素数が1以下の場合は何もしない
if len(x1) <= 1:
continue
# 項目ペアの生成
for x2 in x1:
x3 = x1.copy()
x3.remove(x2)
# x3は更に各要素に分解
for x4 in x3:
# DataFrameの該当要素値をカウントアップ
S.loc[x2, x4] += 1
# 結果確認
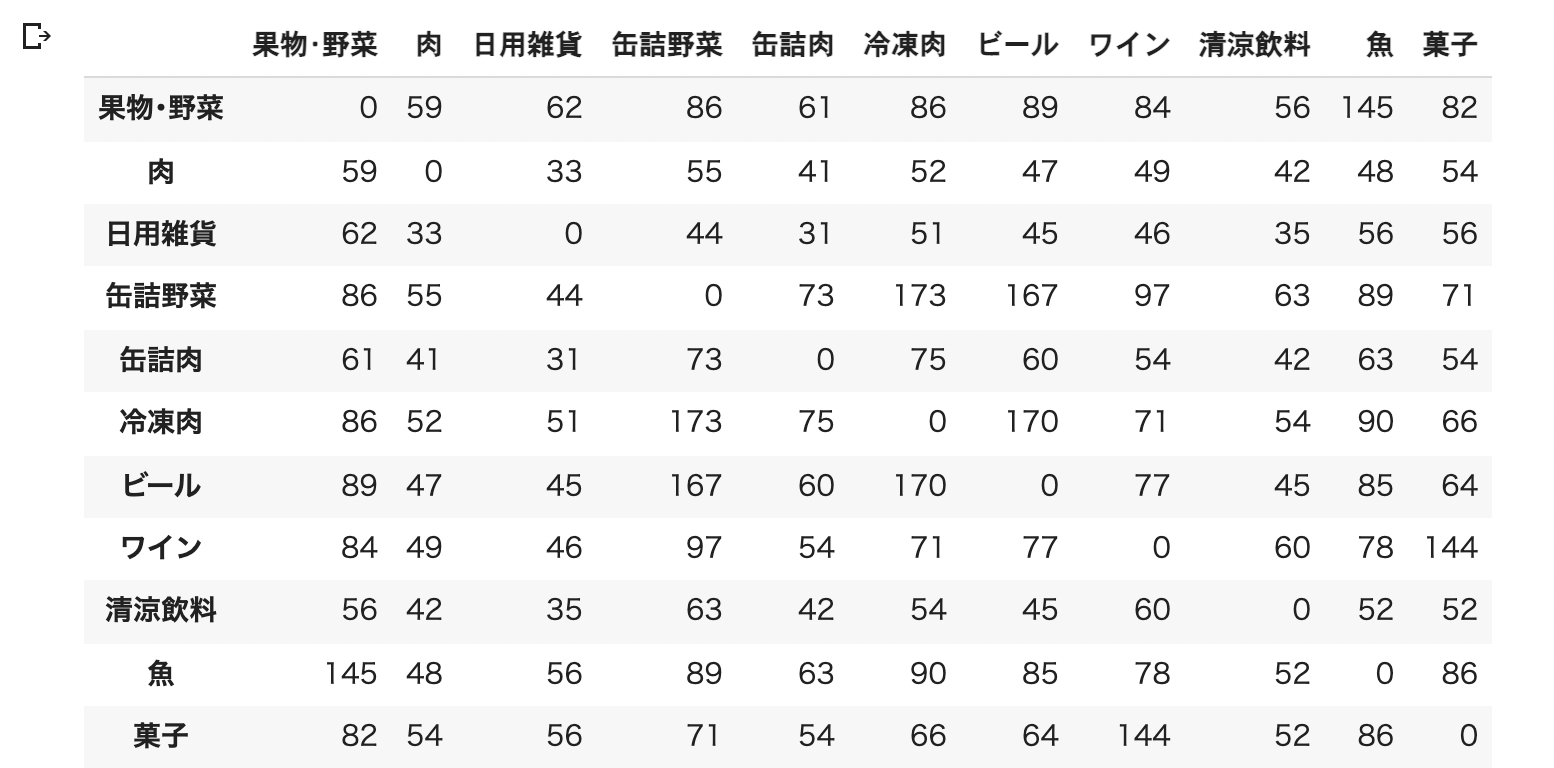
display(S)
最後のdisplay関数の結果は以下のようになります。
解答2
次に例題2を解いてみます。例題2は、「項目ペアの抽出」を行う第1ステップと、「該当データの抽出」を行う第2ステップに分けて実装します。
関数定義
最初に第1ステップ実装の準備として関数定義をします。
第1ステップは、例題1で求めた集計表を1次元化し、 argsort関数を使うことで実装しうます。ここで定義する関数は、1次元化されたindexを元の行、列の2次元に戻し、更に大該当する項目のペアを求めるためのものです。
# 1次元化したインデックスを2次元に戻し
# 該当項目名をタプルで戻す関数
def getitem(x, I):
N = len(I)
x1, x2 = (x % N), (x // N)
return(I[x1], I[x2])
項目ペアのリスト作成
次が、項目ペアのリスト作成処理です。この処理は、「項目値の1次元化」、「上位5個のインデックス値取得」、「getitem関数を使って項目名ペアのリスト作成」の3ステップからなります。
2つめのステップのnp.argsort(-w1)[:10:2]がちょっとややこしいことをしています。
-w1 としているのは、逆順ソートをするため
[:10:2]は、結果の先頭10個を一つおきに取得
という意味になります。
# 上位5個の項目ペアを取得
# 結果リスト初期化
cols_list = []
# 行列の項目値を抜き出し1次元化
w1 = S.values.reshape(-1)
# 上位5個のインデックス値取得
w2 = np.argsort(-w1)[:10:2]
# getitem関数を使って項目名ペアのリスト作成
for i in w2:
x, y = getitem(i, I)
cols_list.append([x, y])
# 結果確認
for cols in cols_list:
print(cols)
結果

該当データの抽出
次に、オリジナルデータであるdfから該当データ行を抽出します。
最初に空のデータフレーム変数target_df を準備し、該当列が見つかると、順にappend関数で、このデータフレーム変数に追加していきます。
該当であるかどうかの判断は、5つの対象項目ペアと、行単位で抽出した項目リストのそれぞれを集合変数に変換し、 <= 演算子で含まれているかどうかの判定をしました。最後の3行は、Pythonの2重ループで、最初のループに対して continueをかけたいときに使われるテクニックになります。
# 空のデータフレーム作成
target_df = pd.DataFrame()
# 先頭行から順にループ処理
for i in range(len(df2)):
# 要素がTrueの項目のみ抽出
item = df2.iloc[i]
# 抽出結果を集合化
x1 = set(I[item.values].tolist())
for j in cols_list:
# cols_listの各要素も集合化
x2 = set(j)
# 集合同士の比較で条件を満たしているかチェック
if x2 <= x1:
target_df = target_df.append(df.iloc[i])
break
# 以下の実装は2重ループで最初のループにcontinueをかけるためのテクニック
else:
continue
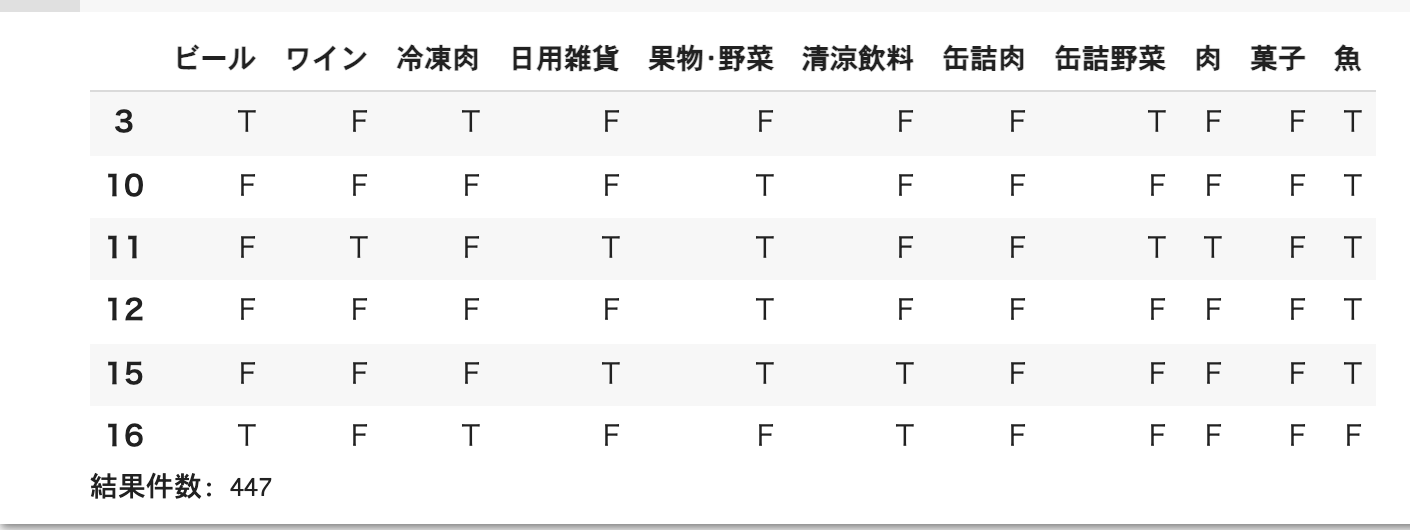
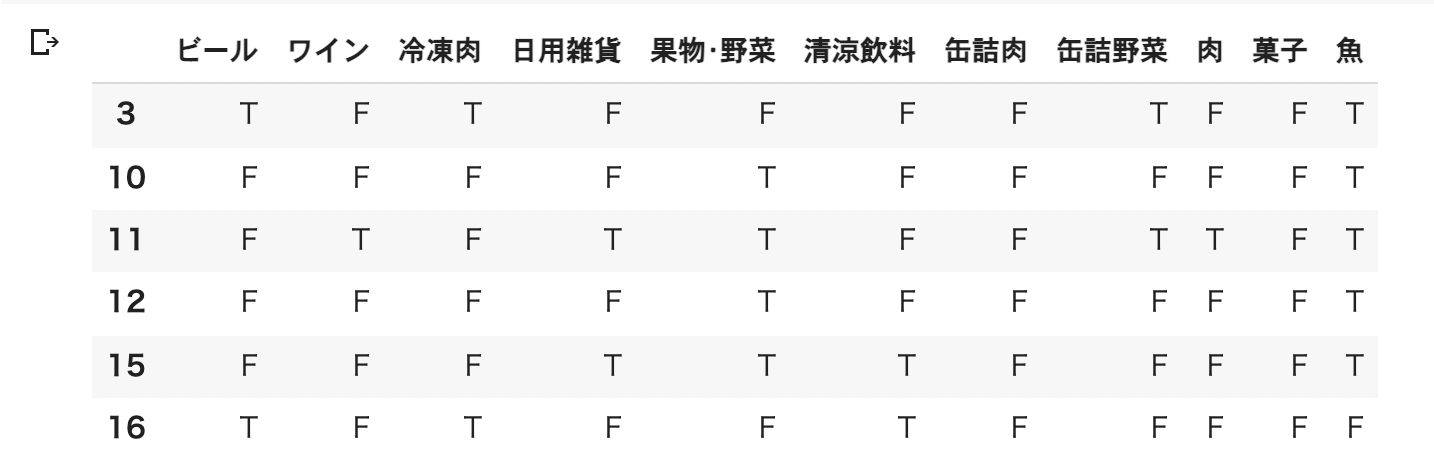
最終的に下記のような結果が得られ、目的を達することができました。
# 結果確認
display(target_df.head(6))
# 結果件数確認
count = len(target_df)
print(f'結果件数: {count}')