はじめに
前から、そろそろPyTorchも勉強しないとと思っていたのですが、まとまった時間が取れたので、書籍(PyTorchニューラルネット実装ハンドブック)片手に勉強してみました。
この記事を書く時点での筆者の前提知識は、
- TensorFlowとKerasは普通にわかっている
- PyTorchはまったくの初心者
です。似たような人は他にもいると思うので、その参考になれば幸いです。
PyTorchのざっくりした感想
なんといっても勉強を始めてまだ半日なので間違っているかもしれませんが、ざっくりした感想として、実装のややこしさは、KerasとTensorFlowのちょうど中間ぐらいかと思いました。
モデルの定義のところは、ほぼ、Kerasと同じ感じです。
逆に、学習のところは、かなりの量を裸のコードで書く必要があるという印象でした。ただ、他で動いているコードをコピーしただけで動いたので、そんなに大変ということでもなかったです。裏返すと、このあたりをきれいに隠蔽できているKerasは素晴らしいということなのかもしれません。
アプローチの方法
書籍のコードを写経するのでは頭を使わないので、過去に試したことのあるCIFAR-10の分類をKerasで実装したのと、まったく同じ構造、同じアルゴリズムのモデルを作ってみることにしました。
自分で1から実装して初めて気付いたこともいくつかあったので、効率的な勉強方法だった気がします。
実装コードと環境
以下で解説する実装コードは、下記Githubにアップしてあります。
やったことがある人はわかると思いますが、CIFAR-10は結構難しい例題でして、普通にモデルを作ると60%くらいしか精度がでません。
ここでご紹介するモデルは、確か、Kaggleに出ていた精度の高いモデルを構造だけ持ってきたものと思います。(Kaggleでは他にデータの前処理もやっていたが、そこは省略)。毎回精度は異なりますが、調子がいいと80%くらいまで行きます。
環境はGoogle Colabを使いました。
Keras / PyTorch 関係は、追加導入は一切不要でした。追加導入したのは、matplotlibの日本語化モジュールだけだったと思います。さすが、Google Colab、こういう時にはとても便利です。
コード解説
前置きはこの程度にして、実際のコードの解説に入りましょう。
データのロード
CIFAR-10の学習データに関しては、Keras同様、PyTorchでも関数が用意されていて、すぐにロードできました。
せっかくなので、この部分もコード比較をしてみます。
Keras
# Kerasライブラリのインポート
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Dropout, Flatten, Dense, Activation
# それ以外のライブラリのインポート
!pip install japanize_matplotlib | tail -n 1
import matplotlib.pyplot as plt
import japanize_matplotlib
import numpy as np
# 学習データ読み込み
from keras.datasets import cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 分類先クラス数の計算
class_labels_count = len(set(y_train.flatten()))
# One Hot Encoding
from keras.utils import np_utils
y_train_ohe = np_utils.to_categorical(y_train, class_labels_count)
y_test_ohe = np_utils.to_categorical(y_test, class_labels_count)
PyTorch
# PyTooch関連ライブラリインポート
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision.transforms as transforms
# それ以外のライブラリインポート
%matplotlib inline
import numpy as np
!pip install japanize_matplotlib | tail -n 1
import matplotlib.pyplot as plt
import japanize_matplotlib
# 分類クラス数
num_classes = 10
# 学習繰り返し回数
nb_epoch = 20
# 1回の学習で何枚の画像を使うか
batch_size = 128
# 学習データ読み込み
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,download=True, transform=transform)
test_loader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
学習データの扱い方からPyTorchはKerasと違っていました。
DataSetとDataLoaderという、学習に特化したクラスが作られていて、これを利用する形になります。
DataSetとは、入力データと正解ラベル値のセットがタプルになっていて、そのIteratorとして用意されます。入力データはPyTorch固有のTensorというクラスの変数です。
いわゆる「ミニバッチ学習法」で用いるbatch_sizeの指定は、DataLoaderの中で行う形になります(このことに最初はまったく気付かなかった)。
もう1点、正解ラベルデータについても違いがあります。Kerasの場合は、正解データはOne Hot Encodingをする必要があります。コードの最後でその実装をしています。PyTorchでは、ラベル値のエンコードはフレームワークの内部でやってくれるようで、エンコーディングなしの値(6とか3とかの値)をそのまま学習時の正解値にできます。この点はPyTorchの方が便利なようです。
入力データのイメージ表示
学習そのものとは関係ないのですが、せっかくなので、読み込んだ学習データのうち、先頭の10個をイメージ表示してみます。結果は下記のとおりです。

こんな単純なことでも、データの持ち方の違いからKeras / PyTorchで結構別の実装になります。
Keras
plt.figure(figsize=(15, 4))
for i in range(10):
ax = plt.subplot(1, 10, i + 1)
image = x_train[i]
label = y_train[i][0]
plt.imshow(image)
ax.set_title(classes[label], fontsize=16)
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
PyTorch
plt.figure(figsize=(15, 4))
for i in range(10):
ax = plt.subplot(1, 10, i + 1)
image, label = trainset[i]
np_image = image.numpy().copy()
img = np.transpose(np_image, (1, 2, 0))
img2 = (img + 1)/2
plt.imshow(img2)
ax.set_title(classes[label], fontsize=16)
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
trainsetという変数からループを回して(image, label)のセットを一つずつ取り出す点が、一つ目のPyTorchの特徴です。
もう一つの違いは、imageデータを画面表示するのに、結構加工が必要な点です。Kerasの場合は、そもそものデータがnumpy配列になっていて、plt.imshow関数にそのまま渡せばそれで表示できたのですが、PyTorchの場合は、次の3段階の加工が必要でした。
- image変数がTensorクラスの変数なので、Numpyに変換する
- 軸の順番が違っているので
np.transpose関数で入れ替える - 学習データの範囲が [-1, 1]になっているので、これを [0, 1]の範囲に変更する
最後の話がなかなか気付かなかった点なのですが、わかってみると、データ読み込みの時に使っている transforms.Normalize関数で加工することで、こういうデータになっているようです。
うまく、加工前の状態を別変数でもっておけばもっと効率いい実装にできるはずですが、PyTorch初心者で具体的にどうするかわからなかったので、いったんこれでよしとしています。
モデルの生成
次のステップは一番本質的なモデルの生成です。こちらに関しては、Keras / PyTorchほぼ同等かなという印象です。
Keras
def cnn_model(x_train, class_labels_count):
model = Sequential()
model.add(Conv2D(32, (3, 3), padding="same", input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(class_labels_count))
model.add(Activation('softmax'))
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy']
)
return model
# モデル生成
model = cnn_model(x_train, class_labels_count)
PyTorch
# モデルクラスの定義
class cifar10_cnn(nn.Module):
def __init__(self, num_classes):
super(cifar10_cnn,self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3, padding=(1,1), padding_mode='replicate')
self.conv2 = nn.Conv2d(32, 32, 3)
self.conv3 = nn.Conv2d(32, 64, 3, padding=(1,1), padding_mode='replicate')
self.conv4 = nn.Conv2d(64, 64, 3)
self.relu = nn.ReLU(inplace=True)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.maxpool = nn.MaxPool2d((2,2))
self.classifier1 = nn.Linear(2304, 512)
self.classifier2 = nn.Linear(512, num_classes)
self.features = nn.Sequential(
self.conv1,
self.relu,
self.conv2,
self.relu,
self.maxpool,
self.dropout1,
self.conv3,
self.relu,
self.conv4,
self.relu,
self.dropout1,
self.maxpool)
self.classifier = nn.Sequential(
self.classifier1,
self.relu,
self.dropout2,
self.classifier2)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
# GPUの確認
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(device)
# モデルインスタンスの生成とGPUの割り当て
net = cifar10_cnn(num_classes).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters())
Kerasでは、モデルの定義は関数でできる(関数を使わずにベタにやってもできる)のに対して、PyTorchの場合はクラスを定義するのがお作法のようです。でも、実装コードの分量でいうと似たり寄ったりという印象です。
一点だけ、PyTorchで苦労した点があって、パディングに関してKerasみたいにシンプルにpadding='same'のような指定ができないみたいです。ググったらqiitaで記事で下記の記事を見つけたので、使わせてもらいました。
あと、PyTorchではモデルの構造を動的に宣言できるので、nn.Linear(2304, 512)のマジックナンバー2304は、きっと計算で出せるのだろうなと思いつつ、動かすこと優先で先に進めました。
PyTorchではGPUを使おうとする場合、net = cifar10_cnn(num_classes).to(device)のようにデバイスの割り当てを明示的にする必要があるようです。Kerasでは、GPUがあれば勝手に使ってくれますので、その点はKerasの方が便利でした。
モデルの構造確認
これで本当に同じ構造になったのか、確認してみましょう。Keras / PyTorchで構造を確認するためのコマンドとその出力を示します。
Keras
# モデルのサマリー表示
model.summary()
結果
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 32, 32, 32) 896
_________________________________________________________________
activation (Activation) (None, 32, 32, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 30, 30, 32) 9248
_________________________________________________________________
activation_1 (Activation) (None, 30, 30, 32) 0
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 15, 15, 32) 0
_________________________________________________________________
dropout (Dropout) (None, 15, 15, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 15, 15, 64) 18496
_________________________________________________________________
activation_2 (Activation) (None, 15, 15, 64) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 13, 13, 64) 36928
_________________________________________________________________
activation_3 (Activation) (None, 13, 13, 64) 0
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 6, 6, 64) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 6, 6, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 2304) 0
_________________________________________________________________
dense (Dense) (None, 512) 1180160
_________________________________________________________________
activation_4 (Activation) (None, 512) 0
_________________________________________________________________
dropout_2 (Dropout) (None, 512) 0
_________________________________________________________________
dense_1 (Dense) (None, 10) 5130
_________________________________________________________________
activation_5 (Activation) (None, 10) 0
=================================================================
Total params: 1,250,858
Trainable params: 1,250,858
Non-trainable params: 0
_________________________________________________________________
PyTorch
# モデルのサマリー表示
from torchsummary import summary
summary(net,(3,32,32))
結果
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 32, 32, 32] 896
Conv2d-2 [-1, 32, 32, 32] 896
ReLU-3 [-1, 32, 32, 32] 0
ReLU-4 [-1, 32, 32, 32] 0
ReLU-5 [-1, 32, 32, 32] 0
Conv2d-6 [-1, 32, 30, 30] 9,248
Conv2d-7 [-1, 32, 30, 30] 9,248
ReLU-8 [-1, 32, 30, 30] 0
ReLU-9 [-1, 32, 30, 30] 0
ReLU-10 [-1, 32, 30, 30] 0
MaxPool2d-11 [-1, 32, 15, 15] 0
MaxPool2d-12 [-1, 32, 15, 15] 0
Dropout-13 [-1, 32, 15, 15] 0
Dropout-14 [-1, 32, 15, 15] 0
Conv2d-15 [-1, 64, 15, 15] 18,496
Conv2d-16 [-1, 64, 15, 15] 18,496
ReLU-17 [-1, 64, 15, 15] 0
ReLU-18 [-1, 64, 15, 15] 0
ReLU-19 [-1, 64, 15, 15] 0
Conv2d-20 [-1, 64, 13, 13] 36,928
Conv2d-21 [-1, 64, 13, 13] 36,928
ReLU-22 [-1, 64, 13, 13] 0
ReLU-23 [-1, 64, 13, 13] 0
ReLU-24 [-1, 64, 13, 13] 0
Dropout-25 [-1, 64, 13, 13] 0
Dropout-26 [-1, 64, 13, 13] 0
MaxPool2d-27 [-1, 64, 6, 6] 0
MaxPool2d-28 [-1, 64, 6, 6] 0
Linear-29 [-1, 512] 1,180,160
Linear-30 [-1, 512] 1,180,160
ReLU-31 [-1, 512] 0
ReLU-32 [-1, 512] 0
ReLU-33 [-1, 512] 0
Dropout-34 [-1, 512] 0
Dropout-35 [-1, 512] 0
Linear-36 [-1, 10] 5,130
Linear-37 [-1, 10] 5,130
================================================================
Total params: 2,501,716
Trainable params: 2,501,716
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 3.76
Params size (MB): 9.54
Estimated Total Size (MB): 13.31
----------------------------------------------------------------
要素の数は、すべての層でぴったり合っていて、なんとなくよさそうな感じです。
PyTorchの場合は、モデルのインスタンスであるnetという変数をそのまま実行すると、下のような情報も表示してくれます。
net
cifar10_cnn(
(conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), padding_mode=replicate)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
(conv3): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), padding_mode=replicate)
(conv4): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))
(relu): ReLU(inplace=True)
(dropout1): Dropout(p=0.25, inplace=False)
(dropout2): Dropout(p=0.5, inplace=False)
(maxpool): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
(classifier1): Linear(in_features=2304, out_features=512, bias=True)
(classifier2): Linear(in_features=512, out_features=10, bias=True)
(features): Sequential(
(0): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), padding_mode=replicate)
(1): ReLU(inplace=True)
(2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
(5): Dropout(p=0.25, inplace=False)
(6): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), padding_mode=replicate)
(7): ReLU(inplace=True)
(8): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))
(9): ReLU(inplace=True)
(10): Dropout(p=0.25, inplace=False)
(11): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Linear(in_features=2304, out_features=512, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=512, out_features=10, bias=True)
)
)
学習
これで準備はすべて整いました。いよいよ学習を実施します。冒頭でも説明しましたが、この部分は(現在のところ)Kerasが圧倒的に簡単です。
Keras
# 学習繰り返し回数
nb_epoch = 20
# 1回の学習で何枚の画像を使うか
batch_size = 128
# 学習
history = model.fit(
x_train, y_train_ohe, batch_size=batch_size, epochs=nb_epoch, verbose=1,
validation_data=(x_test, y_test_ohe), shuffle=True
)
PyTorch
学習
train_loss_list = []
train_acc_list = []
val_loss_list = []
val_acc_list = []
for epoch in range(nb_epoch):
train_loss = 0
train_acc = 0
val_loss = 0
val_acc = 0
#train
net.train()
for i, (images, labels) in enumerate(train_loader):
#view()での変換をしない
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = net(images)
loss = criterion(outputs, labels)
train_loss += loss.item()
train_acc += (outputs.max(1)[1] == labels).sum().item()
loss.backward()
optimizer.step()
avg_train_loss = train_loss / len(train_loader.dataset)
avg_train_acc = train_acc / len(train_loader.dataset)
#val
net.eval()
with torch.no_grad():
for images, labels in test_loader:
#view()での変換をしない
images = images.to(device)
labels = labels.to(device)
outputs = net(images)
loss = criterion(outputs, labels)
val_loss += loss.item()
val_acc += (outputs.max(1)[1] == labels).sum().item()
avg_val_loss = val_loss / len(test_loader.dataset)
avg_val_acc = val_acc / len(test_loader.dataset)
print ('Epoch [{}/{}], loss: {loss:.4f} val_loss: {val_loss:.4f}, val_acc: {val_acc:.4f}'
.format(epoch+1, nb_epoch, i+1, loss=avg_train_loss, val_loss=avg_val_loss, val_acc=avg_val_acc))
train_loss_list.append(avg_train_loss)
train_acc_list.append(avg_train_acc)
val_loss_list.append(avg_val_loss)
val_acc_list.append(avg_val_acc)
それぞれの実行結果は、以下のようになります。
ただ、Kerasの方はフレームワークで用意されたfit関数の出力そのものなのに対して、PyTorchの方は、それに似せた出力をprint関数手組みで出しているだけなので、そもそも比較することが正しくないともいえます。
Keras
Epoch 1/20
391/391 [==============================] - 7s 11ms/step - loss: 4.8051 - accuracy: 0.2355 - val_loss: 1.5342 - val_accuracy: 0.4480
Epoch 2/20
391/391 [==============================] - 4s 10ms/step - loss: 1.4853 - accuracy: 0.4612 - val_loss: 1.2996 - val_accuracy: 0.5420
Epoch 3/20
391/391 [==============================] - 4s 10ms/step - loss: 1.3215 - accuracy: 0.5309 - val_loss: 1.1627 - val_accuracy: 0.5996
Epoch 4/20
391/391 [==============================] - 4s 10ms/step - loss: 1.2014 - accuracy: 0.5732 - val_loss: 1.0446 - val_accuracy: 0.6388
Epoch 5/20
391/391 [==============================] - 4s 10ms/step - loss: 1.1124 - accuracy: 0.6070 - val_loss: 0.9813 - val_accuracy: 0.6627
Epoch 6/20
391/391 [==============================] - 4s 10ms/step - loss: 1.0317 - accuracy: 0.6355 - val_loss: 0.9245 - val_accuracy: 0.6772
Epoch 7/20
391/391 [==============================] - 4s 10ms/step - loss: 0.9625 - accuracy: 0.6639 - val_loss: 0.8732 - val_accuracy: 0.7022
Epoch 8/20
391/391 [==============================] - 4s 10ms/step - loss: 0.9309 - accuracy: 0.6748 - val_loss: 0.8433 - val_accuracy: 0.7064
Epoch 9/20
391/391 [==============================] - 4s 10ms/step - loss: 0.8730 - accuracy: 0.6922 - val_loss: 0.8197 - val_accuracy: 0.7174
Epoch 10/20
391/391 [==============================] - 4s 10ms/step - loss: 0.8575 - accuracy: 0.6982 - val_loss: 0.7722 - val_accuracy: 0.7310
Epoch 11/20
391/391 [==============================] - 4s 10ms/step - loss: 0.8030 - accuracy: 0.7178 - val_loss: 0.7756 - val_accuracy: 0.7272
Epoch 12/20
391/391 [==============================] - 4s 10ms/step - loss: 0.7841 - accuracy: 0.7244 - val_loss: 0.7372 - val_accuracy: 0.7468
Epoch 13/20
391/391 [==============================] - 4s 10ms/step - loss: 0.7384 - accuracy: 0.7429 - val_loss: 0.7738 - val_accuracy: 0.7340
Epoch 14/20
391/391 [==============================] - 4s 10ms/step - loss: 0.7321 - accuracy: 0.7462 - val_loss: 0.7177 - val_accuracy: 0.7501
Epoch 15/20
391/391 [==============================] - 4s 10ms/step - loss: 0.6976 - accuracy: 0.7530 - val_loss: 0.7478 - val_accuracy: 0.7477
Epoch 16/20
391/391 [==============================] - 4s 10ms/step - loss: 0.7047 - accuracy: 0.7537 - val_loss: 0.7160 - val_accuracy: 0.7608
Epoch 17/20
391/391 [==============================] - 4s 10ms/step - loss: 0.6638 - accuracy: 0.7682 - val_loss: 0.7111 - val_accuracy: 0.7630
Epoch 18/20
391/391 [==============================] - 4s 10ms/step - loss: 0.6509 - accuracy: 0.7709 - val_loss: 0.7099 - val_accuracy: 0.7610
Epoch 19/20
391/391 [==============================] - 4s 10ms/step - loss: 0.6346 - accuracy: 0.7770 - val_loss: 0.6933 - val_accuracy: 0.7691
Epoch 20/20
391/391 [==============================] - 4s 10ms/step - loss: 0.6119 - accuracy: 0.7833 - val_loss: 0.7006 - val_accuracy: 0.7619
PyTorch
Epoch [1/20], loss: 0.0124 val_loss: 0.0104, val_acc: 0.5187
Epoch [2/20], loss: 0.0094 val_loss: 0.0081, val_acc: 0.6432
Epoch [3/20], loss: 0.0079 val_loss: 0.0075, val_acc: 0.6791
Epoch [4/20], loss: 0.0069 val_loss: 0.0066, val_acc: 0.7173
Epoch [5/20], loss: 0.0062 val_loss: 0.0060, val_acc: 0.7405
Epoch [6/20], loss: 0.0058 val_loss: 0.0057, val_acc: 0.7557
Epoch [7/20], loss: 0.0053 val_loss: 0.0054, val_acc: 0.7666
Epoch [8/20], loss: 0.0050 val_loss: 0.0054, val_acc: 0.7656
Epoch [9/20], loss: 0.0047 val_loss: 0.0052, val_acc: 0.7740
Epoch [10/20], loss: 0.0045 val_loss: 0.0052, val_acc: 0.7708
Epoch [11/20], loss: 0.0042 val_loss: 0.0051, val_acc: 0.7790
Epoch [12/20], loss: 0.0040 val_loss: 0.0051, val_acc: 0.7797
Epoch [13/20], loss: 0.0038 val_loss: 0.0051, val_acc: 0.7802
Epoch [14/20], loss: 0.0037 val_loss: 0.0050, val_acc: 0.7812
Epoch [15/20], loss: 0.0035 val_loss: 0.0049, val_acc: 0.7910
Epoch [16/20], loss: 0.0034 val_loss: 0.0049, val_acc: 0.7840
Epoch [17/20], loss: 0.0033 val_loss: 0.0049, val_acc: 0.7936
Epoch [18/20], loss: 0.0031 val_loss: 0.0049, val_acc: 0.7917
Epoch [19/20], loss: 0.0030 val_loss: 0.0048, val_acc: 0.8008
Epoch [20/20], loss: 0.0029 val_loss: 0.0050, val_acc: 0.7900
学習曲線
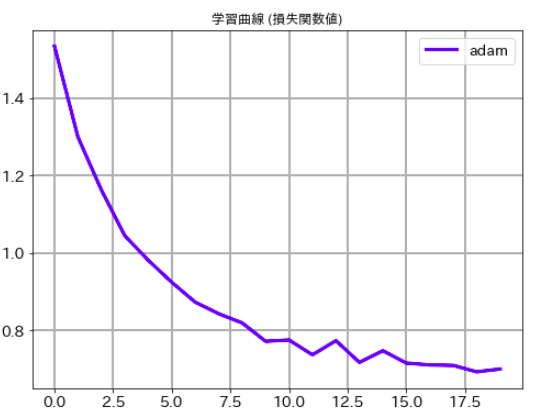
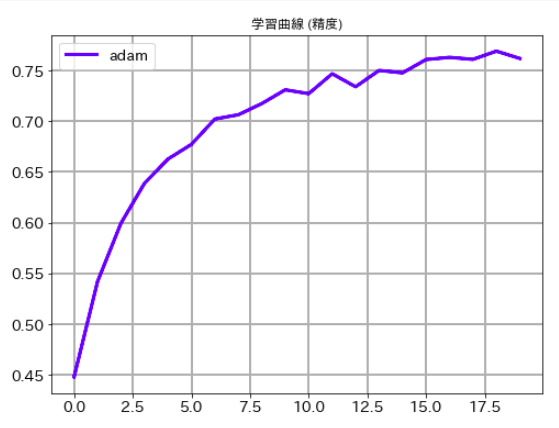
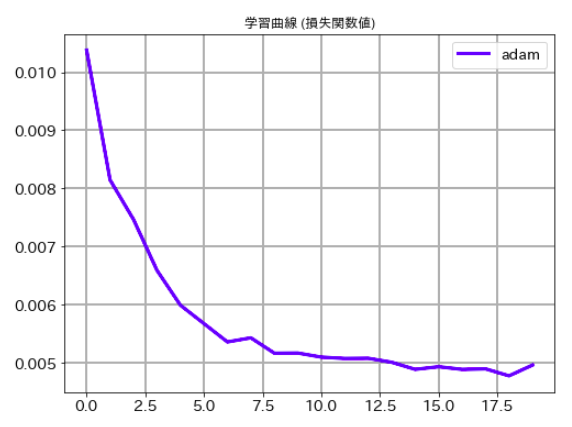
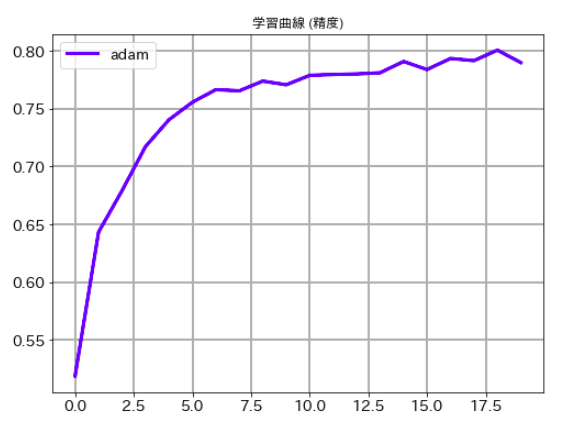
最後にそれぞれのケースの学習曲線ものせておきます。ご承知のとおり、deep learningでは乱数を使っている関係で一回ごとに精度が異なります。この結果だけでどちらのルレームワークがいいかは議論できませんので、その点はご注意下さい。
Keras
# 学習曲線 (損失関数値)
plt.figure(figsize=(8,6))
plt.plot(history.history['val_loss'],label='adam', lw=3, c='b')
plt.title('学習曲線 (損失関数値)')
plt.xticks(size=14)
plt.yticks(size=14)
plt.grid(lw=2)
plt.legend(fontsize=14)
plt.show()
# 学習曲線 (精度)
plt.figure(figsize=(8,6))
plt.plot(history.history['val_accuracy'],label='adam', lw=3, c='b')
plt.title('学習曲線 (精度)')
plt.xticks(size=14)
plt.yticks(size=14)
plt.grid(lw=2)
plt.legend(fontsize=14)
plt.show()
PyTorch
# 学習曲線 (損失関数値)
plt.figure(figsize=(8,6))
plt.plot(val_loss_list,label='adam', lw=3, c='b')
plt.title('学習曲線 (損失関数値)')
plt.xticks(size=14)
plt.yticks(size=14)
plt.grid(lw=2)
plt.legend(fontsize=14)
plt.show()
# 学習曲線 (精度)
plt.figure(figsize=(8,6))
plt.plot(val_acc_list,label='adam', lw=3, c='b')
plt.title('学習曲線 (精度)')
plt.xticks(size=14)
plt.yticks(size=14)
plt.grid(lw=2)
plt.legend(fontsize=14)
plt.show()
参考文献
PyTorchニューラルネットワーク 実装ハンドブック
宮本圭一郎 (著), 大川洋平 (著), 毛利拓也 (著)
秀和システム
2021-10-10 追記
ここで説明したノウハウを含めてPyTorchの書籍を出版しました。
紹介記事をqiitaに掲載しましたので、こちらもあわせてご参照いただけると幸いです。