はじめに
Watson Machine Learningの新機能のうち、HPO(Hyper Parameter Optimizer)機能を実装しているチュートリアルを試してみました。
例によってトラップがあちこちにあり、なかなかプログラムが流れなかったのですが、無事流れるようになったNotebookをこちらにアップしておきました。
HPO機能とは
Hyper Parameter Optimizerのことです。深層学習では数多くのパラメータがあり、この値を変えると性能が大きく変わることがあるのに、条件を変えてテストするのは相当大変です。Watson Machine LeaningではGPU環境で条件を変えたテストを行い、最適なパラメータ値を自動的に見つけてくれる機能を持っています。
サンプルアプリの概要
このサンプルアプリの流れは次のようになっています。
- COS(Cloud Object Storage)上にテスト用データの配置
- アプリケーションの登録(Keras/PythonのソースをZIPに固めてリポジトリにアップします)
- トレーニングの定義
- Experimentの定義 この中で、HPOの定義も行います
- Experimentの実行
- モニター
- テスト結果の確認
- WEBサービス化とテスト
それぞれのスクリプトは以下のようになっています。
COS上に入力bucketと出力bucketの定義
import ibm_boto3
from ibm_botocore.client import Config
import os
import json
import warnings
import time
# 個別に設定して下さい
# 前提として事前にCloud Object Storageでhmacキーを取得しておく必要があります
# 手順は例えば https://qiita.com/ishida330/items/b093439a1646eba0f7c6
# を参考にして下さい
cos_credentials = {
"apikey": "xxxxx",
"cos_hmac_keys": {
"access_key_id": "xxxxx",
"secret_access_key": "xxxxx"
},
"endpoints": "https://cos-service.bluemix.net/endpoints",
"iam_apikey_description": "Auto generated apikey during resource-key operation for Instance - crn:v1:bluemix:public:cloud-object-storage:global:a/0960d86217f3b669ae4408f3b4deaa08:38bc5a04-c294-44d0-93d3-57a963ea4f0d::",
"iam_apikey_name": "xxxxx",
"iam_role_crn": "crn:v1:bluemix:public:iam::::serviceRole:Writer",
"iam_serviceid_crn": "xxxxx",
"resource_instance_id": "xxxxx"
}
api_key = cos_credentials['apikey']
service_instance_id = cos_credentials['resource_instance_id']
auth_endpoint = 'https://iam.bluemix.net/oidc/token'
service_endpoint = 'https://s3-api.us-geo.objectstorage.softlayer.net'
cos = ibm_boto3.resource('s3',
ibm_api_key_id=api_key,
ibm_service_instance_id=service_instance_id,
ibm_auth_endpoint=auth_endpoint,
config=Config(signature_version='oauth'),
endpoint_url=service_endpoint)
# 入力bucketと出力bucketの定義
# 個別に行って下さい
# 最初の要素が入力bucket名、次の要素が出力bucket名でどちらも任意で
# いいのですが、グローバルでユニークである必要があります
# すでに作成済みのものであればそれを利用しますし、まだの場合は下記のコードで
# 自動的に作成されます
buckets = ['xxxxx', 'yyyyy']
for bucket in buckets:
if not cos.Bucket(bucket) in cos.buckets.all():
print('Creating bucket "{}"...'.format(bucket))
try:
cos.create_bucket(Bucket=bucket)
except ibm_boto3.exceptions.ibm_botocore.client.ClientError as e:
print('Error: {}.'.format(e.response['Error']['Message']))
print(list(cos.buckets.all()))
MNISTデータをCOSに配置
!pip install wget
link = 'https://s3.amazonaws.com/img-datasets/mnist.npz'
import wget, os
data_dir = 'MNIST_KERAS_DATA'
if not os.path.isdir(data_dir):
os.mkdir(data_dir)
if not os.path.isfile(os.path.join(data_dir, os.path.join(link.split('/')[-1]))):
wget.download(link, out=data_dir)
# データファイルを入力bucketにアップロードします
bucket_name = buckets[0]
bucket_obj = cos.Bucket(bucket_name)
for filename in os.listdir(data_dir):
with open(os.path.join(data_dir, filename), 'rb') as data:
bucket_obj.upload_file(os.path.join(data_dir, filename), filename)
print('{} is uploaded.'.format(filename))
# アップロードしたファイルの確認
for obj in bucket_obj.objects.all():
print('Object key: {}'.format(obj.key))
print('Object size (kb): {}'.format(obj.size/1024))
Watson Machine Learning管理クライアント
管理クライアントは、Watson MLとのやりとりを行うためのインスタンスで、一番最初に認証を取得してから、各種コントロールコマンドを発行します。
!rm -rf $PIP_BUILD/watson-machine-learning-client
!pip install --upgrade watson-machine-learning-client
import urllib3, requests, json, base64, time, os
warnings.filterwarnings('ignore')
# Watson Machine LearningのCredntial情報
# 個別に設定して下さい。
wml_credentials = {
"url": "https://ibm-watson-ml.mybluemix.net",
"username": "xxxxx",
"password": "xxxxx",
"instance_id": "xxxxx"
}
from watson_machine_learning_client import WatsonMachineLearningAPIClient
client = WatsonMachineLearningAPIClient(wml_credentials)
print(client.version)
Trainingの定義
# Authorの定義 個別に行って下さい
author_email = 'xxx@ibm.com'
model_definition_metadata = {
client.repository.DefinitionMetaNames.NAME: "MNIST-MLP",
client.repository.DefinitionMetaNames.AUTHOR_EMAIL: author_email,
client.repository.DefinitionMetaNames.FRAMEWORK_NAME: "tensorflow",
client.repository.DefinitionMetaNames.FRAMEWORK_VERSION: "1.5",
client.repository.DefinitionMetaNames.RUNTIME_NAME: "python",
client.repository.DefinitionMetaNames.RUNTIME_VERSION: "3.5",
client.repository.DefinitionMetaNames.EXECUTION_COMMAND: "python3 mnist_mlp.py"
}
# モデル定義 (Python/Kerasのコード)のダウンロード
# MNIST.zipにはmnist-nlp.pyとmninst-cnn.pyの2つのコードが含まれていますが、
# 以下のサンプルではmnist-nlp.pyのみを利用します
!rm -rf MNIST.zip
filename_mnist = 'MNIST.zip'
if os.path.isfile(filename_mnist):
!ls 'MNIST.zip'
else:
!wget https://github.com/pmservice/wml-sample-models/raw/master/keras/mnist/MNIST.zip
!ls 'MNIST.zip'
# リポジトリに定義ファイルの登録
definition_details = client.repository.store_definition(filename_mnist, model_definition_metadata)
definition_url = client.repository.get_definition_url(definition_details)
definition_uid = client.repository.get_definition_uid(definition_details)
print(definition_url)
# 定義ファイルの一覧
client.repository.list_definitions()
リポジトリ登録で使われるMNIST.zipファイルに関しては、すでに開発・テスト済みのものが、zipファイルに固められているというのが、前提となっています。
同じコーディングによるWatson MLの利用でもscikit-learnによる従来型機械学習の場合、pythonプログラム内で、学習、評価済みのモデルそのものが登録できるのに対して1段階余分に入るところが、まだ発展途上な感じです。
参考までに、このzipファイルをダウンロード・解凍して得られる元のソースも添付しておきます。
import keras
import json
import os.path
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
import os
from os import environ
from keras.callbacks import TensorBoard
from emetrics import EMetrics
###############################################################################
# Set up working directories for data, model and logs.
###############################################################################
model_filename = "mnist_cnn.h5"
# writing the train model and getting input data
if environ.get('RESULT_DIR') is not None:
output_model_folder = os.path.join(os.environ["RESULT_DIR"], "model")
output_model_path = os.path.join(output_model_folder, model_filename)
else:
output_model_folder = "model"
output_model_path = os.path.join("model", model_filename)
os.makedirs(output_model_folder, exist_ok=True)
# writing metrics
if environ.get('JOB_STATE_DIR') is not None:
tb_directory = os.path.join(os.environ["JOB_STATE_DIR"], "logs", "tb", "test")
else:
tb_directory = os.path.join("logs", "tb", "test")
os.makedirs(tb_directory, exist_ok=True)
tensorboard = TensorBoard(log_dir=tb_directory)
###############################################################################
###############################################################################
# Set up HPO.
###############################################################################
config_file = "config.json"
if os.path.exists(config_file):
with open(config_file, 'r') as f:
json_obj = json.load(f)
learning_rate = json_obj["learning_rate"]
else:
learning_rate = 0.001
def getCurrentSubID():
if "SUBID" in os.environ:
return os.environ["SUBID"]
else:
return None
class HPOMetrics(keras.callbacks.Callback):
def __init__(self):
self.emetrics = EMetrics.open(getCurrentSubID())
def on_epoch_end(self, epoch, logs={}):
train_results = {}
test_results = {}
for key, value in logs.items():
if 'val_' in key:
test_results.update({key: value})
else:
train_results.update({key: value})
print('EPOCH ' + str(epoch))
self.emetrics.record("train", epoch, train_results)
self.emetrics.record(EMetrics.TEST_GROUP, epoch, test_results)
def close(self):
self.emetrics.close()
###############################################################################
batch_size = 128
num_classes = 10
epochs = 4
# the data, split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
model = Sequential()
model.add(Dense(512, activation='relu', input_shape=(784,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(num_classes, activation='softmax'))
model.summary()
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(lr=learning_rate),
metrics=['accuracy'])
hpo = HPOMetrics()
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_test, y_test),
callbacks=[tensorboard, hpo])
hpo.close()
print("Training history:" + str(history.history))
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
# save the model
model.save(output_model_path)
Experimentの定義
Trainingを定義した後は、このTrainingを参照する形でExperimentの定義を行います。
具体的なコードは以下のとおりです。
# サポートしている項目の一覧表示
client.repository.ExperimentMetaNames.show()
# 学習時の入力用bucketの定義
TRAINING_DATA_REFERENCE = {
"connection": {
"endpoint_url": service_endpoint,
"aws_access_key_id": cos_credentials['cos_hmac_keys']['access_key_id'],
"aws_secret_access_key": cos_credentials['cos_hmac_keys']['secret_access_key']
},
"source": {
"bucket": buckets[0],
},
"type": "s3"
}
# 学習時の出力用bucketの定義
TRAINING_RESULTS_REFERENCE = {
"connection": {
"endpoint_url": service_endpoint,
"aws_access_key_id": cos_credentials['cos_hmac_keys']['access_key_id'],
"aws_secret_access_key": cos_credentials['cos_hmac_keys']['secret_access_key']
},
"target": {
"bucket": buckets[1],
},
"type": "s3"
}
# HPOパラメータの指定
# val_acc(検証データの認識率)を最大にしたいので、これをOptimizerのObjectiveにしています。
# num_optimizer_stepsで、どの程度細かくパラメータを変化させるかを指定します。
HPO = {
"method": {
"name": "rbfopt",
"parameters": [
client.experiments.HPOMethodParam("objective", "val_acc"),
client.experiments.HPOMethodParam("maximize_or_minimize", "maximize"),
client.experiments.HPOMethodParam("num_optimizer_steps", 3)
]
},
"hyper_parameters": [
client.experiments.HPOParameter('learning_rate', min=0.0001, max=0.001, step=0.0003)
]
}
# TRAINING_REFERENCESの定義で、前に定義したTRAININGの設定を参照します。
experiment_metadata = {
client.repository.ExperimentMetaNames.NAME: "MNIST experiment",
client.repository.ExperimentMetaNames.DESCRIPTION: "Best model for MNIST.",
client.repository.ExperimentMetaNames.AUTHOR_EMAIL: "akaishi@jp.ibm.com",
client.repository.ExperimentMetaNames.EVALUATION_METHOD: "multiclass",
client.repository.ExperimentMetaNames.EVALUATION_METRICS: ["val_acc"],
client.repository.ExperimentMetaNames.TRAINING_DATA_REFERENCE: TRAINING_DATA_REFERENCE,
client.repository.ExperimentMetaNames.TRAINING_RESULTS_REFERENCE: TRAINING_RESULTS_REFERENCE,
client.repository.ExperimentMetaNames.TRAINING_REFERENCES: [
{
"name": "MNIST_MLP",
"training_definition_url": definition_url,
"compute_configuration": {"name": "k80x2"},
"hyper_parameters_optimization": HPO
}],
}
# experimentをリポジトリに登録します
experiment_details = client.repository.store_experiment(meta_props=experiment_metadata)
experiment_uid = client.repository.get_experiment_uid(experiment_details)
print(experiment_uid)
# 登録済みexperimentsの一覧表示
client.repository.list_experiments()
experimentの実行
experiment_run_details = client.experiments.run(experiment_uid, asynchronous=True)
# experimentの状況確認
client.experiments.list_runs()
# experiment run_uidの取得
experiment_run_uid = client.experiments.get_run_uid(experiment_run_details)
print(experiment_run_uid)
# training run内の個別テスト結果の取得
client.experiments.list_training_runs(experiment_run_uid)
# 詳細結果の取得
experiment_run_details = client.experiments.get_run_details(experiment_run_uid)
# experiment実行状況の取得
client.experiments.get_status(experiment_run_uid)
# 詳細状況の取得
experiment_details = client.experiments.get_details(experiment_uid)
print(json.dumps(experiment_details, indent=2))
# training runs uidsの取得
experiment_run_details = client.experiments.get_run_details(experiment_run_uid)
training_run_uids = client.experiments.get_training_uids(experiment_run_details)
for i in training_run_uids:
print(i)
モニター機能
# experiment runのモニター
client.experiments.monitor_logs(experiment_run_uid)
# statusの確認
client.experiments.get_status(experiment_run_uid)['state']
性能の確認
!pip install cufflinks
# metricsの取得
metrics = client.experiments.get_latest_metrics(experiment_run_uid)
all_metrics = client.experiments.get_metrics(experiment_run_uid)
import sys
import pandas
import plotly.plotly as py
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
import cufflinks as cf
import plotly.graph_objs as go
init_notebook_mode(connected=True)
sys.path.append("".join([os.environ["HOME"]]))
# Pandasでmetricsの表示
import pandas as pd
metrics_df = pd.DataFrame(columns=['GUID', 'NAME', 'METRIC NAME', 'METRIC VALUE'])
for m in metrics:
for v in m['metrics']['values']:
metrics_df = metrics_df.append({'GUID': m['training_guid'], 'NAME': m['training_reference_name'], 'METRIC NAME': v['name'], 'METRIC VALUE': v['value']}, ignore_index=True)
metrics_df
# バーチャートでグラフ化
data = []
for i in list(pd.unique(metrics_df['METRIC NAME'])):
data.append(go.Bar(x=metrics_df[metrics_df['METRIC NAME'].isin([i])]['GUID'] + ' (' + metrics_df[metrics_df['METRIC NAME'].isin([i])]['NAME'] + ')', y=metrics_df[metrics_df['METRIC NAME'].isin([i])]['METRIC VALUE'], name=i))
layout = go.Layout(
barmode='group'
)
fig = go.Figure(data=data, layout=layout)
iplot(fig)
オンラインサービスのデプロイ
status = client.experiments.get_status(experiment_run_uid)
best_model_uid = status['best_results']['experiment_best_model']['training_guid']
best_model_name = status['best_results']['experiment_best_model']['training_reference_name']
print(best_model_uid + ' (' + best_model_name + ')')
saved_model_details = client.repository.store_model(best_model_uid, {'name': 'MNIST best model'})
model_guid = client.repository.get_model_uid(saved_model_details)
print("Saved model guid: " + model_guid)
client.repository.list_models()
deployment_details = client.deployments.create(name="MNIST keras deployment", model_uid=model_guid)
scoring_url = client.deployments.get_scoring_url(deployment_details)
print(scoring_url)
WEBサービスとして予測実行
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
for i, image in enumerate([x_test[0], x_test[1]]):
plt.subplot(2, 2, i + 1)
plt.axis('off')
plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
image_1 = x_test[0].ravel()
image_2 = x_test[1].ravel()
scoring_data = {'values': [image_1.tolist(), image_2.tolist()]}
predictions = client.deployments.score(scoring_url, scoring_data)
print("Scoring result: " + str(predictions))
Watson Studio UI側の状況
-
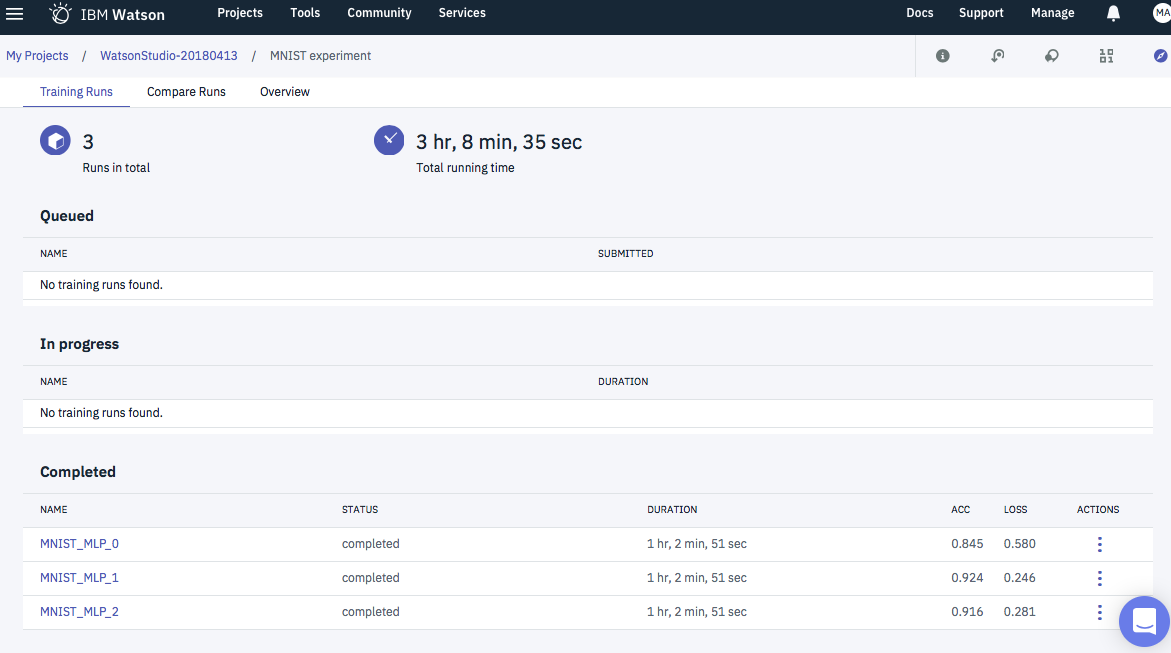
Training Runsタブ
-
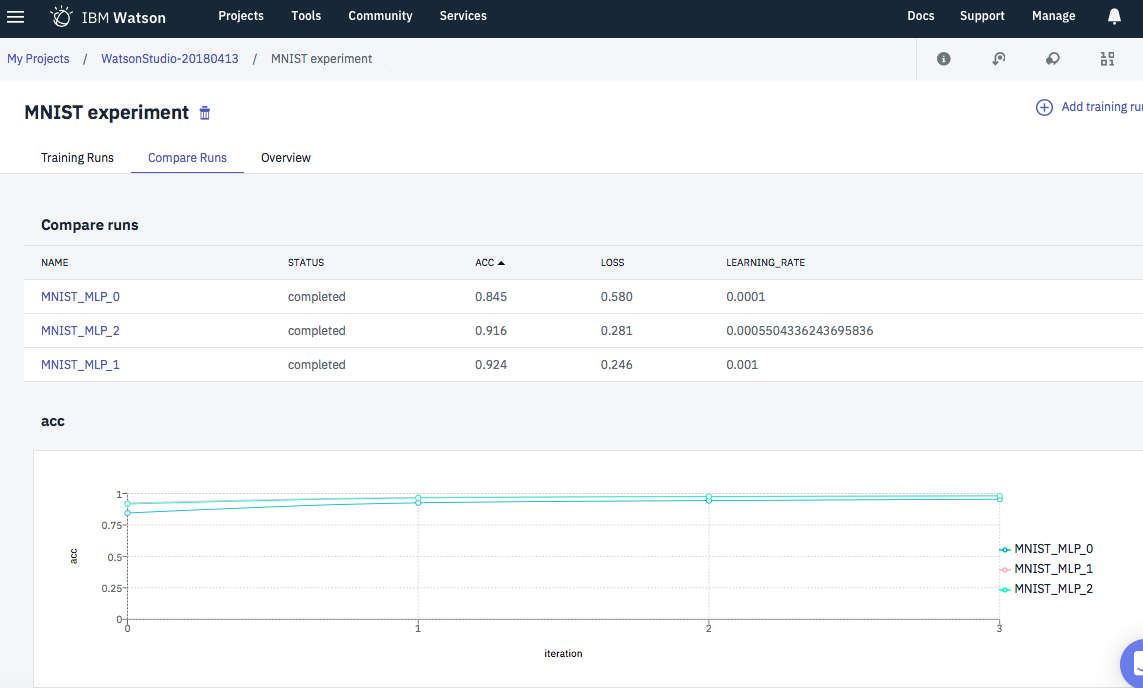
Common Runsタブ
-
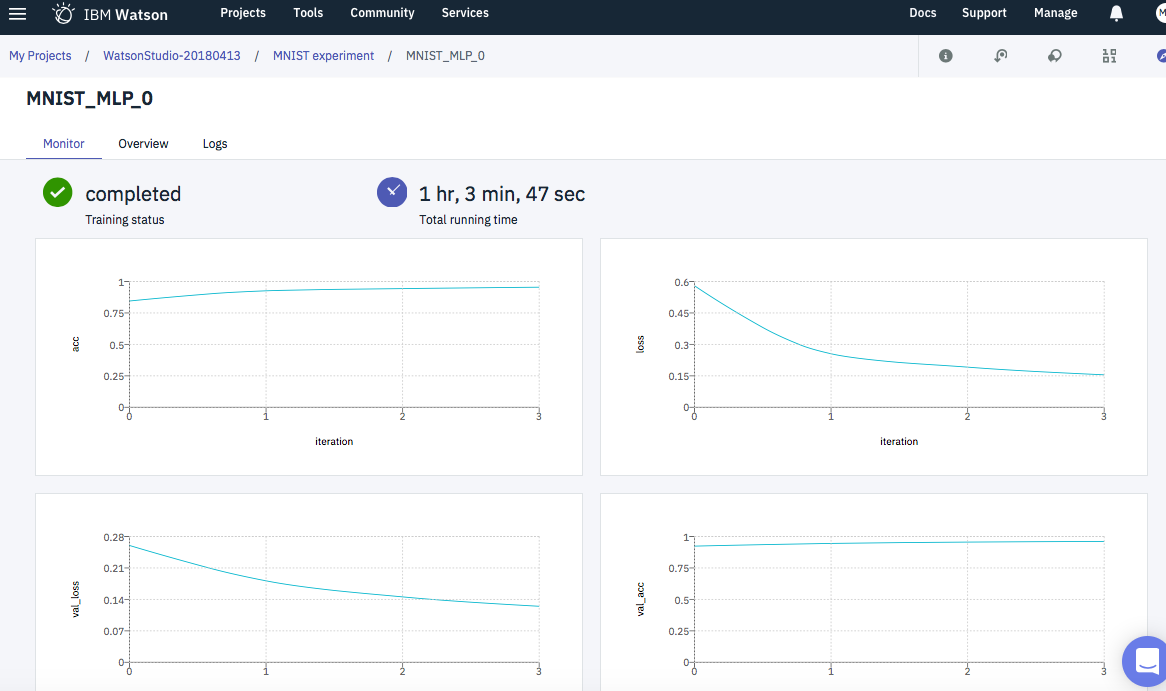
個別runのMonitorタブ
-
個別runのLogsタブ