前処理
データは1次元のデータ系列 (x, y) で、これが2次元の空間上に数千点分布している。
3次元からモデル関数で値を得て残差を返し、残差二乗和を最小とするモデル関数のパラメータを得たい。このfittingパラメータには大域的なものたかだか十数個と、空間上の各点ごとに決まる重要度の低いものに分けられる。後者についてもfitting対象とするならfittingパラメータの総数が数千になる。
これをTensorflowの機能で解いてみたい。
fitting対象は1次元で、1データたかだか数十点である。抽出の都合で、これが [(x1, y1), (x2, y2),..] の形でリスト化されており、これに抽出時に最高点で確認したピーク中心候補 [xc, yc] を頭につけて ([ピーク中心], [データ列]) の形でタプル化されている。拡張性のためにこのタプル任意個(1個以上)をさらにリストに束ねて、ある2次元の位置情報 (px, py) をヘッダとして付加してタプル化している。すなわち、((px, py), [([xc, yc], [data...])]) が1データ列であり、これが例えばあるデータについては3072個で1リストとなっている。
当面はこの3072点データをサンプルデータとして解析法を考えてみる。
参考までに、リストを dump した末尾を以下に載せる。
((47, 60), [([41790.0, 310.0], [(41734.0, 25.0), (41738.0, 42.0), (41742.0, 53.0), (41746.0, 76.0), (41750.0, 79.0), (41754.0, 114.0), (41758.0, 128.0), (41762.0, 162.0), (41766.0, 193.0), (41770.0, 191.0), (41774.0, 228.0), (41778.0, 233.0), (41782.0, 266.0), (41786.0, 287.0), (41790.0, 310.0), (41794.0, 294.0), (41798.0, 286.0), (41802.0, 308.0), (41806.0, 306.0), (41810.0, 305.0), (41814.0, 302.0), (41818.0, 259.0), (41822.0, 286.0), (41826.0, 259.0), (41830.0, 212.0), (41834.0, 230.0), (41838.0, 208.0), (41842.0, 186.0), (41846.0, 140.0)])]), ((47, 61), [([41806.0, 319.0], [(41750.0, 116.0), (41754.0, 132.0), (41758.0, 148.0), (41762.0, 168.0), (41766.0, 198.0), (41770.0, 201.0), (41774.0, 220.0), (41778.0, 279.0), (41782.0, 279.0), (41786.0, 272.0), (41790.0, 297.0), (41794.0, 288.0), (41798.0, 295.0), (41802.0, 315.0), (41806.0, 319.0), (41810.0, 291.0), (41814.0, 311.0), (41818.0, 253.0), (41822.0, 281.0), (41826.0, 228.0), (41830.0, 223.0), (41834.0, 189.0), (41838.0, 194.0), (41842.0, 121.0), (41846.0, 125.0), (41850.0, 132.0), (41854.0, 106.0), (41858.0, 67.0), (41862.0, 60.0)])]), ((47, 62), [([41794.0, 118.0], [(41738.0, 21.0), (41742.0, 23.0), (41746.0, 28.0), (41750.0, 29.0), (41754.0, 46.0), (41758.0, 53.0), (41762.0, 50.0), (41766.0, 64.0), (41770.0, 75.0), (41774.0, 84.0), (41778.0, 88.0), (41782.0, 93.0), (41786.0, 98.0), (41790.0, 106.0), (41794.0, 118.0), (41798.0, 112.0), (41802.0, 118.0), (41806.0, 88.0), (41810.0, 86.0), (41814.0, 107.0), (41818.0, 105.0), (41822.0, 76.0), (41826.0, 84.0), (41830.0, 84.0), (41834.0, 59.0), (41838.0, 54.0), (41842.0, 62.0), (41846.0, 49.0), (41850.0, 31.0)])]), ((47, 63), [([41810.0, 12.0], [(41754.0, 4.0), (41758.0, 5.0), (41762.0, 2.0), (41766.0, 7.0), (41770.0, 4.0), (41774.0, 8.0), (41778.0, 7.0), (41782.0, 6.0), (41786.0, 7.0), (41790.0, 9.0), (41794.0, 8.0), (41798.0, 6.0), (41802.0, 11.0), (41806.0, 6.0), (41810.0, 12.0), (41814.0, 7.0), (41818.0, 7.0), (41822.0, 4.0), (41826.0, 8.0), (41830.0, 11.0), (41834.0, 6.0), (41838.0, 9.0), (41842.0, 5.0), (41846.0, 6.0), (41850.0, 5.0), (41854.0, 2.0), (41858.0, 2.0), (41862.0, 4.0), (41866.0, 2.0)])])]
まず最初に、この pickle から読み込まれたデータを numpy の適当な行列に変換する。
これは Spark でやってみる。pickleからloadしてすぐRDDとしたものを以下のように変換する。
データの都合で、 fitting 対象とする数列が拾えない箇所があり、そのような場所では空のリストが渡ってくる。これをそのままにしておくと leastsq の際にエラーとなるので RDD 上で変換の際に filter する。
>>> import pickle
>>> import numpy as np
>>> R=pickle.load(f)
>>> RDD=sc.parallelize(R)
>>> RDD.take(1)
>>> 2017-04-01 15:13:01,949 WARN [dispatcher-event-loop-4] scheduler.TaskSetManager (Logging.scala:logWarning(66)) - Stage 0 contains a task of very large size (307 KB). The maximum recommended task size is 100 KB.
[((0, 0), [([44050.0, 2.0], [(43990.0, 0.0), (43994.0, 0.0), (43998.0, 0.0), (44002.0, 0.0), (44006.0, 0.0), (44010.0, 0.0), (44014.0, 0.0), (44018.0, 0.0), (44022.0, 0.0), (44026.0, 0.0), (44030.0, 1.0), (44034.0, 1.0), (44038.0, 1.0), (44042.0, 0.0), (44046.0, 0.0), (44050.0, 2.0), (44054.0, 0.0), (44058.0, 1.0), (44062.0, 2.0), (44066.0, 0.0), (44070.0, 1.0), (44074.0, 0.0), (44078.0, 0.0), (44082.0, 1.0), (44086.0, 0.0), (44090.0, 0.0), (44094.0, 0.0), (44098.0, 0.0), (44102.0, 0.0), (44106.0, 0.0), (44110.0, 1.0)])])]
>>> R2=RDD.filter(lambda l: l[1]!=[[]]).map(lambda l: (l[0], l[1][0][0], np.array(l[1][0][1]).T))
>>> R2.take(1)
>>> 2017-04-01 15:13:28,573 WARN [dispatcher-event-loop-4] scheduler.TaskSetManager (Logging.scala:logWarning(66)) - Stage 1 contains a task of very large size (307 KB). The maximum recommended task size is 100 KB.
[((0, 0), [44050.0, 2.0], array([[ 4.39900000e+04, 4.39940000e+04, 4.39980000e+04,
4.40020000e+04, 4.40060000e+04, 4.40100000e+04,
4.40140000e+04, 4.40180000e+04, 4.40220000e+04,
4.40260000e+04, 4.40300000e+04, 4.40340000e+04,
4.40380000e+04, 4.40420000e+04, 4.40460000e+04,
4.40500000e+04, 4.40540000e+04, 4.40580000e+04,
4.40620000e+04, 4.40660000e+04, 4.40700000e+04,
4.40740000e+04, 4.40780000e+04, 4.40820000e+04,
4.40860000e+04, 4.40900000e+04, 4.40940000e+04,
4.40980000e+04, 4.41020000e+04, 4.41060000e+04,
4.41100000e+04],
[ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 1.00000000e+00, 1.00000000e+00,
1.00000000e+00, 0.00000000e+00, 0.00000000e+00,
2.00000000e+00, 0.00000000e+00, 1.00000000e+00,
2.00000000e+00, 0.00000000e+00, 1.00000000e+00,
0.00000000e+00, 0.00000000e+00, 1.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
1.00000000e+00]]))]
fitting ステージ1
1段目の処理としてこれを Lorentz 関数で fitting する。 Lorentz 関数や Gauss 関数で fit する時は fitting parameter が3つ必要になる。 peak 中心、高さ、半値幅である。中心、高さの初期値は抽出時に得ていたものをこれに使うが(変換したRDDの2項目目)、半値幅はないので計算で出す。この問題のケースでは、ある仮定のもとに、
fwhm=peaks*res/(2*math.sqrt(math.sqrt(2.0)-1))
としていた。
fitting 用の残差関数を以下のように定義しておく。
def lor2Fit(parameters, x, y):
p0, p1, p2= parameters
P = (p2 * (1/(1+((x-p0)/p1)**2.0))**2.0 )
return y-P
fwhm を計算し、それを初期値として与えて個別に scipy で最小二乗法fittingしてみる。
>>> import math
>>> from scipy.optimize import leastsq
>>> R3=R2.map(lambda l: (l[0], (l[1][0], (l[1][0]*res/(2*math.sqrt(math.sqrt(2.0)-1))), l[1][1]), l[2]))
>>> R4=R3.map(lambda l: (l[0], leastsq(lor2Fit, np.array(l[1]), args=(l[2][0],l[2][1]))))
>>> R4.take(3)
>>> 2017-04-01 15:16:56,227 WARN [dispatcher-event-loop-2] scheduler.TaskSetManager (Logging.scala:logWarning(66)) - Stage 3 contains a task of very large size (307 KB). The maximum recommended task size is 100 KB.
[((0, 0), (array([ 4.40547959e+04, 3.07846553e+01, 9.45295878e-01]), 1)), ((0, 1), (array([ 4.40470300e+04, 4.83602971e+01, 5.41476541e+00]), 1)), ((0, 2), (array([ 4.40379737e+04, 4.40231770e+01, 7.67038928e+01]), 1))]
fitting失敗のケースでは各最後の項が5になる。そのようなケースを潰す処理をいれて以下のように peak 中心だけ抽出する。
描画用に、 fitting を省いた領域も復活させた RDD を作成する。
値が 0 の RDD を作って outer join して None は 0 で抽出して値の map を作る。
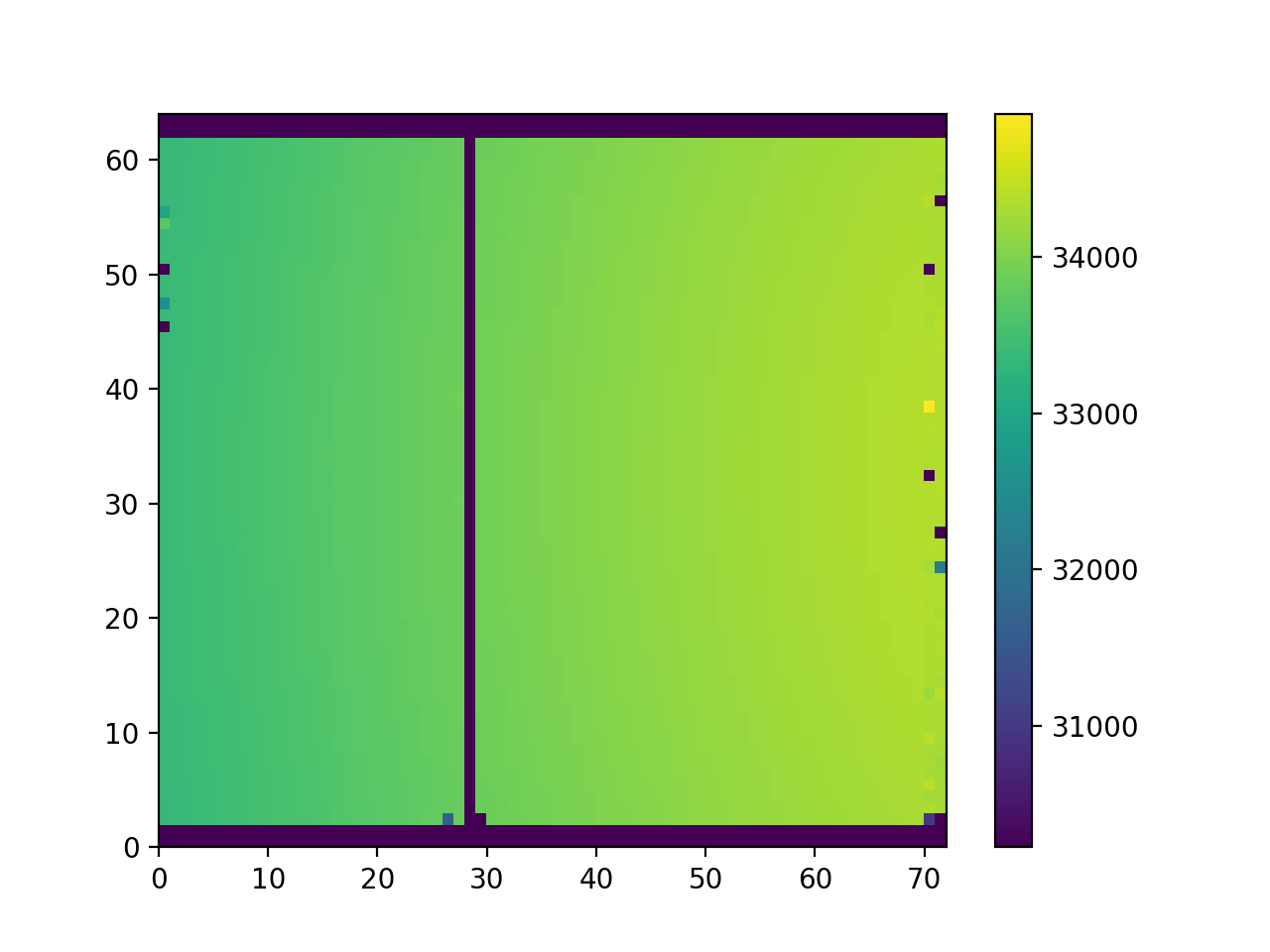
これをこのまま pyplot.pcolormap() で plot すると色範囲が 0 にまで及び、値の区別がつかなくなる。
そこで有効な値の最小値を vmin として pcolormap() に渡してやるわけだが、この値は RDD の min() で分散状態で求める。
>>> R5=R4.map(lambda l: (l[0], l[1][0][0]) if l[1][1]<5 else (l[0], 0))
>>> RX = RDD.map(lambda l: (l[0], 0)).leftOuterJoin(R5)
>>> RX2=RX.map(lambda l: (l[0], l[1][1]) if l[1][1]!=None else (l[0], 0)).sortByKey()
>>> #print(RX2.collect())
>>> RXV = RX2.values().filter(lambda l: l>0)
>>> pyplot.pcolormesh(np.reshape(np.array(RX2.values().collect()), [72, 64]).T, vmin=RXV.min())
>>> <matplotlib.collections.QuadMesh object at 0x1097b7898>
>>> pyplot.colorbar()
>>> <matplotlib.colorbar.Colorbar object at 0x10a5db048>
>>> pyplot.show()