Puppeteerでページの必要な部分だけをブラウザ上でクリック選択して登録、定期的なスクレイピングするツールを作っていきます(1)
初投稿します。majirouと申します。
開発過程の備忘録と共にどういった考えで作っていったかを記載します。
本稿では、puppeteerで対象URLを取得するまでを記載し、残りは随時別途まとめていきます。
概要
- タイトルの通り、ブラウザ上で対象サイトの必要な箇所だけを定期的に取得するブラウザアプリです。
- 画面上の操作しかできない、ガンガンHTML書けない or むしろ苦手な方々が、直感的に操作できることを目指します。
- 上記を実現するために、一度対象サイトをスクレイピングし、その結果をiframeで呼び出すことで実現をします。
- 最終的には、対象ページをDB管理し、世代管理を行い、前回の結果との差分を取得していき通知するまでを目標とします。
- 部分的な取得をする理由は、上記差分をとった際、ページ全体を対象とすると、小さな修正も差分と認識することを避けるためです。
- イメージとしては、「お知らせ欄だけ取得して差分があったら教えて!」というものです。
- なお、筆者はJqueryで時が止まっていたので、最近のJavaScriptに疎い状況を打破するために勉強がてら着手しています。
構成
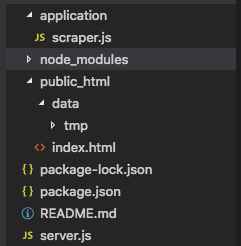
- application配下に、メイン処理を行うJS
- スクレイピング結果をpublic_html/data/tmp配下に設置し、iframeで読込
- HTTPサーバーは express
Puppeteer インストール
公式の通りとします。
npm i puppeteer
実装
スクレイピング処理クラス application/scraper.js
- 本アプリのメイン処理を行います。
- puppeteer を呼び出し、対象URLのHTMLを取得します。
- scriptタグは iframe内で呼び出した時に邪魔にならないように削除しておきます。
class Scraper {
constructor(){
console.log("constructed");
this.fs = require('fs');
}
createTemporaryDir(){
// 実行した日時をディレクトリ名にして作成
const dt = new Date();
this.save_dir_name = dt.getFullYear()
+ ("00" + (dt.getMonth()+1)).slice(-2)
+ ("00" + dt.getDate() ).slice(-2)
+ ("00" + dt.getHours() ).slice(-2)
+ ("00" + dt.getMinutes() ).slice(-2)
+ ("00" + dt.getSeconds() ).slice(-2)
;
console.log( this.save_dir_name ) ;
this.save_path = "./public_html/data/tmp/" + this.save_dir_name ;
this.fs.mkdir( this.save_path , function (err) {
if( err ) { console.log( err ) } ;
});
}
async scrape( url ){
const pptr = require('puppeteer');
this.createTemporaryDir();
console.log( process.cwd(),"mkdir " + this.save_path ) ;
const browser = await pptr.launch( {
args: [ '--lang=ja,en-US,en'
, '--no-sandbox'
, '--disable-setuid-sandbox'
]
} ) ;
try{
console.log("START");
const page = await browser.newPage();
// 画面サイズ
await page.setViewport({ width: 1024, height: 800 });
// ページ移動
await page.goto( url );
// ページタイトル取得
console.log(await page.title());
// スクリーンショット
await page.screenshot({ path: this.save_path + '/screenshot.png', fullPage: true } ) ;
//
var html = await page.evaluate(()=>{
const html = document.getElementsByTagName('html')[0] ;
// script タグを削除(理由:動的な部分は本スクレイピングでは無視する)
const script = html.getElementsByTagName("script") ;
// 削除なので逆から行う
for( let i=(script.length-1) ; i >= 0 ; i-- ) {
script[i].parentNode.removeChild( script[i] ) ;
}
return html.innerHTML;
});
await this.fs.writeFileSync( this.save_path+'/index.html', html);
}catch( err ) {
console.log( "ERROR" , err);
}finally{
// 終了
console.log("END");
await browser.close();
}
}
}
module.exports = new Scraper();
フロント
- とりあえず動かせるものでいいので、bootstrapとvueで簡易的な画面を作ります。
- URLを入力すると、先ほどのScraperクラスが動くAPIへ投げ込みます。
- スクレイピングした結果(保存先)のディレクトリを返すのでそれをiframeのsrcに当てて読み込みます。
<html>
<head>
<script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js"></script>
<script src="https://unpkg.com/axios/dist/axios.min.js"></script>
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.1.3/css/bootstrap.min.css" integrity="sha384-MCw98/SFnGE8fJT3GXwEOngsV7Zt27NXFoaoApmYm81iuXoPkFOJwJ8ERdknLPMO" crossorigin="anonymous">
</head>
<body>
<main id="app" class="container">
<h1>{{title}}</h1>
<div class="input-group mb-3">
<input type="text" class="form-control" placeholder="URL" v-model="url">
<div class="input-group-append">
<button class="btn btn-primary" @click="getTargetSite()">取得</button>
</div>
</div>
<div>
<iframe class="w-100 h-75 border border-info rounded" id="crawled-result" :src="iframeSource"></iframe>
</div>
</main>
</body>
<script>
var app = new Vue(
{
el:"#app",
data:{
title: "ウェブページを取得するフォーム" ,
url: null ,
apiUrlTriger: '/scrape' ,
iframeSource: null
} ,
methods:{
getTargetSite: function(){
// data.url に対してクロールを実行する。
var reg = new RegExp( "((https?|ftp)(:\/\/[-_.!~*\'()a-zA-Z0-9;\/?:\@&=+\$,%#]+))");
if( this.url && this.url.match( reg ) ){
const targetUrl = this.apiUrlTriger + "?url="+this.url ;
axios.get( targetUrl )
.then( ( res )=>{
// handle success
console.log( res ) ;
if( res.status === 200 ){
// 保存したディレクトリ名が返ってくるのでそれをiframe.srcとして格納→読込
this.iframeSource = "/data/tmp/" + res.data.result ;
}else{
throw new Exception("error") ;
}
} )
.catch( ( err )=>{
// handle error
console.log( err ) ;
} ) ;
}
return null ;
},
} ,
}
) ;
</script>
</html>
サーバー server.js
- expressサーバーで動かします。
'use strict';
const express = require('express');
const app = express();
app.use(express.static('./public_html/'));
app.listen( 8001 , () => {
console.log('Express Server listened 8001');
} ) ;
app.get( '/scrape' , function( req, res ) {
// URLパラメタが空でなければ画面に表示
let url = null ;
if ( req.query.url ) {
url = req.query.url ;
var s = require( './application/scraper' );
( async () => {
await s.scrape( req.query.url );
res.send( { url: url , result: s.save_dir_name } ) ;
} )();
}
} )
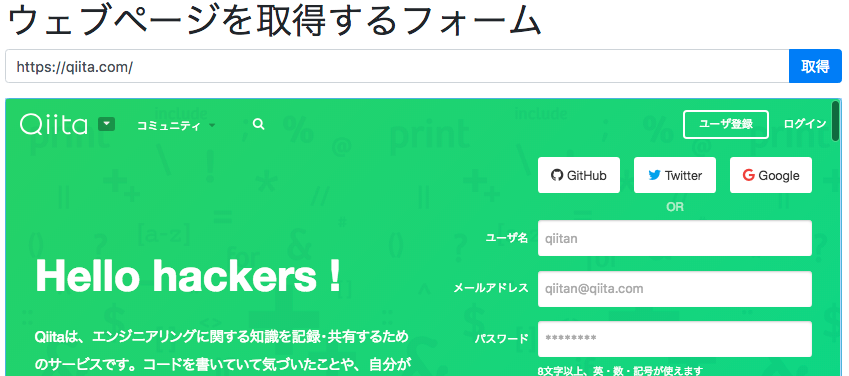
動作確認
- qiita のトップページを読み込んでみます。
現時点での問題点・課題点
- CSSや画像などをダウンロードしていないので、相手のサーバーに読み込みにいったりするので、これらもローカルに保存するようにする
- iframeで読み込んだページに、クリックイベントリスナーを施してページの部分的な取得をしたい箇所を検知できるようにする
- 上記、URLと取得箇所をDBに保存し管理する
- 2回以上のスクレイピング結果がある場合は差分(テキストや画像)があるかを判断し、メール通知を行う。
最後に
まずは、対象ページを取得し、保存するまで漕ぎ着きました。
最初にも書きましたが、私の知識がjqueryで止まっていたので、サーバーサイドでjavascriptを書いて動かすことが不思議で、未だ不慣れな点が多く四苦八苦していますが、最後まで作り終えたいと思います。
次回以降の予定は
- iframe内でのクリックの検知と、それらの保存
- スクレイピング結果の差分と通知