前回のおさらい
前回の記事インデックとは①の続きです。
前回行ったときは社員テーブルに登録されている件数が少なかったので、レコードを10000件ほど増やして、再度実行してみました。
Shainテーブル
| NO | Name | Age |
|---|---|---|
| 1 | Ooi | 48 |
| 2 | Ubukata | 35 |
| 3 | Kato | 20 |
| 4 | Mano | 28 |
| 5 | Endou | 38 |
| 6 | Wtarai | 40 |
| ・・・ |
--使用するインデックス
Create INDEX TR_Name
ON Shain(Name)
--実行するSelect文
SELECT *
FROM Shain
WHERE Name = 'Endou'
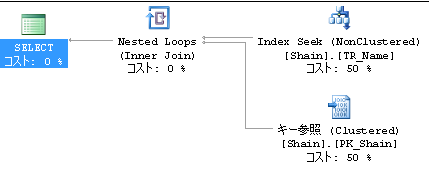
実行プラン
処理イメージ
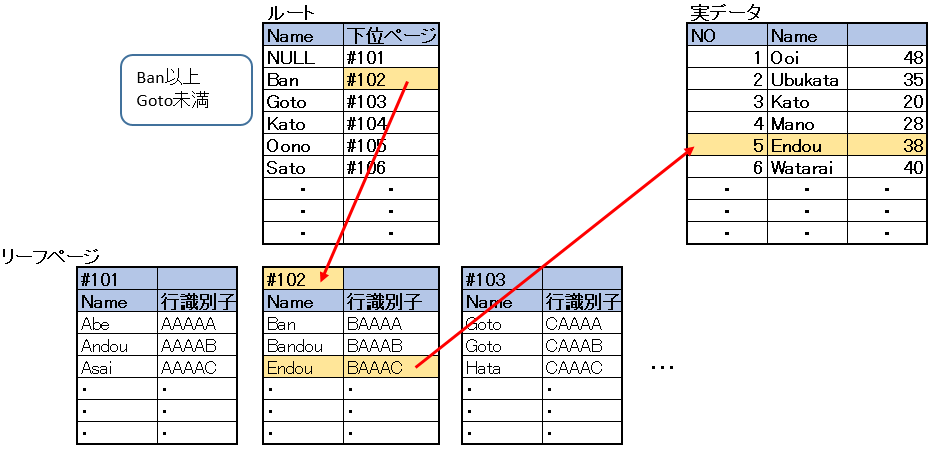
前回と結果が違うことがわかると思います。
オプティマイザが判断し、このレコード数なら全件走査したほうが早いと判断したため前回の結果となっていました。
今回はレコード数が増えたためまず設定したインデックスを利用して、キーを特定、その後クラスタ化インデックスにより該当レコードの取得を行ったことになります。
こうなってしまうと、検索に掛ける手間が1つ増え、データの数によっては処理速度の低下につながります。
インデックスの種類
カバリングインデックス
カバリング インデックス(Covering Index)は、非クラスター化インデックスのリーフレベルへ検索で取得したいデータを格納して、キー参照(または RID Lookup)を行うことなく、Index Seekのみで完了するインデックスです。
インデックスの設定
Create INDEX TR_Name
ON Shain(Name, Age)
SELECT Age
FROM Shain
WHERE Name = 'Endou'
実行プラン
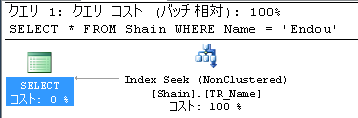
一回の操作で対象データを取得することが出来ました。
処理イメージ
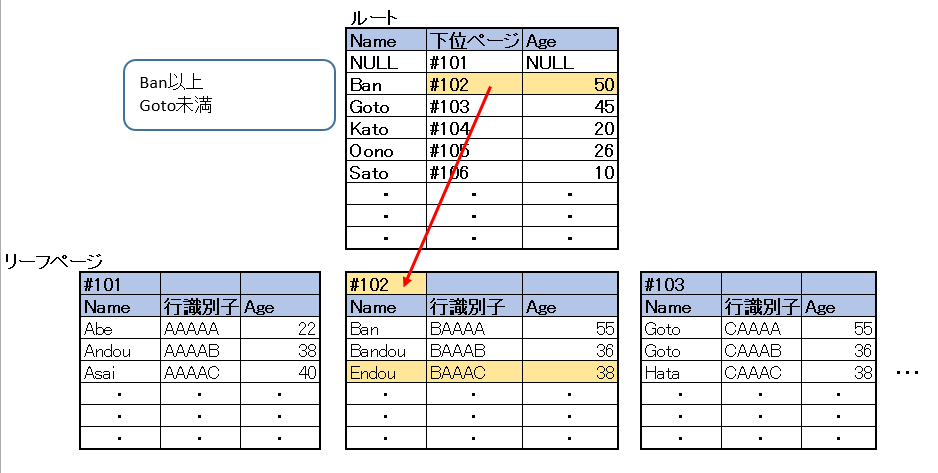
各ページにAgeの情報が追加されたため、一回の走査で取得が可能になったことがわかると思います。
カバリングインデックスの注意点
①検索の対象は一番左に設定した列が優先されるため、Where句の順番に気を付ける必要がある。
②ルートページやリーフページ(実際には中間ページも)に列が追加されるので、余計に領域を圧迫していしまう
付加列インデックス
付加列インデックスは、「Include オプション」とも呼ばれ、インデックスのリーフ レベルへ指定した列を含める(Include する)ことができるインデックス。
カバリングインデックスとの違いは、リーフページのみ列を追加するので、必要領域が小さくて済みます。
Create INDEX TR_Name
ON Shain(Name)
INCLUDE (Age)
SELECT Age
FROM Shain
WHERE Name = 'Endou'
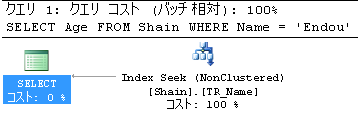
同じ結果が得られるので、付加列インデックスを採用する方がよい!
更新時の注意
ここまでインデックスについて説明してきました。
めっちゃ便利!最高!どんどんインデックスを作成しよう!
となりそうですが、そうでもないです。
前述した通り、インデックスも領域を圧迫しますし、更新時の処理負荷を上げてしまいます。
カバリングインデックスや付加列インデックスはインデックスのページにも列を持っています。
つまりその列の値が更新されれば、インデックスの負荷列も更新する必要があります。
従って、インデックスは必要なものを最低限作成する必要があります。
おわりに
ここまでまとめてきましたが、正直ここまではわかるんだけど・・・・って思われる方も多いと思います。
実際には、必要なインデックスを作成しても、オプティマイザによって別のインデックスを利用するようになっていたり、こっちのパフォーマンスは改善したけど、こっちは遅くなった!なんてこともたくさんありますよね。
こればっかりは常に立ち向かっていくしかないと思ってます。
俺たちの戦いは続く・・・・てきな