Hadoop と RDB でどれくらい処理時間に差が出るか手元で検証してみたかったので Python で Big Data を自作しました。
データ構成
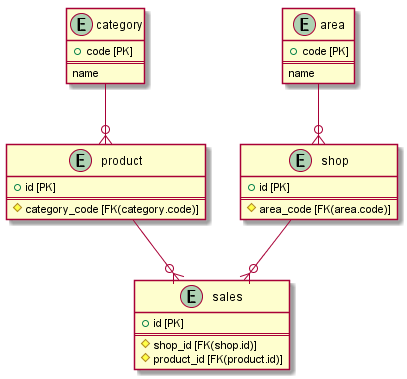
| テーブル | 説明 |
|---|---|
| 売上 | 100,000,000 件の売上明細。 |
| 店舗 | 1,000,000 件の店舗。 |
| エリア | 1,000 件の店舗エリア。 |
| 商品 | 10,000,000 件の商品。 |
| 分類 | 10,000 件の商品分類。 |
Big Data 生成
$ cd ~
$ ls
generate_big_data.py
$ sudo apt install python3 -y
$ python3 generate_big_data.py
$ du -h ./*
184K /home/vagrant/category.csv
8.0K /home/vagrant/generate_big_data.py
122M /home/vagrant/product.csv
3.8G /home/vagrant/sales.csv
11M /home/vagrant/shop.csv
プログラム
一定の件数ごとにファイルに吐き出すようにし OOM にならないようにしました。
import random
import datetime
import time
# 店舗数: 1,000,000
SHOP_CNT = 1000000
# エリア数: 1,000
AREA_CNT = 1000
# 商品数: 10,000,000
PRODCUT_CNT = 10000000
# 商品区分: 10,000
CATEGORY_CNT = 10000
# 売上数: 100,000,000
SALES_CNT = 100000000
# 最大価格: 100,000
PRICE_MAX = 100000
# 最大購入数: 100
COUNT_MAX = 100
SHOP_DST = 'shop.csv'
AREA_DST = 'area.txt'
PRODUCT_DST = 'product.csv'
CATEGORY_DST = 'category.csv'
SALES_DST = 'sales.csv'
# Table: shop
# Column: id,area_code
# id: 1 - 1,000,000
# area_code: 1 - 1,000
print('{} start: generate shop csv'.format(datetime.datetime.now().strftime('%Y/%m/%d %H:%M:%S')))
start = time.time()
rows = []
# header
# rows.append('id,area_code\n')
for i in range(SHOP_CNT):
shop_id = str(i + 1)
area_code = str(random.randrange(1, AREA_CNT, 1))
rows.append('{},{}\n'.format(shop_id, area_code))
# 100,000 件ごとに出力する
if((i + 1) % 100000 == 0):
cnt = i + 1
print('shop rows: {}'.format(cnt))
with open(SHOP_DST, 'a', encoding='utf-8') as f:
f.writelines(rows)
rows = []
elapsed_time = time.time() - start
print('{} finish: generate shop csv({} sec)'.format(datetime.datetime.now().strftime('%Y/%m/%d %H:%M:%S'), elapsed_time))
# Table: area
# Column: area_code,area_name
# area_code: 1 - 1,000
# area_name: area_0 - area_1000
print('{} start: generate area csv'.format(datetime.datetime.now().strftime('%Y/%m/%d %H:%M:%S')))
start = time.time()
rows = []
# header
# rows.append('area_code,area_name\n')
for i in range(AREA_CNT):
area_code = str(i + 1)
area_name = 'area_' + str(i + 1)
rows.append('{},{}\n'.format(area_code, area_name))
# 100 件ごとに出力する
if((i + 1) % 100 == 0):
cnt = i + 1
print('area rows: {}'.format(cnt))
with open(AREA_DST, 'a', encoding='utf-8') as f:
f.writelines(rows)
rows = []
elapsed_time = time.time() - start
print('{} finish: generate area csv({} sec)'.format(datetime.datetime.now().strftime('%Y/%m/%d %H:%M:%S'), elapsed_time))
# Table: product
# Column: id,category_code
# id: 1 - 10,000,000
# category_code: 1 - 10,000
print('{} start: generate product csv'.format(datetime.datetime.now().strftime('%Y/%m/%d %H:%M:%S')))
start = time.time()
rows = []
# header
# rows.append('id,category_code\n')
for i in range(PRODCUT_CNT):
product_id = str(i + 1)
category_code = str(random.randrange(1, CATEGORY_CNT, 1))
rows.append('{},{}\n'.format(product_id, category_code))
# 1,000,000 件ごとに出力する
if((i + 1) % 1000000 == 0):
cnt = i + 1
print('product rows: {}'.format(cnt))
with open(PRODUCT_DST, 'a', encoding='utf-8') as f:
f.writelines(rows)
rows = []
elapsed_time = time.time() - start
print('{} finish: generate product csv({} sec)'.format(datetime.datetime.now().strftime('%Y/%m/%d %H:%M:%S'), elapsed_time))
# Table: category
# Column: category_code,name
# category_code: 1 - 10,000
# name: category_1 - category_10000
print('{} start: generate category csv'.format(datetime.datetime.now().strftime('%Y/%m/%d %H:%M:%S')))
start = time.time()
rows = []
# header
# rows.append('id,name\n')
for i in range(CATEGORY_CNT):
category_code = str(i + 1)
category_name = 'category_' + str(i + 1)
rows.append('{},{}\n'.format(category_code, category_name))
# 1,000 件ごとに出力する
if((i + 1) % 1000 == 0):
cnt = i + 1
print('category rows: {}'.format(cnt))
with open(CATEGORY_DST, 'a', encoding='utf-8') as f:
f.writelines(rows)
rows = []
elapsed_time = time.time() - start
print('{} finish: generate category csv({} sec)'.format(datetime.datetime.now().strftime('%Y/%m/%d %H:%M:%S'), elapsed_time))
# Table: sales
# Column: id,shop_id,product_id,price,count,total_price
# id: 1 - 10,000,000
print('{} start: generate sales csv'.format(datetime.datetime.now().strftime('%Y/%m/%d %H:%M:%S')))
start = time.time()
rows = []
# header
# rows.append('id,shop_id,product_id,price,count,total_price\n')
cnt = 0
for i in range(SALES_CNT):
sales_id = str(i + 1)
shop_id = str(random.randrange(1, SHOP_CNT, 1))
product_id = str(random.randrange(1, PRODCUT_CNT, 1))
price = str(random.randrange(1, PRICE_MAX, 10))
count = str(random.randrange(1, COUNT_MAX, 1))
total_price = str(int(price) * int(count))
rows.append('{},{},{},{},{},{}\n'.format(sales_id, shop_id, product_id, price, count, total_price))
# 10,000,000 件ごとに出力する
if((i + 1) % 10000000 == 0):
cnt = i + 1
print('sales rows: {}'.format(cnt))
with open(SALES_DST, 'a', encoding='utf-8') as f:
f.writelines(rows)
rows = []
elapsed_time = time.time() - start
print('{} finish: generate sales csv({} sec)'.format(datetime.datetime.now().strftime('%Y/%m/%d %H:%M:%S'), elapsed_time))