はじめに
Optunaを使用してScikit-learn、Kerasのパラメータチューニングを行ってみました。使用したデータは2001年以降の日経平均株価で、ハイパーパラメータをチューニングしたとき、しないときでのリターンがどのように変化するかを比較しています。
※Optunaは、Preferred Networks社が開発しているハイパーパラメータを最適化するためのフレームワークです。
日経平均株価の取得
まずは日経平均株価を取得します。2022年12月からpandas_datareaderで株価が取得できなくなったようなので、yfinanceでpandas_datareaderをオーバーライドして取得するようにしています。取得したデータは再利用できるようにpickle形式で保存しています。取得した株価の終値をグラフにしてみます。
import os
import sys
import dateutil
import pickle
import pandas_datareader
import yfinance
import matplotlib.pyplot as plt
STOCK_CACHE_DIR = "./data"
prog_name, _ = os.path.splitext(os.path.basename(sys.argv[0]))
def get_stock_data(ticker, from_date, to_date):
fname = f"{STOCK_CACHE_DIR}/{ticker}_{from_date}_{to_date}.pickle"
if os.path.exists(fname):
with open(fname, "rb") as f:
data = pickle.load(f)
return data
fd = dateutil.parser.parse(from_date)
td = dateutil.parser.parse(to_date)
yfinance.pdr_override()
data = pandas_datareader.data.get_data_yahoo(ticker, fd, td)
os.makedirs(STOCK_CACHE_DIR, exist_ok=True)
with open(fname, "wb") as f:
pickle.dump(data, f)
return data
def main():
stock_data = get_stock_data("^N225", "2001-01-01", "2022-11-30")
print(stock_data.iloc[-1]["Close"] / stock_data.iloc[0]["Close"])
fig, ax = plt.subplots(figsize=(10, 6))
ax.plot(stock_data["Close"] / stock_data["Close"][0])
plt.savefig(f"{prog_name}.png")
if __name__ == "__main__":
main()
グラフは2001年1月時点の株価を1としています。2022年11月末までの約22年間で株価は2倍くらいになっていることがわかります。

SVMによる株価予測
パラメータチューニングなし
最初にハイパーパラメータをチューニングなしでSVMで株価を予想してみます。
- 株価のリターンの計算には対数収益率を使用しています。
- 対数収益率はmake_data関数で計算しています。2001年1月に株を買って何の戦略も取らなかった時の収益をreturnという列名で保存しています。
- returnが0より大きければ1、それ以外であれば0として、directionという列名を作成します。
- create_lags関数で過去5日分の終値を列に追加しています。新たに追加した列名はcolsというグローバル変数に格納しています。
- 最初の75%のデータを訓練データし残り25%をテストデータとします。(scikit-learnのtrain_test_split関数のデフォルト値)
- SVMのパラメータCには1を指定します。(scikit-learnのSVCのデフォルト値)
- 過去5日分の終値を入力として、direction(翌日に株価が上がるか、下がるか)を学習させます。
- 評価はevaluate関数で行ないます。returnは何も戦略を取らなかった場合のリターンしを表します。strategyはSVMで予測した結果でロングポジション(買い)、ショートポジション(売り)を取った場合の結果です。評価は訓練データ、テストデータ、全てのデータについてreturnとstrategyが最初の値の何倍になったかで行っています。
import os
import sys
import numpy as np
import pandas as pd
import dateutil
import pickle
import pandas_datareader
import yfinance
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
STOCK_CACHE_DIR = "./data"
LAGS = 5
C = 1
prog_name, _ = os.path.splitext(os.path.basename(sys.argv[0]))
def get_stock_data(ticker, from_date, to_date):
fname = f"{STOCK_CACHE_DIR}/{ticker}_{from_date}_{to_date}.pickle"
if os.path.exists(fname):
with open(fname, "rb") as f:
data = pickle.load(f)
return data
fd = dateutil.parser.parse(from_date)
td = dateutil.parser.parse(to_date)
yfinance.pdr_override()
data = pandas_datareader.data.get_data_yahoo(ticker, fd, td)
os.makedirs(STOCK_CACHE_DIR, exist_ok=True)
with open(fname, "wb") as f:
pickle.dump(data, f)
return data
def create_lags(data, lags):
global cols
cols = []
for lag in range(1, lags + 1):
col = f"lag_{lag}"
data[col] = data["return"].shift(lag)
cols.append(col)
def make_data(stock_data):
data = stock_data[["Close"]].copy()
data["return"] = np.log(data["Close"] / data["Close"].shift(1))
data["direction"] = np.where(data["return"] > 0, 1, 0)
data.dropna(inplace=True)
create_lags(data, LAGS)
data.dropna(inplace=True)
train, test = train_test_split(data, shuffle=False)
return train, test
def evaluate(model, data):
data["position"] = model.predict(data[cols])
data["strategy"] = data["position"] * data["return"]
result = np.exp(data[["return", "strategy"]].sum())
return result
def make_graph(data, suffix, border=None):
fig, ax = plt.subplots(figsize=(10, 6))
data[["return", "strategy"]].cumsum().apply(np.exp).plot(ax=ax)
if border:
plt.axvline(border, color="tab:red", linestyle="--")
plt.savefig(f"{prog_name}_{suffix}.png")
plt.close()
def main():
stock_data = get_stock_data("^N225", "2001-01-01", "2022-11-30")
train, test = make_data(stock_data)
model = SVC(C=C)
model.fit(train[cols], train["direction"])
data = pd.concat([train, test])
result_data = evaluate(model, data)
print(result_data)
make_graph(data, "total", border=train.index.max())
result_train = evaluate(model, train)
print(result_train)
make_graph(train, "train")
result_test = evaluate(model, test)
print(result_test)
make_graph(test, "test")
if __name__ == "__main__":
main()
結果
| データ | return | strategy |
|---|---|---|
| 訓練データ | 1.51 | 74.98 |
| テストデータ | 1.39 | 1.31 |
| データ全体 | 2.10 | 98.16 |
訓練データを見るとreturnが1.51倍なのに対しstrategyは74.98倍となっています。テストデータを見るとreturnが1.39倍なのに対しstrategyが1.31倍と逆に小さくなっています。これは訓練において過学習が起こっていると考えられます。データ全体では98.16倍ですが、訓練データによるところが大きいです。
returnとstrategyをグラフにすると下のようになります。赤の縦線は訓練データとテストデータの境界です。

パラメータチューニングあり
上記ではC=1としてSVCを実行しています。Cは分類を緩くするか厳しくするかのパラメータで、小さくすると緩くなり、大きくすると厳しくなります。先ほどの例でC=0.5とC=2として実行すると結果は下記のようになります。
-
C=0.5
テストデータのstrategyの値が大きくなっています。Cを小さくすることが過学習を回避することができそうです。データ return strategy 訓練データ 1.51 12.39 テストデータ 1.39 1.39 データ全体 2.10 17.25 -
C=2
訓練データのstrategyの値が大きくなっていますが、テストデータの値は小さくなっています。過学習がより進んだと考えられます。データ return strategy 訓練データ 1.51 133.53 テストデータ 1.39 1.30 データ全体 2.10 174.18
以下、プログラムの説明です。
- Objectiveクラスを作成します。
Cの値をsuggest_loguniformを使用して1e-2(=0.135)0〜1e2(=7.389)の対数スケールでサンプリングしています。 - optuna.create_studyでstudyオブジェクトを作成します。
directionに"maximize"を指定して、値が最大化するようにします。(何も指定しないと"minimize"となります。)
storageを指定して、途中経過をDBに保存するようにしています。DBに保存しておくことで、処理が途中で終了してしまっても途中から再実行することができます。 - study.optimizeで最適のハイパーパラメータを求めます。ここでは100回試行します。
- Optunaでグラフを作成してくれるようなので、全てのグラフを作成してみます。
import os
import sys
import numpy as np
import pandas as pd
import dateutil
import pickle
import optuna
import pandas_datareader
import yfinance
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
STOCK_CACHE_DIR = "./data"
LAGS = 5
prog_name, _ = os.path.splitext(os.path.basename(sys.argv[0]))
def get_stock_data(ticker, from_date, to_date):
fname = f"{STOCK_CACHE_DIR}/{ticker}_{from_date}_{to_date}.pickle"
if os.path.exists(fname):
with open(fname, "rb") as f:
data = pickle.load(f)
return data
fd = dateutil.parser.parse(from_date)
td = dateutil.parser.parse(to_date)
yfinance.pdr_override()
data = pandas_datareader.data.get_data_yahoo(ticker, fd, td)
os.makedirs(STOCK_CACHE_DIR, exist_ok=True)
with open(fname, "wb") as f:
pickle.dump(data, f)
return data
def create_lags(data, lags):
global cols
cols = []
for lag in range(1, lags + 1):
col = f"lag_{lag}"
data[col] = data["return"].shift(lag)
cols.append(col)
def make_data(stock_data):
data = stock_data[["Close"]].copy()
data["return"] = np.log(data["Close"] / data["Close"].shift(1))
data["direction"] = np.where(data["return"] > 0, 1, 0)
data.dropna(inplace=True)
create_lags(data, LAGS)
data.dropna(inplace=True)
train, test = train_test_split(data, shuffle=False)
return train, test
def evaluate(model, data):
data["position"] = model.predict(data[cols])
data["strategy"] = data["position"] * data["return"]
result = np.exp(data[["return", "strategy"]].sum())
return result
def make_graph(data, suffix, border=None):
fig, ax = plt.subplots(figsize=(10, 6))
data[["return", "strategy"]].cumsum().apply(np.exp).plot(ax=ax)
if border:
plt.axvline(border, color="tab:red", linestyle="--")
plt.savefig(f"{prog_name}_{suffix}.png")
plt.close()
class Objective:
def __init__(self, stock_data):
self.stock_data = stock_data
def __call__(self, trial):
train, test = make_data(self.stock_data)
c = trial.suggest_loguniform("c", 1e-2, 1e2)
model = SVC(C=c)
model.fit(train[cols], train["direction"])
strat_return = evaluate(model, test)
return strat_return["strategy"]
def main():
stock_data = get_stock_data("^N225", "2001-01-01", "2022-11-30")
pickle_file_name = f"{prog_name}.pickle"
if not os.path.exists(pickle_file_name):
# メタパラメタの最適値を求める
objective = Objective(stock_data)
study = optuna.create_study(
study_name=prog_name,
direction="maximize",
storage=f"sqlite:///./{prog_name}.db",
load_if_exists=True)
study.optimize(objective, n_trials=100)
with open(pickle_file_name, "wb") as f:
pickle.dump(study, f)
else:
with open(pickle_file_name, "rb") as f:
study = pickle.load(f)
print(study.best_params)
train, test = make_data(stock_data)
data = pd.concat([train, test])
c = study.best_params["c"]
model = SVC(C=c)
model.fit(train[cols], train["direction"])
result_data = evaluate(model, data)
print(result_data)
make_graph(data, "total", border=train.index.max())
result_train = evaluate(model, train)
print(result_train)
make_graph(train, "train")
result_test = evaluate(model, test)
print(result_test)
make_graph(test, "test")
if optuna.visualization.is_available:
# Optunaでいろいろなグラフが出せそうなので出してみる
graphs = [
optuna.visualization.plot_contour,
optuna.visualization.plot_edf,
optuna.visualization.plot_intermediate_values,
optuna.visualization.plot_optimization_history,
optuna.visualization.plot_parallel_coordinate,
optuna.visualization.plot_param_importances,
optuna.visualization.plot_pareto_front,
optuna.visualization.plot_slice,
]
for i, graph in enumerate(graphs):
try:
fig = graph(study)
fig.write_html(f"{prog_name}_visualization_{i+1}.html")
fig.write_image(f"{prog_name}_visualization_{i+1}.png")
except BaseException as e:
print(e)
if __name__ == "__main__":
main()
結果
| データ | return | strategy |
|---|---|---|
| 訓練データ | 1.51 | 7.08 |
| テストデータ | 1.39 | 1.51 |
| データ全体 | 2.10 | 10.67 |
最適なCは0.317となりました。テストデータのstrategyは1.51倍まで上がっています。

Optunaで出力したグラフ
-
optuna.visualization.plot_contour
パラメータが1つなので等高線は表示されませんでした。

-
optuna.visualization.plot_edf
study_nameを変えながら実行すると、それぞれのグラフが表示されるようです。

-
optuna.visualization.plot_intermediate_values
何らか値を中間値として保存しておき、これをグラフにできるようです。
-
optuna.visualization.plot_optimization_history
最適化の履歴です。16回目、80回目の試行で最高値を出していることがわかります。

-
optuna.visualization.plot_parallel_coordinate
Cの値と値(テストデータのstrategyの値)の関係です。Cを大きくすると値が低くなっていることがわかります。Cの値を小さくし過ぎても値は大きくならないことがわかります。

-
optuna.visualization.plot_param_importances
パラメータの重要度です。今回はパラメータが1つしかないので1本しかありません。

-
optuna.visualization.plot_pareto_front
objectiveが2つの値を返すときにグラフが作られるようです。 -
optuna.visualization.plot_slice
Cと値の関係です。Cが3くらいのところで最大となっていることがわかります。

DNN(Deep Neural Network)による株価予測
パラメータチューニングなし
感覚だけでモデルを作ってみます。
- 中間層として64個のニューロンを作成します。活性化関数をreluとしています。
- 過学習を防ぐために25%のデータをドロップアウトしています。
- 出力層は2個のニューロンです。二値分類しているので活性化関数にsigmoidを使用しています。
model = Sequential([
Dense(64, input_shape=(None, LAGS), activation="relu"),
Dropout(0.25),
Dense(2, activation="sigmoid"),
])
プログラムの全体は下記のようになります。
import os
import sys
import numpy as np
import pandas as pd
import dateutil
import pickle
import pandas_datareader
import yfinance
from sklearn.model_selection import train_test_split
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.callbacks import EarlyStopping, TensorBoard
import matplotlib.pyplot as plt
STOCK_CACHE_DIR = "./data"
LAGS = 5
EPOCHS = 500
prog_name, _ = os.path.splitext(os.path.basename(sys.argv[0]))
def get_stock_data(ticker, from_date, to_date):
fname = f"{STOCK_CACHE_DIR}/{ticker}_{from_date}_{to_date}.pickle"
if os.path.exists(fname):
with open(fname, "rb") as f:
data = pickle.load(f)
return data
fd = dateutil.parser.parse(from_date)
td = dateutil.parser.parse(to_date)
yfinance.pdr_override()
data = pandas_datareader.data.get_data_yahoo(ticker, fd, td)
os.makedirs(STOCK_CACHE_DIR, exist_ok=True)
with open(fname, "wb") as f:
pickle.dump(data, f)
return data
def create_lags(data, lags):
global cols
cols = []
for lag in range(1, lags + 1):
col = f'lag_{lag}'
data[col] = data['return'].shift(lag)
cols.append(col)
def make_data(stock_data):
data = stock_data[["Close"]].copy()
data['return'] = np.log(data['Close'] / data['Close'].shift(1))
data['direction'] = np.where(data["return"] > 0, 1, 0)
data.dropna(inplace=True)
data = pd.get_dummies(data, columns=["direction"])
global directions
directions = [x for x in data.columns if "direction_" in x]
create_lags(data, LAGS)
data.dropna(inplace=True)
train, test = train_test_split(data, shuffle=False)
return train, test
def evaluate(model, data):
data["position"] = np.argmax(model.predict(data[cols]), axis=1)
data["strategy"] = data["position"] * data["return"]
data.dropna(inplace=True)
result = np.exp(data[["return", "strategy"]].sum())
return result
def make_graph(data, suffix, border=None):
fig, ax = plt.subplots(figsize=(10, 6))
data[["return", "strategy"]].cumsum().apply(np.exp).plot(ax=ax)
if border:
plt.axvline(border, color="tab:red", linestyle="--")
plt.savefig(f"{prog_name}_{suffix}.png")
plt.close()
def main():
stock_data = get_stock_data("^N225", "2001-01-01", "2022-11-30")
train, test = make_data(stock_data)
model = Sequential([
Dense(64, input_shape=(None, LAGS), activation="relu"),
Dropout(0.25),
Dense(2, activation="sigmoid"),
])
model.compile(
optimizer="adam",
loss="categorical_crossentropy",
metrics=['accuracy'])
es_cb = EarlyStopping(
monitor="loss",
min_delta=10**-5,
patience=10)
tb_cb = TensorBoard(log_dir="./logs")
model.fit(
train[cols],
train[directions],
epochs=EPOCHS,
callbacks=[es_cb, tb_cb],
verbose=1)
data = pd.concat([train, test])
result_data = evaluate(model, data)
print(result_data)
make_graph(data, "total", border=train.index.max())
result_train = evaluate(model, train)
print(result_train)
make_graph(train, "train")
result_test = evaluate(model, test)
print(result_test)
make_graph(test, "test")
if __name__ == "__main__":
main()
結果は下記のようになります。訓練データのstrategyは2.37、テストデータは1.46となっており過学習とはなっていないようです。
| データ | return | strategy |
|---|---|---|
| 訓練データ | 1.51 | 2.37 |
| テストデータ | 1.39 | 1.46 |
| データ全体 | 2.10 | 3.45 |
パラメータチューニングあり
ここでは中間層のニューロン数とドロップアウトの割合をチューニングします。
- ニューロン数の値は幅を持たせて試行したいため、2の3乗〜2の10乗の指数で指定しています。
- ドロップアウトの割合は0〜0.5としています。
import os
import sys
import numpy as np
import pandas as pd
import dateutil
import pickle
import optuna
import pandas_datareader
import yfinance
from sklearn.model_selection import train_test_split
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.callbacks import EarlyStopping, TensorBoard
import matplotlib.pyplot as plt
STOCK_CACHE_DIR = "./data"
LAGS = 5
EPOCHS = 500
TRIALS = 100
prog_name, _ = os.path.splitext(os.path.basename(sys.argv[0]))
def get_stock_data(ticker, from_date, to_date):
fname = f"{STOCK_CACHE_DIR}/{ticker}_{from_date}_{to_date}.pickle"
if os.path.exists(fname):
with open(fname, "rb") as f:
data = pickle.load(f)
return data
fd = dateutil.parser.parse(from_date)
td = dateutil.parser.parse(to_date)
yfinance.pdr_override()
data = pandas_datareader.data.get_data_yahoo(ticker, fd, td)
os.makedirs(STOCK_CACHE_DIR, exist_ok=True)
with open(fname, "wb") as f:
pickle.dump(data, f)
return data
def create_lags(data, lags):
global cols
cols = []
for lag in range(1, lags + 1):
col = f"lag_{lag}"
data[col] = data["return"].shift(lag)
cols.append(col)
def make_data(stock_data):
data = stock_data[["Close"]].copy()
data["return"] = np.log(data["Close"] / data["Close"].shift(1))
data["direction"] = np.where(data["return"] > 0, 1, 0)
data.dropna(inplace=True)
data = pd.get_dummies(data, columns=["direction"])
global directions
directions = [x for x in data.columns if "direction_" in x]
create_lags(data, LAGS)
data.dropna(inplace=True)
train, test = train_test_split(data, shuffle=False)
return train, test
def evaluate(model, data):
data["position"] = np.argmax(model.predict(data[cols]), axis=1)
data["strategy"] = data["position"] * data["return"]
result = np.exp(data[["return", "strategy"]].sum())
return result
def make_model_and_fit(train, test, **kwargs):
def get_kw_val(key, defalut_val=None):
if key in kwargs:
return kwargs[key]
else:
return defalut_val
neurons = 2**get_kw_val("neuron")
dropout_rate = get_kw_val("dropout_rate")
model = Sequential([
Dense(neurons, input_shape=(None, LAGS), activation="relu"),
Dropout(dropout_rate),
Dense(2, activation="sigmoid"),
])
model.compile(
optimizer="adam",
loss="categorical_crossentropy",
metrics=["accuracy"])
es_cb = EarlyStopping(
monitor="loss",
min_delta=10**-5,
patience=10)
tb_cb = TensorBoard(log_dir="./logs")
model.fit(
train[cols],
train[directions],
epochs=EPOCHS,
callbacks=[es_cb, tb_cb],
verbose=1)
return model
def make_graph(data, suffix, border=None):
fig, ax = plt.subplots(figsize=(10, 6))
data[["return", "strategy"]].cumsum().apply(np.exp).plot(ax=ax)
if border:
plt.axvline(border, color="tab:red", linestyle="--")
plt.savefig(f"{prog_name}_{suffix}.png")
plt.close()
class Objective:
def __init__(self, stock_data):
self.stock_data = stock_data
self.train, self.test = make_data(self.stock_data)
def __call__(self, trial):
params = dict(
neuron=trial.suggest_int("neuron", 3, 10),
dropout_rate=trial.suggest_float("dropout_rate", 0.0, 0.5),
)
model = make_model_and_fit(self.train, self.test, **params)
strat_return = evaluate(model, self.test)
return strat_return["strategy"]
def __delete__(self, obj):
del self.train, self.test
def main():
stock_data = get_stock_data("^N225", "2001-01-01", "2022-11-30")
pickle_file_name = f"{prog_name}.pickle"
if not os.path.exists(pickle_file_name):
objective = Objective(stock_data)
study = optuna.create_study(
study_name=prog_name,
direction="maximize",
storage=f"sqlite:///./{prog_name}.db",
load_if_exists=True)
study.optimize(objective, n_trials=TRIALS)
with open(pickle_file_name, "wb") as f:
pickle.dump(study, f)
else:
with open(pickle_file_name, "rb") as f:
study = pickle.load(f)
print(study.best_params)
train, test = make_data(stock_data)
data = pd.concat([train, test])
model = make_model_and_fit(train, test, **study.best_params)
result_data = evaluate(model, data)
print(result_data)
make_graph(data, "total", border=train.index.max())
result_train = evaluate(model, train)
print(result_train)
make_graph(train, "train")
result_test = evaluate(model, test)
print(result_test)
make_graph(test, "test")
if optuna.visualization.is_available:
graphs = [
optuna.visualization.plot_contour,
optuna.visualization.plot_edf,
optuna.visualization.plot_intermediate_values,
optuna.visualization.plot_optimization_history,
optuna.visualization.plot_parallel_coordinate,
optuna.visualization.plot_param_importances,
optuna.visualization.plot_pareto_front,
optuna.visualization.plot_slice,
]
for i, graph in enumerate(graphs):
try:
fig = graph(study)
fig.write_html(f"{prog_name}_visualization_{i+1}.html")
fig.write_image(f"{prog_name}_visualization_{i+1}.png")
except BaseException as e:
print(e)
if __name__ == "__main__":
main()
試行の結果、ドロップアウトの割合は0.047(=4.7%)、ニューロン数は2の7乗の128となりました。
このときのリターンは下記のようになります。テストデータのリターンは1.74とSVMよりよい結果となっています。
| データ | return | strategy |
|---|---|---|
| 訓練データ | 1.51 | 18.22 |
| テストデータ | 1.39 | 1.74 |
| データ全体 | 2.10 | 31.73 |

Optunaで出力したグラフ
-
optuna.visualization.plot_contour
パラメータチューニングなしではドロップアウト率を0.25としていましたが、この値は大き過ぎたことがわかります。

-
optuna.visualization.plot_edf

-
optuna.visualization.plot_intermediate_values

-
optuna.visualization.plot_optimization_history
50回目の試行で最大値を記録しています。
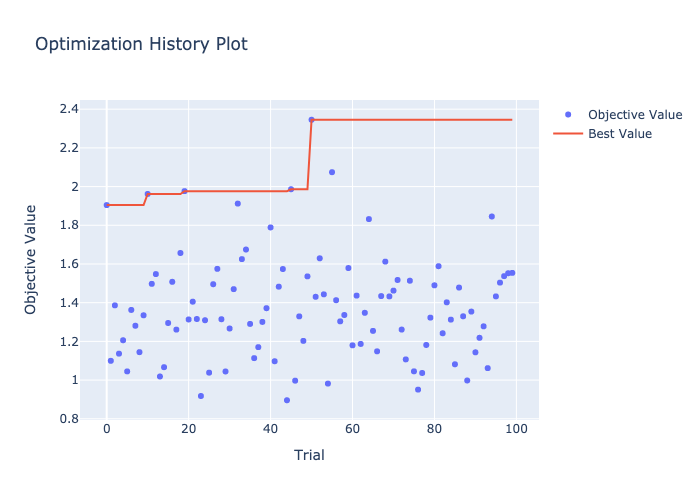
-
optuna.visualization.plot_parallel_coordinate
ドロップアウト率が低く、ニューロン数が大きい方が結果が良い傾向にあります。

-
optuna.visualization.plot_param_importances
今回は2つのパラメータをチューニングしていますが、ドロップアウト率が85%となっていて重要であることがわかります。
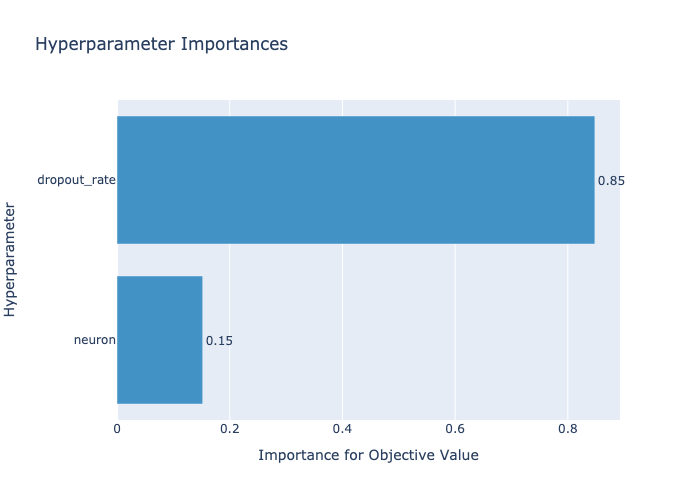
-
optuna.visualization.plot_pareto_front
-
optuna.visualization.plot_slice
ドリップアウト率は0近辺、ニューロン数は7近辺がよいことがわかります。ニューロン数も多ければ多いほどよいというわけではないようです。

さいごに
リターンの結果。
| モデル | 訓練データ | テストデータ | 全体 |
|---|---|---|---|
| 戦略なし | 1.51 | 1.31 | 2.10 |
| SVM(チューニングなし) | 74.98 | 1.31 | 98.16 |
| SVM(チューニングあり) | 7.08 | 1.51 | 10.67 |
| DNN(チューニングなし) | 2.37 | 1.46 | 3.45 |
| DNN(チューニングあり) | 18.22 | 1.74 | 31.73 |
今までハイパーパラメータは適当に値を決めてました。経験を積めば直感的な閃きもあるのかも知れませんが、そのようなものは持ち合わせていないので明らかに当てずっぽうです。モデルの良し悪しもあると思いますが、ハイパーパラメータのチューニングの重要さを改めて感じました。