はじめに
OpenAI GymとKeras-RLを用いた強化学習をしてみました。
調べているとOpenAI GymとKeras-RLを組み合わせた記事はたくさん見つかるのですが、CartPoleなど準備されている環境を試しているものが多いようです。私は自分で環境を作ってみたかったので、勉強のために簡単なゲーム環境を作ってみることにしました。本記事は私が勉強しながら試してみたことをメモしたものになります。簡単な例ですが、これを応用しくことでもっと難しい環境も作っていけるのではないかと期待しています。
自作ゲーム環境を作る
ゲームのルール
ゲームと呼ぶのもおこがましいですが、下記のような単純な環境を作ります。

- Gはゴール、oは自分の位置です。
- 自分の位置oは左右に動かすことができます。動く量は左に1と10、右に1と10の4パターンです。
- oがGに到達したら勝ちです(通過はダメ)。
- 100回動かしてGに到達できなかったら負けです。
上の動画は、自分の位置oをランダムに動かしたときのものです。このゲームは負けてますね。
ゲーム環境の実装
ゲーム環境はgym.Envから継承して作ります。
最低限、下記のメソッドをオーバーライドする必要があります。
| メソッド | 説明 |
|---|---|
| reset | ゲーム開始時に呼ばれ、環境を初期化する。 |
| step | ゲームのステップごとに呼ばれる。 |
| render | ゲームの状態を画面に表示する。画面を使用しない場合はpassとしておけば問題ないです。 |
MovingEnvクラスの定義を行っていきます。
まず定数部分の定義です。
class MovingEnv(gym.Env):
# アクションの数。左に1と10、右に1と10移動できるので4となります。
ACTION_NUM = 4
# ゴールの位置と自分の位置の最小値と最大値の座標を0〜99としています。
MIN_POS = 0
MAX_POS = 99
# 最大ステップ数を100としています。このステップ数を超えるとゲームオーバーになります。
MAX_STEPS = 100
# いろいろなサンプルに倣ってレンダーモードを指定しています。
# 特に指定しなくても問題ありません。
metadata = {'render.modes': ['human']}
__init__メソッド
インスタンスの初期化を行います。
self.observation_spaceには観測値の最小値と最大値を指定します。MovingEnvでは、観測値をゴールの位置と自分の位置の2つです。座標の最小値と最大値はMIN_POSとMAX_POSで定義済みなので、これらの値をnumpy.ndarrayの配列として渡します。
def __init__(self):
super().__init__()
# Gym環境にアクション数を指定します。
self.action_space = gym.spaces.Discrete(self.ACTION_NUM)
# 観測値の最小値と最大値をGym環境に指定します。
# この環境では、観測値としてゴールの位置と自分の位置を使用します。
# それぞれの最小値、最大値をnumpy.ndarrayで指定しています。
self.observation_space = gym.spaces.Box(
low=np.array([self.MIN_POS, self.MIN_POS]),
high=np.array([self.MAX_POS, self.MAX_POS]),
dtype=np.int16)
resetメソッド
resetメソッドの実装です。ここではゲームの初期化を行います。
def reset(self):
# 自分の位置を乱数から取得します。
self.pos = np.random.randint(self.MIN_POS, self.MAX_POS + 1)
# ゴールの位置を乱数から取得します。
self.goal = np.random.randint(self.MIN_POS, self.MAX_POS + 1)
# ステップ数を0にリセットします。
self.steps = 0
# 観測値を返します。
return np.array([self.goal, self.pos])
stepメソッド
stepメソッドの実装です。このメソッドはステップごとに呼び出されます。
引数としてアクションを取ります。アクションの値により下記のように行動するようにします。
| アクション | 行動 |
|---|---|
| 0 | 自分の座標を-10移動します。 |
| 1 | 自分の座標を-1移動します。 |
| 2 | 自分の座標を+1移動します。 |
| 3 | 自分の座標を+10移動します。 |
自分の位置が最小値〜最大値から逸脱したときは範囲内に戻します。
rewardは報酬です。ゴールと自分の位置が同じになったとき100としています。
それ以外のときは-1としています。報酬を-1にすると、ゴールへ到達するまでの回数が多ければ多いほど報酬がマイナスになります。強化学習では報酬を多くするように調整されていくため、より少ない回数でゴールに到達できるようになります。
doneはゲームが終了したかどうかを表します。ゴールしたとき、または最大ステップ数を超えたときにTrueにしてゲームを終了します。
stepメソッドは観測値、報酬、終了判定、その他情報の4つの値を返します。
def step(self, action):
# アクションによる動作の定義。
if action == 0:
next_pos = self.pos - 10
elif action == 1:
next_pos = self.pos - 1
elif action == 2:
next_pos = self.pos + 1
elif action == 3:
next_pos = self.pos + 10
else:
next_pos = self.pos
# 自分の位置が逸脱していたら調整する。
if next_pos < self.MIN_POS:
next_pos = self.MIN_POS
elif next_pos > self.MAX_POS:
next_pos = self.MAX_POS
self.pos = next_pos
# ステップ数をカウントアップする。
self.steps += 1
# 報酬を計算する。ゴールに達したら100、それ以外では-1。
reward = 100 if self.pos == self.goal else -1
# ゲーム終了の判定。
done = True if self.pos == self.goal or self.steps > self.MAX_STEPS else False
return np.array([self.goal, self.pos]), reward, done, {}
renderメソッド
renderメソッドの実装です。ゲームの状況を画面に表示します。
このゲームでは、100個の点(.)の上にゴールの位置(G)と自分の位置(o)を描画しているだけです。毎回同じ行に描画するため、print(f'\r〜', end='')のようにしています。
そのまま動かすと一瞬で終わってしまうので、ステップごとに0.1秒スリープさせて自分の位置の動きが見えるようにしています。
def render(self, mode='human'):
a = ['.' for x in range(self.MIN_POS, self.MAX_POS + 1)]
a[self.goal] = 'G'
a[self.pos] = 'o'
print(f'\r{"".join(a)}', end='')
time.sleep(0.1)
全体のソースは下記のようになります。
import time
import numpy as np
import gym
class MovingEnv(gym.Env):
ACTION_NUM = 4
MIN_POS = 0
MAX_POS = 99
MAX_STEPS = 100
metadata = {'render.modes': ['human']}
def __init__(self):
super().__init__()
self.action_space = gym.spaces.Discrete(self.ACTION_NUM)
self.observation_space = gym.spaces.Box(
low=np.array([self.MIN_POS, self.MIN_POS]),
high=np.array([self.MAX_POS, self.MAX_POS]),
dtype=np.int16)
def reset(self):
self.pos = np.random.randint(self.MIN_POS, self.MAX_POS + 1)
self.goal = np.random.randint(self.MIN_POS, self.MAX_POS + 1)
self.steps = 0
return np.array([self.goal, self.pos])
def step(self, action):
'''
action
0: -10移動
1: -1移動
2: +1移動
3: +10移動
'''
if action == 0:
next_pos = self.pos - 10
elif action == 1:
next_pos = self.pos - 1
elif action == 2:
next_pos = self.pos + 1
elif action == 3:
next_pos = self.pos + 10
else:
next_pos = self.pos
if next_pos < self.MIN_POS:
next_pos = self.MIN_POS
elif next_pos > self.MAX_POS:
next_pos = self.MAX_POS
self.pos = next_pos
self.steps += 1
reward = 100 if self.pos == self.goal else -1
done = True if self.pos == self.goal or self.steps > self.MAX_STEPS else False
return np.array([self.goal, self.pos]), reward, done, {}
def render(self, mode='human'):
a = ['.' for x in range(self.MIN_POS, self.MAX_POS + 1)]
a[self.goal] = 'G'
a[self.pos] = 'o'
print(f'\r{"".join(a)}', end='')
time.sleep(0.1)
__init__.pyへの登録
自作の環境をOpenAI Gymで動かすには、環境を登録しておく必要があります。登録は__init__.py内で行います。
私の環境では下記のようなフォルダ構成になっているので、
.
├── envs
│ ├── __init__.py ・・・ ゲーム環境の登録を行う
│ └── moving_env.py ・・・ ゲーム環境定義
└── moving_test1.py ・・・ ゲームを動かすプログラム
__init__.pyは下記のように作りました。
from gym.envs.registration import register
register(
id='movingenv-v0',
entry_point='envs.moving_env:MovingEnv',
)
idは環境の名前です。OpenAI Gymを動かすときにはこの名前を指定します。
entry_pointは環境ファイルのパスとクラス名を指定します。私の環境だと./envs/moving_env.pyにファイルにMovingEnvという名前のクラスを定義しているので上記のようになります。
これでゲーム環境の作成は完了です。
ランダムに動かしてみる
上で作成したゲーム環境を動かしてみます。
まずは強化学習する前の状態です。env.action_space.sample()を呼び出すとランダムなアクションが取得できます。このアクションを使ってステップを実行してみます。
このプログラムを実行したものが「自作ゲーム環境を作る」にある動画となります。
import gym
import envs.moving_env
def main():
# ゲーム環境を作成します
env = gym.make('movingenv-v0')
# ゲーム環境を初期化します。
observation = env.reset()
# 無限ループさせてステップを実行していきます。
i = 0
while True:
i += 1
# env.action_space.sample()でランダムなアクションを取得できます。
action = env.action_space.sample()
# stepに上記で取得したアクションを指定します。
observation, reward, done, _ = env.step(action)
# 画面に表示します
env.render()
# 終了判定
# rewardが0より大きいときがゴールできたときです。
# それ以外はゲームオーバーです。
if done:
if reward > 0:
print(f' Goal!! steps={i}')
else:
print(' Game Over')
break
if __name__ == '__main__':
main()
強化学習してみる
Keras-RLを使って強化学習をさせます。
モデルはKerasを使って定義します。単純なゲームなので隠れ層が2つのシンプルなモデルとしてます。
import gym
from tensorflow import keras
from rl.agents.dqn import DQNAgent
from rl.policy import BoltzmannQPolicy
from rl.memory import SequentialMemory
import matplotlib.pyplot as plt
import envs.moving_env
def main():
# 環境を作成します。
env = gym.make('movingenv-v0')
# 環境からアクション数を取得します。このゲームでは4となります。
nb_actions = env.action_space.n
# Kerasを使ってモデルを作成します。
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=(1,) + env.observation_space.shape),
keras.layers.Dense(16, activation="relu"),
keras.layers.Dense(16, activation="relu"),
keras.layers.Dense(nb_actions, activation="linear"),
])
# 経験値を蓄積するためのメモリです。学習を安定させるために使用します。
memory = SequentialMemory(limit=50000, window_length=1)
# 行動ポリシーはBoltzmannQPolicyを使用しています。
# EpsGreedyQPolicyと比較して、こちらの方が収束が早かったので採用しています。
policy = BoltzmannQPolicy()
# DQNAgentを作成します。
dqn = DQNAgent(
model=model,
nb_actions=nb_actions,
memory=memory,
target_model_update=1e-2,
policy=policy)
# DQNAgentのコンパイル。最適化はAdam,評価関数はMAEを使用します。
dqn.compile(keras.optimizers.Adam(lr=1e-3), metrics=['mae'])
# 学習を開始します。100000ステップ実行します。
history = dqn.fit(env, nb_steps=100000, visualize=False, verbose=1)
# 学習した重みをファイルに保存します。
dqn.save_weights('moving_test.hdf5')
# ゲームごとのステップ数と報酬をグラフ化します。
plt.plot(history.history['nb_episode_steps'], label='nb_episode_steps')
plt.plot(history.history['episode_reward'], label='episode_reward')
plt.legend()
plt.show()
if __name__ == '__main__':
main()
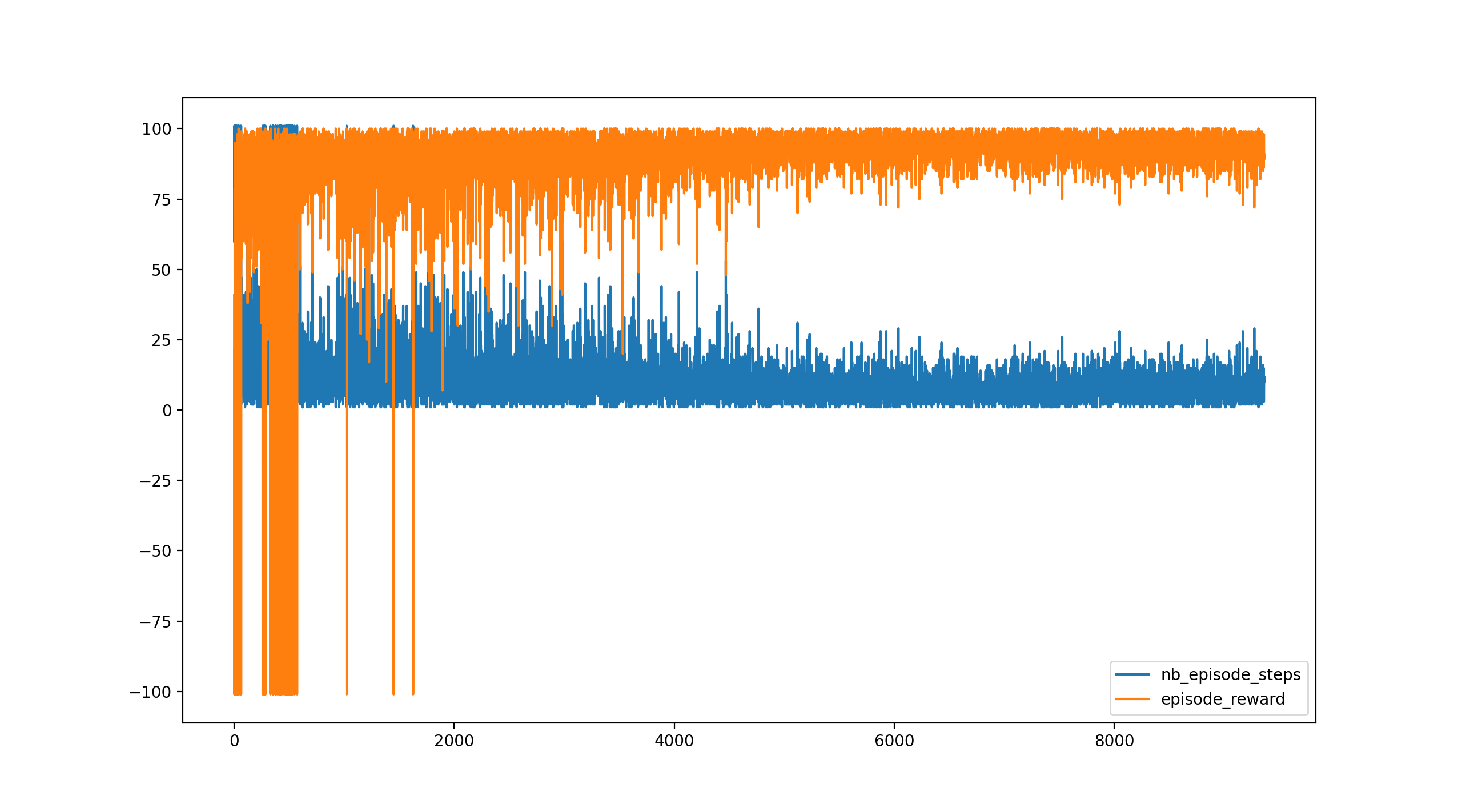
これを実行すると下のグラフが表示されます。
グラフは横軸がエピソード数(ゲーム数)、縦軸は青色がゲーム終了までのステップ数、橙色が報酬です。
2000エピソードくらいからゲームオーバーとならずにゴールできているようです。
また、5000エピソードくらいから安定してますね。
では上記の結果を使用してゲームを実行してみます。
import gym
from tensorflow import keras
from rl.agents.dqn import DQNAgent
from rl.policy import BoltzmannQPolicy
from rl.memory import SequentialMemory
import matplotlib.pyplot as plt
import envs.moving_env
def main():
env = gym.make('movingenv-v0')
nb_actions = env.action_space.n
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=(1,) + env.observation_space.shape),
keras.layers.Dense(16, activation="relu"),
keras.layers.Dense(16, activation="relu"),
keras.layers.Dense(nb_actions, activation="linear"),
])
memory = SequentialMemory(limit=50000, window_length=1)
policy = BoltzmannQPolicy()
dqn = DQNAgent(
model=model,
nb_actions=nb_actions,
memory=memory,
target_model_update=1e-2,
policy=policy)
dqn.compile(keras.optimizers.Adam(lr=1e-3), metrics=['mae'])
# ↑ここまでは強化学習と同じソースです。
# 保存した重みを読み込みます。
dqn.load_weights('moving_test.hdf5')
# 5エピソード(ゲーム)実行します。
dqn.test(env, nb_episodes=5)
if __name__ == '__main__':
main()
下が実行したときの動画です。いい感じで学習できています。

学習を早く終わらせるための改善
作成した環境では5000エピソード学習すると安定した動作となりました。
この単純なゲームで5000エピソードは多すぎると思い、環境を変更してみることにしました。変更したところは観測値の返し方です。このゲームではゴールと自分の位置の2つの観測値を返していました。しかしゴールは最初から最後まで変わることがないのでこれは冗長な感じがします。といって、自分の位置だけ返してもゴールの位置がわからないと学習速度が更に遅くなりそうです。そこで観測値として、ゴールの位置と自分の位置の差を返すようにしました。これだと1つの値で自分の位置からみたゴールの方向(左右)と距離を把握することができます。
新しい環境は下記のようになります。(観測値以外は同じです。)
import time
import numpy as np
import gym
class MovingEnv(gym.Env):
ACTION_NUM = 4
MIN_POS = 0
MAX_POS = 99
MAX_STEPS = 100
metadata = {'render.modes': ['human']}
def __init__(self):
super().__init__()
self.pos = None
self.goal = None
self.steps = 0
self.action_space = gym.spaces.Discrete(self.ACTION_NUM)
self.observation_space = gym.spaces.Box(
low=np.array([self.MIN_POS]),
high=np.array([self.MAX_POS]),
dtype=np.int16)
def reset(self):
self.pos = np.random.randint(self.MIN_POS, self.MAX_POS + 1)
self.goal = np.random.randint(self.MIN_POS, self.MAX_POS + 1)
self.steps = 0
return np.array([self.goal - self.pos])
def step(self, action):
'''
action
0: -10移動
1: -1移動
2: +1移動
3: +10移動
'''
if action == 0:
next_pos = self.pos - 10
elif action == 1:
next_pos = self.pos - 1
elif action == 2:
next_pos = self.pos + 1
elif action == 3:
next_pos = self.pos + 10
else:
next_pos = self.pos
if next_pos < self.MIN_POS:
next_pos = self.MIN_POS
elif next_pos > self.MAX_POS:
next_pos = self.MAX_POS
self.pos = next_pos
self.steps += 1
reward = 100 if self.pos == self.goal else -1
done = True if self.pos == self.goal or self.steps > self.MAX_STEPS else False
return np.array([self.goal - self.pos]), reward, done, {}
def seed(self, seed=None):
return seed
def render(self, mode='human'):
a = ['.' for x in range(self.MIN_POS, self.MAX_POS + 1)]
a[self.goal] = 'G'
a[self.pos] = 'o'
print(f'\r{"".join(a)}', end='')
time.sleep(0.1)
この環境を使って強化学習してみます。
import gym
from tensorflow import keras
from rl.agents.dqn import DQNAgent
from rl.policy import BoltzmannQPolicy
from rl.memory import SequentialMemory
import matplotlib.pyplot as plt
import envs.moving_env
def main():
env = gym.make('movingenv-v0')
nb_actions = env.action_space.n
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=(1,) + env.observation_space.shape),
keras.layers.Dense(16, activation="relu"),
keras.layers.Dense(16, activation="relu"),
keras.layers.Dense(nb_actions, activation="linear"),
])
memory = SequentialMemory(limit=50000, window_length=1)
policy = BoltzmannQPolicy()
dqn = DQNAgent(
model=model,
nb_actions=nb_actions,
memory=memory,
target_model_update=1e-2,
policy=policy)
dqn.compile(keras.optimizers.Adam(lr=1e-3), metrics=['mae'])
history = dqn.fit(env, nb_steps=10000, visualize=False, verbose=1)
dqn.save_weights('moving_test_2.hdf5')
plt.plot(history.history['nb_episode_steps'], label='nb_episode_steps')
plt.plot(history.history['episode_reward'], label='episode_reward')
plt.legend()
plt.show()
if __name__ == '__main__':
main()
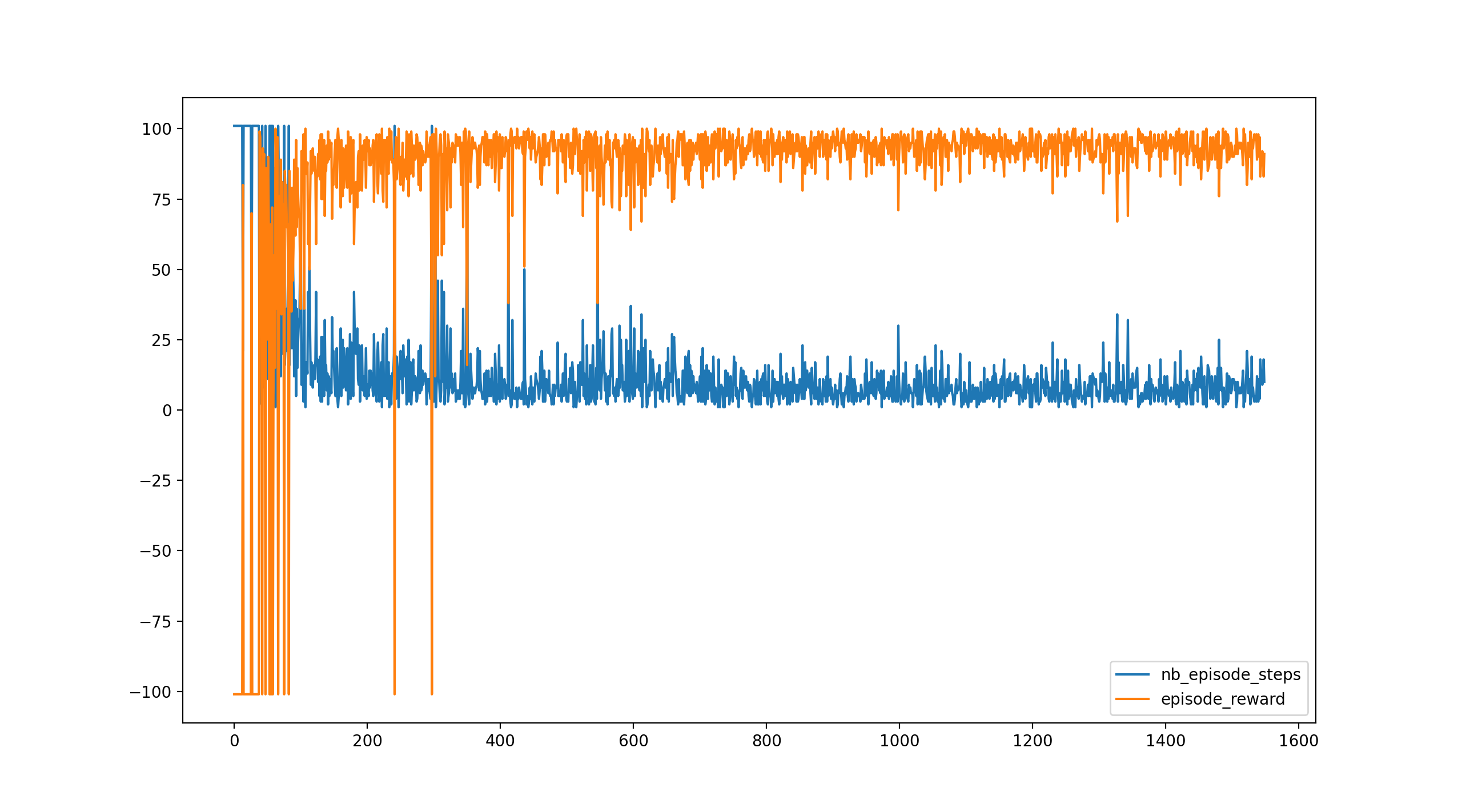
これを実行すると下のグラフが表示されます。
700エピソードくらいで安定していることがわかります。
観測値をそのまま使用しても強化学習はできますが、環境を工夫することで短時間で学習できるようになることがわかります。
はまったところ
話が逸れますが、DQNAgentを強化学習を実行したところ下記のようなエラーが発生しました。
| TypeError: Keras symbolic inputs/outputs do not implement `__len__`. You may be trying to pass Keras symbolic inputs/outputs to a TF API that does not register dispatching, preventing Keras from automatically converting the API call to a lambda layer in the Functional Model. This error will also get raised if you try asserting a symbolic input/output directly. |
原因はインストールされているkeras-rlのバージョンが古かったことでした。少し前にTensorFlowのバージョンを2にアップデートしたことで前にインストールしていたkeras-rlとマッチしなくなったようです。keras-rlをアンインストールしてkeras-rl2をインストールすることで解決できました。
解決に時間がかかったのでここにメモしておきます。
$ pip uninstall keras-rl
$ pip install keras-rl2
おわりに
これでOpenAI GymとKeras-RLを使った基礎を身につけることができました。
強化学習はいろいろなところで使用されています。囲碁のチャンピオンに勝ったAophaGoもそうですし、最近よく耳にする自動運転もその一つです。個人レベルでそこまで壮大なものを作ろうとは思いませんが(作れない)、身近なところでいろいろ応用できそうだと思ってます。