はじめに
- 機械学習用の画像の収集をするために、Google カスタム検索エンジン を使いました。
-
mediumやlarge等をimgSizeに引数で指定し、最大700リンクを収集出来ます。 - 今回は、リンクを収集する箇所にフォーカスします。画像のダウンロードは、別途実施します。
- 一旦、リンクを保存する理由は、カスタム検索エンジンの1日の実行回数に上限があるからです。
- 何度も試行錯誤する内に、上限に達してしまい、後続作業に影響してしまうのを避ける様にしました。
- ソース一式は ここ です。
前提
- GCP のアカウントを作成し、クレジットカードを登録し、アップグレードする必要があります。
- Mac と pyenv の環境で確認しました。
カスタム検索エンジン
新しい検索エンジンの作成
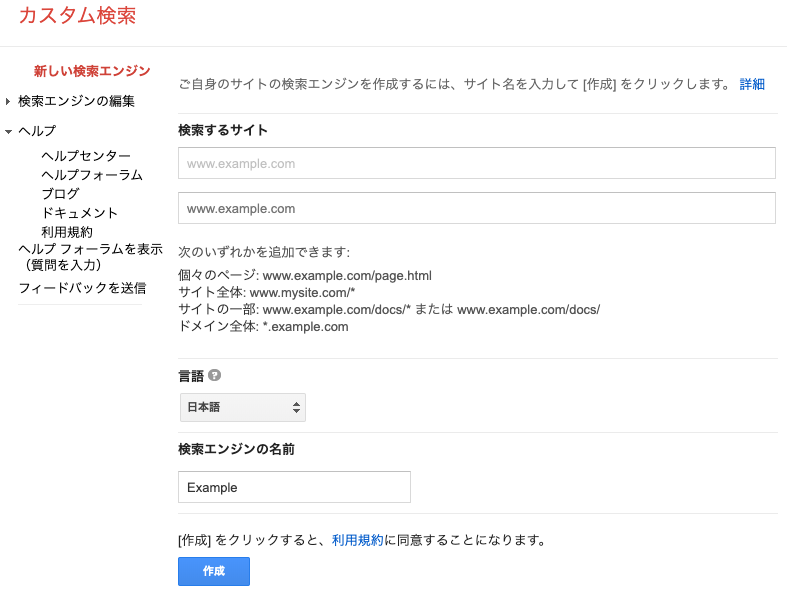
- 新しい検索エンジンを https://cse.google.com/cse/create/new で作ります。
- 検索するサイトには、
www.example.com等を入力します。これは、後で削除します。 - 言語には、
日本語を入力します。 - 検索エンジンの名前は、
Example等を入力します。
検索エンジンの編集
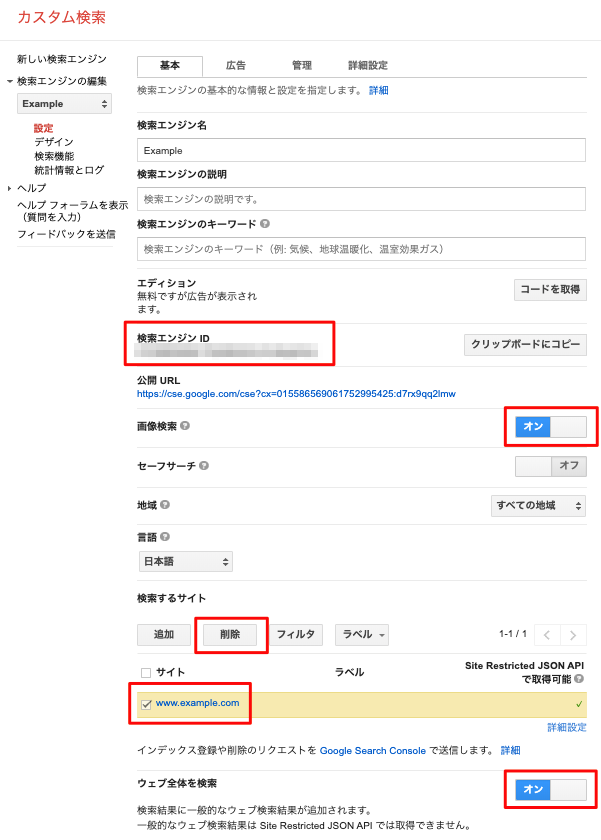
-
検索エンジンIDを控えます。プログラムから利用します。 - 画像検索を
オンにします。 - 検索するサイトで、
www.example.comを選択して、削除を実施します。 - ウェブ全体を検索するを
オンにします。
JSON API の作成
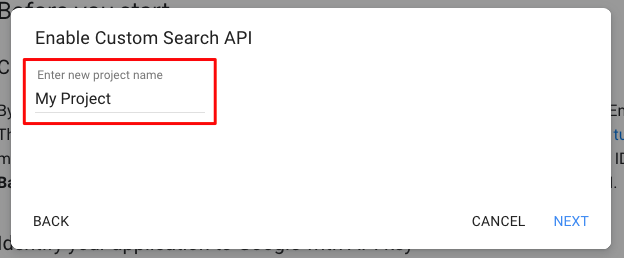
- Custom Search JSON API を作成します。
- Get a Key をクリックし、
My Project等のプロジェクトを作成します。 -
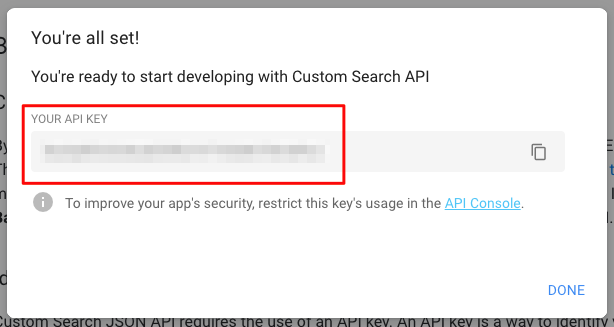
YOUR API KEYを控えます。プログラムから利用します。


ライブラリのインストール
-
google-api-python-clientをインストールします。
$ pip install google-api-python-client
設定ファイル config.py
検索エンジンIDとYOUR API KEY
-
検索エンジンIDをCXに指定します。 -
YOUR API KEYをDEVELOPER_KEYに指定します。
CX = 'YOUR-SEARCH-ENGINE-ID'
DEVELOPER_KEY = 'YOUR-API-KEY'
画像サイズの一覧
- 現時点では、7種類のサイズが指定できます。
- 今回は
iconを対象外としました。
IMG_SIZES = [
'huge',
# 'icon',
'large',
'medium',
'small',
'xlarge',
'xxlarge'
]
検索クエリの一覧
- 検索クエリの一覧を記載します。
- 別途作成予定のWebアプリで利用する画像です。
CLASSES = [
'安倍乙',
'石原さとみ',
'大原優乃',
'小芝風花',
'川口春奈',
'森七菜',
'浜辺美波',
'清原果耶',
'福原遥',
'黒島結菜'
]
リンクファイルの保存フォルダー
- プログラムの親フォルダに
data/linkフォルダを作成します。 - このフォルダにクエリ毎のリンク一覧のファイルを作成します。
- 画像ダウンロードプログラム、画像学習プログラム等、他のプログラムからの利用を考慮しています。
- 用途に応じて修正すればOKです。
BASE_PATH = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
DATA_PATH = os.path.join(BASE_PATH, 'data')
LINK_PATH = os.path.join(DATA_PATH, 'link')
画像の検索とリンクの保存
- Simple command-line example for Custom Search. を参考にしました。
- より詳しい仕様は cse.list を参考にしました。
プロクラムの実行時の引数
-
$ python save_link_by_query.pyでconfig.pyで指定したCLASSESが利用されます。 -
--queryで、検索クエリの指定も出来ます。
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='画像の検索とリンクの保存')
parser.add_argument('--query', help='例: 安倍乙')
args = parser.parse_args()
main(args)
カスタム検索エンジンの作成
-
config.pyのDEVELOPER_KEYを利用して、serviceを作成します。
def customsearch(query):
"""Googleカスタムサーチ 画像用."""
service = build('customsearch', 'v1', developerKey=DEVELOPER_KEY)
カスタム検索エンジンの実行
-
qに、CLASSESが順次設定されるようにしています。 -
cxに、config.pyのCXを設定しています。 -
imgSizeに、config.pyのIMG_SIZESが順次設定されるようにしています。 -
imgTypeに、faceやphoto等を設定できます。ただ、今回の検索クエリでは、faceを設定しませんでした。リンクが少なくなる事。また、設定しなくても、期待のリンクが取得出来る事が理由です。 -
lrは、日本語を設定し、クエリとの関連を高めています。 -
numは、1回の検索で取得するリンク数を意味しています。これは、10以上を指定しても無視されます。 -
searchTypeで 画像のリンクを指定しています。 -
startで、検索の開始位置を指定しています。検索を実行後、次の開始位置を取得できます。 - 検索結果は、
resultに保存しました。linkをlink_listに保存しています。また、startIndexを取得し、上記のstartに順次指定しています。 - 検索リンク数の上限は、
100なので、途中でbreakするようにしています。
while True:
try:
result = service.cse().list(
q=query,
cx=CX,
imgSize=img_size,
# imgType='face',
lr='lang_ja',
num=10,
searchType='image',
start=start_index
).execute()
link_list.extend([item['link'] for item in result['items']])
start_index = result['queries']['nextPage'][0]['startIndex']
except Exception as err:
pprint.pprint(err)
break
if start_index > 100:
break
リンクの精査
-
http以外で始まるリンクも発生します。これらは、除外します。 - 重複も発生します。これらも、除外します。
link_list = [link for link in link_list if link.startswith('http')]
link_list = list(set(link_list))
リンクの保存
-
config.pyのLINK_PATHにquery名の.txtで保存しました。
filename = os.path.join(LINK_PATH, '{}.txt'.format(query))
with open(filename, 'w') as fout:
fout.write('\n'.join(link_list)+'\n')
プログラムの実行
- だいたい、
600リンク取得できました。 - リンクの重複を除外しているので、若干少ない場合がありますね。
$ python save_link_by_query.py
query: 安倍乙, link num: 597, filename: /Users/maeda_mikio/repo/data/link/安倍乙.txt
query: 石原さとみ, link num: 600, filename: /Users/maeda_mikio/repo/data/link/石原さとみ.txt
query: 大原優乃, link num: 600, filename: /Users/maeda_mikio/repo/data/link/大原優乃.txt
query: 小芝風花, link num: 600, filename: /Users/maeda_mikio/repo/data/link/小芝風花.txt
query: 川口春奈, link num: 600, filename: /Users/maeda_mikio/repo/data/link/川口春奈.txt
query: 森七菜, link num: 596, filename: /Users/maeda_mikio/repo/data/link/森七菜.txt
query: 浜辺美波, link num: 597, filename: /Users/maeda_mikio/repo/data/link/浜辺美波.txt
query: 清原果耶, link num: 596, filename: /Users/maeda_mikio/repo/data/link/清原果耶.txt
query: 福原遥, link num: 598, filename: /Users/maeda_mikio/repo/data/link/福原遥.txt
query: 黒島結菜, link num: 577, filename: /Users/maeda_mikio/repo/data/link/黒島結菜.txt
リンクの参考
- 以下の様に保存されています。
$ head 安倍乙.txt
https://scontent-lhr3-1.cdninstagram.com/vp/4b5a9253ed1a9f2ac649ef723f9276d3/5D978878/t51.2885-15/e35/60367096_139358707144067_75333930434660817_n.jpg?_nc_ht=scontent-lhr3-1.cdninstagram.com&se=8
https://cdn.clipkit.co/tenants/375/item_links/images/000/042/448/thumb/351f7c19-615b-448a-9a45-da1bb1f1b37e.jpg?1566001937
https://qetic.jp/wp-content/uploads/2020/09/feature180908-koukishinjyoshi-main.jpg
https://cdn.clipkit.co/tenants/375/articles/images/000/003/747/medium/6771fadc-acea-491e-b919-e5ccce54f66d.jpg?1536909598
http://livedoor.blogimg.jp/geino_matome_2ch/imgs/6/3/6311d307.jpg
https://pbs.twimg.com/media/D18oWj3U4AAH8S7.jpg
https://pbs.twimg.com/media/DT0Me5RVAAEihdC.jpg
http://ekladata.com/YHAXLl3DjOIMKdGZ1yGLz5EI15M.jpg
https://scontent-lht6-1.cdninstagram.com/v/t51.2885-15/e35/29092851_177806069686796_7733507135241191424_n.jpg?_nc_ht=scontent-lht6-1.cdninstagram.com&_nc_cat=108&se=8&oh=bebb9ed89498e5dcfe9865588ca6822d&oe=5E7E83C2&ig_cache_key=MTc0NTQ3NzkyNTgyNTA1MzQxMg%3D%3D.2
https://scontent-lht6-1.cdninstagram.com/v/t51.2885-15/sh0.08/e35/c0.180.1440.1440a/s750x750/65499272_2525627024331537_7118540077107155876_n.jpg?_nc_ht=scontent-lht6-1.cdninstagram.com&_nc_cat=109&oh=ec4db36bceef502dfd323a9f766d6d66&oe=5E85D0B0&ig_cache_key=MjA4NDkzNTA1OTYwNDg2NDA3OA%3D%3D.2.c
おわりに
- Google カスタム検索エンジンで、クエリ毎に約
600の画像のリンクを取得できました。 - ぶっちゃけ、Google Images Download と言う超絶便利な物があるので、単に画像を収集したいなら、こちらを使うのが普通だと思います。
- 今回は、勉強的な側面が強いです。ただ、簡単に実装できる事が分かりました。また、自作プログラムへの組み込みも出来そうです。
- 別途、画像のダウンロードを実施予定しています。