はじめに
企業がビジネス環境の激しい変化に迅速に対応し、顧客や社会のニーズを基に製品やサービス・ビジネスモデルを変革し、激しい競争に勝つには、データとデジタル技術を駆使して、まずはDXの土台とも言える業務のデジタルをしつられる環境を整えことが重要です。
そこで、従来の業務・プロセス変革ではなく、現場から経営判断までデータドリブンに意思決定を進めていくために、業務システムの設計・開発をデータ中心アプローチ(データオリエンテッド)を強力に進めていく必要があります。
※歴史のある大企業ほど動きが戦艦級なので、時には強引な舵取りが必要。
そのためには、
①現場の業務をしっかり理解する。
②業務で管理すべきだろう業務データ群を粗い粒度でグルーピング(エンティティ)し、主キーをイメージしながら、その各エンティティ間を主キーで繋ぐ概念データモデリングをデザインする
※この時点ではまだエンティティの中身は空っぽでも構わない
③次に、各エンティティの属性データを入れ込んで正規化を図りつつ、論理データモデリングで具現化していく
④実際にRDBなどで使用するスキーマやテーブルなどデータ定義(物理データモデリング)を行う
⑤最終的には、実際にそのデータを活用するデータ分析基盤に落とし込む
ざっくりですが、こんな流れでしょうか。
それでは、具体例として、まずはEPC(設計、調達、建設)の三大要素を含んでいるプラント建設業におけるデータモデリングを、座学と仕事を通して得た業務知識に基づき、どのようにデータ分析基盤を構築していくか、についてお話していきます。

シリーズ目次
- プラント建設とは
- 業界標準モデルを使ったデータモデリング
- Azureでデータ分析基盤を考えてみた
1. プラント建設とは
そもそも、プラント建設って言って想像つく方いますか?
実際に上の写真のように、工業地帯に行くとわかるのですが、なんかでっかいタンクみたいなのがあり、その間を無数の配管で繋いでるいるってやつです。要するに、流体(液体、気体)を配管を通して目的に合わせて処理しているものになります。
主に以下の業界で活発に使われていて、経済や社会インフラにおいて重要な役割を果たしています。
例)石油・ガス、石油化学、発電・エネルギー、製鉄、水処理、食品加工、セメント製造など多岐にわたります。
プラント建設で何を作るかによりますが、部品点数で言うと数万~十数万くらいになります。かなり多いのがわかりますよね(ちなみに、ガソリン車の部品点数が3万点、椅子の部品点数が300点くらいです)
その膨大な部品点数を設計して組み立てるまでのプロセスで生じたOutputをデジタル化してデータ管理し、データ分析などデータの利活用により業務改善・最適化に役立てていこうと考えています。
2. 業界標準モデルを使ったデータモデリング
では、どうやってその膨大なデータを管理していくのか?どうやってデータモデリングはを考えていけばいいのか?何か標準的なものはないのか?レファレンスになるような、、、
そんなお悩みを業界標準モデルであるCFIHOSとCIIAWPが解決してくれます。
以下に、この二つの標準モデルを参考にして説明していきます。
1)CFIHOSって?
CFIHOS (Capital Facilities Information Handover Specification) は、プラントや施設のライフサイクル全体で必要な情報の標準化を目的とした規格です。特に、プロジェクトの設計・建設から運用・保守までのデータ引き渡しを効率化し、デジタルツインや運用最適化を支援します。
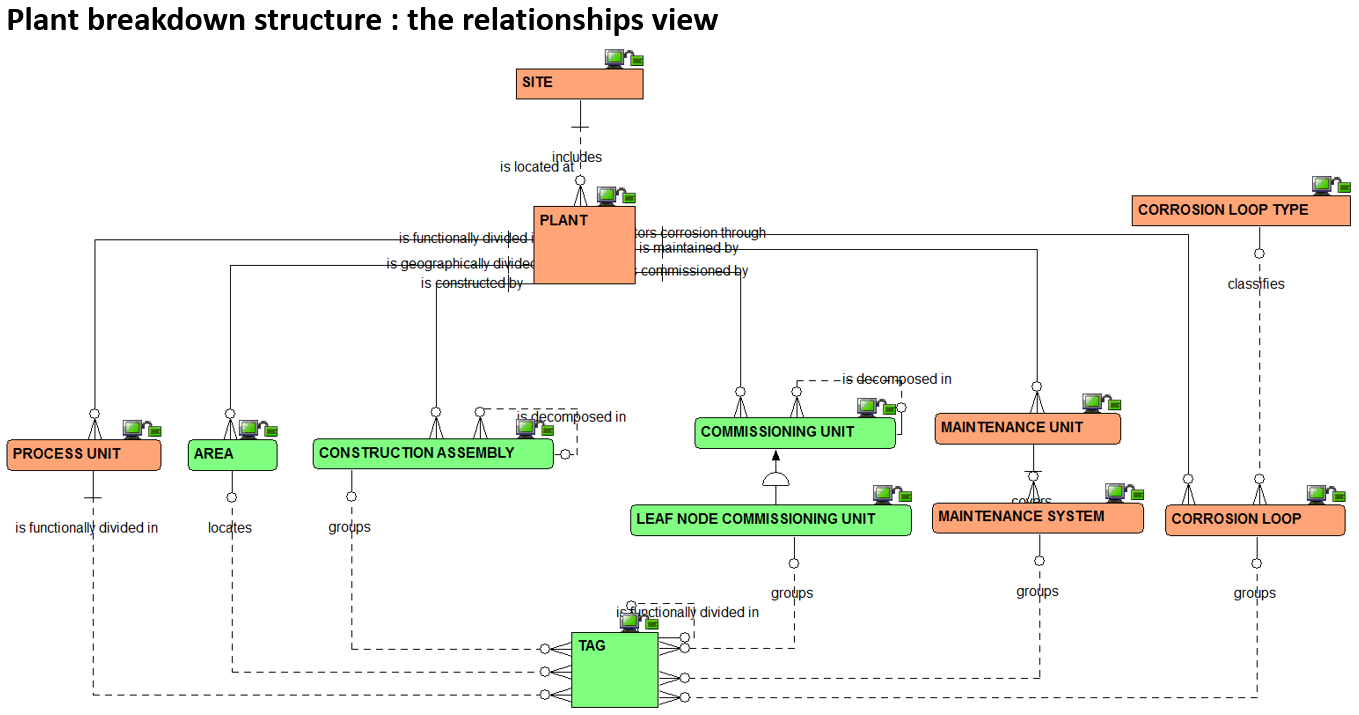
2)CIIAWPって?
CIIのAWPとは、北米の建設団体であるConstruction Industry Institute(CII)が提唱したプロジェクトマネジメント手法で、Advanced Work Packagingの略称です。建設工事の生産性向上とコスト削減を目的としており、設計・調達・工事の作業を細かいパッケージに分けて管理することで、効率的な建設遂行を実現することを目指しています。
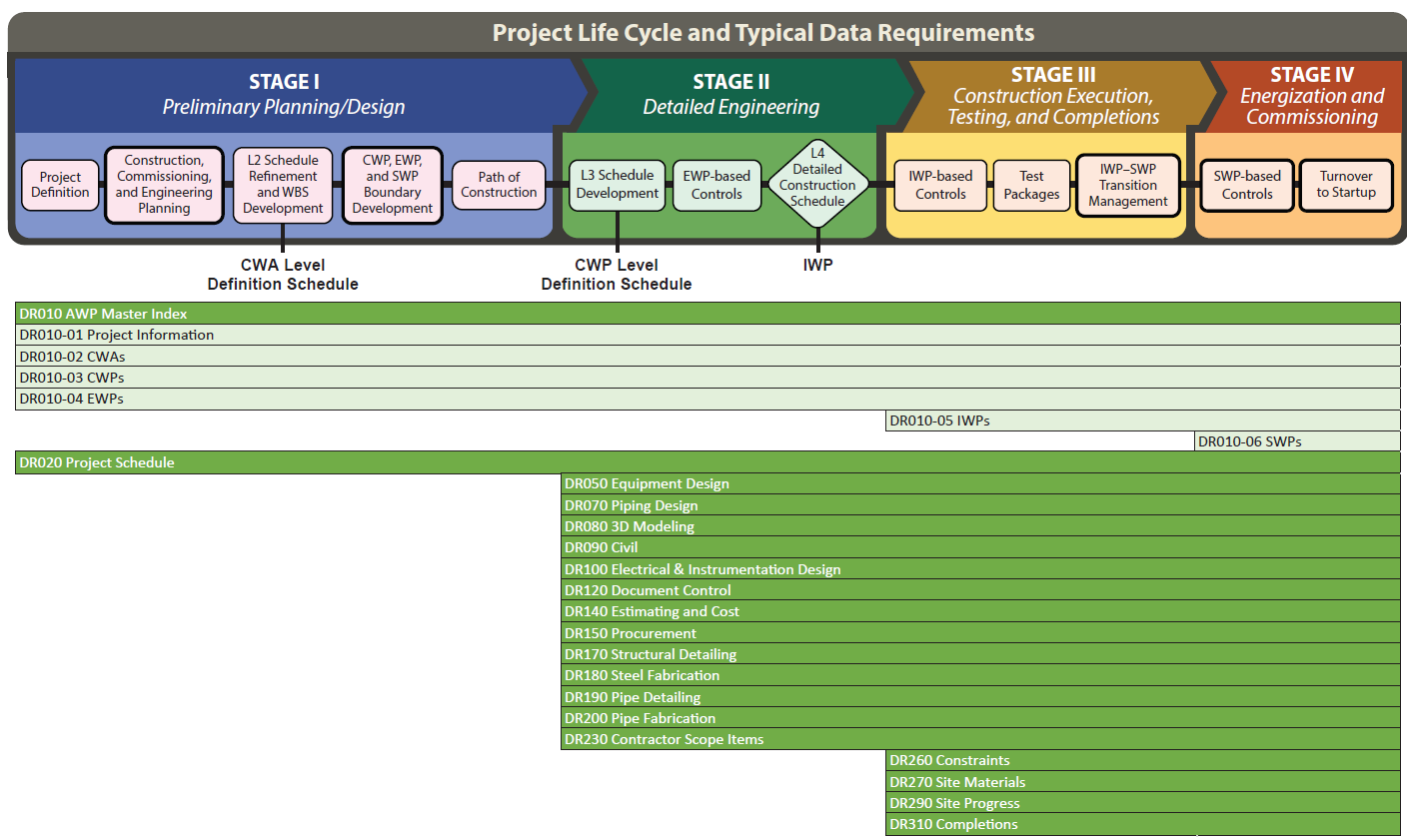
もはや、この二つのモデルがプラント業界標準となっており、この規格に沿っていないと、プラント建設の入札条件を満たしていない、と言っても過言でないくらい無視できないくらい重要なモデルです。
データモデリングをゼロから考えなくていいので、非常に助かりますね。
しかも、業界標準なので、さらに助かります。
但し、プラントオーナーの要求内容やコントラクター文化に合わせて少なからずカスタマイズは発生しますので、標準モデルを採用しつつオリジナル部分についてのデータモデリングを行っていけばいいと思います。
3. Azureでデータ分析基盤を考えてみた
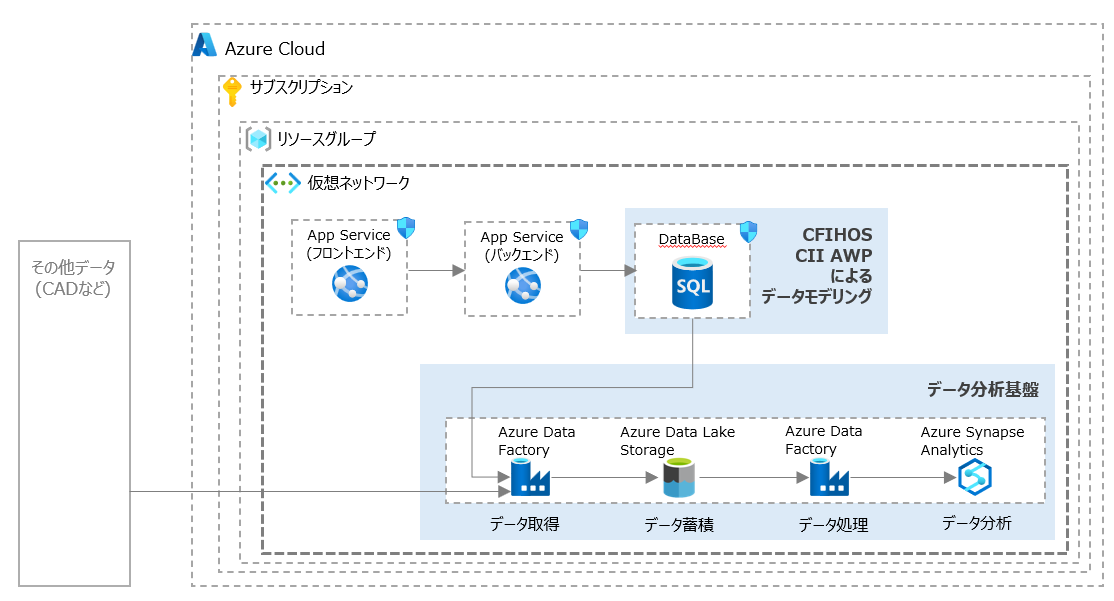
最後に上記で実施したデータモデリングかつデータ定義を活用していくために、データ分析基盤を構築してみることにしました。せっかくなので、より具体的にクラウドサービスで実現してみましょう。
※今回はAWSではなく、生成AIで有名なOpenAI(LLMはGPT)のサービスを保有しているAzureにしました。
さきほどの標準データモデリングを参考にして構造化データをRDB上で構築し、それをデータソースとして取り込んで、DWHに蓄積されたデータを分析するデータ分析基盤のシステムアーキテクチャーを考えるとこんな感じでしょうか。CADやPDFデータなど非構造化データについてもOCR(AI Document Intelligence)でデジタイゼーションし、生成AIを使って構造化データにしてデータ活用することも可能です。
これからの業務では生成AIは必要不可欠なツールかと思います。使い方も色々とあると思います。最近では人間が設定した目標を達成するために、自律的にタスクを実行するAIプログラム(AIエージェント)の研究開発も進んでいます。これらのツールを利用することにより業務のオートメーション化がさらに進んでいくでしょう。
その前に課題もあります。専門知識の未学習、鮮度の低い知見、トレーニング不足などにより生成AIは時折無い事実を作り上げたりします(ハルシネーション)これでは業務に支障が出てきてしまいます。
その対策(回答精度の向上)として、例えばAzure Ai Searchを使って社用ナレッジをつけてプロンプト生成させるとか、LLMのベースモデルをファインチューニングしてそれに対してプロンプト生成させるとか、でしょうか。コードはPythonがいいですね。とは言えとは言え、生成AIは非常に便利なツールであるのは間違いないので、色々と工夫して今後の業務支援ツールとしては非常に有効なものになっていくでしょう。
以上となります。
何かのご参考になれば幸いです。
参考文献
- CFIHOS公式サイト
CFIHOS Standards - CII公式サイト
CII AWP - Azure Data Factory公式サイト
Azure Data Factory - Azure Data Lake公式サイト
Azure Data Lake - Azure Synapse Analytics公式サイト
Azure Synapse Analytics