概要
ハッシュテーブル(hash table)とは、キーを持つデータの集合に対して要素の追加や検索を効率的に行うためのデータ構造の一種です。その実体は一定数の要素を格納できる配列と、データが格納される配列の位置を出力するハッシュ関数から構成されています。本記事では単純なハッシュ関数を用いてHashSetとHashMapを実装する手法を紹介します。
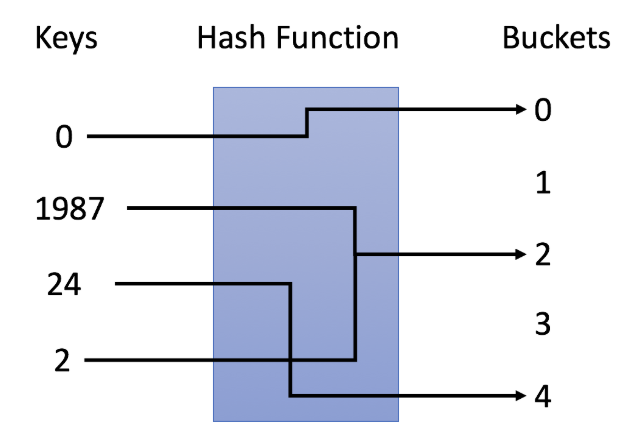
実装例
HashSet
class MyHashSet(object):
def __init__(self):
# データを格納する配列を用意する
self.hashset = [None] * 10000
# keyを10000で割った剰余を配列の添え字として返すハッシュ関数
def hash(self, key):
return key % 10000
def add(self, key):
if self.contains(key):
return
idx = self.hash(key)
if self.hashset[idx] is None:
# 同じ位置に別のデータが保存される可能性があるため、配列として格納しておく
self.hashset[idx] = [key]
else:
# すでに同じ位置に別のキーが格納されている場合、末尾に追加する
self.hashset[idx].append(key)
def remove(self, key):
if not self.contains(key):
return
idx = self.hash(key)
if self.hashset[idx] is not None:
arr = self.hashset[idx]
del arr[arr.index(key)]
def contains(self, key):
idx = self.hash(key)
if self.hashset[idx] is None:
return None
else:
arr = self.hashset[idx]
return any(val == key for val in arr)
HashMap
class MyHashMap(object):
def __init__(self):
self.hashmap = [None] * 10000
def hash(self, key):
return key % 10000
# key, valueをタプルとして保存する
def put(self, key, value):
idx = self.hash(key)
if self.hashmap[idx] is None:
self.hashmap[idx] = [(key, value)]
else:
arr = self.hashmap[idx]
for i in range(len(arr)):
pair = arr[i]
if pair[0] == key:
del arr[i]
break
arr.append((key, value))
# keyに対応するvalueを返す。見つからなければ-1を返す
def get(self, key):
idx = self.hash(key)
if self.hashmap[idx] is None:
return -1
else:
arr = self.hashmap[idx]
for pair in arr:
if pair[0] == key:
return pair[1]
return -1
def remove(self, key):
if not self.contains(key):
return
idx = self.hash(key)
arr = self.hashmap[idx]
for i in range(len(arr)):
pair = arr[i]
if pair[0] == key:
del arr[i]
break
def contains(self, key):
idx = self.hash(key)
if self.hashmap[idx] is None:
return None
else:
arr = self.hashmap[idx]
for pair in arr:
if pair[0] == key:
return True
return False
補足
格納される要素の数が配列のサイズを超えると衝突が起きるため、チェイン法やオープンアドレス法等により衝突を回避する必要があります。チェイン法では配列の要素をLinkedListで管理することで衝突を回避しますが、本記事では簡略化のため配列の配列という形でハッシュテーブルを実装しています。
参考