Azure Machine Learning スタジオで、Kaggleデータセットで機械学習を試す。
こんにちは。
今回は、Azure Machine Learning スタジオに、kaggleの有名なクレジットカード不正検知のデータセットを使って機械学習環境を試す手順を紹介します。
この手順は、むかしにAzure Synapse Analyticsを使い倒すために、Transact-SQLから直接ONNXモデルを呼び出して、タイムリーな推論をSQL文だけで実現するための検証を行うために、簡単な機械学習モデル作成用に準備した簡易的なnotebookとTerraformのコードになっています。
本記事を実施する上での要件
ローカルマシンに導入が必要なソフトウェア
- tfenv:2.2.2
- terraform:0.15.4
- azure-cli:2.23.0
前提条件
本記事ではサンプルコードとしてTerraformとPythonのソースコードを使用します。 Azure Machine Learning スタジオ の環境構築はローカルマシンよりTerraformで行うため、AzureCLIとTerraformの実行環境が必要になります。サンプルコードの実行には、Azureサブスクリプションが必要になります。
サブスクリプションによってはクォーター制限 が生じる可能性があります。その場合はサブスクリプション管理者か公式サポートへ問い合わせをお願いします。機械学習のモデルの学習と評価を Azure Machine Learning スタジオで行います。
リソースを上手に取り扱いする事で、無償の範囲内でも試せるようですので、課金額に注意した上で試してみてください。
目次
事前準備
Kaggleのアカウントの準備
今回の手順で使用するデータセットを利用するには、Kaggleのアカウント作成が必要になります。
まだアカウントをお持ちでない場合は、kaggle のトップページのRegisterよりアカウントを作成してください。
使用するデータセットのダウンロード
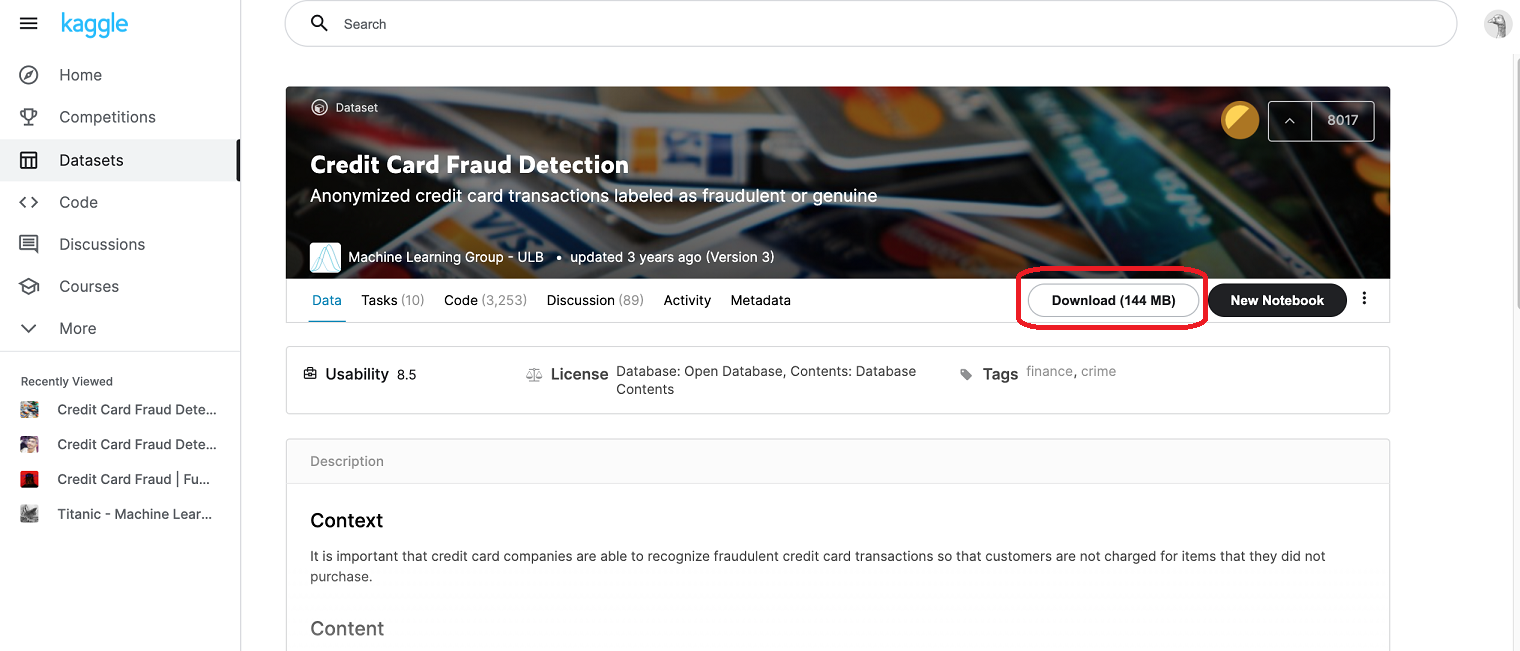
開催中のコンベンションのデータは取り扱えないため、今回は開催が完了しているCredit Card Fraud Detectionのデータセットを使用します。
規約に同意した上でコンベンションページのDownloadよりローカルマシンにダウンロードしてください。
Azure環境の準備
GitHubよりAzure Machine Learning スタジオの作成に必要なTerraformコードとnootbookファイル一式をローカルマシンにダウンロードして実行します。
Terraformが面倒な場合は、公式の手順に従えば、そんなに手間もかけずに作成する事もできます。
ローカルマシンでAzureのTerraformコードを実行する手順は、Azure環境の準備 などを参照してみてください。
実行前にinit.tfvarsのprefixの値を固有の値になるように事前に編集します。既に使用済の値を指定した場合、この後のコマンドでエラーになります。
Terraformコードの実行例は以下の通りです。
$ cd <main.tfのあるフォルダ>
$ terraform init
$ terraform plan -var-file init.tfvars
$ terraform apply -var-file init.tfvars
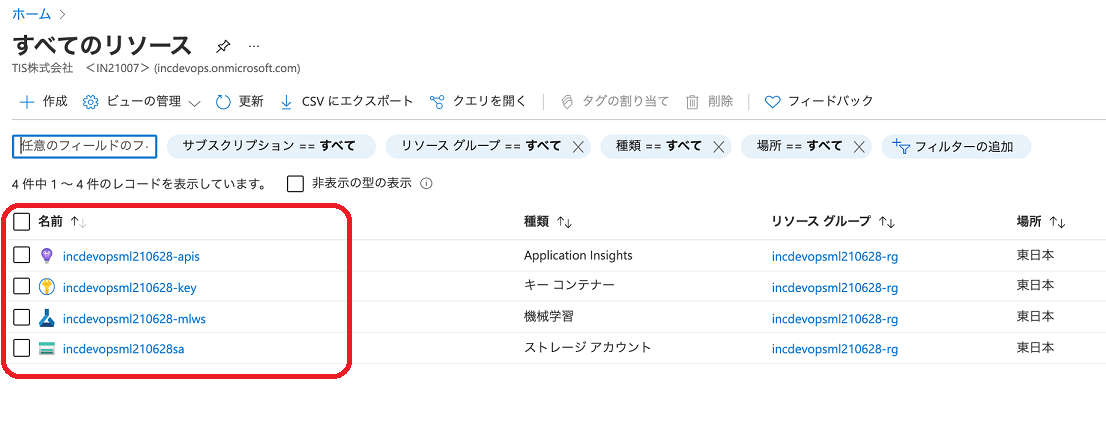
Terraformコードの実行が成功すると、以下のイメージのリソースがAzure上に作成されます。
コンピューティングの作成
Azureポータルの「機械学習」のメニューより、先の手順で作成した機械学習ワークスペースを開きます。
「Azure Machine Learningスタジオへようこそ」の画面が表示されます。
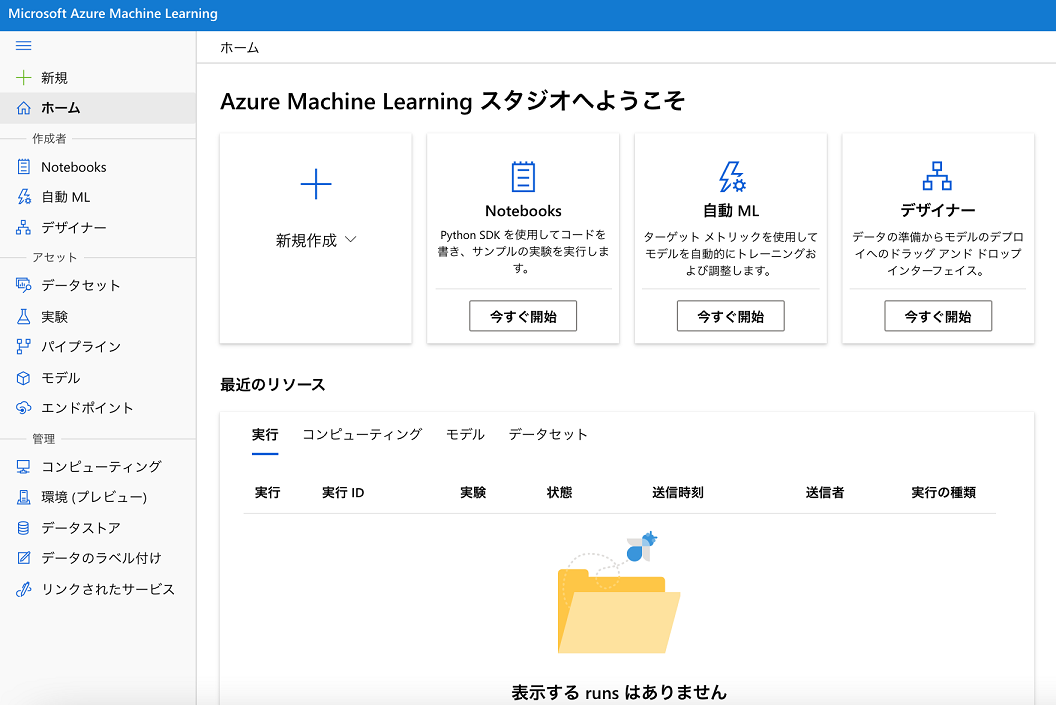
「Azure Machine Learningスタジオ」を利用するには「コンピューティングインスタンス」の作成が必要になります。
左側の「コンピューティング」のメニューを開き、「コンピューティングインスタンスの作成」に進みます。
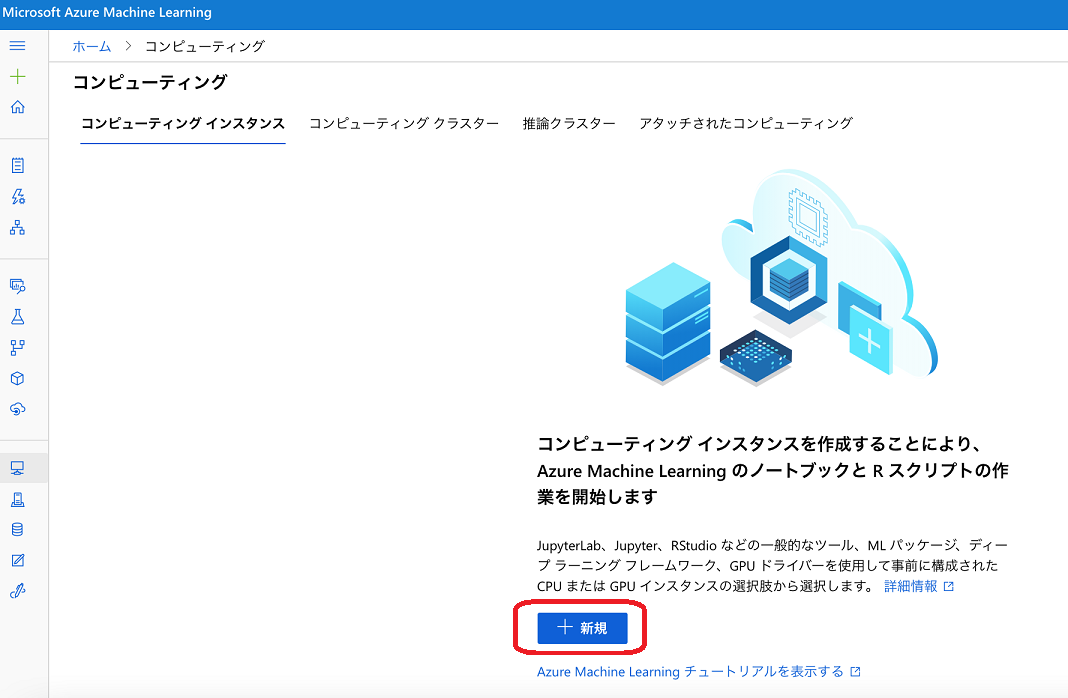
コンピューティング名、仮想マシンの種類、仮想マシンのサイズを選択してコンピューティングの作成を行います。
今回の例では、仮想マシンの種類はCPU、仮想マシンのサイズは「Standard_DS1_v2」でも十分です。
コンピューティングの稼働中は、課金が発生するため、使用しない間はコンピューティングを停止するようにしてください。
分析に必要な追加モジュールのインストール
今回の分析に必要になる追加モジュールを「Azure Machine Learningスタジオ」上のターミナルより導入します。
【今回の分析に必要になる追加モジュール】
- seaborn
-
imbalanced-learn
「Azure Machine Learningスタジオ」上のターミナルは「Notebooks」メニューを開くと起動する事ができます。
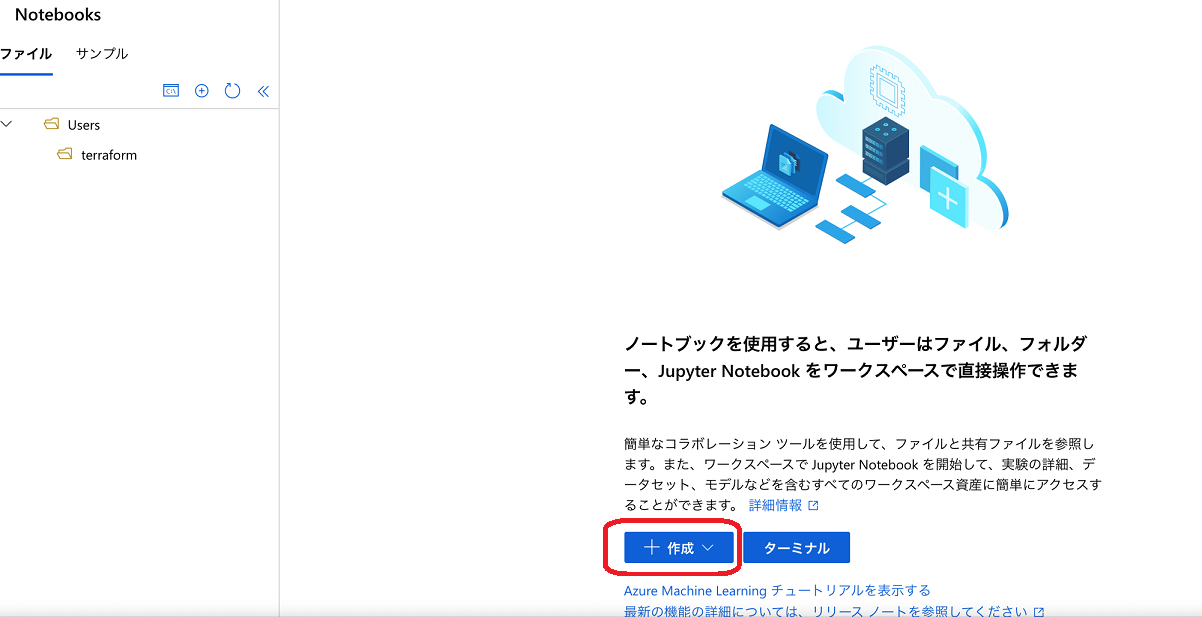
「Azure Machine Learningスタジオ」上のターミナルウインドウで以下のコマンドを入力して追加モジュールを導入します。
$ conda install seaborn
$ conda install -c conda-forge imbalanced-learn
導入後に「Azure Machine Learningスタジオ」上のコンピューティングを再起動してください。
データの分析
使用するデータセットについて
Credit Card Fraud Detectionコンベンションサイトの説明には以下の通りの説明が書かれています。
【説明文を和訳して抜粋】
データセットには、2013年9月にヨーロッパのカード所有者がクレジットカードで行った取引が含まれています。
このデータセットは、2日間に発生したトランザクションを示しており、284,807件のトランザクションのうち492件の不正が発生しています。
データセットは非常に不均衡であり、ポジティブクラス(詐欺)がすべてのトランザクションの0.172%を占めています。
これには、PCA変換の結果である数値入力変数のみが含まれます。残念ながら、機密性の問題により、データに関する元の機能や詳細な背景情報を提供することはできません。
特徴V1、V2、…V28はPCAで得られる主成分であり、PCAで変換されていない唯一の特徴は「時間」と「量」です。
機能「時間」には、各トランザクションからデータセット内の最初のトランザクションまでの経過秒数が含まれます。
機能「金額」はトランザクション金額です。この機能は、たとえば、依存するコストに敏感な学習に使用できます。
機能「クラス」は応答変数であり、不正の場合は値1を取り、それ以外の場合は値0を取ります。
つまり、creditcard.csvのV1、V2、…V28とTime、amountのカラムのデータを利用して、classを推論するコンベンションとなります。
使用するデータの説明は、コンベンションサイトに詳しく掲載されていますので、そちらを事前によく確認します。
新しいNotebookの作成
準備が整いましたので、これからデータの分析を進めていきます。「Notebooks」メニューの「作成」から「新しいファイルの作成」を選択します。
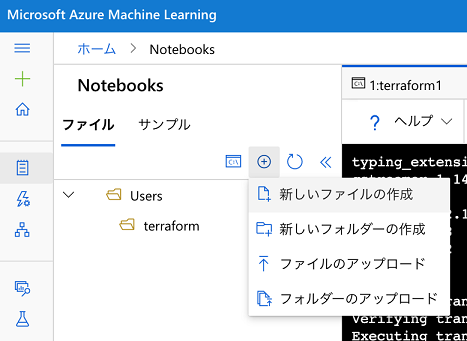
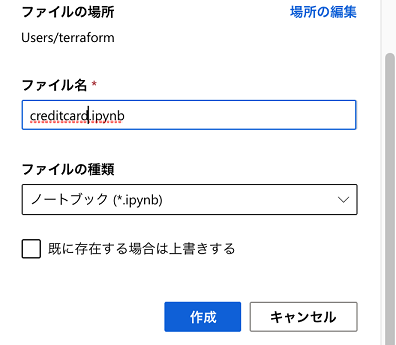
新しいファイルに名前を付けます。今回は「creditcard.ipynb」(Jupyter Notebook形式)とします。
Kaggleのコンベンションサイトからダウンロードしたデータセットをアップロードします。
「Notebooks」メニューの「作成」から「新しいファイルのアップロード」を選択してアップロードしてください。アップロードする場所は、「creditcard.ipynb」と同じフォルダ階層になるようにします。
使用するライブラリの宣言
最初に使用するライブラリを宣言します。 今回は以下のライブラリを使用します。
| No | ライブラリ | 説明 |
|---|---|---|
| 1 | numpy | 数値計算を効率的に行うための拡張モジュール |
| 2 | pandas | データ解析を支援する機能を提供するライブラリ |
| 3 | matplotlib | NumPyのためのグラフ描画ライブラリ |
| 4 | seaborn | matplotlib を拡張した表現力の高いグラフ描画ライブラリ |
| 5 | tqdm | 処理の進捗情報をプログレスバーとして表示するライブラリ |
| 6 | sklearn | scikit-learnはPythonの代表的な機械学習のライブラリ |
| 7 | xgboost | eXtreme Gradient Boosting 勾配ブースティングと呼ばれるアンサンブル学習と決定木を組み合わせたアルゴリズム |
| 8 | imblearn | 不均衡なデータのサンプリングに利用する |
最初のマークダウンのセルに以下のPythonコードを貼り付けて実行します。
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pylab as plt
import seaborn as sns
from scipy.stats import mstats
from tqdm import tqdm
from sklearn import metrics, model_selection,feature_selection, ensemble, gaussian_process, linear_model, naive_bayes, neighbors, svm, tree, discriminant_analysis, model_selection
from xgboost import XGBClassifier
from imblearn import under_sampling, over_sampling
import warnings
warnings.filterwarnings('ignore')
実行すると以下のような画面イメージになります。

データを視覚化
Pandasライブラリを使用してデータセットをロードして一部表示します。マークダウンのセルに以下のPythonコードを貼り付けて実行します。
df = pd.read_csv('./creditcard.csv')
df.head()
データセットの中身がNotebook上に表示され、正しく読み取れている事が確認できるかと思います。

各列の要約統計量の出力
Pandasのdescribeのセルを実行して結果を確認します。マークダウンのセルに以下のPythonコードを貼り付けて実行します。
df.describe()
データセットの各列の平均、標準偏差が表示されます。

不均衡データのダウンサンプリング
データセットは不均衡なデータになっているため、ダウンサンプリングして不均衡を解消します。
マークダウンのセルに以下のPythonコードを貼り付けて実行します。
col = df.columns.tolist()
col.remove('Class')
positive_cnt = int(df['Class'].sum())
rus = under_sampling.RandomUnderSampler(sampling_strategy={0:positive_cnt, 1:positive_cnt}, random_state=0)
data_x, data_y = rus.fit_resample(df[col], df[['Class']])
特徴選択
推論の精度を向上させるために特徴選択をします。
マークダウンのセルに以下のPythonコードを貼り付けて実行します。
feature_importance_models = [
ensemble.AdaBoostClassifier(),
ensemble.ExtraTreesClassifier(),
ensemble.GradientBoostingClassifier(),
ensemble.RandomForestClassifier(),
tree.DecisionTreeClassifier(),
XGBClassifier()
]
rfecv_col = pd.DataFrame(columns=['cnt'], index=col)
rfecv_col['cnt'] = 0
for i, model in tqdm(enumerate(feature_importance_models), total=len(feature_importance_models)):
rfe = feature_selection.RFECV(model, step=3)
rfe.fit(data_x, data_y)
rfe_col = df[col].columns.values[rfe.get_support()]
rfecv_col.loc[rfe_col, 'cnt'] += 1
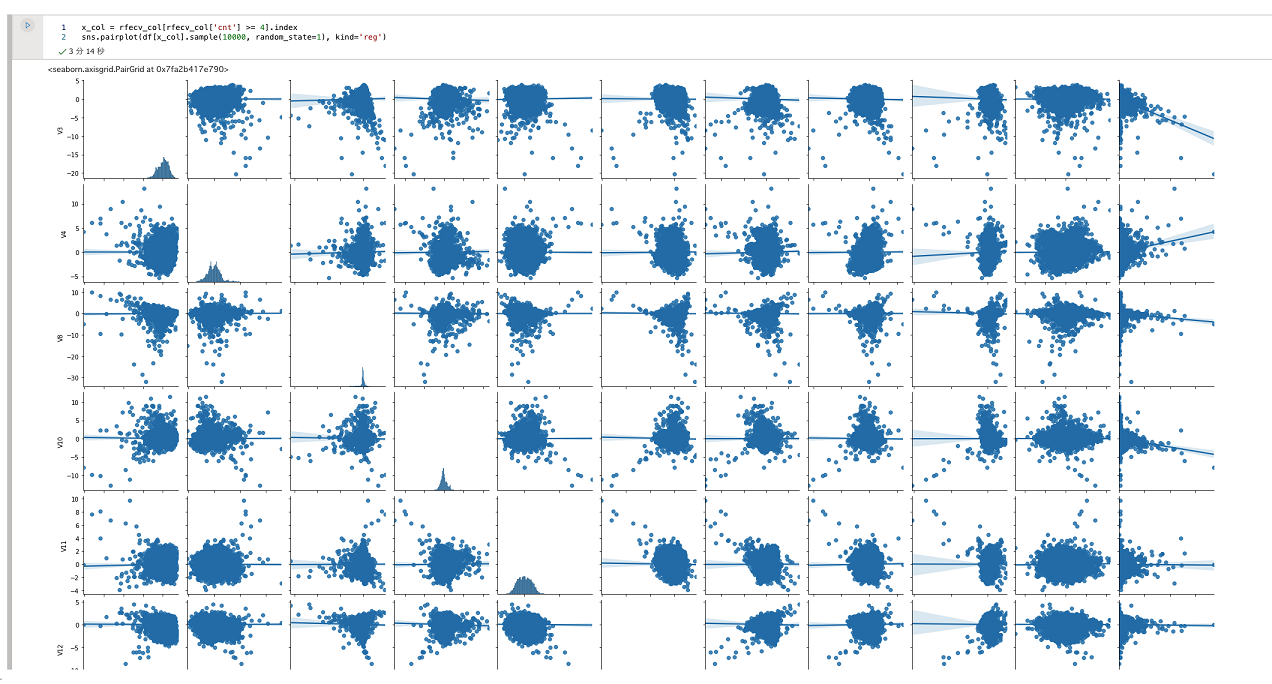
選択した特徴の傾向を視覚化
選択した特徴の傾向をseabornで可視化します。
マークダウンのセルに以下のPythonコードを貼り付けて実行します。
x_col = rfecv_col[rfecv_col['cnt'] >= 4].index
sns.pairplot(df[x_col].sample(10000, random_state=1), kind='reg')
分析とグラフの生成が終わると、以下のような画面イメージが表示されます。
ハイパーパラメータの選択
今回は推論精度と実装のわかりやすさを重視して、ランダムフォレストを採用します。ハイパーパラメータをグリッドサーチで選択します。
マークダウンのセルに以下のPythonコードを貼り付けて実行します。
model = ensemble.RandomForestClassifier()
param = [{
'n_estimators': [10, 50, 100, 300],
'criterion': ['gini', 'entropy'],
'max_depth': [2, 4, 6, 8, 10, None],
'oob_score': [True],
'random_state': [0]
}]
best_search = model_selection.GridSearchCV(estimator=model, param_grid=param, scoring='roc_auc')
best_search.fit(data_x, data_y)
best_param = best_search.best_params_
model.set_params(**best_param)
モデルをトレーニングして評価
早速モデルのトレーニングと精度評価を行います。マークダウンのセルに以下のPythonコードを貼り付けて実行します。
train_x, valid_x, train_y, valid_y = model_selection.train_test_split(data_x, data_y, test_size=0.3, random_state=0)
model.fit(train_x, train_y)
pred = model.predict(valid_x)
fig, axs = plt.subplots(ncols=2,figsize=(15,5))
sns.heatmap(metrics.confusion_matrix(valid_y, pred), vmin=0, annot=True, fmt='d', ax=axs[0])
axs[0].set_xlabel('Predict')
axs[0].set_ylabel('Ground Truth')
axs[0].set_title('Accuracy: {}'.format(metrics.accuracy_score(valid_y, pred)))
fpr, tpr, thresholds = metrics.roc_curve(valid_y, pred)
axs[1].plot(fpr, tpr, color='red')
axs[1].set_title('ROC')
axs[1].set_xlabel('FP')
axs[1].set_ylabel('TP')
axs[1].grid(True)
plt.show()
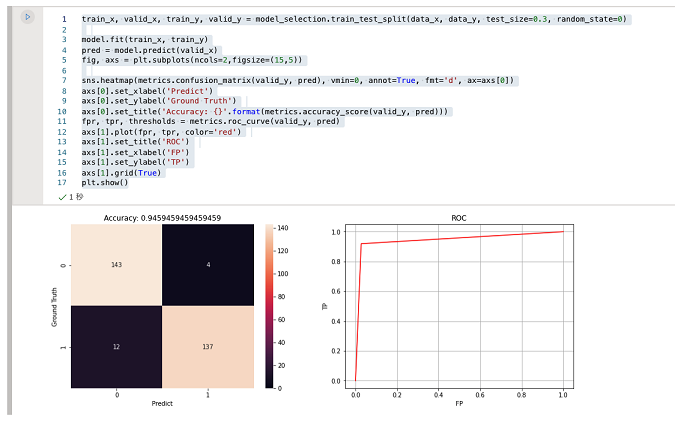
それなりの精度が得られている事が確認出来ていると思います。
データセットを利用して推論を再現
先ほどトレーニングしたモデルを使用して実際のデータセットを推論します。
マークダウンのセルに以下のPythonコードを貼り付けて実行します。
pred = model.predict(df[col])
fig, axs = plt.subplots(ncols=2,figsize=(15,5))
sns.heatmap(metrics.confusion_matrix(df[['Class']], pred), vmin=0, annot=True, fmt='d', ax=axs[0])
axs[0].set_xlabel('Predict')
axs[0].set_ylabel('Ground Truth')
axs[0].set_title('Accuracy: {}'.format(metrics.accuracy_score(df[['Class']], pred)))
fpr, tpr, thresholds = metrics.roc_curve(df[['Class']], pred)
axs[1].plot(fpr, tpr, color='red')
axs[1].set_title('ROC')
axs[1].set_xlabel('FP')
axs[1].set_ylabel('TP')
axs[1].grid(True)
plt.show()
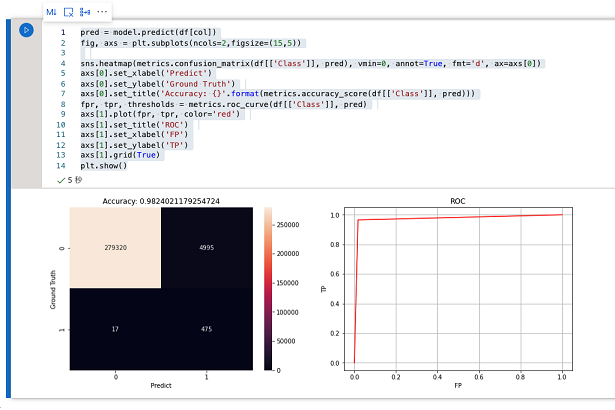
こちらも簡易的な実装にしては、それなりの精度が出来ていると思います。
実際のコンベンションに挑む場合は、より少ないリソースで高い精度を得るためのテクニックが必要になるかと思います。
リソースの削除
今回作成したAzureリソースを残しておくと、余計な課金額が発生してしまうため、作業を終える前に忘れずにリソースの削除を行います。
削除するにはターミナルで「terraform destroy -var-file init.tfvars」と入力します。
$ terraform destroy -var-file init.tfvars
・・・(省略)
Destroy complete! Resources: 6 destroyed.
念のため、Azureポータルにログインして「すべてのリソース」メニューより、不要なリソースが残っていないか確認します。
まとめ
このように、Azure Machine Learning スタジオを使用すると、 機械学習環境を簡単に構築できる事が確認いただけたかと思います。
kaggleでは世界中の企業から常時様々なコンベンションが開催されており、以下のイメージのように開催中のコンベンションと賞金額が確認できます。
これを機会に開催中のコンベンションに挑戦いただき、一攫千金を目指されてはいかがでしょうか。
わたしも、いつかはチャレンジしてみたいと思います。