データベースとは
「複数で共有」「検索、加工」される、一定の形式で整理されたデータの集まりのこと。
データベースの活用
事例1)
①facebookの自分のページにアクセス
②facebookのデータベース内にある自分の情報を探す
(氏名、メールアドレス、投稿内容、投稿した写真等)
③インターネットを経由して自分の情報を呼び出し、ブラウザ上で表示
事例2)
①ショッピングサイトにアクセスし、欲しい商品を検索
②検索条件を受け、データベース内でマッチした商品情報を探す
③インターネットを経由してマッチした商品情報を呼び出し、ブラウザ上で表示
リレーショナルデータベース(RDB)
一般的に使用されているデータベースは下記の表のようなリレーショナル・データベースである。
| 氏名 | 電話番号 | 年齢 | 住所 |
|---|---|---|---|
| 山田 太郎 | 090-0000-0000 | 20歳 | 東京都千代田区 |
| 佐藤 次郎 | 090-0000-0000 | 25歳 | 千葉県千葉市 |
| 鈴木 花子 | 090-0000-0000 | 30歳 | 神奈川県横浜市 |
表全体をtable
表の列をカラム=フィールドという
表の行をロー=レコードという
SQLとは
プログラミング言語とは違い、RDBMS(データベース管理システム/Relational DataBase Management System)専用に作られた問い合わせ言語。
SQL(Structured Query Language)
MySQLとは
MySQLは、世界で最も利用されているデータベース管理システム。
大容量のデータに対しても高速で動作し、機能も豊富で実用性が高い。
クエリとトランザクション
MySQLに限らず、データベースは、使用者が発行する命令によって動作しており、
この命令を一般にクエリという。
そのクエリの集合をトランザクションという。
それらのクエリがすべて適用できた場合のみデータベースに反映される。
一つでも適用できないクエリがあった場合、そのまとまりすべてのクエリの結果は反映されない。
コミットとロールバック
データベースのユーザーは、トランザクションにおいて、**コミット(COMMIT)とロールバック(ROLLBACK)**を行うことができる。
処理を確定する場合にはコミット、データベースに対する変更処理をすべて取り消す場合、ロールバックを行う。
※コミットを行うと、ロールバックによる処理の取り消しはできなくなる
データ型
MySQLにおけるデータ型
■整数型
| 型 | バイト | 最小値 | 最大値 |
|---|---|---|---|
| TYNYINT | 1 | -128 | 127 |
| SMALLINT | 2 | -32768 | 32767 |
| MEDIUMINT | 3 | -8388608 | 83388607 |
| INTEGER | 4 | -2147483648 | 2147483647 |
| BIGINT | 8 | -9223372036854775808 | 9223372036854775807 |
■浮動小数点型
| 型 | バイト | 最小値 | 最大値 |
|---|---|---|---|
| FLOAT | 4 | -3.4-2823466E+38〜-1.175494351E-38 | 1.175494351E-38〜3.402823466E+38 |
| DOUBLE | 8 | -1.7976931348623157E+308〜-2.2250738585072014E-308 | 2.2250738585072014E-308〜1.7976931348623157E+308 |
■文字列型
| 型 | バイト | 特徴 |
|---|---|---|
| CHAR | 255 | 固定長文字列 |
| VARCHAR | 255 | 可変長文字列 |
| TEXT | 655535 | 文章に利用 |
■日付・時刻型
| 型 | 内容 | 範囲 |
|---|---|---|
| DATETIME | 日付と時刻 | '1000-01-01 00:00:00'〜'9999-12-31 23:59:59' |
| TIMESTAMP | 日付と時刻 | '1970-01-01 00:00:01.000000'UTC〜'2038-01-19 03:14:07.999999' |
| DATE | 日付 | '1000-01-01'〜'9999-12-31 |
| TIME | 時刻 | '-838:59:59〜:838:59:59' |
| YEAR | 時刻 | '1901〜2155' |
MySQLの使用方法
①レンタルサーバーを借りて、そのサーバー上でMySQLを使用する
②Linuxサーバを自分のPCにインストールして、その上でMySQLを使用する
③XAMPPを自分のPCにインストールして、その上でMySQLを使用する
XamppとMamp
Xamppは、Windows、Linux、maxOS、Solarisなどの様々なOSと、Apache(webサーバ)
MariaDB(SQLデータベースサーバ;旧バージョンはMySQL)、PHPがパッケージになったもの。
Mampは、Xampp同様の開発環境がWindowsとmacOSのデスクトップ上で使用できる。
※macユーザーは一般的にMampを使用することが多い
テーブルの作成と削除
| 対応するSQL文 | 操作内容/意味/活用事例 |
|---|---|
| Create文 | データベースにテーブルを作成する |
| Drop文 | 作成したテーブルを削除する |
テーブルの操作
データベース操作は大きく4つに分かれる。
※CRUDと呼ばれる
| 名称 | 対応するSQL文 | 操作内容/意味/活用事例 |
|---|---|---|
| Create | insert文 | データをテーブルに書き込む。 Facebookに新規で自分の名前を登録する際には、システムの裏側で、insert文が走っている |
| Read | select文 | テーブルに入っているデータを呼び出す。 アカウントを持っているFacebookにログインした際に、自分のプロフィールや投稿内容が表示されるとき、その裏側ではselect文が走っている。 |
| Update | update文 | テーブルにすでに入っているデータを呼び出す。 facebookにすでに登録してあるメールアドレスを変更する際、その裏側ではupdate文が走っている。 |
| Delete | delete文 | テーブルにすでに入っているデータを削除する。 facebookにすでに登録してあるアカウントを削除する際に、その裏側でdelete文が走っている。 |
SQL文
データベースを操作する文のことを総称して、SQL文という。
※SQL分は、大文字小文字の区別がなく、改行してもしなくても良い
CREATE文
テーブルを作成しデータを書き込むSQL文。
CREATE TABLE 任意のテーブル名(
カラム名 データ型、 //int(数字)、varchar(文字列)、decimal(金額)等がある
カラム名 データ型
);
例)テーブル「addresslist」を作成し、user_id、name、mail、tellとういう名前のカラムを作成
CREATE TABLE addresslist(
user_id int(11),
name varchar(255),
mail varchar(255),
tell varchar(255),
prefecture varchar(255)
);
●デーブル/データベースが存在していない場合、それを作成する場合
CREATE TABLE/DETABASE if note exists テーブル名/データベース名;
INSERT文
空のテーブルにデータを挿入するSQL文。
INSERT INTO テーブル名 VALUES
("挿入するデータ","挿入するデータ","挿入するデータ");
例1)データを1行追加するinsert文
INSERT INTO addresslist VALUES
("1","山田太郎","abcd123@yahoo.co.jp","03-0000-0000","東京");
例2)データを複数行追加するinsert文
INSERT INTO addresslist VALUES
("2","佐藤花子","xyz777@yahoo.co.jp","073-0000-0000","神奈川"),
("3","田中浩史","hello888@yahoo.co.jp","045-0000-0000","静岡"),
("4","鈴木次郎","efg123@yahoo.co.jp","080-0000-0000","沖縄"),
("5","藤田三郎","ccc999@yahoo.co.jp","090-0000-0000","千葉");
SELECT文
テーブルに入っているデータを抽出するために使用するSQL文
SELECT 抽出対象のカラム名 FROM 抽出対象のテーブル名;
※すべてのカラムを対象とする場合はカラム名の箇所に「*」と記述する
例1)addresslistのすべてのデータを抽出するselect文
SELECT * FROM addresslist;
例2)addresslistの指定するカラム(name)を抽出するselect文
SELECT name FROM addresslist;
例3)addresslistのprefectureが千葉のフィールドのうち、指定するカラム(mail)を抽出するselect文
SELECT mail FROM addresslist WHERE prefecture = "千葉";
※where以下には、演算子を使用することもできる
UPDATE文
テーブルに入っているデータを上書きして更新するSQL文
UPDATE 対象のテーブル名 SET 上書き対象のカラム名 = "上書きするデータ" WHERE 上書きするフィールドの指定
例1)addresslistのuser_idが1のレコードのprefectureを埼玉に上書きするupdate文
UPDATE addresslist SET prefecture = "埼玉" WHERE user_id = 1;
DELETE文
テーブルに入っているデータを削除するSQL文
DELETE FROM 対象のテーブル名;
例2)addresslistのuser_idが3の行を削除するdelete文
DELETE FROM addresslist WHERE user_id = "3"'
ソート
SELECT文でデータを抽出する際に、データを並び替えて表示できる。
これをソートという。
SELECT カラム名 FROM テーブル名 ORDER BY カラム名 ASC;
※ascは昇順、descは降順となる、何も書かなければ昇順となる
例1)fruit_stockテーブルのすべてのデータをnumberカラムの昇順に並べ替えるソート文
SELECT * FROM fruit_stock ORDER BY number ASC;
例2)fruit_stockテーブルのすべてのデータのうち、numberが25以上のものを、priceカラムの降順に並べ替えるソート文
SELECT * FROM fruit_stock WHERE number >= 25 ORDER BY price DESC;
データの集計
select文を使って、データの合計値、最大値、平均値などのデータの集会ができる。
データの件数を取得
select count(カラム名)from テーブル名;
例1)fruit_stockテーブルのfruitカラムのデータ件数を取得するselect文
select count(fruit) from fruit_stock;
例2)fruit_stockテーブルの中から、priceが200以上で、madeinが日本のfruitカラムのデータ件数を取得する条件付きselect文
select count(fruit) from fruit_stock where price >= 200 and madein = "日本";
データの合計値を取得
select sum(カラム名) from テーブル名;
例)fruit_stockテーブルのnumberカラムの合計値を取得するselect文
select sum(number) from fruit_stock;
データの最大値を取得
select max(カラム名) from テーブル名;
データの最大値を取得
select min(カラム名) from テーブル名;
データの平均値を取得
select avg(カラム名) from テーブル名;
コマンドプロンプト/ターミナルでのMySQL操作
ターミナルでのMySQL操作の前に、以下の手順が必要。
①Xampp/Mampを起動し、ApacheとMySQLを起動
②MySQLにログインコマンドでログイン
③useコマンドで使用したいデータベースへ移動
④select、insert、descコマンドなどでデータベースを操作
ログインコマンド
| コマンド | 意味 |
|---|---|
| mysql | mysqlにログインするためのコマンド |
| -u | user(ユーザー)オプション:-uの次にユーザー名を指定し、そのアカウントでログイン |
| root | root(ルート)は最高権限をもつユーザー ※会社等の組織では、通常rootではなく、固定された権限を持つユーザーアカウントを使う |
| -p | password(パスワード)オプション:このコマンドの後にパスワードが求められる |
基本操作コマンド
| コマンド | 意味 |
|---|---|
| show | データベースやテーブルを見るためのコマンド |
| use | 使用したいデータベースへ移動するためのコマンド |
| desc | テーブルの構造やデータを見るためのコマンド |
show
データベース一覧を表示するコマンド
show databases;
use
使用したいデータベースにするコマンド
use データベース名;
show
テーブル一覧を表示するコマンド
show tables;
desc
テーブルの構造を表示するコマンド
desc テーブル名;
select
テーブルのデータを表示するコマンド
SELECT * FROM テーブル名;
drop
テーブル/データベース自体を削除するコマンド
DROP table/database テーブル名/データベース名;
デーブル/データベースが存在している場合、それを削除する
DROP table/database IF EXISTS テーブル名/データベース名;
ALTER TABLE
一度作成されたテーブルはALTER TABLEというコマンドを使用してテーブル構造の変更・削除・追加ができる。
ALTER TABLE テーブル名;
◆テーブル名を変更
ALTER TABLE テーブル名 RENAME 新しいテーブル名;
◆カラム名を変更
ALTER TABLE テーブル名 CHANGE 変更するカラム名 データ型;
◆カラムのデータ型のみを変更
ALTER TABLE テーブル名 MODIFY 変更するカラム名 新しいデータ型;
◆カラムを追加
ALTER TABLE テーブル名 ADD カラム名 データ型;
※後方にAFTER テーブル名と記述することで指定したカラム名の後ろにカラムを追加できる
◆カラムを削除
ALTER TABLE テーブル名 DROP カラム名;
--テーブルの作成
mysql> create table sumple01(
-> id int,
-> name varchar(255),
-> email varchar(255),
-> class enum("no1","no2","no3")
-> );
Query OK, 0 rows affected (0.02 sec)
--テーブルにデータを入力
mysql> insert into sumple01 values
-> (1,"田中さん","tanaka@yahoo.co.jp","no1"),
-> (2,"山田さん","yamada@gmail.com","no3"),
-> (3,"木村さん","kimura@yahoo.co.jp","no2");
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0
--テーブルをすべて表示
mysql> select * from sumple01;
+------+--------------+--------------------+-------+
| id | name | email | class |
+------+--------------+--------------------+-------+
| 1 | 田中さん | tanaka@yahoo.co.jp | no1 |
| 2 | 山田さん | yamada@gmail.com | no3 |
| 3 | 木村さん | kimura@yahoo.co.jp | no2 |
+------+--------------+--------------------+-------+
3 rows in set (0.00 sec)
--テーブルの構造を表示
mysql> desc sumple01;
+-------+-------------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(255) | YES | | NULL | |
| email | varchar(255) | YES | | NULL | |
| class | enum('no1','no2','no3') | YES | | NULL | |
+-------+-------------------------+------+-----+---------+-------+
4 rows in set (0.00 sec)
--テーブルの名前を変更
mysql> alter table sumple01 rename sample02;
Query OK, 0 rows affected (0.00 sec)
--テーブルを表示
mysql> show tables;
+--------------------+
| Tables_in_lesson02 |
+--------------------+
| sample02 |
+--------------------+
1 row in set (0.00 sec)
--テーブルの中身を表示
mysql> select * from sample02;
+------+--------------+--------------------+-------+
| id | name | email | class |
+------+--------------+--------------------+-------+
| 1 | 田中さん | tanaka@yahoo.co.jp | no1 |
| 2 | 山田さん | yamada@gmail.com | no3 |
| 3 | 木村さん | kimura@yahoo.co.jp | no2 |
+------+--------------+--------------------+-------+
3 rows in set (0.00 sec)
--idカラムをNumberカラムに名称変更
mysql> alter table sample02 change id Number int;
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
--結果の確認
mysql> select * from sample02;
+--------+--------------+--------------------+-------+
| Number | name | email | class |
+--------+--------------+--------------------+-------+
| 1 | 田中さん | tanaka@yahoo.co.jp | no1 |
| 2 | 山田さん | yamada@gmail.com | no3 |
| 3 | 木村さん | kimura@yahoo.co.jp | no2 |
+--------+--------------+--------------------+-------+
3 rows in set (0.00 sec)
--emailカラムをmailaddlessカラムに名称変更
mysql> alter table sample02 change email mailaddless varchar(255);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
--結果の確認
mysql> select * from sample02;
+--------+--------------+--------------------+-------+
| Number | name | mailaddless | class |
+--------+--------------+--------------------+-------+
| 1 | 田中さん | tanaka@yahoo.co.jp | no1 |
| 2 | 山田さん | yamada@gmail.com | no3 |
| 3 | 木村さん | kimura@yahoo.co.jp | no2 |
+--------+--------------+--------------------+-------+
3 rows in set (0.00 sec)
--テーブルの構造を表示
mysql> desc sample02;
+-------------+-------------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------------+-------------------------+------+-----+---------+-------+
| Number | int(11) | YES | | NULL | |
| name | varchar(255) | YES | | NULL | |
| mailaddless | varchar(255) | YES | | NULL | |
| class | enum('no1','no2','no3') | YES | | NULL | |
+-------------+-------------------------+------+-----+---------+-------+
4 rows in set (0.00 sec)
--classカラムの型のみをintからvarcharに変更
mysql> alter table sample02 modify class varchar(255);
Query OK, 3 rows affected (0.03 sec)
Records: 3 Duplicates: 0 Warnings: 0
--結果の確認
mysql> desc sample02;
+-------------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------------+--------------+------+-----+---------+-------+
| Number | int(11) | YES | | NULL | |
| name | varchar(255) | YES | | NULL | |
| mailaddless | varchar(255) | YES | | NULL | |
| class | varchar(255) | YES | | NULL | |
+-------------+--------------+------+-----+---------+-------+
4 rows in set (0.00 sec)
--テーブルの中身を表示
mysql> select * from sample02;
+--------+--------------+--------------------+-------+
| Number | name | mailaddless | class |
+--------+--------------+--------------------+-------+
| 1 | 田中さん | tanaka@yahoo.co.jp | no1 |
| 2 | 山田さん | yamada@gmail.com | no3 |
| 3 | 木村さん | kimura@yahoo.co.jp | no2 |
+--------+--------------+--------------------+-------+
3 rows in set (0.00 sec)
--ageカラムを追加
mysql> alter table sample02 add age int;
Query OK, 0 rows affected (0.05 sec)
Records: 0 Duplicates: 0 Warnings: 0
--結果の確認
mysql> select * from sample02;
+--------+--------------+--------------------+-------+------+
| Number | name | mailaddless | class | age |
+--------+--------------+--------------------+-------+------+
| 1 | 田中さん | tanaka@yahoo.co.jp | no1 | NULL |
| 2 | 山田さん | yamada@gmail.com | no3 | NULL |
| 3 | 木村さん | kimura@yahoo.co.jp | no2 | NULL |
+--------+--------------+--------------------+-------+------+
3 rows in set (0.00 sec)
--classカラムの削除
mysql> alter table sample02 drop class;
Query OK, 0 rows affected (0.05 sec)
Records: 0 Duplicates: 0 Warnings: 0
--結果の確認
mysql> select * from sample02;
+--------+--------------+--------------------+------+
| Number | name | mailaddless | age |
+--------+--------------+--------------------+------+
| 1 | 田中さん | tanaka@yahoo.co.jp | NULL |
| 2 | 山田さん | yamada@gmail.com | NULL |
| 3 | 木村さん | kimura@yahoo.co.jp | NULL |
+--------+--------------+--------------------+------+
3 rows in set (0.00 sec)
テーブル結合
テーブル結合とは、作成してある既存のテーブル同士をつなぎ合わせて表示すること。
| 結合の種類 | コマンド/書き方 | 意味/使い方 | |
|---|---|---|---|
| 内部結合 | INNNER JOIN / JOIN | それぞれのテーブルの指定した列の値が一致するデータだけを取得する。 nullとしてデータは取得しない。 | |
| 外部結合 | 左外部結合 | LEFT OUTER JOIN / LEFT JOIN | それぞれのテーブルの指定した列の値が一致しない場合も、 nullとしてデータを取得。左のテーブル(selectの右に記述するテーブル)を基準にして結合。 |
| 右外部結合 | RIGHT OUTER JOIN / RIGHT JOIN | それぞれのテーブルの指定した列の値が一致しない場合も、 nullとしてデータを取得。右のテーブル(joinの右に記述するテーブル)を基準にして結合。 | |
内部結合(INNER JOIN)
テーブル①とテーブル②を比較し、結合条件に合ったテーブル内の値を表示する
SELECT カラム名 FROM テーブル名①
INNER JOIN テーブル名② ON 結合の条件
※テーブル①の中で、結合の条件と合致したデータをテーブル②から取得する
左外部結合(LEFT OUTER JOIN)
テーブル①を基準として、テーブル②から結合条件に合ったデータを取得し、テーブル①に結合して表示する
SELECT カラム名 FROM テーブル名①
LEFT OUTER JOIN テーブル名② ON 結合の条件
※テーブル①が基準となり、結合の条件と合致したデータをテーブル②から取得する
右外部結合(RIGHT OUTER JOIN)
テーブル①を基準として、テーブル②から結合条件に合ったデータを取得し、テーブル①に結合して表示する
SELECT カラム名 FROM テーブル名②
LEFT OUTER JOIN テーブル名① ON 結合の条件
※テーブル①が基準となり、結合の条件と合致したデータをテーブル②から取得する
まとめると、
・内部結合(INNER JOIN/JOIN)
結合しようとする各テーブルにおいて、ONの条件に合うカラムのデータが一致するデータのみを取得。
・左外部結合(LEFT OUTER JOIN)
左側に書いたテーブルにあるデータを基準として、ONの条件に合うカラムのデータを取得。
右側のテーブルでデータがない場合は、NULLとして取得する。
・右外部結合(RIGHT OUTER JOIN)
右側に書いたテーブルにあるデータを基準として、ONの条件に合うカラムのデータを取得。
左側のテーブルでデータがない場合は、NULLとして取得する。
--fruitsデータベースの作成
mysql> create database fruits;
Query OK, 1 row affected (0.00 sec)
--fruitsデータベースの使用の宣言
mysql> use fruits;
Database changed
--table_aテーブルの作成
mysql> create table table_a(
-> fruit_a int, name varchar(255), price int)
-> ;
Query OK, 0 rows affected (0.03 sec)
--table_aテーブルにデータを入力
mysql> insert into table_a values
-> (1,"りんご",100),
-> (2,"みかん",150),
-> (3,"バナナ",140);
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0
--table_aのデータの確認
mysql> select * from table_a;
+---------+-----------+-------+
| fruit_a | name | price |
+---------+-----------+-------+
| 1 | りんご | 100 |
| 2 | みかん | 150 |
| 3 | バナナ | 140 |
+---------+-----------+-------+
3 rows in set (0.00 sec)
--table_bテーブルの作成
mysql> create table table_b(
-> fruit_id int, place varchar(255), stock int);
Query OK, 0 rows affected (0.03 sec)
----table_bテーブルにデータを入力
mysql> insert into table_b values
-> (1,"青森",5),
-> (2,"愛媛",30),
-> (3,"沖縄",20),
-> (4,"東京",50),
-> (5,"長野",10),
-> (6,"和歌山",25);
Query OK, 6 rows affected (0.00 sec)
Records: 6 Duplicates: 0 Warnings: 0
--table_bのデータの確認
mysql> select * from table_b;
+----------+-----------+-------+
| fruit_id | place | stock |
+----------+-----------+-------+
| 1 | 青森 | 5 |
| 2 | 愛媛 | 30 |
| 3 | 沖縄 | 20 |
| 4 | 東京 | 50 |
| 5 | 長野 | 10 |
| 6 | 和歌山 | 25 |
+----------+-----------+-------+
6 rows in set (0.00 sec)
--table_cテーブルの作成
mysql> create table table_c(
-> place varchar(225), shopping_fee int
-> );
Query OK, 0 rows affected (0.02 sec)
--table_cにデータを入力
mysql> insert into table_c values
-> ("青森",400),
-> ("愛媛",400),
-> ("沖縄",650),
-> ("東京",250),
-> ("長野",350),
-> ("和歌山",350);
Query OK, 6 rows affected (0.01 sec)
Records: 6 Duplicates: 0 Warnings: 0
--table_cの構造の確認
mysql> select * from table_c;
+-----------+--------------+
| place | shopping_fee |
+-----------+--------------+
| 青森 | 400 |
| 愛媛 | 400 |
| 沖縄 | 650 |
| 東京 | 250 |
| 長野 | 350 |
| 和歌山 | 350 |
+-----------+--------------+
6 rows in set (0.00 sec)
--table_aのfruit_aカラムをfruit_idに名称変更
mysql> alter table table_a change fruit_a fruit_id int;
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
--内部結合
mysql> select * from table_a INNER JOIN table_b on table_a.fruit_id = table_b.fruit_id;
+----------+-----------+-------+----------+--------+-------+
| fruit_id | name | price | fruit_id | place | stock |
+----------+-----------+-------+----------+--------+-------+
| 1 | りんご | 100 | 1 | 青森 | 5 |
| 2 | みかん | 150 | 2 | 愛媛 | 30 |
| 3 | バナナ | 140 | 3 | 沖縄 | 20 |
+----------+-----------+-------+----------+--------+-------+
3 rows in set (0.00 sec)
--table_bのfruit_idが5のものを1に変更
mysql> update table_b set fruit_id = 1 where fruit_id = 5;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
--table_bの構造の確認(上記変更の確認)
mysql> select * from table_b;
+----------+-----------+-------+
| fruit_id | place | stock |
+----------+-----------+-------+
| 1 | 青森 | 5 |
| 2 | 愛媛 | 30 |
| 3 | 沖縄 | 20 |
| 4 | 東京 | 50 |
| 1 | 長野 | 10 |
| 6 | 和歌山 | 25 |
+----------+-----------+-------+
6 rows in set (0.00 sec)
--table_bのfruit_idが6のものを2に変更
mysql> update table_b set fruit_id = 2 where fruit_id = 6;
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
--table_bの構造の確認(上記変更の確認)
mysql> select * from table_b;
+----------+-----------+-------+
| fruit_id | place | stock |
+----------+-----------+-------+
| 1 | 青森 | 5 |
| 2 | 愛媛 | 30 |
| 3 | 沖縄 | 20 |
| 4 | 東京 | 50 |
| 1 | 長野 | 10 |
| 2 | 和歌山 | 25 |
+----------+-----------+-------+
6 rows in set (0.00 sec)
--内部結合
mysql> select * from table_a INNER JOIN table_b on table_a.fruit_id = table_b.fruit_id;
+----------+-----------+-------+----------+-----------+-------+
| fruit_id | name | price | fruit_id | place | stock |
+----------+-----------+-------+----------+-----------+-------+
| 1 | りんご | 100 | 1 | 青森 | 5 |
| 2 | みかん | 150 | 2 | 愛媛 | 30 |
| 3 | バナナ | 140 | 3 | 沖縄 | 20 |
| 1 | りんご | 100 | 1 | 長野 | 10 |
| 2 | みかん | 150 | 2 | 和歌山 | 25 |
+----------+-----------+-------+----------+-----------+-------+
5 rows in set (0.00 sec)
--table_aの構造の確認
mysql> select * from table_a;
+----------+-----------+-------+
| fruit_id | name | price |
+----------+-----------+-------+
| 1 | りんご | 100 |
| 2 | みかん | 150 |
| 3 | バナナ | 140 |
+----------+-----------+-------+
3 rows in set (0.01 sec)
--table_bの構造の確認
mysql> select * from table_b;
+----------+-----------+-------+
| fruit_id | place | stock |
+----------+-----------+-------+
| 1 | 青森 | 5 |
| 2 | 愛媛 | 30 |
| 3 | 沖縄 | 20 |
| 4 | 東京 | 50 |
| 1 | 長野 | 10 |
| 2 | 和歌山 | 25 |
+----------+-----------+-------+
6 rows in set (0.00 sec)
--table_cの構造の確認
mysql> select * from table_c;
+-----------+--------------+
| place | shopping_fee |
+-----------+--------------+
| 青森 | 400 |
| 愛媛 | 400 |
| 沖縄 | 650 |
| 東京 | 250 |
| 長野 | 350 |
| 和歌山 | 350 |
+-----------+--------------+
6 rows in set (0.00 sec)
--table_bのplaceカラムをplace_idに名称変更
mysql> alter table table_b change place place_id varchar(255);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
--table_bの構造の確認(上記変更の確認)
mysql> select * from table_b;
+----------+-----------+-------+
| fruit_id | place_id | stock |
+----------+-----------+-------+
| 1 | 青森 | 5 |
| 2 | 愛媛 | 30 |
| 3 | 沖縄 | 20 |
| 4 | 東京 | 50 |
| 1 | 長野 | 10 |
| 2 | 和歌山 | 25 |
+----------+-----------+-------+
6 rows in set (0.00 sec)
--内部結合
mysql> select * from table_b INNER JOIN table_c on table_b.place_id = table_c.place;
+----------+-----------+-------+-----------+--------------+
| fruit_id | place_id | stock | place | shopping_fee |
+----------+-----------+-------+-----------+--------------+
| 1 | 青森 | 5 | 青森 | 400 |
| 2 | 愛媛 | 30 | 愛媛 | 400 |
| 3 | 沖縄 | 20 | 沖縄 | 650 |
| 4 | 東京 | 50 | 東京 | 250 |
| 1 | 長野 | 10 | 長野 | 350 |
| 2 | 和歌山 | 25 | 和歌山 | 350 |
+----------+-----------+-------+-----------+--------------+
6 rows in set (0.00 sec)
--左外部結合
mysql> SELECT
-> * from table_b left outer join table_a on table_a.fruit_id = table_b.fruit_id;
+----------+-----------+-------+----------+-----------+-------+
| fruit_id | place_id | stock | fruit_id | name | price |
+----------+-----------+-------+----------+-----------+-------+
| 1 | 青森 | 5 | 1 | りんご | 100 |
| 1 | 長野 | 10 | 1 | りんご | 100 |
| 2 | 愛媛 | 30 | 2 | みかん | 150 |
| 2 | 和歌山 | 25 | 2 | みかん | 150 |
| 3 | 沖縄 | 20 | 3 | バナナ | 140 |
| 4 | 東京 | 50 | NULL | NULL | NULL |
+----------+-----------+-------+----------+-----------+-------+
6 rows in set (0.00 sec)
--右外部結合
mysql> select * from table_a RIGHT OUTER JOIN table_b on table_a.fruit_id = table_b.fruit_id;
+----------+-----------+-------+----------+-----------+-------+
| fruit_id | name | price | fruit_id | place_id | stock |
+----------+-----------+-------+----------+-----------+-------+
| 1 | りんご | 100 | 1 | 青森 | 5 |
| 1 | りんご | 100 | 1 | 長野 | 10 |
| 2 | みかん | 150 | 2 | 愛媛 | 30 |
| 2 | みかん | 150 | 2 | 和歌山 | 25 |
| 3 | バナナ | 140 | 3 | 沖縄 | 20 |
| NULL | NULL | NULL | 4 | 東京 | 50 |
+----------+-----------+-------+----------+-----------+-------+
6 rows in set (0.00 sec)
☆データベース「sqlkadaidb」を作成
mysql> create database sqlkadaidb;
Query OK, 1 row affected (0.01 sec)
☆「sqlkadaidb」を使用
mysql> use sqlkadaidb
Database changed
☆「userlist」テーブルを作成
mysql> create table userlist (
-> id INT (11) primary key auto_increment,
-> user_name VARCHAR(255) not NULL,
-> age INT (11) not NULL,
-> address VARCHAR(255) not NULL
-> );
Query OK, 0 rows affected (0.04 sec)
☆テーブル確認
mysql> desc userlist
-> ;
+-----------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-----------+--------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| user_name | varchar(255) | NO | | NULL | |
| age | int(11) | NO | | NULL | |
| address | varchar(255) | NO | | NULL | |
+-----------+--------------+------+-----+---------+----------------+
4 rows in set (0.00 sec)
☆テーブルにカラムを登録(idはauto_incrementなのでそれ以外のカラムに1行だけ追加する方式)
mysql> insert into userlist (user_name, age, address) values ("山田", "35", "東京都");
Query OK, 1 row affected (0.00 sec)
できた。
☆全てのカラムに一気にデータを入れる方式
mysql> insert into userlist values
-> ("2", "佐藤", "28", "神奈川県"),
-> ("3", "門前", "22", "千葉県"),
-> ("4", "鈴木", "31", "東京都");
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0
☆もう一行追加
mysql> insert into userlist (user_name, age, address) values ("田中", "26", "埼玉県");
Query OK, 1 row affected (0.01 sec)
☆テーブル確認
mysql> select * from userlist;
+----+-----------+-----+--------------+
| id | user_name | age | address |
+----+-----------+-----+--------------+
| 1 | 山田 | 35 | 東京都 |
| 2 | 佐藤 | 28 | 神奈川県 |
| 3 | 門前 | 22 | 千葉県 |
| 4 | 鈴木 | 31 | 東京都 |
| 5 | 田中 | 26 | 埼玉県 |
+----+-----------+-----+--------------+
5 rows in set (0.00 sec)
☆「age」が25歳以上のデータを全て抽出
mysql> select * from userlist where age >= 25;
+----+-----------+-----+--------------+
| id | user_name | age | address |
+----+-----------+-----+--------------+
| 1 | 山田 | 35 | 東京都 |
| 2 | 佐藤 | 28 | 神奈川県 |
| 4 | 鈴木 | 31 | 東京都 |
| 5 | 田中 | 26 | 埼玉県 |
+----+-----------+-----+--------------+
4 rows in set (0.00 sec)
☆「address」が東京都以外のデータを全て抽出
mysql> select * from userlist where address != "東京都";
+----+-----------+-----+--------------+
| id | user_name | age | address |
+----+-----------+-----+--------------+
| 2 | 佐藤 | 28 | 神奈川県 |
| 3 | 門前 | 22 | 千葉県 |
| 5 | 田中 | 26 | 埼玉県 |
+----+-----------+-----+--------------+
3 rows in set (0.00 sec)
☆鈴木さんの「address」を神奈川県に変更
mysql> update userlist set address = "神奈川" where user_name = "鈴木";
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from userlist;
+----+-----------+-----+--------------+
| id | user_name | age | address |
+----+-----------+-----+--------------+
| 1 | 山田 | 35 | 東京都 |
| 2 | 佐藤 | 28 | 神奈川県 |
| 3 | 門前 | 22 | 千葉県 |
| 4 | 鈴木 | 31 | 神奈川 |
| 5 | 田中 | 26 | 埼玉県 |
+----+-----------+-----+--------------+
5 rows in set (0.00 sec)
☆「県」をつけ忘れてました
mysql> update userlist set address = "神奈川県" where user_name = "鈴木";
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
☆テーブル確認
mysql> select * from userlist;
+----+-----------+-----+--------------+
| id | user_name | age | address |
+----+-----------+-----+--------------+
| 1 | 山田 | 35 | 東京都 |
| 2 | 佐藤 | 28 | 神奈川県 |
| 3 | 門前 | 22 | 千葉県 |
| 4 | 鈴木 | 31 | 神奈川県 |
| 5 | 田中 | 26 | 埼玉県 |
+----+-----------+-----+--------------+
5 rows in set (0.00 sec)
☆「user_name」が山田のデータを削除
mysql> delete from userlist where user_name = "山田";
Query OK, 1 row affected (0.00 sec)
☆テーブル確認
mysql> select * from userlist;
+----+-----------+-----+--------------+
| id | user_name | age | address |
+----+-----------+-----+--------------+
| 2 | 佐藤 | 28 | 神奈川県 |
| 3 | 門前 | 22 | 千葉県 |
| 4 | 鈴木 | 31 | 神奈川県 |
| 5 | 田中 | 26 | 埼玉県 |
+----+-----------+-----+--------------+
4 rows in set (0.00 sec)
フィールドオプション
テーブル作成のオプション
create tableを使う際に使用する主なオプション
●NOT NULL
入力を必須とする
●AUTO_INCREMENT
連続した数値を自動でカラムに格納する
create table テーブル名 (カラム名 カラムのデータ型 AUTO_INCREMENT);
●PRIMARY KEY(主キー)
PRIMARY KEYが指定されたカラムは、重複禁止のインデックスとして定義され、NOT NULL成約が自動的に付与される
データベースのデータを一意に識別するための項目で、項目を主キーとして使うには
・中身が空でない
・中身がキー内で重複していない(一意である)
必要がある
●UNIQUE 重複した値を登録できなくする
UNIQUEが指定されたカラムは、重複禁止のインデックスとして定義され、NULLを許容する
●FOREGN KEY
外部テーブルとリンクするためのキー
他のテーブルのカラムを参照するキー
参照先である他テーブルのカラムに登録されている値以外を登録できなくする
create table table1(
id INT(11) PRYMARY KEY AUTO_INCREMENT, /*primary keyとauto_incrementの指定*/
column1 VARCAHR(255) NOT NULL, /*not nullの指定*/
column2 VARCHAR(255) UNIQIE, /*uniqueの指定*/
/*foregn keyの使い方*/
FOREGN KEY(column1) 参照先テーブル名 REFERENCES 参照テーブル名(カラム名)
);
データベース設計
データベース設計
現実の世界を抽象化してデータモデルを作成していく作業のこと。
データモデル
データベースをどのように構成するかということを定義したもの。
※リレーショナルデータベースだったら、リレーショナルモデルというのがある
データモデリング
データモデリングは以下の段階を通して行われる。
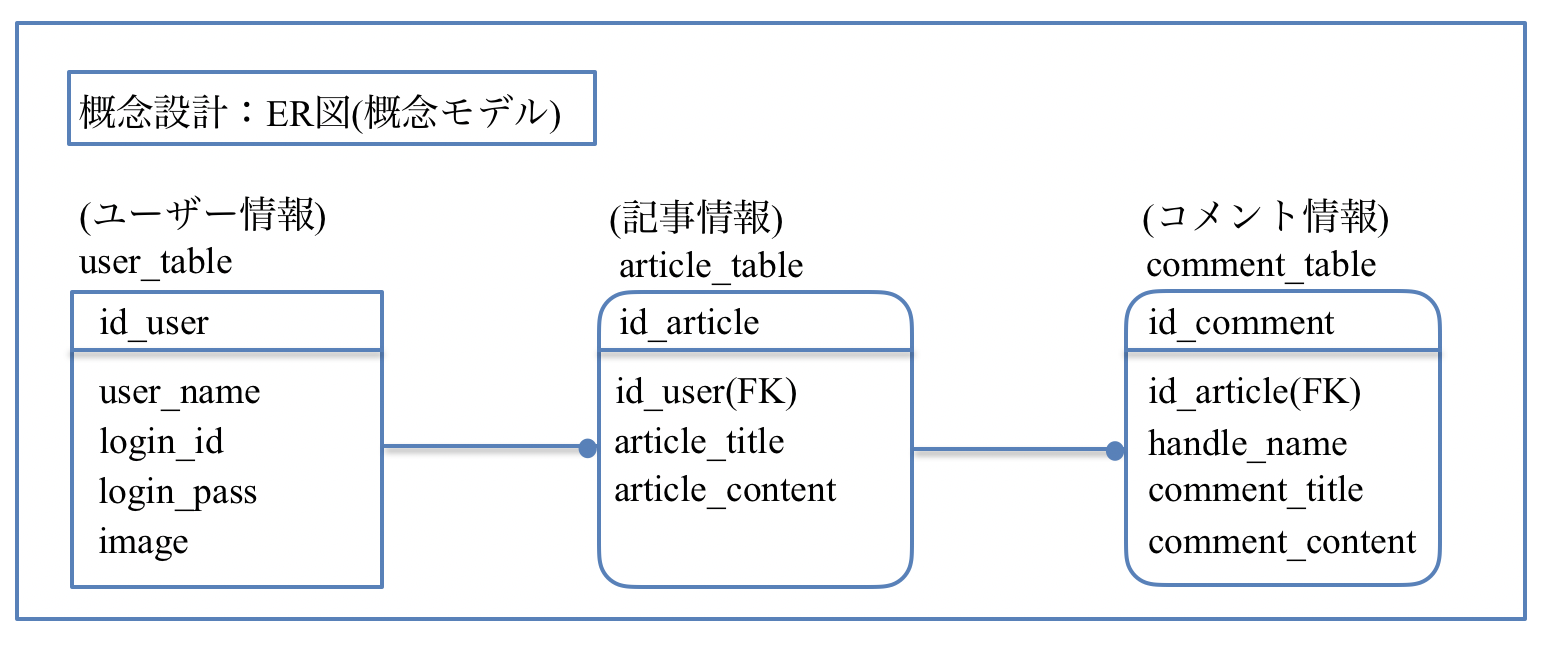
①概念設計→概念モデルを作成
データベースによって管理の対象とするものを現実世界から抽出して概念モデルを作成
概念モデルは、最終的にRDBでデータを扱うとしても、特定のデータモデルを意識して作成するものではない。
概念モデルを作成するに当たり、ERモデル(実体参照モデル)がよく使用される。
ERモデルでは、実態(Entity)と関連(Relation)によってモデルを作成する。
実態や関連は属性を持つことができる。
②論理設計→論理モデルを作成
概念設計によって作成された概念モデルを特定のデータモデルに対応した論理モデルに変換する。
RDBであれば、ERモデルからリレーショナルモデルを作成する。
ERモデル→リレーショナルモデルへの変換は機械的に行えるが、そのままでは適切な形式にならない場合がある。
そのため、論理設計ではテーブルをリレーショナルモデルとして適切に変換する作業である正規化を行う。
正規化を行うことで、データの冗長性や不具合の発生を減少させることができる。
また、ERモデルにおける属性をテーブルの列として、データ型を決定し、テーブルや列に対して制約を定義するといったことも、この段階において行う。
③物理設計→物理モデルを作成
データベースの性能について考慮する。
論理設計で正規化したテーブルの定義を崩したり、インデックスを定義して性能が向上するようにモデルを修正していく。
物理設計によってい修正されたモデルを物理モデルと呼び、このモデルを実際にデータベースによって管理する
正規化...
データベース上で扱うデータの重複を排除して、矛盾の発生を設計レベルで防ぐことが目的。
IDEF1X...
IDEF(Integration Definition)と呼ばれるモデリング方法の一つ。
システムを様々な側面から分析してモデリングを行う。
おもにデータベースの概念設計でER図を既述する方法として使用される。
MySQLのパスワード変更
mysql> set password=password('新パスワード');