はじめに
以下の方に向けた記事です。
・何かの用途でスクレイピングなどでWebで表示した情報を抽出したい人
・BeatifulSoupやNokogiriなどを使おうか検討している人。
上記のため、ライブラリを試したり、実装することが目的の人には向きません。
スクレイピングで得られる結果を最短で求めている人向けです。
スクレイピングとは
注意事項
主訴
開発や実装をせずに目的を達成するために、スクレイピングを実装する。
スクレイピングのライブラリなどを実装したい場合は、別記事を探してください。
本稿では紹介しません。
ゴール
この記事では、Webページに表示されているHTMLの
テキストやリンクなどを抽出することをゴールとします。
この拡張機能は、Webページ内のテキスト・リンク・画像などを自動で抽出できます。
具体的なイメージとして以下の画像を見てください。
※画像はイメージで実際にスクレイピングは実行していません。
この画像は、抽出するデータのセレクター指定した時の画面です。
該当の項目を2箇所以上クリックすることで要素を自動的に検知してくれます。
この機能を利用して開発しないスクレイピングをやっていきましょう。
準備編
今回はWeb Scraper - Free Web Scrapingを使用します。
上記リンクからchoromeウェブストアに遷移します。
以下画像のような拡張機能の紹介ページになっているので、
[choromeに追加]ボタンを押下してください。

インストール完了後は以下の画面に遷移します。
このサイトでアカウントを作ってログインは、今回ご紹介する機能では不要です。
今後の運用次第で検討してみてください。

設定編
さて使い方ですが、このツールはChromeの開発者ツール(developperTool)で設定をしていきます。
非エンジニアの方にとっては、触るのがちょっと怖い画面かもしれませんので、画像を付けながら
説明していくので一緒にやってみましょう。
今回はあくまでスクレイピングをするまでの手順をご案内します。
実際のサイトが、スクレイピングなどを行なって良いかという観点は
robot.txtを参考にしてご自身で判断してみてください。
今回、公式が用意しているテストサイトがあるのでそちらを利用します。
以下いずれかの方法で開発者ツールを起動します。
・F12キーを押す
・右クリックで検証を押す
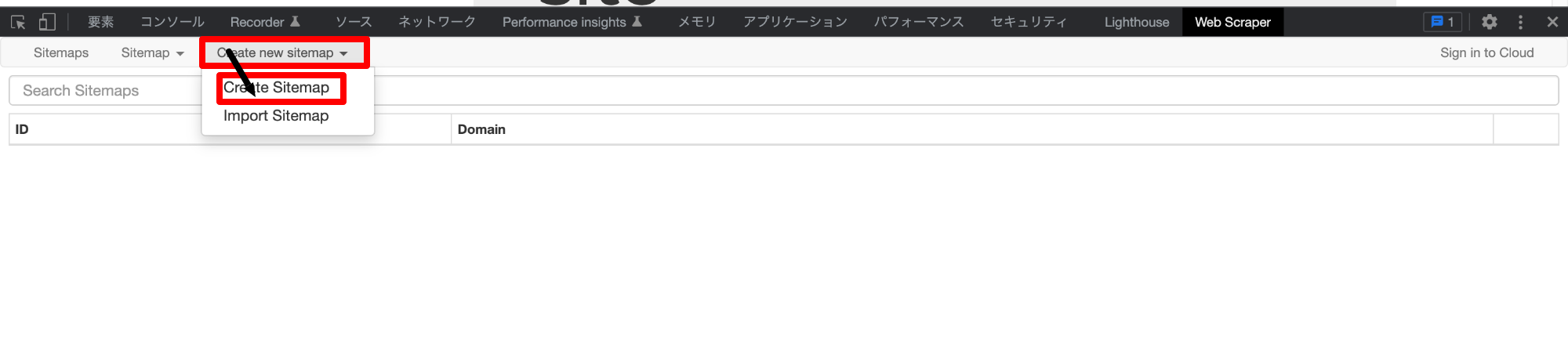
画像の赤い部分にある[Web Scraper]の項目をクリックしてください。

上記をクリックすると、[Web Scraper]メニューに遷移します。
まずはどのサイトでスクレピングをするのかを登録します。
メニューの[create new sitemap]を押下し、サブメニューの[create sitemap]を押下します。
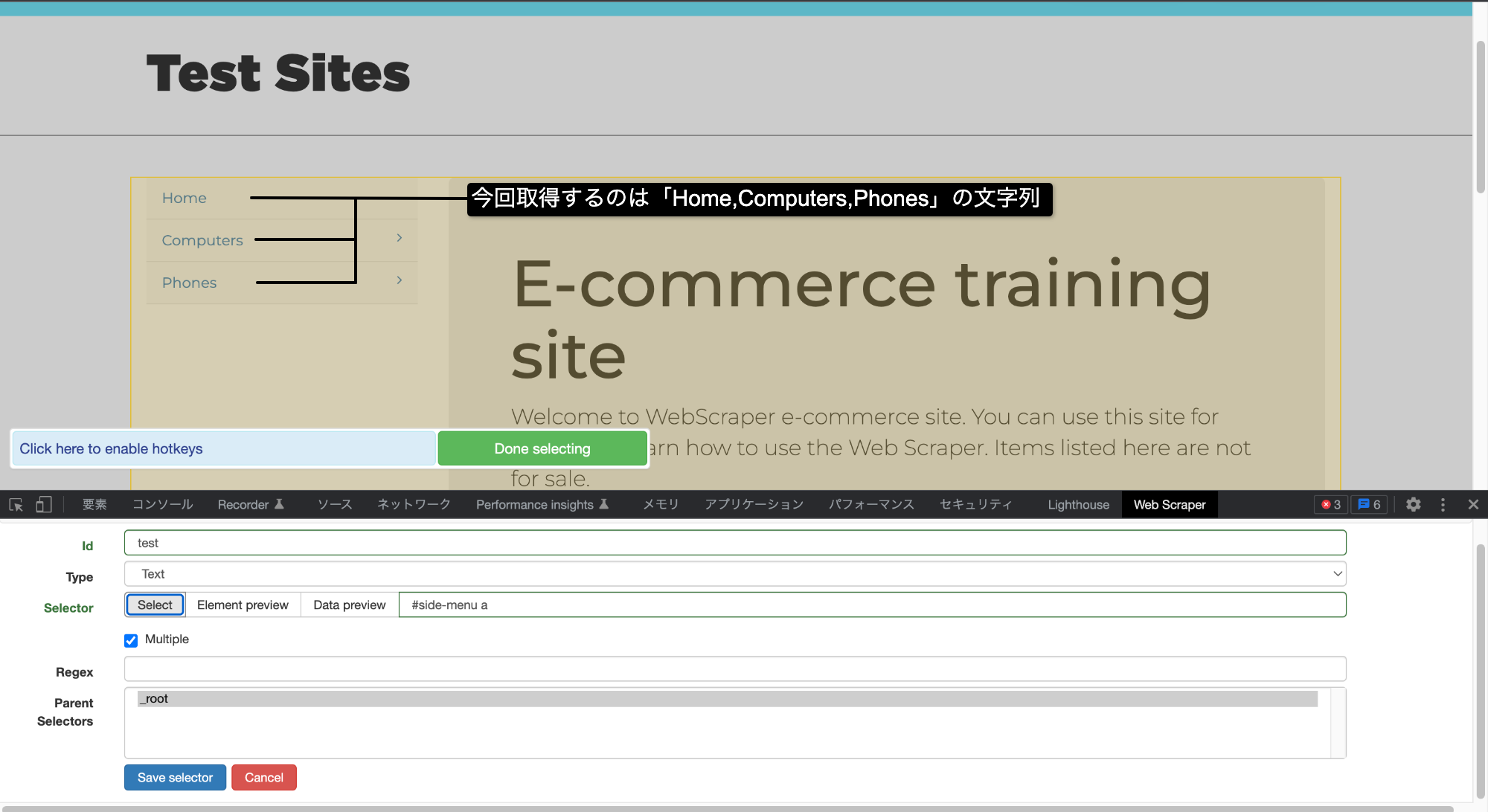
任意の名前とURLを入力して、[create sitemap]ボタンを押下してください。

最上位のsitemapが出来上がったので、どの値をスクレイピングするか
[Add new selector]ボタンでセレクターを登録していきましょう。

※セレクタとはどの要素を抽出するか判定する際の名称です。
webscraperではあまり意識しなくても大丈夫です。
上記の抽象概念が理解できていれば大丈夫なので、ここでは詳しくは説明しません。
公式ドキュメントがあるので気になる方はこちらを参照してください。
さて、以下が[Add new selector]後の画面です。
フォーム形式になっており、それぞれ画面の意味を説明します。
id:セレクタの任意の認証
Type:取得する要素の種類
Selector:セレクタ、クリックで選択して、選択ができているかプレビューで確認できます。
Multiples:要素が複数ある場合はこのチェックボックスにレ点を入れてください。
Regex:正規表現ですが、今回は使用しません。

ちなみにTypeは全13種類あります。
よく使うにはText Link Image Tableあたりです。
取得する要素が何に該当するかは、検証のページソースから判断してみてください。
今回はTextにします。

ここからは肝心のセレクターの要素を選択し、抽出したいデータを取得します。
画像の通り、[selector]ボタンをクリックします。

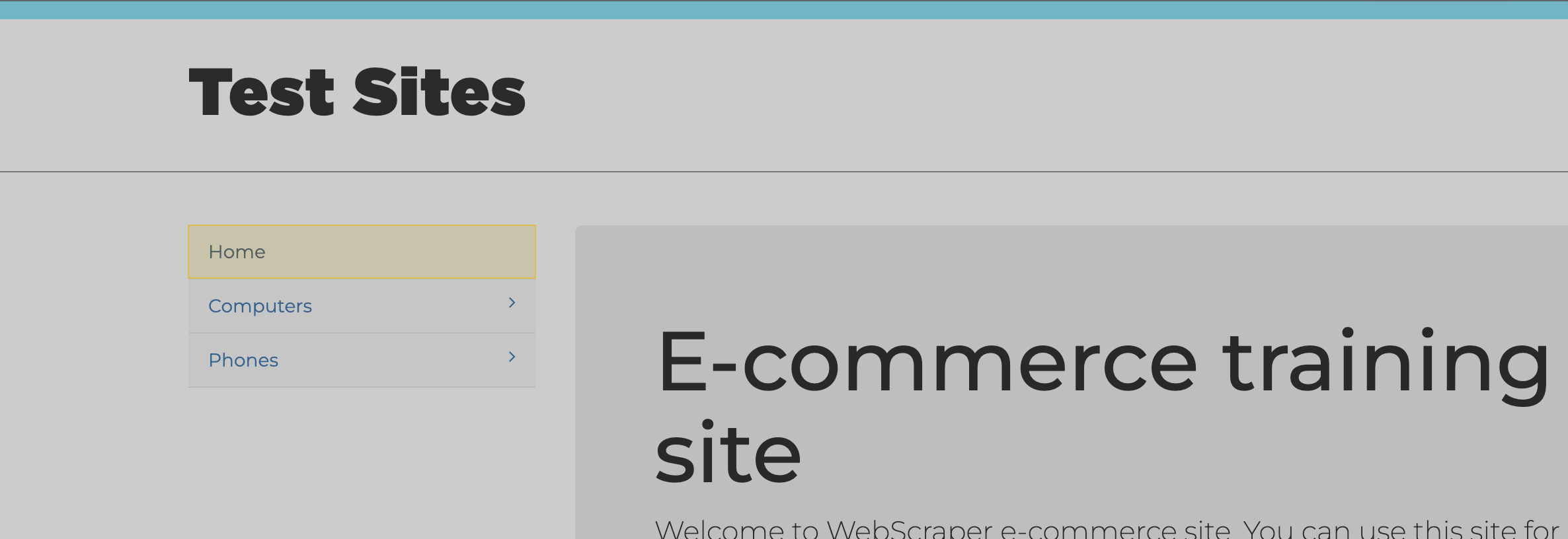
今回はこのテストサイトのメニュー名の「Home,Computers,Phones」3つを取得します。
まず、selector押下状態で[Home]の要素にマウスを持っていくと、
Homeの要素が黄色く色づきます。
ここで黄色になった箇所をクリックすると赤くなります。

赤くなった箇所はスクレイピングの抽出対象となります。
選択した箇所が1つで良い場合は、[Done selecting]を押下し、確定します。

複数選択したい場合は、1つ目の要素から連続する同じ要素をクリックすると
類似する連続した要素を自動で選択されます。
難しい言い方になりましたが、似たような要素を自動で取得します。
選択したい要素が設定できたら、[Done selecting]を押下し、確定します。

複数の要素を選択している場合は、Multipleにチェックを入れてください。

取得したい値がきちんと取れているかプレビューをしましょう。

プレビュー画面は以下のような表示になります。
取得したい値が取れているかを確認してください。

選択が終わったら、[Save Selector]ボタンをクリックします。
これで設定が完了しました。

実行編
設定したスクレイピングを実行する方法について説明します。
以下の画像と赤いメニューの「Scrape」を選択します。

実行時の速度設定します。
取得先のサーバーに配慮した設定をお願いしてください。
値を設定したら、[Start Scraping]ボタンを押下してください。

Web Sctaperのメニューに戻って[Browse]を選択します。
以下の画像の形でスクレピングが完了しています。

補足編
スクレイピングしたデータはCSVにしてインポートすることが可能です。
画像の[Export data]をクリックします。

エクスポートの形は選べます。
このデータはtextのみですが、tableやlinkではより実用的なデータとなります。

終わりに
久しぶりにまとめたので、説明不足なところがあったら教えてください。
私は業務でちょこっとスクレイピングしたいタイミングがあって、いい方法ないかなと
思ってこの方法に行きつきました。