※この記事のコードは全て MATLAB R2020b で動作確認をしています。他のバージョンではうまく動かない可能性がありますのでご注意ください。
つい先日、「MATLAB でPDF を分割する」というコードを書く機会があったので紹介します。
ついでに、せっかくなのでどういう流れで MATLAB のコードが完成したのか、についてもまとめてみました。
今回やったことの紹介
「複数の書類がまとまった PDF ファイルを読み込んで、書類に記載されている番号ごとにまとめて自動で分割したい」
と相談を受けたので、MATLAB でスクリプトを書きました。
イメージとしては、以下のように同じ形式の書類が 1 ページずつまとめられている PDF を、ID ごとに分割して保存するような感じです。
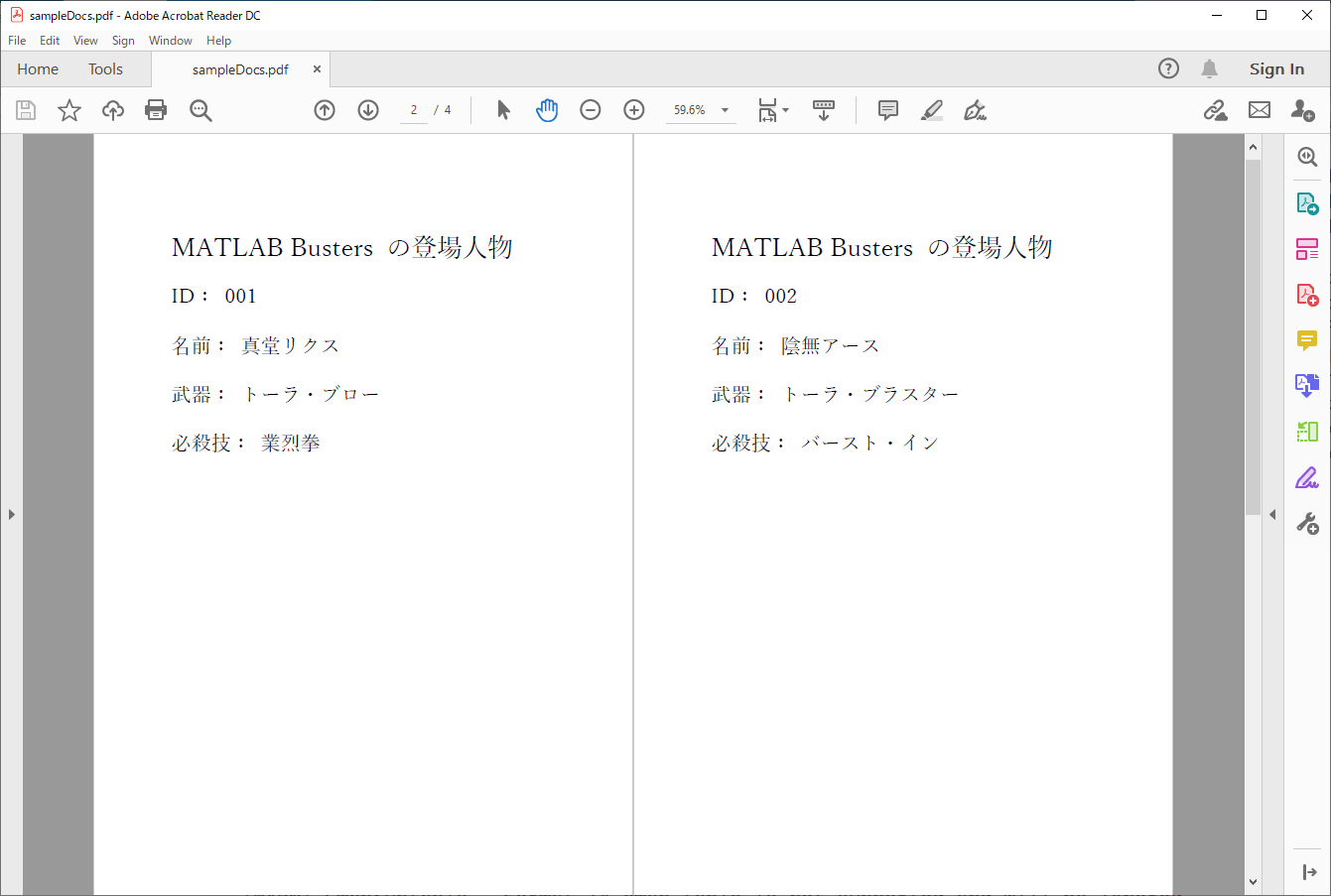
(もちろん実際はこんなふざけた書類じゃないですよ)
MATLAB で PDF 分割ができるようになるまで
1. とりあえずググる
そもそも MATLAB で PDF ファイルを読み込めるのかすらわからないので、適当にググってみます。
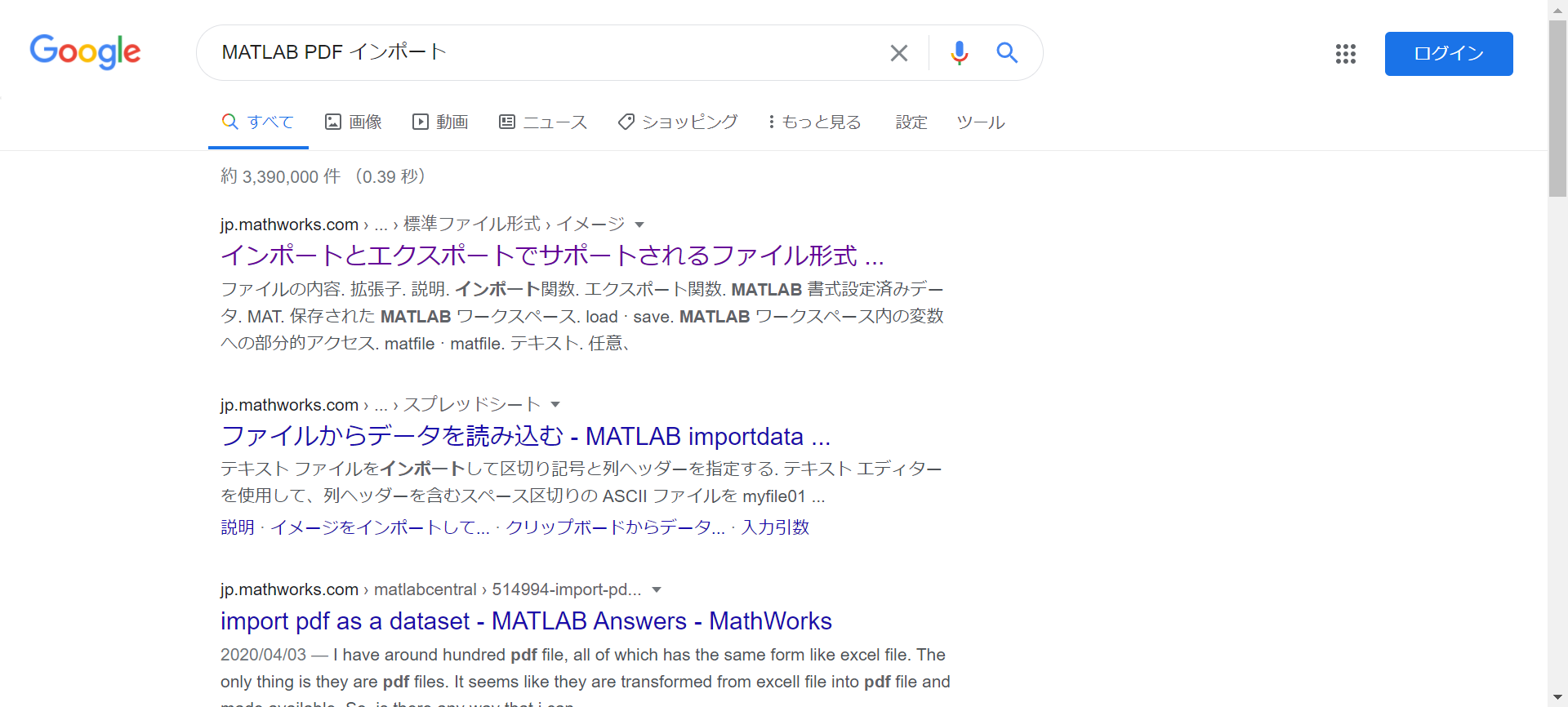
サポートされるファイル形式のドキュメントがヒットしました。ということは、PDF はサポートされているのか!
喜んでドキュメントを開いて pdf で検索をかけると
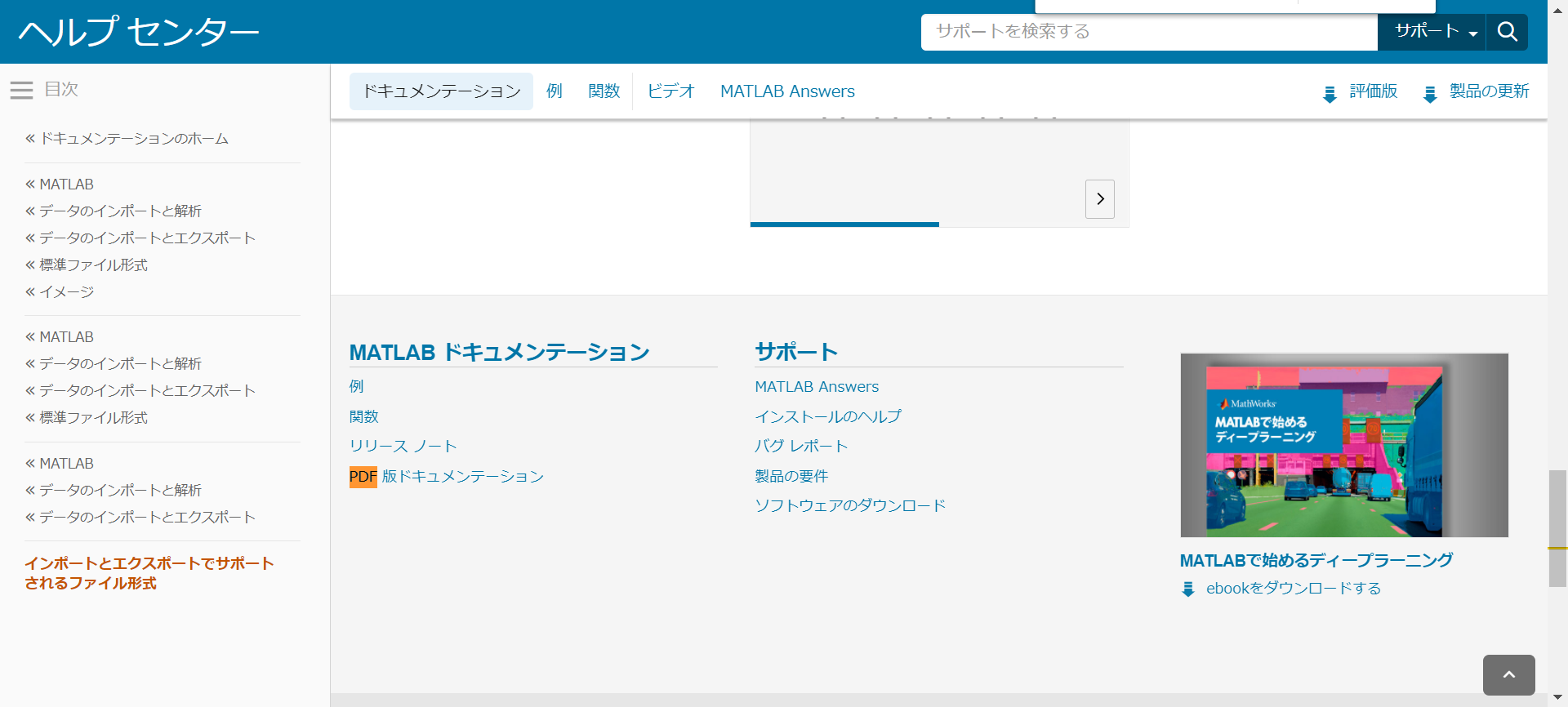
は?(真顔)
念のため上の方も確認してみましたが、表に PDF はありませんでした。
まとめ
調査の結果、残念ながら MATLAB で PDF を読み込むことはできないようです。
いかがだったでしょうか?
参考になった!という方は LGTM をお願いします!
2. MATLAB Answers で調べる
冗談です。まだ終わりません。
冷静に考えて、MATLAB で PDF を加工するなんてことを、過去の頭のおかしな MATLAB ユーザーが考えないはずがありません。
そういったユーザーは MATLAB Answers に潜んでいることが多いので、MATLAB Answers を探してみます。
ちなみに、MATLAB のヘルプ検索で 「MATLAB Answers」 を選ぶと MATLAB Answers の投稿を検索できますのでご参考まで。
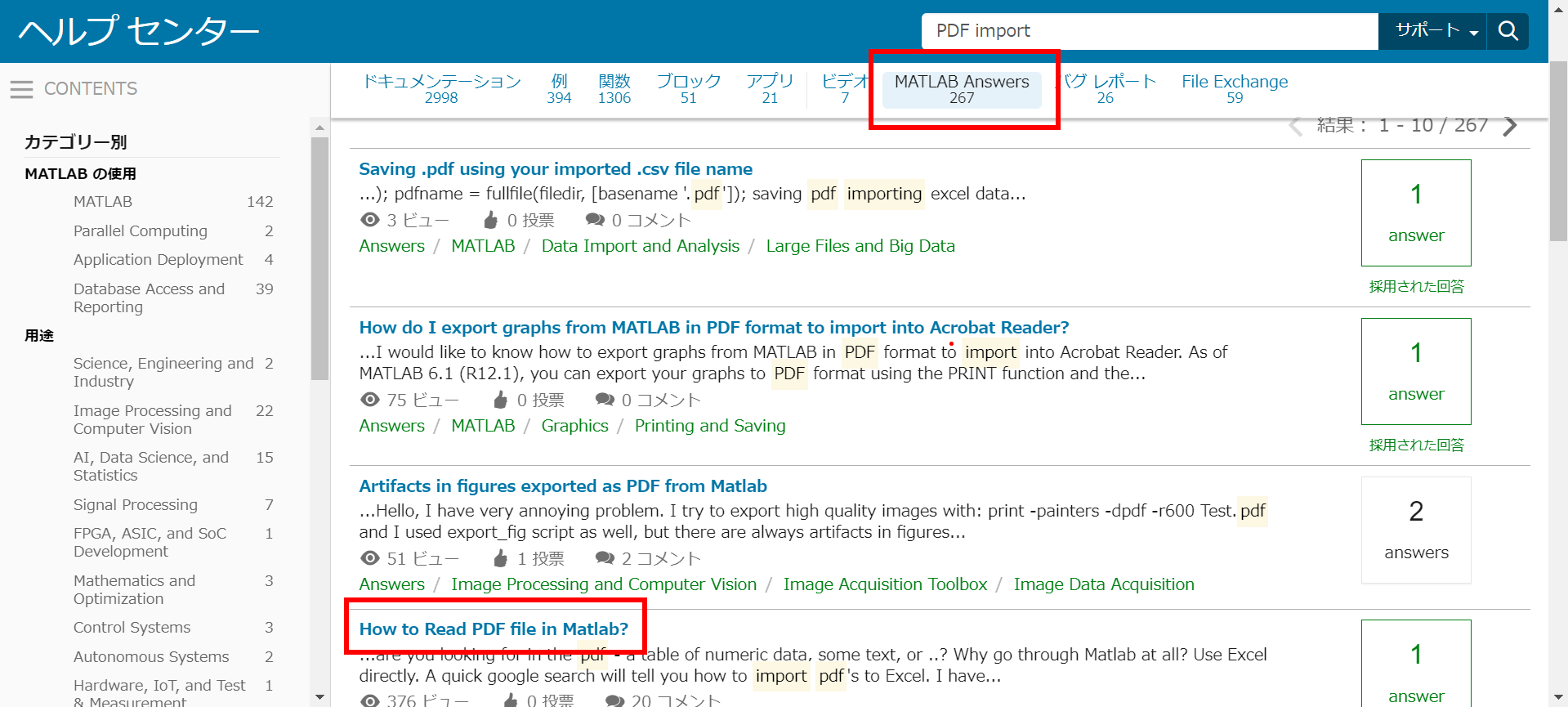
お、「How to Read PDF file in Matlab?」というそれっぽい質問がありました。コメントもいっぱいついてるみたいなので、開いてみましょう。
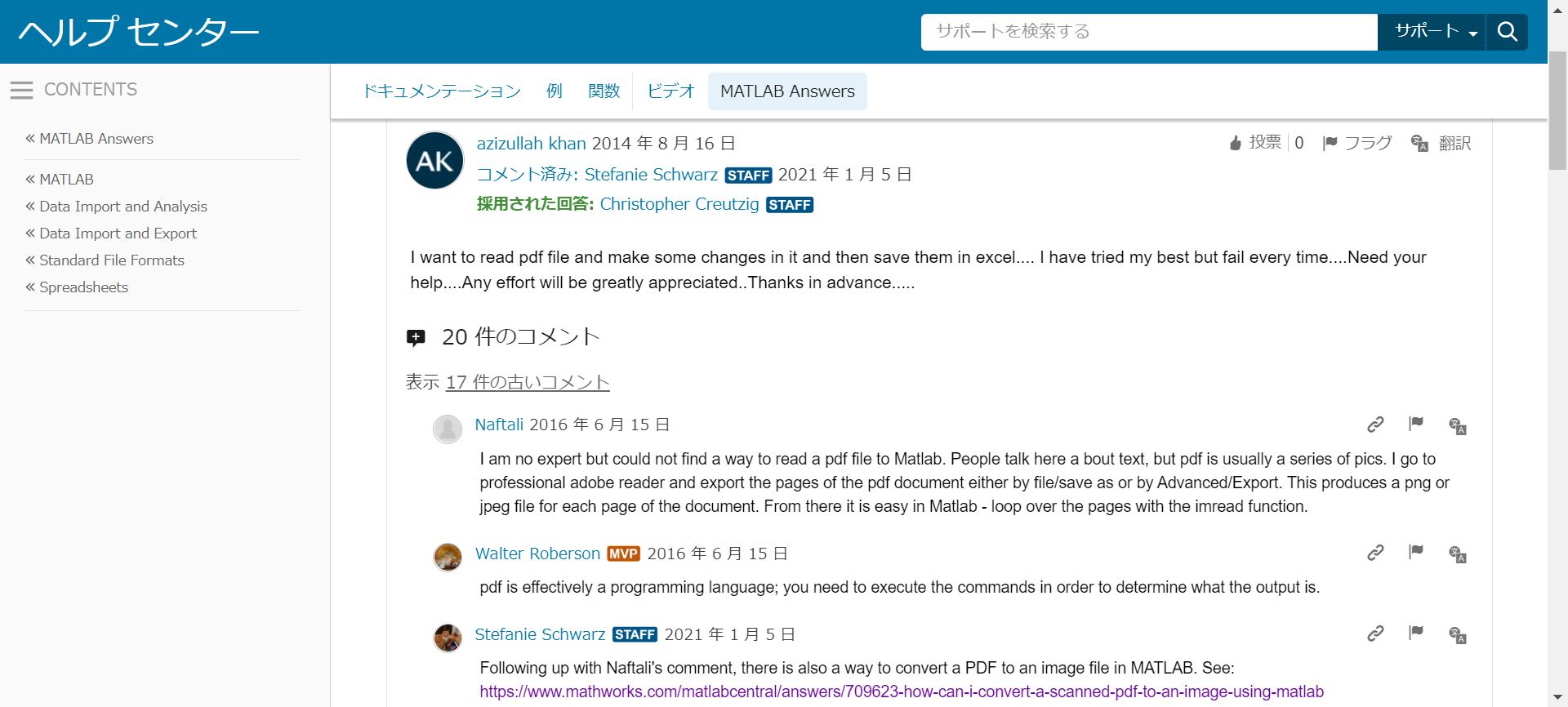
「PDF を読み込んで編集して Excel で保存したい」という質問みたいです。「Excel で保存」の部分は違いますが、PDF を読み込む部分に関しては同士のようです。
一番下に「この回答が参考になるよ!」と回答がついているので、そっちを見てみましょう。
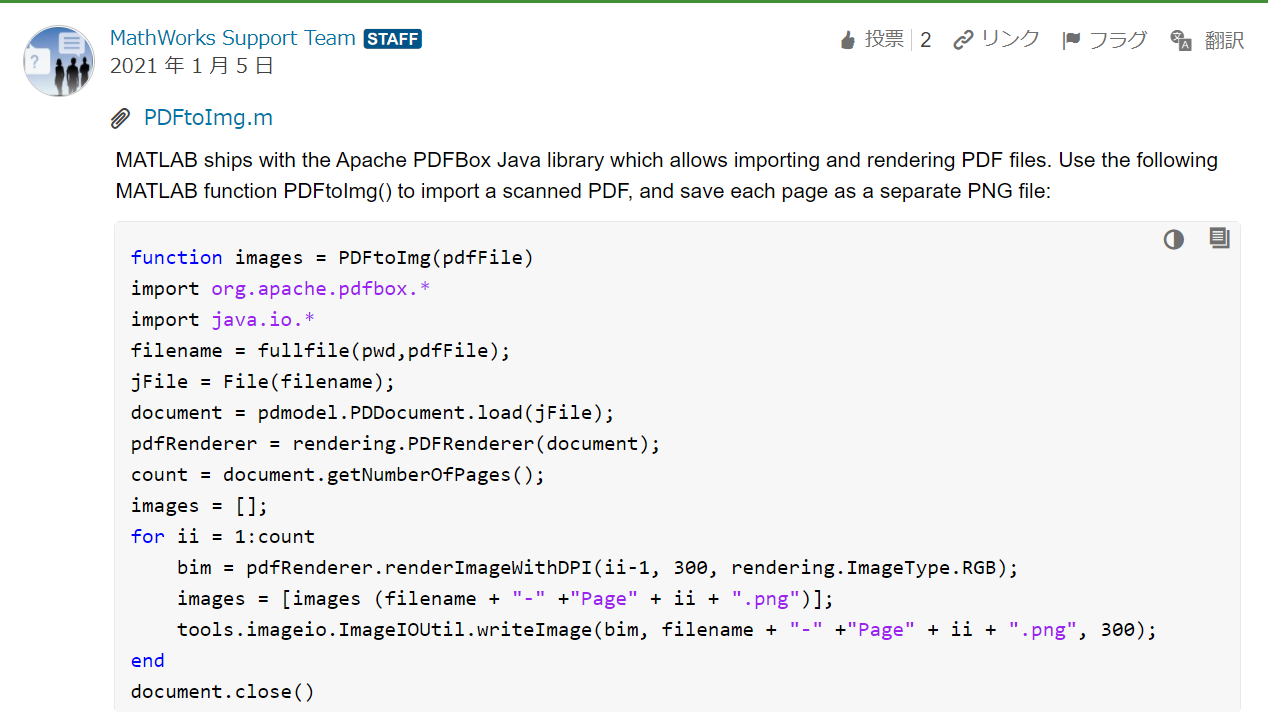
「Apache PDFBox Java library を使えば PDF の読み込みやレンダリングができるよ!」
だそうです。コードも載っていますね。
「Java なんて書いたことねぇよ!」
という方、ご安心ください。私も Java 書いたことないです。
3. 使われてる関数をドキュメントで調べる
コードを見てみると、pdmodel.PDDocument やら rendering.PDFRenderer やら聞いたことのない関数がいっぱい使われてます。おそらくこれが Java の関数なんでしょう。一番上の import で Java を使うための準備をしてるように見えますね。
ということで、まずはこの import 関数のドキュメントを見に行きましょう。
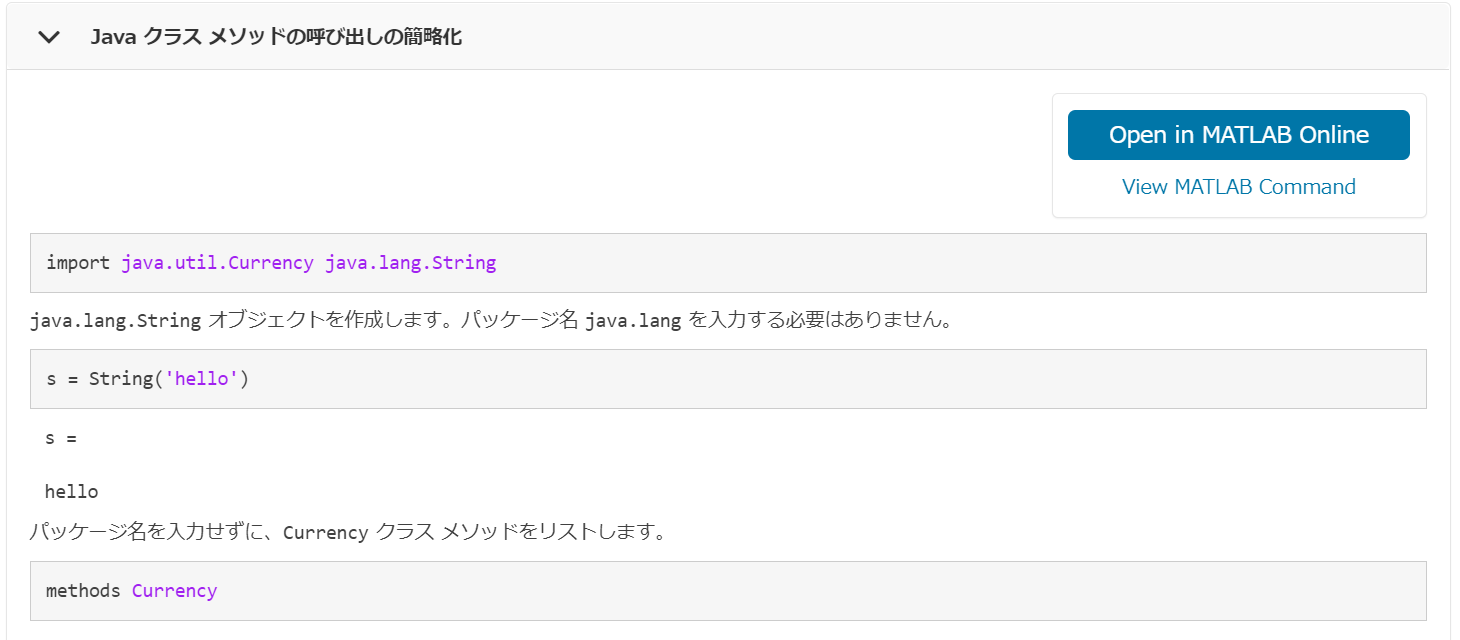
なるほど、ドキュメントを見る感じ、 Java クラスの関数の呼び出しを短縮化できるみたいです。ということは、さっきのコードは Java の org.apache.pdfbox と java.io の関数を使ってるというになります。
java.io は名前的にファイルを読み込むためのものでしょうから、PDF の操作は org.apache.pdfbox の関数を使う必要があるみたいですね
4. 再度ググる
しょうがないのでこの org.apache.pdfbox についてググってみます。
めっちゃ頭悪そうな検索してますが、一番上のサイトに簡単なサンプルコードが載っていそうなので、中身を見てみましょう。
空の PDF を作るサンプルコードが載っていました。
package sample.pdfbox;
import java.io.IOException;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDPage;
public class Main {
public static void main(String args[]) {
try {
// 空のドキュメントオブジェクトを作成します
PDDocument document = new PDDocument();
// 新しいページのオブジェクトを作成します
PDPage page = new PDPage();
document.addPage(page);
// ドキュメントを保存します
document.save("sample.pdf");
document.close();
}
catch (IOException e) {
e.printStackTrace();
}
}
}
※[Java ライブラリ Apache PDFBox で PDF を操作しよう (第1回:概要と簡単な操作)](https://weblabo.oscasierra.net/java-pdfbox-1/) より引用
お、サンプルコードの上部に
`import org.apache.pdfbox.pdmodel.PDDocument`
という行があります。さっきの MATLAB Answers の回答コードにも `pdmodel.PDDocument` って出てきてましたね。
回答コードの上部に `import org.apache.pdfbox.*` というコードがあったので、`org.apache.pdfbox.` の部分を省略して呼び出してるんですかね?
試しに MATLAB のコマンドウィンドウで省略なしで呼び出してみましょう。
```matlab
>> org.apache.pdfbox.pdmodel.PDDocument
ans =
org.apache.pdfbox.pdmodel.PDDocument@7b2794ac
ようわからんけど、ちゃんと認識してる!
じゃあ、クラスの宣言とかを除いてやればこのサイトのコードも MATLAB で動くのでは?
document = org.apache.pdfbox.pdmodel.PDDocument;
page = org.apache.pdfbox.pdmodel.PDPage;
document.addPage(page);
document.save("sample.pdf");
document.close();
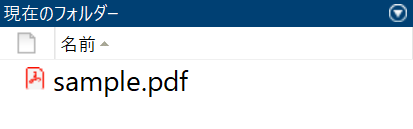
PDF 作れちゃいました、マジか……
5. さらにググる
さて、次は PDF の分割をどうやるか調べてみましょう。
またまた頭の悪そうな検索ワードですが、ちゃんとそれっぽいサイトが一番上に出てきました。
package com.example;
import org.apache.pdfbox.multipdf.Splitter;
import org.apache.pdfbox.pdmodel.PDDocument;
import java.io.File;
import java.io.IOException;
import java.util.List;
public class PDFBoxExample {
public static void main(String[] args) throws IOException {
try (PDDocument source = PDDocument.load(new File("input.pdf"))) {
Splitter splitter = new Splitter();
List<PDDocument> documents = splitter.split(source);
for (int i = 0; i < documents.size(); i++) {
PDDocument document = documents.get(i);
document.save("out" + i + ".pdf");
}
}
}
}
※[[Java]PDFBoxでPDFを分割する](https://tech.chakapoko.com/java/pdfbox/split-a-pdf-document.html)より引用
サイトのサンプルコードを見る限り、`org.apache.pdfbox.multipdf.Splitter` が PDF の分割をしてくれる Java クラスみたいです。MATLAB でも使えるかな?
```matlab
>> org.apache.pdfbox.multipdf.Splitter
ans =
org.apache.pdfbox.multipdf.Splitter@67b47b31
使えました。じゃあ今度はこのサイトのコードを MATLAB っぽく書き換えてみましょう。
jFile = java.io.File('sample.pdf');
document = org.apache.pdfbox.pdmodel.PDDocument.load(jFile);
splitter = org.apache.pdfbox.multipdf.Splitter;
documents = splitter.split(document);
sz = documents.size
for i = 1:sz
document = documents.get(i-1);
document.save("out" + i + ".pdf");
end
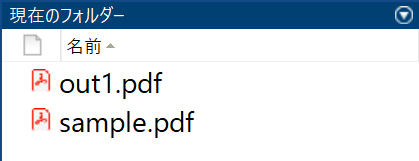
動きました。すげー(小並感)
6. まだまだググる
これだけだと 1 ページずつ分割するだけです。今回は PDF の中のテキストも取得する必要があります。
ということでテキストを取得する方法について調べてみましょう。
真ん中の Qiita の記事がサンプルコードも載っててわかりやすそうです。
import java.io.File;
import java.io.IOException;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
public class PdfToTextMain1 {
public static void main(String[] args) {
// https://pdfbox.apache.org/download.cgi
// pdfbox-2.0.8
// fontbox-2.0.8.jar
String filepath = "file/pdf_ja.pdf";
try {
PDDocument pdDoc = PDDocument.load(new File(filepath)); // throws
// IOException
PDFTextStripper pdfStripper = new PDFTextStripper();// throws
// IOException
pdfStripper.setStartPage(1);
pdfStripper.setEndPage(5);
String parsedText = pdfStripper.getText(pdDoc); // throws
// IOException
System.out.println(parsedText);
} catch (IOException e) {
e.printStackTrace();
}
}
}
※[pdfbox-2.0.8 でPDFからJavaでテキスト抽出](https://qiita.com/oyahiroki/items/799f2d1097211b0cb008)より引用
コードを見てみると、`org.apache.pdfbox.text.PDFTextStripper` が該当するクラスのようですね。`setStartPage` と `setEndPage` で開始ページと終了ページを指定して `getText` で取ってくるのかな?
また簡単なコードで試してみましょう。
```matlab:pdfTextGet.m
jFile = java.io.File('sampleDocs.pdf');
document = org.apache.pdfbox.pdmodel.PDDocument.load(jFile);
stripper = org.apache.pdfbox.text.PDFTextStripper;
stripper.setStartPage(1);
stripper.setEndPage(1);
txt = stripper.getText(document);
>> txt
txt =
MATLAB Busters の登場人物
ID: 001
名前: 真堂リクス
武器: トーラ・ブロー
必殺技: 業烈拳
動きました。感動!
テキストで取ってこれたらこっちのもの。あとは strsplit 関数で分割して contain 関数で ID: を検索し、その次の要素を取ってくれば各ページの ID が取れるはず!
>> strsplit(txt)
エラー: strsplit (行 80)
最初の入力は文字ベクトルか string スカラーのいずれかでなければなりません。
ここまで来てまさかのエラー。いや、txt は string 型なんですが。

ほら、whos 関数だって string 型だって言って……
>> whos txt
Name Size Bytes Class Attributes
txt 1x1 java.lang.String
えぇ……。
ということで、ワークスペースではちゃっかり String と表示されていた txt は、実際は java.lang.String 型だったみたいです。というか、冷静に考えると Java の関数呼び出したときの返り値が MATLAB の string 型なのはおかしい。
さて、このままだと Java でテキスト処理をしなくちゃいけません。どうしたものか。
7. これでもかというほどググる
2 番目のドキュメントがそれっぽいです。見てみます。
『MATLAB string への変換
java.lang.String オブジェクトおよび配列を MATLAB の string または文字ベクトルに変換するには、MATLAB 関数 string または char を使用します。』
string 使うだけでいいんかーい!
>> strsplit(string(txt))
ans =
1×12 の string 配列
1 列から 7 列
"MATLAB" "Busters" "の登場人物" "ID:" "001" "名前:" "真堂リクス"
8 列から 12 列
"武器:" "トーラ・ブロー" "必殺技:" "業烈拳" ""
問題なくできました!
8. コードを書く
これまでの内容をまとめると、
-
java.io.Fileでファイルを指定する -
org.apache.pdfbox.pdmodel.PDDocument.loadで PDF を読み込む -
org.apache.pdfbox.multipdf.Splitterで PDF を 1 ページずつ分割 -
org.apache.pdfbox.text.PDFTextStripperで PDF のテキストを取得する - string 型に変換して strsplit + contains で ID を取得
- save メソッドで各ページを保存。
のような流れでやれば大丈夫そうです。
ということでコード完成。
jFile = java.io.File('sampleDocs.pdf');
document = org.apache.pdfbox.pdmodel.PDDocument.load(jFile);
stripper = org.apache.pdfbox.text.PDFTextStripper;
stripper.setStartPage(1);
stripper.setEndPage(1);
splitter = org.apache.pdfbox.multipdf.Splitter;
documents = splitter.split(document);
sz = documents.size;
for i = 1:sz
doc = documents.get(i-1);
txtJava = stripper.getText(doc);
txtSp = strsplit(string(txtJava));
idx = find(contains(txtSp,"ID:"));
id = txtSp(idx+1);
doc.save(id + ".pdf");
doc.close;
end
document.close;
ちゃんと動きました。

uigetfile 関数で PDF ファイルを選べるようにすると、もっと使いやすくなるかもです。
MATLAB 芸を完成させるための 3 つの秘訣
「MATLAB で PDF を分割する」という MATLAB 芸が完成するまでの一連の流れをまとめてみましたが、重要なのは以下の 3 点です。
①ドキュメントになくても諦めずに MATLAB Answers で調べる
Answers には頭のおかしな生粋の MATLAB ユーザーがたくさんいますので、ダメもとで調べてみると意外とそれっぽい機能がヒットする場合が多いです。
②色んなサイトのサンプルコードを有効活用する
今回の流れを見てもらえばわかる通り、ほとんど Java のサンプルコードを MATLAB に翻訳しているだけです。
使ったことのない機能を使って 1 からコードを書くのは非常に大変なので、サンプルコードを改変するところからスタートしましょう。
③ちょくちょくコマンドウィンドウや簡単なスクリプトで実行する
使い方が合ってるか、所望の動作が得られるかを確かめるために、ちょくちょくコマンドウィンドウや簡単なスクリプトで試しましょう。
ここでいろんなエラーを見ておくと、後々コードを書いてエラーが出たときにも原因がわかりやすいです。
まとめ
ということで、無事 MATLAB で PDF を分割するコードを完成することができました。
それにしても、こんなに簡単に Java 関数が使えるとなると、Java の関数をうまく使えばいろんな MATLAB 芸ができそうな気がしますね。