修正
・見ずらかった実行結果をコードブロックに修正しました(よく見たらコピペミスしてたのでそこも合わせて修正、、、)。リクエスト助かりました。ありがとうございます。2019/03/06
・DataFrame関数を使わないときでも内包表記を利用することでsum関数が使えることを教えていただき、修正追記しました。ありがとうございます。2019/03/06
まえおき
Google ColaboratoryはJupyterNotebook環境が無料で利用できるサービスです。
JupyterNotebookはipynbというファイル形式で保存されます。Google Colaboratoryは一定時間(12時間)で環境がリセットされるため、定期的に保存が必要です。
前回はローカルPC内にあるCSVファイルを読み込んで表示しました(そのためにローカルPCにAnacondaをインストールし、そこからJupyterNotebookを立ち上げてファイルを読み込みました)。
今回はGoogle Colaboratory上で読み込んだデータの操作を行います。
Git上のファイルを読み込む
今回は操作に慣れるため、あらかじめインターネット上に置いたipynbファイルを読み込んで、データの操作を行います。
インターネット上に、誰に読み取られてもよい公開データを置くことは最近ではごく簡単にできるようになりました。今回はJupyterNotebookからGITHUB(Git)というサイトにアクセスし、そこにあるファイル取得して使うことにします。
GoogleColaboratory上から、「ファイル」の「ノートブックを開く」を選択します。

以下の画面が表示されますので、「GITHUB」のタブをクリックし、下記URLをコピーして貼り付けます。
https://github.com/mabota/python3_tutorial01
そして右側にある検索の虫眼鏡マークをクリックして結果が表示されるのを待ちます。
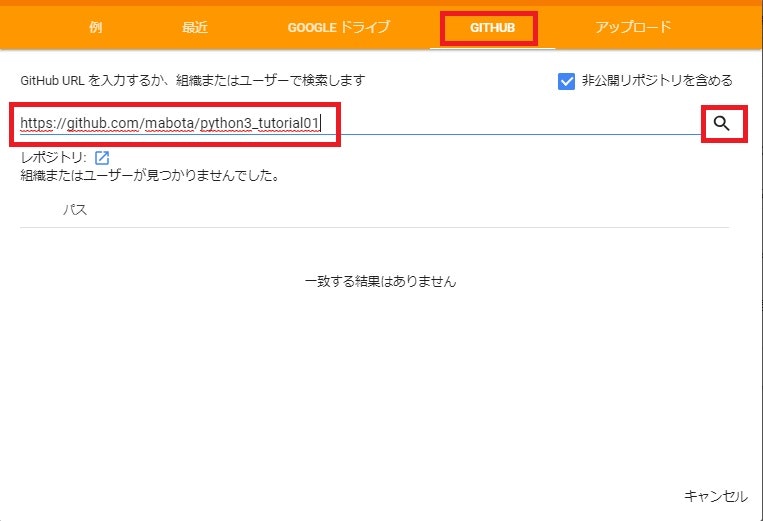
検索結果に「pythondata01.ipynb」ファイルが表示されていれば、それをクリックすることで、GoogleColaboratory上で「pythondata01.ipynb」ファイルが表示されます。

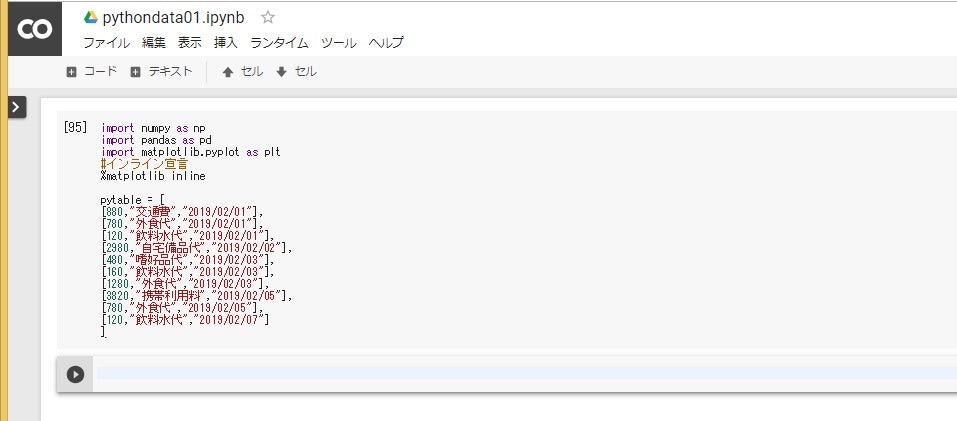
データを操作する
データを変数へ格納し、それを使ってデータ操作を行います。
最初に、GITHUBから選択して開いた「pythondata01.ipynb」の一つ目のセルを実行させます。セルの実行は、セルの左側にある▽の部分をクリックします。すると下記画面のように警告画面が出ますが、「このまま実行」をクリックします。
※ランタイムリセットするとまずいという詳しい人はいったんファイルをローカルに保存するなどして開き直すことをお願いします。

すべてのランタイムをリセットしますか、というので、「はい」をクリックします。

このセルはこれからの準備用ですので実行しても表面上何もおきません。
今回の記事の以下記載のコードは、次の空セルにコピペして実行していきます。
# データの表示
以下のコードをコピペして実行します。#の右側はコメント部分です。このようなかたちでコードに影響することなく注釈をつけることができます。
pytable #変数の中身を表示する
実行結果>>>
[[880, '交通費', '2019/02/01'],
[780, '外食代', '2019/02/01'],
[120, '飲料水代', '2019/02/01'],
[2980, '自宅備品代', '2019/02/02'],
[480, '嗜好品代', '2019/02/03'],
[160, '飲料水代', '2019/02/03'],
[1280, '外食代', '2019/02/03'],
[3820, '携帯利用料', '2019/02/05'],
[780, '外食代', '2019/02/05'],
[120, '飲料水代', '2019/02/07']]
# データ操作『抽出(フィルタリング)』
上記は変数の中にある内容がすべて表示されています。Excelなどの表計算ソフトでは、表の内容を必要な情報だけ表示させたりしますが、Pythonでも同じことが出来ます。
先頭の1行だけ表示する
以下のようにコードを書きます。pythonでは先頭は0(ゼロ)から始まりますので、角かっこの中が0となります。
pytable[0] #1行目だけ表示する
実行結果>>>
[880, '交通費', '2019/02/01']
## 特定の行のみ抽出(フィルタリング)
以下のようなコードで抽出の操作が出来ます。検索したい文字列が該当する行を表示します。
for line in pytable:
if "外食代" in line: #外食代の行を抽出
print(line),
実行結果>>>
[780, '外食代', '2019/02/01']
[1280, '外食代', '2019/02/03']
[780, '外食代', '2019/02/05']
また該当文字列以外にも、ifの右側を数値の範囲「>=」などで指定するかたちで、該当する行を表示することも出来ます。
for line in pytable:
cost = line[0] #取り出した行の1列目の金額を変数へ代入
if 1500 >= cost >= 500 #1500円~500円の範囲指定抽出
print(line),
実行結果>>>
[880, '交通費', '2019/02/01']
[780, '外食代', '2019/02/01']
[1280, '外食代', '2019/02/03']
[780, '外食代', '2019/02/05']
データ操作『計算』
その他のよく使うデータ計算もやってみます。
ExcelのSUM関数的な操作
合計を求めます。今回は上記のpytable変数の中の1列目のデータが金額になっていますので、その金額を変数へ足し込んでいき合計を出します。
costs = 0 #計算する箱の中身をゼロクリア
for line in pytable:
costs = costs + line[0] #1行目から順に変数へ足し込み
print(costs) #変数の中身を表示
実行結果>>>
11400
※SUM関数もPythonにあります。~~DataFrameという概念というか関数を使うときにはSUM関数が使えますがここではfor文使って計算します。~~ 以下のように記述することでsum関数が使えます。
sum(x[0]for x in pytable)
実行結果>>>
11400
# データ追加
pytableの表データに1行追加したいときは、以下のコードで追加できる。
pytable = pytable + [[360,"交通費","2019/02/07"]]
pytable
実行結果>>>
[[880, '交通費', '2019/02/01'],
[780, '外食代', '2019/02/01'],
[120, '飲料水代', '2019/02/01'],
[2980, '自宅備品代', '2019/02/02'],
[480, '嗜好品代', '2019/02/03'],
[160, '飲料水代', '2019/02/03'],
[1280, '外食代', '2019/02/03'],
[3820, '携帯利用料', '2019/02/05'],
[780, '外食代', '2019/02/05'],
[120, '飲料水代', '2019/02/07'],
[360, '交通費', '2019/02/07']]
次回は平均値や中央値、グラフ表示などのデータ操作をしたいと思います。