はじめに
CMLを使ったチーム対抗トラシュートレーニングを開催する機会があったため、プロビジョニングを自動化し、トレーニング用のサーバーを削減し、問題更新を容易にできないかと考えました。
社内でCMLを使ったトレーニングを企画されている方などにおすすめです。
※CMLとは?→こちらのスライドを御覧ください
環境
ProductName: macOS
ProductVersion: 13.3.1
BuildVersion: 22E261
Terraform v1.4.4 on darwin_arm64
+ provider registry.terraform.io/ciscodevnet/cml2 v0.5.1
CML Version: 2.4.1+build.34
概要
トレーニングの開催には、
- チームアカウントの作成
- チームごとのラボのデプロイ
- ラボへのアクセス権限設定
の3つのプロセスが必要でした。
問題を複数出題する際、②③が繰り返しのオペレーションとなるため、これらの自動化に取り組みました。
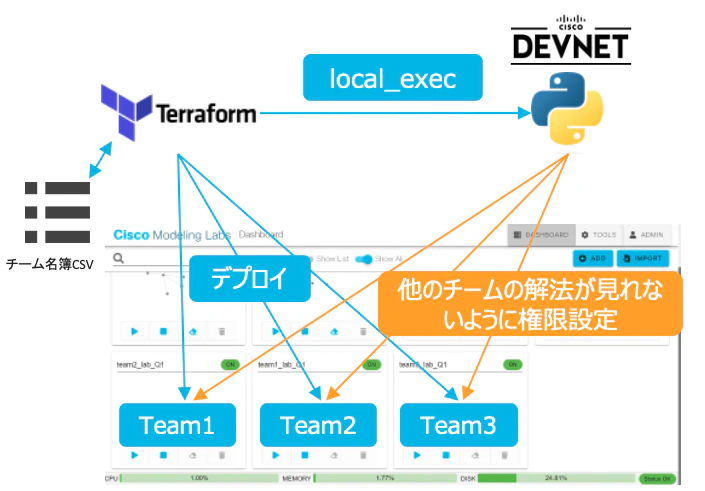
TerraformによるCML環境プロビジョニング
main.tf
variable "parameter_csv" {
type = string
default = "parameter.csv"
}
locals {
namelist = csvdecode(file(var.parameter_csv))
}
terraform {
required_providers {
cml2 = {
source = "registry.terraform.io/ciscodevnet/cml2"
}
}
}
provider "cml2" {
address = "https://x.x.x.x"
username = "user"
password = "pw"
}
resource "cml2_lifecycle" "this" {
for_each = { for inst in local.namelist : inst.id => inst }
topology = templatefile("question1.yaml", { toponame = "${each.value.name}_lab_Q1" })
provisioner "local-exec" {
command = "python3 group_assign.py"
}
}
question1.yamlはCMLのラボのエクスポートファイルです。
parameter.csv
id,name
1,team1
2,team2
3,team3
APIでのラボ操作権限設定
group_assign.py
import requests
import json
#token generation
url = "https://x.x.x.x/api/v0/authenticate"
payload = json.dumps({
"username": "user",
"password": "pw"
})
headers = {
'Accept': 'application/json',
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload, verify=False)
token=response.text.strip('"')
#lab list
url = "https://x.x.x.x/api/v0/labs"
headers = {
'Accept': 'application/json',
'Content-Type': 'application/json',
'Authorization': 'Bearer {}'.format(token)
}
response = requests.request("GET", url, headers=headers, data=payload,verify=False)
lab_list=eval(response.text)
print("lab list: {0}".format(lab_list))
#group list
url = "https://x.x.x.x/api/v0/groups"
response = requests.request("GET", url, headers=headers, data=payload,verify=False)
group_list=eval(response.text)
print("group list: {0}".format(group_list))
#group configuration
for count, lab in enumerate(lab_list):
url = "https://x.x.x.x/api/v0/labs/"+lab.strip("")
response = requests.request("GET", url, headers=headers, data=payload,verify=False)
lab_info=eval(response.text)
lab_name=lab_info["lab_title"]
for count, group in enumerate(group_list):
if group["name"] in lab_name:
url = "https://x.x.x.x/api/v0/labs/"+lab.strip("")+"/groups"
payload = json.dumps([
{
"id": group['id'],
"permission": "read_only"
}
])
response = requests.request("PUT", url, headers=headers, data=payload,verify=False)
まとめ
今回CML環境のプロビジョニングに取り組んだことにより、以下のメリットが得られました
- サーバー台数の削減
問題の入れ替えをスムーズにできるようになり、複数の問題を常時デプロイしなくてよくなりました
- 更新・修正の簡易化
ミスがあってもプロビジョニングが自動化できているため、気軽に修正やアップデートをできるようになりました
参考情報
CML Terraform Provider docs
Get Started With Terraform and Cisco Modeling Labs-Ralph Schmieder