この記事は、 Oracle Cloud Infrastructure Advent Calendar 2021, Day 11 です。
背景
2021年11月に、Oracle Cloud Infrastructure(OCI)の新しいAIサービスが発表されました。そのリリースの中に、OCI Anomaly Detectionと呼ばれる異常検出サービスがあり、下記のような記載がありました。
原子炉の健全性監視のような高度な安全性要件を満たすことができる、世界中で使用されている特許取得済みのMSET2アルゴリズムをベースに構築されており
大学、大学院と原子力工学を学んだ私にとっては、「原子炉」というキーワードが気になってしまい、果たしてどんなサービスなのか、どれほど簡単に異常検出モデルが作成、学習、利用できるのか、実際に動かしてみました。
OCI Anomaly Detectionとは
時系列データを用いた、異常検出モデルをより簡単に構築できる、OCIのAIサービスです。UIで作成できるため、データサイエンスの専門知識がなくても、異常検出モデルの作成、トレーニング、適用が簡単にできます。フルマネージドサービスなので、インスタンスの構成などは気にする必要がありません。
一方で、利用されているアルゴリズムは本格的で、MSET2という、Oracle Labで何十年にもわたる研究のもと、実際に使われてきた、多変量時系列異常検出アルゴリズムが利用されています。また、ARP、MVI、UnQといったデータ前処理技術も利用されいているそうです。詳細は 下記のドキュメントを参照ください。
用途としては、特に多数のデータシグナルを含む複雑なシステムを監視するのに役立ち、IoTといった機器故障予測、ログ監視、不正検知、など幅広く適用ができそうです。
参考情報
- OCI Anomaly Detection サイト
- OCI Anomaly Detection Service: The fascinating (nuclear) history ブログ
- OCI Anomaly Detection ドキュメント
- Oracle LiveLabs: Introduction to Anomaly Detection Service with OCI Workshop
価格
-
異常検出モデルの利用
- 0–1000 トランザクション:0円
- 1000 トランザクション以上、1000トランザクション毎:30円
-
異常検出モデルの学習
- 1ヶ月1億データシグナルまで無料
非常に安価です。これは使わなきゃ損。
MSET-SPRT:Multivariate State Estimation Technique - Sequential Probability Ratio Test
利用されている多変量時系列異常検出アルゴリズムには、MSET(多変量状態推定法)、SPRT(逐次確率比検定)が使われています。MSETですべてのデータシグナルから対象のすべての状態を学習して、推測値を算出する予測モデルを作成し、SPRTで推測値と観測値(実際のデータの値)の差から、異常、正常の判定を行います。
例えば、毎秒取得する複数のセンサーがあったとして、正常な状態でのセンサーデータ10000秒分から、対象の正常な状態を学習して、現在の推測値を導出し、実際に現在取得されたセンサーデータと比較することで、現在の状態が正常かどうかを判定する、といったイメージです。
ここらへんはもし間違っていればご指摘もらえるとありがたいです。
というか、難しいことは一回とばして、まずは使ってみましょう。
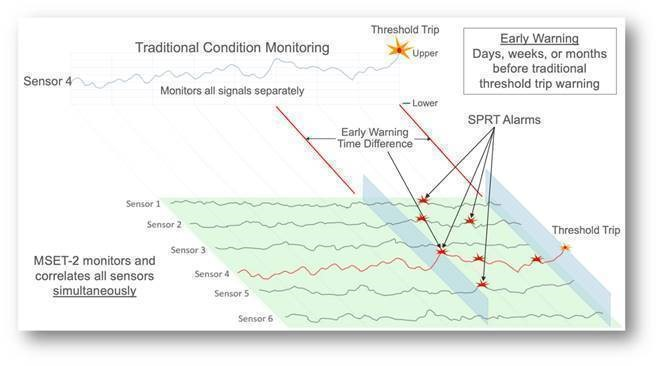
OCI Anomaly Detection ドキュメントより
手順
今回は上述した、「Oracle LiveLabs: Introduction to Anomaly Detection Service with OCI Workshop」のチュートリアルとサンプルデータに基づいて実施していきます。なおこのチュートリアルとサンプルデータであれば、Always Free範囲内でおさまると思います。
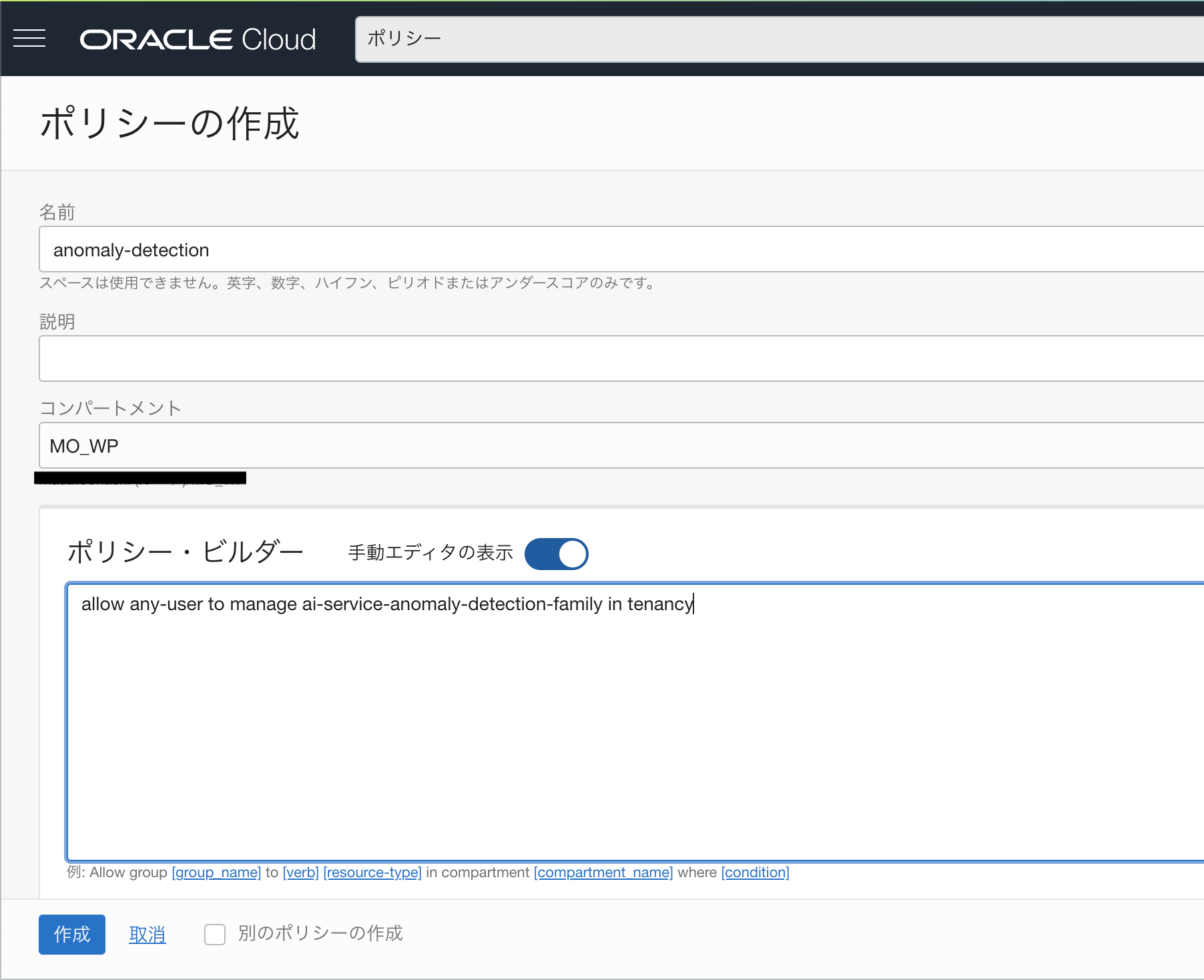
1.ポリシーの設定
Anomaly Detectionを使えるようにポリシーを設定します。(例:すべてのユーザーが利用できるようにするポリシー)
allow any-user to manage ai-service-anomaly-detection-family in tenancy
また、Object Storageも使うので、必要に応じて、Object Storageを利用するポリシーも追加ください。
allow any-user to manage object-family in tenancy
2.サンプルデータをダウンロード
チュートリアル上にあるサンプルデータをダウンロードして確認します。
-
トレーニングデータ(CSV)
- タイムスタンプと10個のデータシグナルが、10000行
- データ属性は、Temperatureが5個、Pressureが5個
-
異常検出のためのデータ(Json)
- タイムスタンプと10個のデータシグナルが、100行
注)ダウンロードしたトレーニングデータは、「temperature_4」の名称が重複しているので、ダウンロードしたのち手動で修正(1つをtemperature_3に変更)してください。

3.サンプルデータをObject Storageにアップロード
Object Storageにバケットを作成し、2でダウンロードしたファイルをアップロードしてください。
4.プロジェクトを作成
異常検出サービスに入ります
プロジェクトを作成ボタンより、プロジェクトを作成します。
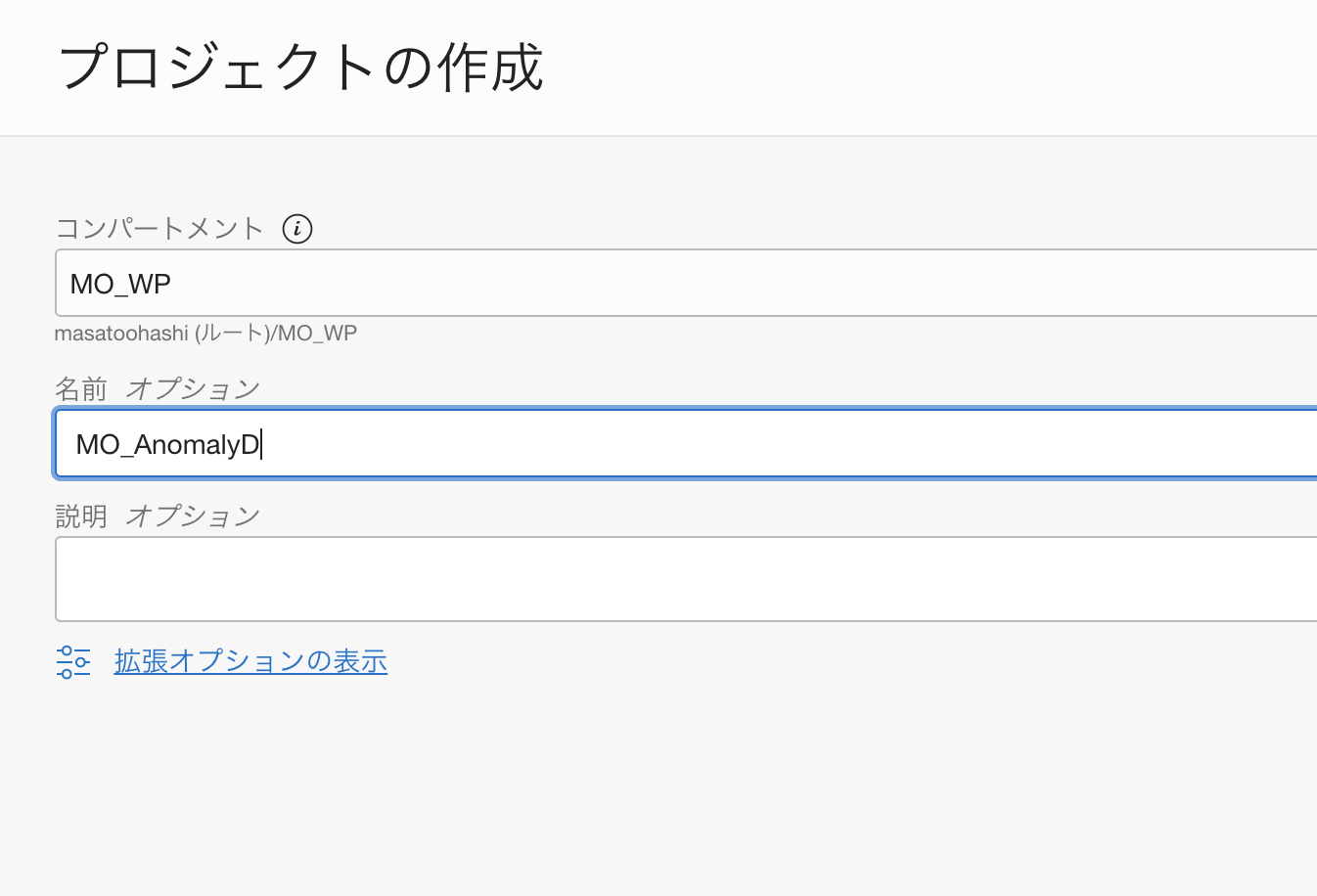
5.データアセットを作成
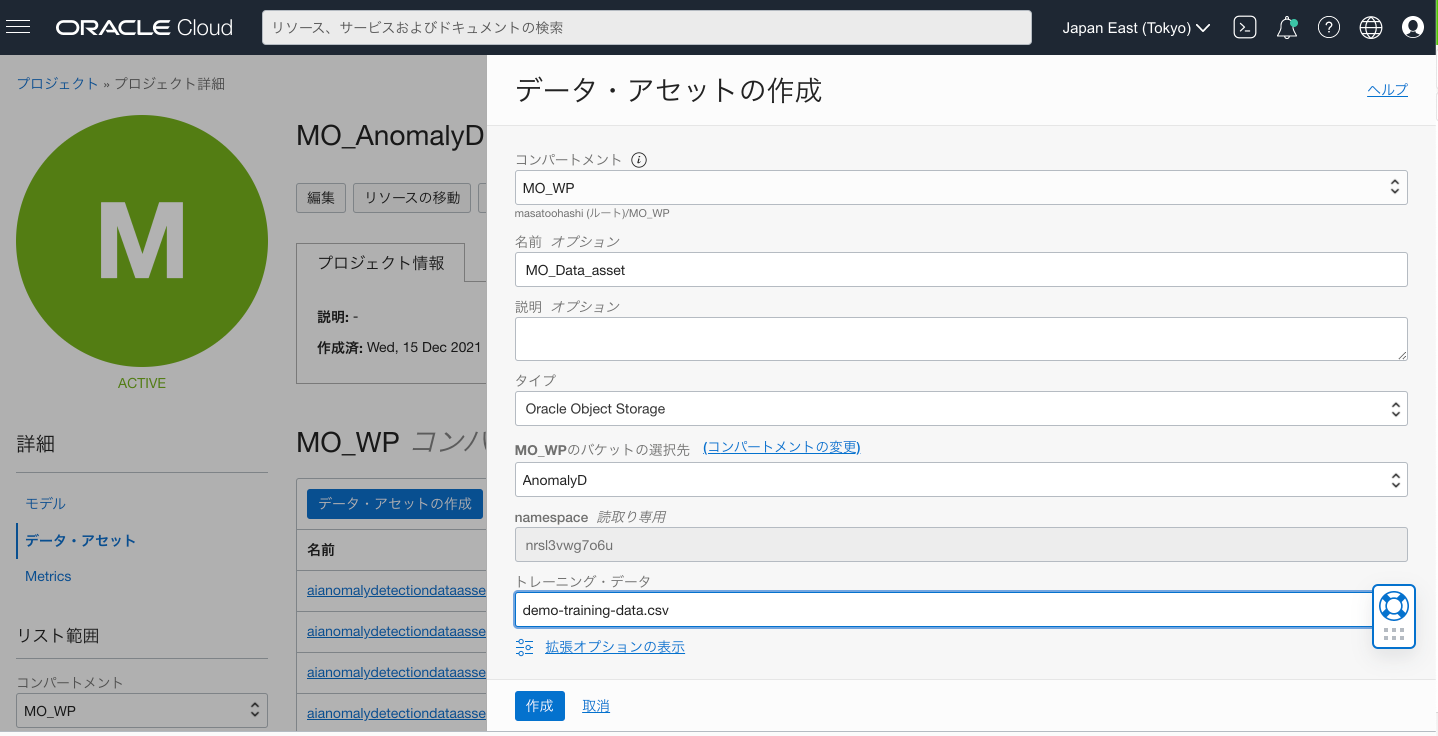
データアセットから、データ・アセットの作成ボタンで、データアセットを作成します。
この際、3でサンプルデータを置いたObject Storageのバケットを選択、また、トレーニングデータとしてcsvファイルを選択します。
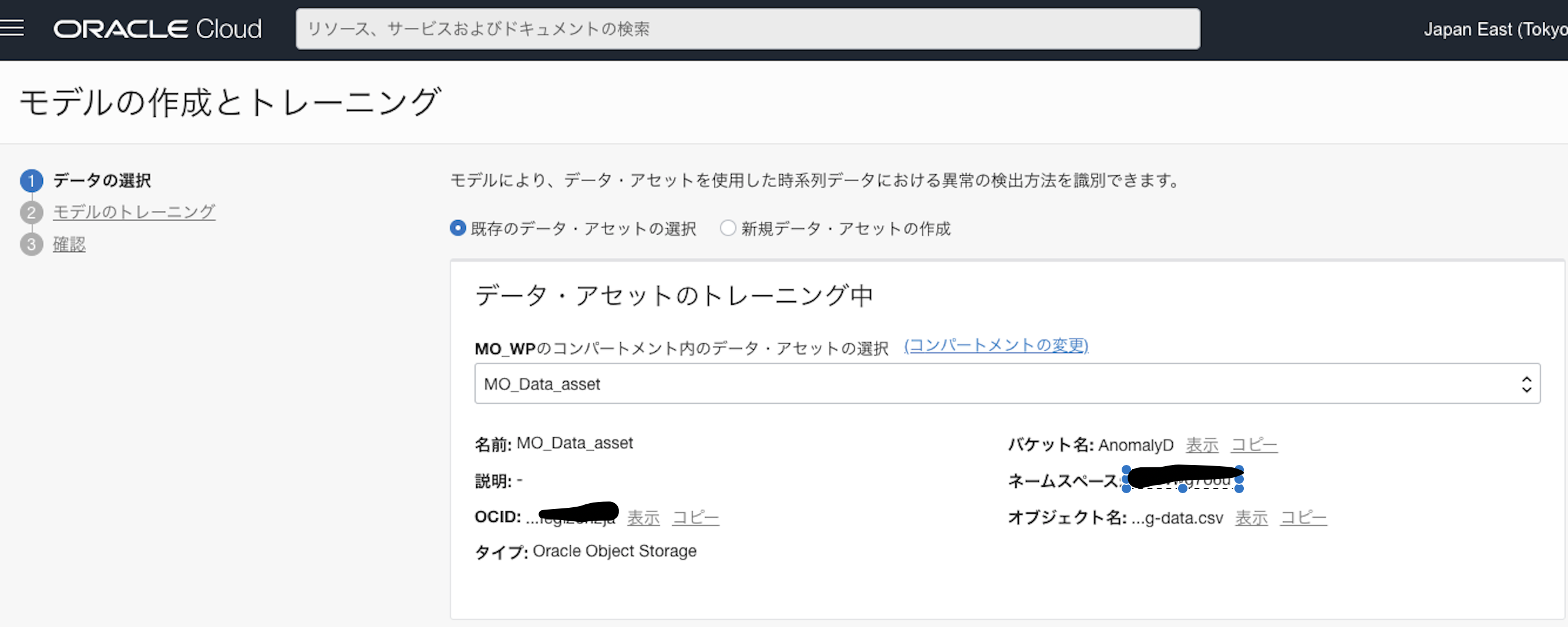
6.モデルの作成
データアセットを使い、いよいよモデルを作成、トレーニングします。
詳細の「モデル」から「モデルの作成とトレーニング」ボタンをおし、先程作成したデータ・アセットを選択します。
トレーニング画面にて、パラメータを選択しますが、ここに2つのパラメータがあります。
ターゲット誤警報確率 (FAP:False Alarm Probability))
- 異常でないものが異常として判断してしまう、誤警報をどれだけ許容できるかの数字です。数字が高いほど、誤警報として判断される異常の可能性が高いことを示します。
なお、チュートリアルによると、
通常、FAPは、実際のビジネスシナリオでの異常のパーセンテージとほぼ同じレベルに設定でき、0.01または1%の値が多くのシナリオに比較的適しています
そうです。
トレーニング分割率 (FAP:False Alarm Probability))
- 学習データのうち、どれだけの割合のデータでトレーニングし、残りのどれだけの割合でそのモデルの性能評価をするかを決めます。デフォルト値の0.7は、トレーニングにデータの70%を使用し、残りの30%でモデルのパフォーマンス評価に利用されます。
注)このあたり、もし間違いなどあればご指摘いただけると嬉しいです。
まあでも気にせず、デフォルトでOKです。まずは使っていきましょう。
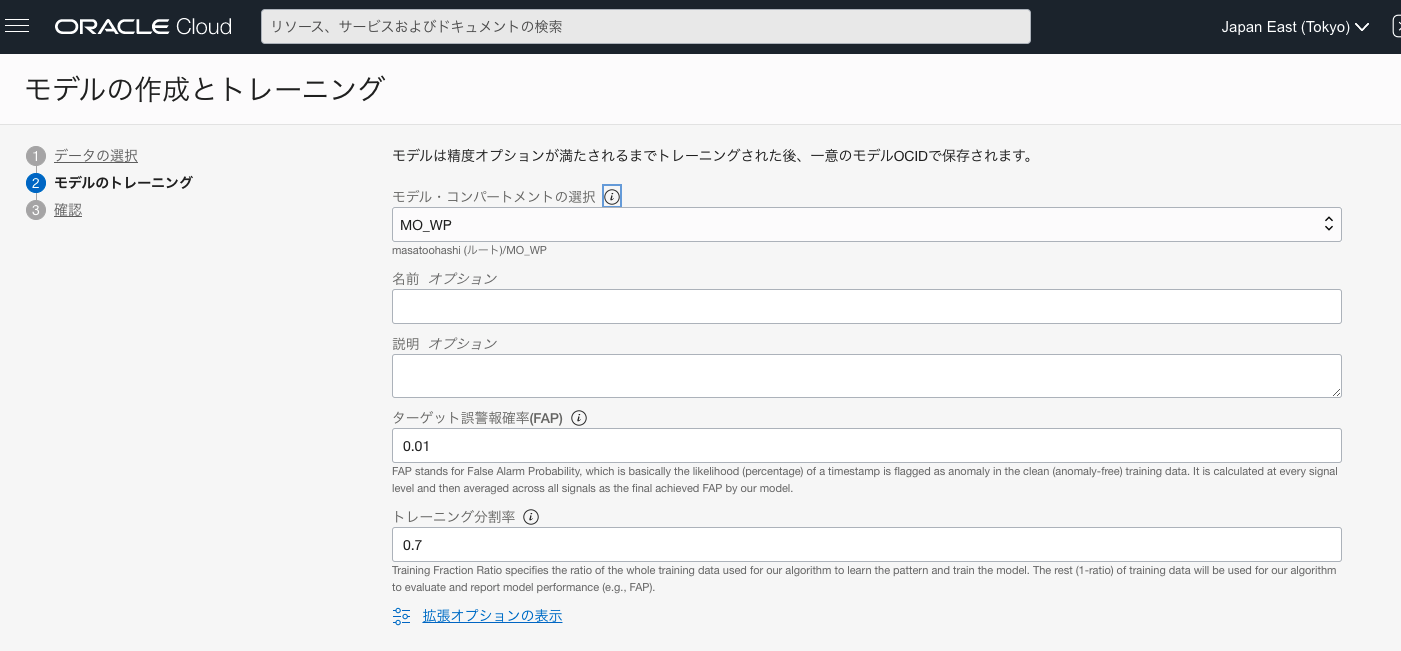
以上のパラメータを元に、モデルの作成とトレーニングが開始されます。
今回のサンプルデータだと、だいたい10分から15分ぐらいでした。
7.新しいデータで異常を検出する
いよいよ新しいデータを使って、異常を検出します。
作成したモデルの、異常から異常の検出ボタンをおします。
サンプルデータのJSONファイルをアップロードし、検出ボタンをおします。
検出結果はすぐに表示されます。
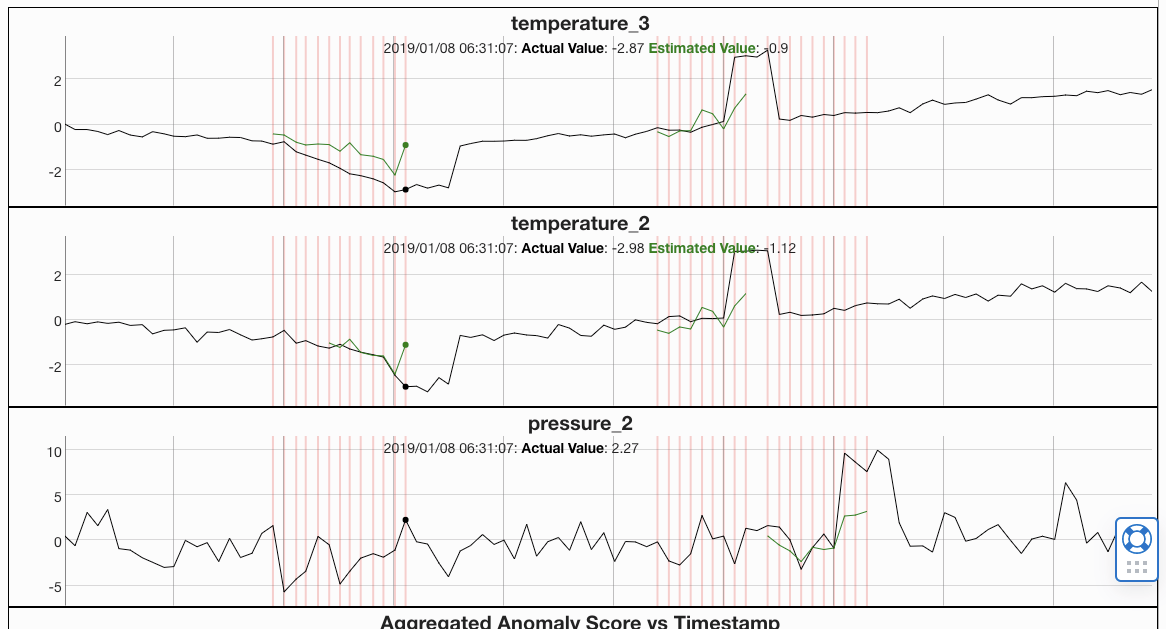
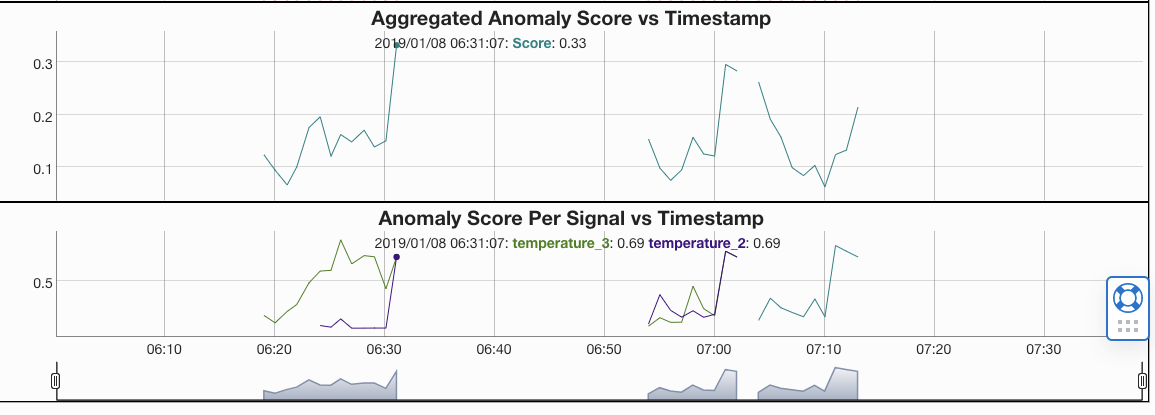
グラフの見方
- 異常を検知したシグナル(今回はTemperature_3、Temperature_2、Pressure_2)と全体の異常判断がタイムスタンプ毎に表示されています
- 黒色のグラフが実際のデータ、緑色のグラフが予測データです。異常と判定された箇所が表示されています。
- 赤い線が入っているのが、全体をもって「異常」と検知された箇所になります。
- Aggregated Anomaly Scoreが全体での異常スコアです。上記赤い線の該当部分です。
異常と判定された時間、どのデータシグナルが主な原因か、わかりやすく表示されていると思います。
8.異常検出データをJSONでエクスポート
異常検出データをJSONでエクスポート可能です。
タイムスタンプ毎の配列でデータポイント毎の、実際のデータ、予測値、異常スコア、そして全体の異常スコアがエクスポートできます。
{
"timestamp": "2019-01-07T22:02:04.000+00:00",
"anomalies": [{
"signalName": "temperature_2",
"actualValue": 3.038691195904264,
"estimatedValue": 1.153255118155411,
"anomalyScore": 0.6888888888888889
}, {
"signalName": "temperature_3",
"actualValue": 3.049010279530258,
"estimatedValue": 1.3548717653499411,
"anomalyScore": 0.6888888888888889
}],
"score": 0.2879873048348054
},
9.応用(PythonやOCI CLIからの実行)
今回はUI画面から実施しましたが、PythonやOCI CLIからの一連の実行も可能です。チュートリアルにサンプルがありますので、ご興味のあるかたは実施してみてください。
まとめ
以上、OCI Anomaly Detectionのチュートリアルとサンプルデータを使って、実際に動かしてみました。
- プログラミングを実施することなく、モデルの作成、トレーニング、異常検出まで実施できました
- 異常の検出箇所、その要因を可視化するグラフも非常にわかりやすいのではと思います
- 今回記載はしませんでしたが、Pythonなどとの親和性、APIなどもありますので、システム連携も違和感なくできそうです。今後実施してみたいです
一方で、留意点として、より精度を高めるためには、データ品質が重要になると思います。
このサービスを利用するにあたっての、3つの主要なデータ品質条件 が、OCI Anomaly Detection ドキュメントに記載されているので、大まかなポイントを記載します。
このようなデータを準備する必要があると同時に、このようなデータが取得できるか、も検討ポイントになるかと思います。
- 学習データは異常のない(外れ値のない)ものであり、正常なビジネス状態のみのデータを含んでいること
- 学習データは、すべてのデータシグナルを含む、正常のビジネスシナリオのすべてカバーをしていること
- データ内のデータシグナルの属性は、関連性が高いか、同じシステムまたは判定するアセットに属していること
最後に
確かに、「Python使って、自分で作るべきだ」という意見もあるかと思います。
だけど、こんな時代ですし、せっかくここまで簡単に利用できるサービスを、まず使ってみる、というのも重要なんじゃないでしょうか。
それがクラウドの醍醐味ですし、UIだけでできてしまう時代ですし、今回のAlways Free環境だと、なんと無料で始めることもできます。データサイエンスを始めたり、DX人材に変身するためのハードルは、確実に下がってきています。
何より、この機能を使うことで、異常を事前に検知することができ、事後対応するための手間暇、ストレス、不安が削減されて、安泰な生活ができて、ぐっすり寝れて、素敵なクリスマスを迎えるって、とっても素敵なことだと思いませんか!