AWSにはAutoScalingという便利な機能があります。AutoScalingは負荷の状況や指定した時間に自動的にインスタンスを用意してくれる機能です。
ソーシャルゲームの様なアクセスがピンポイントで大量にくるような場面で大変活躍してくれます。
そんなAutoScalingを導入して得たメリットと導入の際に気をつけたいポイントについてお話しようと思います。
得たメリット
- インスタンス構築時間が30分から5分に!!
- スケジュール機能により、必要な時間に必要な台数をコントロール!!
- サーバ費のコスト削減!!
1. インスタンス構築時間が30分から5分に!!
**アプリサーバがいますぐ欲しいんです!**こんな依頼が時にはありますよね?
今まではアプリサーバを構築するのにインフラの手とアプリエンジニアの手が必要でした。
まず、インフラがEC2を建ち上げ、chefもしくはansibleでプロビジョニングします。その後、アプリエンジニアにデプロイしてもらい、ELBにアタッチしていました。(順調に行って約30分)
EC2を建ち上げて、プロビジョニングした後にデプロイをお願いするのですが、アプリエンジニアが忙しい場合はすぐにはデプロイが出来ません。そうなるとアプリサーバがサービスインするまで時間が掛かりますし、インフラはデプロイ待ちとなってしまいます。
AutoScaling導入ではプロビジョニング済みのAMIを用意しておき、デプロイ、ELBのアタッチを自動的に行うように設定することで、アプリサーバ増設を簡単にそしてインフラ側で完結するようになりました。
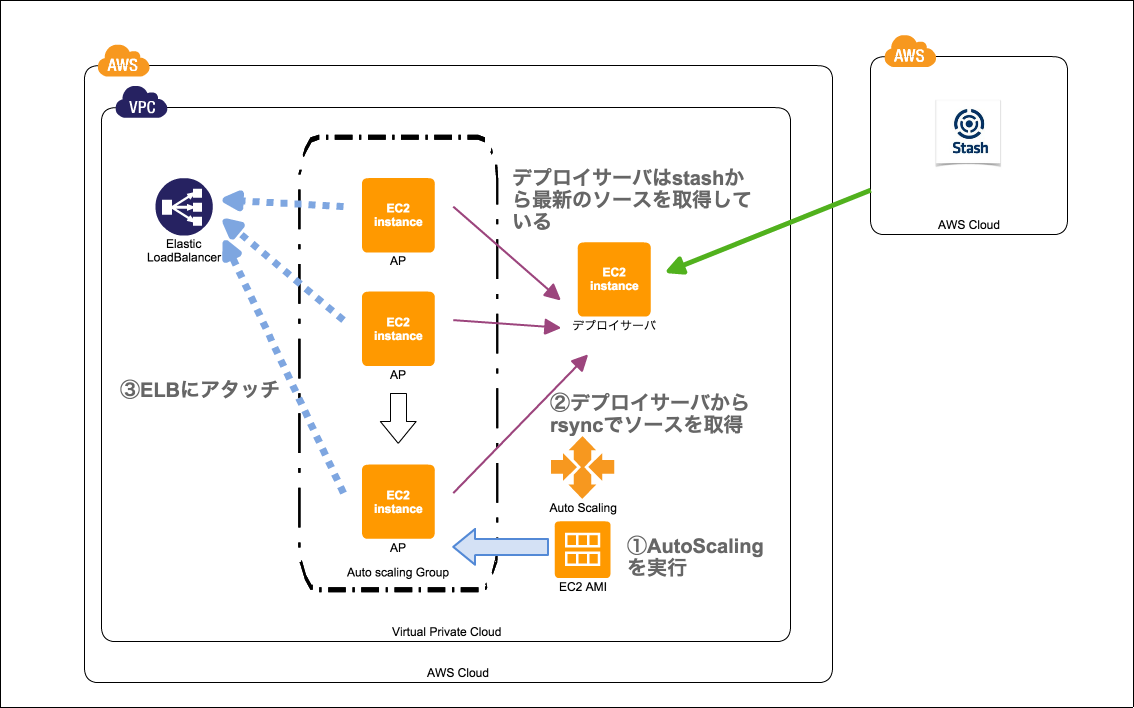
現在はAutoScalingGroupのDesiredCapacityの値を変更するだけで、最新のソースコードを取得したアプリサーバが出来上がり、サービスインするようになっています。(約5分でサービスイン)
2. スケジュール機能により、必要な時間に必要な台数をコントロール!!
AutoScalingには時間指定のスケールアウト、スケールインが設定可能です。この機能を使うことでピンポイントにサーバ増設したい時間にスケールアウトすることが可能です。また、アクセスが減る時間帯にスケールインさせることが出来ます。
例えば、18時にアクセスが大量に来る事が分かっており、アプリサーバが全台で10台必要とします。通常は5台あれば問題ないとした場合、オンデマンドのAutoScalingGroupとして、5台を常に起動しておき、スケールアウト、スケールインさせるグループをスケジューリンググループとし、18時にスケジューリンググループを5台起動させます。
23時にアクセスが減るので、スケールアウトさせたスケジューリンググループを0台にスケールインさせるといった事が可能です。
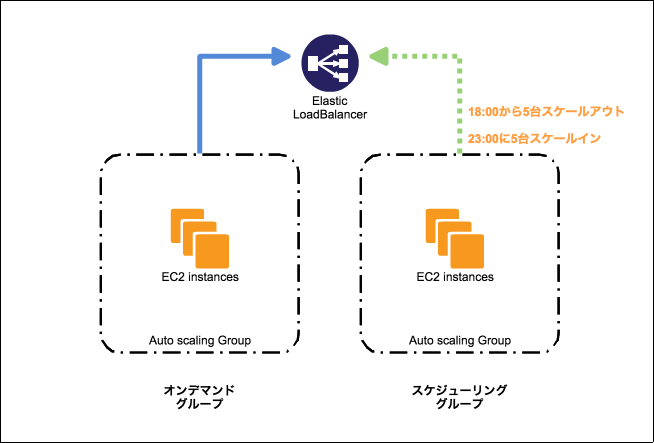
自動的にスケールアウト、スケールインしてくれるので、サーバ増設作業をする工数がまるまる無くなりました。
ちなみにこのスケジューリングを設定するにはAWS CLIを叩くほか無いみたいです。
3. サーバ費のコスト削減!!
必要な時間に必要な台数をコントロールさせる事が可能となったので、深夜帯などアクセスが少ない時間には必要最低限の台数を確保しておき、必要になった時にスケールアウトさせることで、余分なサーバ費が掛からなくなり、コスト削減に繋がりました。
気をつけたいポイント
- 最新のソースコードの取得
- デプロイのロック
- 監視
- ScalingPoliciesによるスケールアウトは間に合わない可能性がある?(未検証)
1. 最新のソースコードの取得
AutoScalingでサーバを自在にスケールアウトさせる事が分かったかと思いますが、そのインスタンスが常に最新のソースコードを取得しておく必要があります。
さきほど上で紹介した図では、EC2からソースコードを取得していますが、仮にこのEC2が死んでしまった場合、AutoScalingサーバへのデプロイが止まってしまう問題があります。スケールアウトさせる台数が多い場合は、デプロイサーバの間にrelayサーバを数台起動させ、負荷を分散させるようにしています。
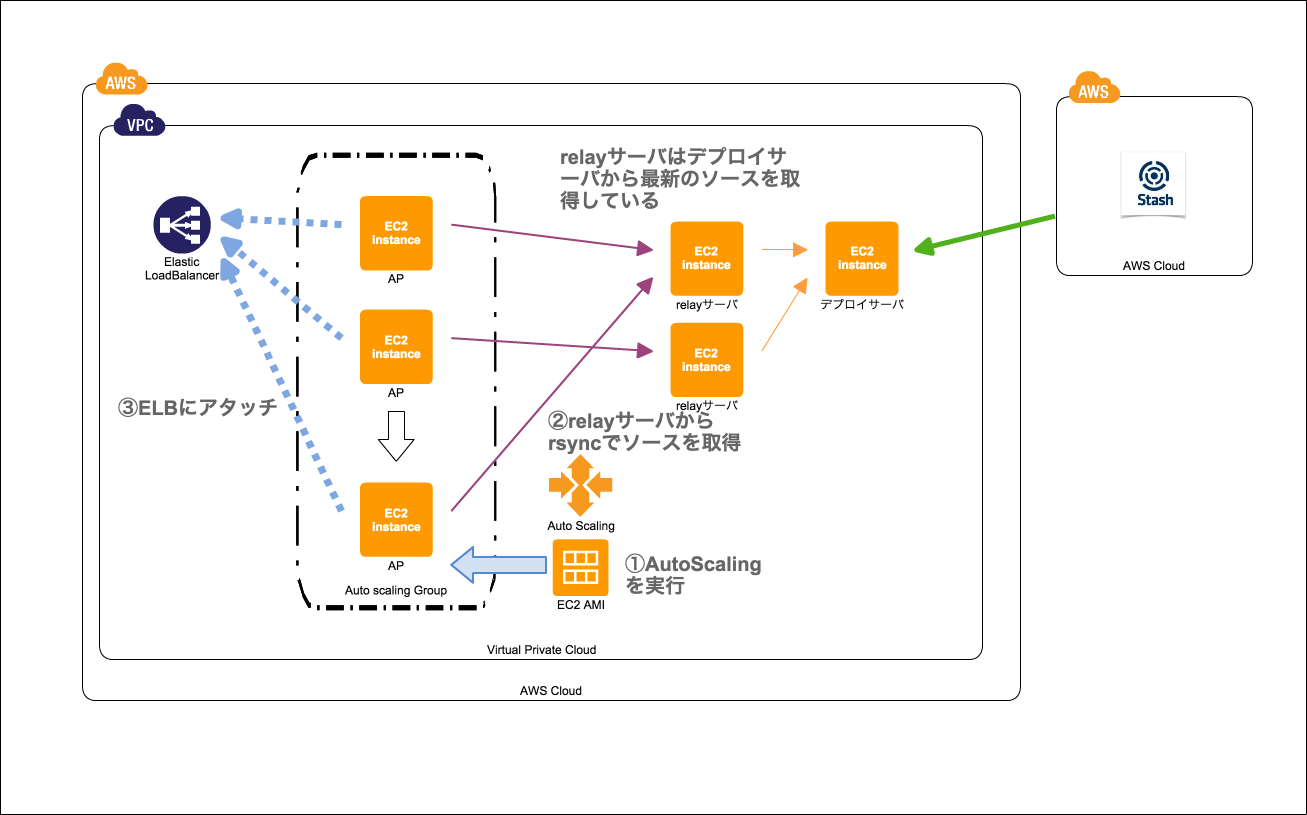
他の方法としては、AMIに最新のソースコードをデプロイしておき、最新のソースコードがデプロイされたAMIからAutoScalingを実行させれば、デプロイする必要もなく、スムーズにサービスインが可能かと思います。
この場合、スケジュールで設定したスケールアウトの時間とLaunchConfigの更新(最新のソースコードのAMIと古いAMIの入れ替え)が被ってしまった場合に、古いソースコードのサーバが起動してしまう可能性がありますので、そこを考慮しなければなりません。
他には、S3に最新のソースコードを置いておき、起動したインスタンスがS3からソースコードを取得する方法があるかと思います。CodeDeployがそれなので、今後はCodeDeployをしっかり検証して、導入していくことになるかもしれません。(個人的な意見)
2. デプロイのロック
ソースコードの取得に絡んで、AutoScalingでスケールアウト中のデプロイについてです。
gumiのAutoScalingの方法ですとEC2(デプロイサーバ)がStashからソースコードを取得して、AutoScalingのサーバがデプロイサーバからrsyncするpull型のデプロイ方法を採用しています。
この時に気をつけているのが、AutoScalingによるスケールアウト中はアプリエンジニアがデプロイ出来ないようにロックをするという点です。
AutoScalingによるスケールアウト中にアプリエンジニアがデプロイ出来た場合、古いソースコードを取得したサーバもいれば、新しいソースコード取得できたサーバが出てくる可能性があります。
これを防ぐ為に、AutoScalingによるスケールアウト中は、インスタンスのbootstrap処理(ソースコードを取得したり、ELBにアタッチしたり)にデプロイサーバへのロックを獲得する処理が含まれています。このロックが存在する間は、アプリエンジニアはデプロイが出来ないようにデプロイツール(fabric)に処理が入っています。
CodeDeploy、S3からソース取得する場合でも、デプロイが二重になってしまわないかチェックするべきポイントだと思います。
3.監視
スケールアウトが頻繁にそして大量に発生する場合、監視追加が大変になってしまいます。gumiではzabbixを監視ツールとして採用しており、AMIにzabbix-agentをインストールしています。zabbix-agentにより、サーバが起動したタイミングでzabbixサーバに追加の通知を送り、自動的に監視追加がされています。
スケールインした際は、サーバとの疎通が取れなくなったタイミングでzabbixから監視削除されているので、サーバが残ったままにはなりません。
AutoScalingを導入する際は、監視追加をどのようにするか検討しておく必要があります。
4.ScalingPoliciesによるスケールアウトは間に合わない可能性がある?(未検証)
負荷の状況からCPU使用率が80%になった時にスケールアウトするといったようになにかをトリガーにスケールアウトさせることがAutoScalingには出来ます。しかし、AutoScalingで起動するインスタンスはステータスがrunningになるまでに約2~3分程度掛かってしまいます。gumiのAutoScalingの仕組みですと、インスタンス起動に約2~3分、ソースコード取得してELBにアタッチされるまでに約1~2分ほど掛かるので、約5分ほどの時間が必要です。
タイミングによっては、急なアクセスのスパイクに間に合わず、サービス障害に繋がってしまう可能性もあります。さらにgumiのAutoScalingではデプロイのロックが発生するので、突然デプロイができない状態が発生する可能性もありますので、あまり相性が良いとは言えないのが現状です。
このような理由からScalingPoliciesによるスケールアウトは間に合わない可能性もあるということを頭に入れておく必要があります。
まとめ
AutoScalingを導入して得たメリットはインスタンス構築の工数削減、コスト削減です。インフラエンジニアとして、工数削減、コスト削減はとてもやりがいのある事だと実感することが出来ました。
gumiのAutoScalingの仕組みは先人のエンジニアが開発したもので、私はAutoScaling導入おじさんと化し、各アプリチームに導入していました。導入後はサーバ増設依頼が来ても、すぐに対応する事が可能になり、サーバ運用がいっきに楽になりました。
導入時はたくさんの失敗もありましたが、アプリチームと連携しつつ導入が行えたのは工数削減、コスト削減より価値のあるメリットだったのかもしれません。(ドヤァァア)