SQL Serverにおける文字コードについていろいろと調べたことをまとめます。
SQL Serverの文字コードについて
SQL Serverでは、nchar/nvarcharについてはUTF-16が固定で採用され、char/varcharについては、そのカラムに適用される照合順序に応じた文字コードが採用されます。
したがって、nchar/nvarcharについては照合順序の指定によって変化するのは文字列比較時の挙動だけとなります。
実験
サンプルテーブルを作成し、データをINSERTして中身をSELECTしてみます。
c1は「japanese_ci_as」を照合順序として指定しており、対応する文字コードは「Shift-JIS」です。
c2は「latin1_general_ci_as」を照合順序として指定しており、対応する文字コードは「Latin-1」です。
create table sample_table
(
c1 varchar(10) collate japanese_ci_as
,c2 varchar(10) collate latin1_general_ci_as
)
insert into sample_table (c1, c2) values ('A', 'A')
insert into sample_table (c1, c2) values ('A', 'A')
insert into sample_table (c1, c2) values ('あ', 'あ')
select * from sample_table
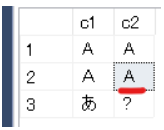
SELECT結果です。全角の「A」については、半角に変換されてINSERTされる挙動のようです。
また、Latin-1のカラムに対して「あ」をINSERTした場合、SELECT結果は「?」となりました。
ページの中身を確認します。
まずは「sys.fn_PhysLocCracker」で該当カラムが格納されているページ番号を取得します。
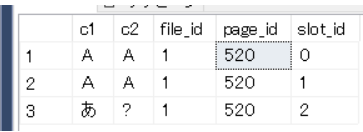
select * from sample_table
CROSS APPLY sys.fn_PhysLocCracker(%%physloc%%)
DBCC TRACEON(3604)
DBCC PAGE (N'TEST', 1, 520, 3)
DBCC TRACEOFF(3604)

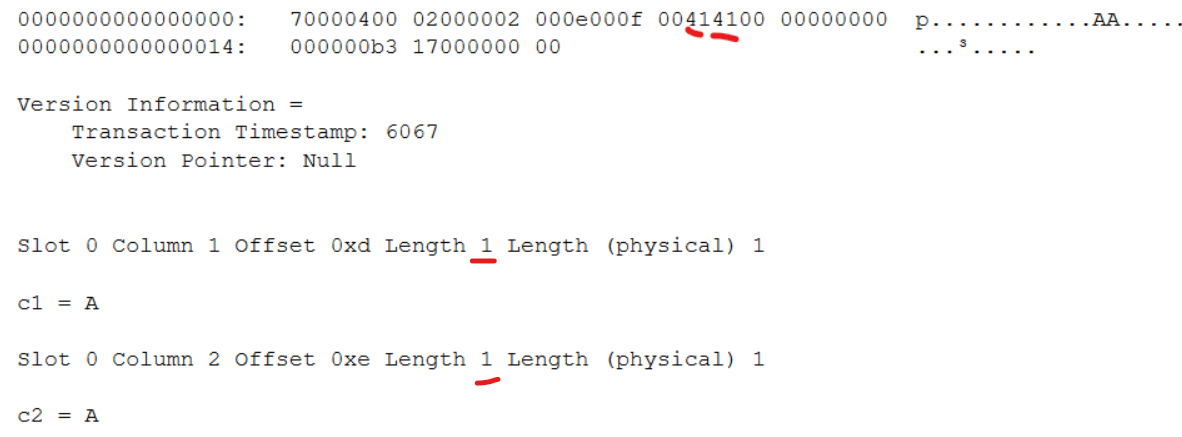
1レコード目の結果です。col1/col2の半角「A」が格納されており、その値はアスキーコードの0x41であることが分かります。
このように、ページの中身をみることで、文字がどういった数値として格納されているかを確認することができます。

2レコード目の結果です。col1は全角の「A」で、col2はSQL Serverの挙動で半角の「A」に変換されて入っていることが、実際の値としても確認できました。「0x8260」は、Shift-Jisの全角の「A」に該当していると予想されます。確認すると、実際にそのようになっていました。
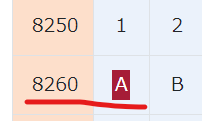
参照元:https://uic.jp/charset/show/cp932/

3レコード目の結果です。0x82a0は「あ」に対応しており、0x3fはアスキーコードの「?」に対応しています。
SELECT時に「?」に変換されているわけではなく、本当に「?」という文字でDBに格納されていることが分かります。
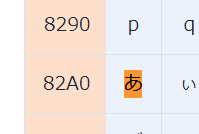
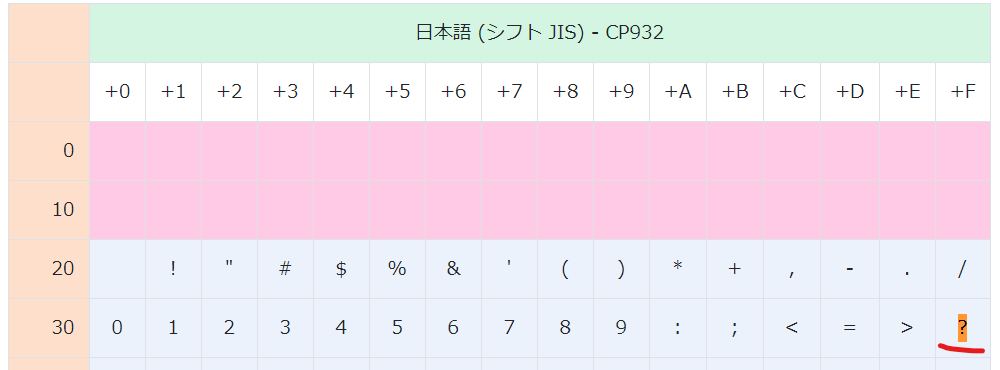
参照元:https://uic.jp/charset/show/cp932/
該当のコードページでは表現できない文字の場合、格納時にアスキーコードにおける「?」に変換される仕様になっているようです。
次に、「aあa」という、コードページに対応している文字と、未対応の文字をMIXしてINSERTしてみました。

「offset 0xd」というのは、col1が先頭から何バイト先にあるかを表しています。(0xdだと13バイト)
「Length 4」がそこから何バイトまでが該当データなのかを表しています。
つまり、↓のように、先頭から13バイト進んだ後の4バイトがカラムの値を実際に格納しているところである、と解釈できます。(1byte=16進数表記で2ケタ)

格納されているデータは「0x6182a061」となります。
col2も同じ考え方で「0x613f61」となります。文字コードに対応している文字「a」は0x61でそのままINSERTされ、未対応文字「あ」については「?」である0x3fに変換されてINSERTされていることが分かります。
つまり、SQL Serverは文字コードで対応している文字はそのままINSERT、未対応文字は一律「?」でINSERTするということがわかりました。(全部を「?」ではなく、未対応だけを「?」に変換している)
各照合順序の文字コードを取得するクエリ
以下のクエリで、照合順序に対応する文字コードを特定できます。
select COLLATIONPROPERTY(name, 'CODEPAGE') as code_page, * from sys.fn_helpcollations()
where name like 'japanese_ci_as%' or name like 'latin1_general_ci_as%'

例えば「Japanese_CI_AS」はコードページ932(Shift-JIS)であると分かります。
※コードページと文字コードは同一のものを指しており、各コードページ値に対応する文字コードがあるイメージです。コードページに対応する文字コードは例えばこちらを参照
こちらを参照すると、コードページ1252はasciiではないことが分かります。

Latin-1の照合順序はwindowsで使われているコードページ1252となっていました。
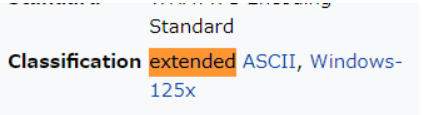
wikipediaをみるとコードページ1252の文字コードは分類が「extended ASCII」と書いてあり、asciiを拡張した文字コードであることが分かります。したがって0x7fまではASCIIと共通となっているはずです。
各カラムのコードページ確認方法
各カラムのコードページは以下のクエリで確認することができます。
ただし、nvarchar/ncharには対応しておりません。
SELECT object_name(a.object_id) AS table_name
,a.name AS column_name
,a.collation_name
,b.*
FROM (
SELECT *
FROM sys.all_columns
) AS a
LEFT JOIN (
SELECT COLLATIONPROPERTY(name, 'CODEPAGE') AS code_page
,*
FROM sys.fn_helpcollations()
) AS b ON a.collation_name = b.name
WHERE code_page IS NOT NULL
ORDER BY object_name(a.object_id)
,a.name

utf-8とutf-16で同じ文字でも格納されるサイズが違うことの確認
utf-16
create table sample_table_n
(
c1 nvarchar(10) collate japanese_ci_as
,c2 nvarchar(10) collate latin1_general_ci_as
)
insert into sample_table_n (c1, c2) values ('A', 'A')
insert into sample_table_n (c1, c2) values ('あ', 'あ')
select * from sample_table_n
select * from sample_table_n
CROSS APPLY sys.fn_PhysLocCracker(%%physloc%%)
DBCC TRACEON(3604)
DBCC PAGE (N'TEST', 1, 528, 3)
DBCC TRACEOFF(3604)
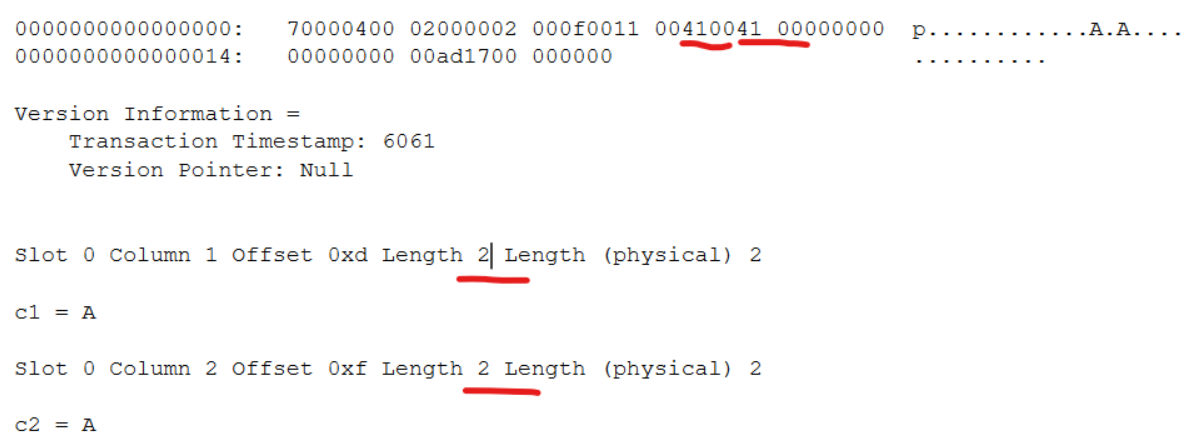
nvarchar/ncharの場合はutf-16固定となるため、半角英数字でも2バイト消費していることが分かります。(varcharの場合は半角「A」は1バイト)
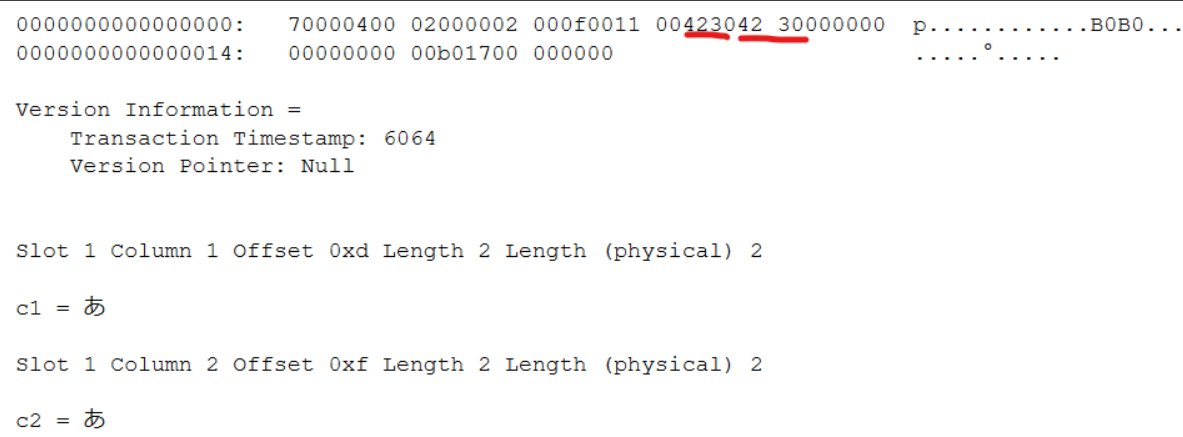
「あ」はutf-16でいうと0x3042となります。DBCC PAGEの結果はバイトが逆になって表示されるため、4230が「あ」に該当していると分かります。
ちなみに、任意の文字のutf-16の文字コードは以下のクエリで確認できます。
SELECT CONVERT(binary(3),UNICODE(N'あ'),1)

utf-8
SQL Server2019からは、vchar/charに対してutf-8を指定することも可能になりました。
select COLLATIONPROPERTY(name, 'CODEPAGE') as code_page, * from sys.fn_helpcollations()
where name like 'japanese_%utf8%' or name like 'latin1_%utf8%'

create table sample_table_utf8
(
c1 varchar(10) collate Japanese_XJIS_140_CI_AS_UTF8
,c2 varchar(10) collate Latin1_General_100_CI_AS_SC_UTF8
)
insert into sample_table_utf8 (c1, c2) values ('A', 'A')
insert into sample_table_utf8 (c1, c2) values ('あ', 'あ')
select * from sample_table_utf8
select * from sample_table_utf8
CROSS APPLY sys.fn_PhysLocCracker(%%physloc%%)
DBCC TRACEON(3604)
DBCC PAGE (N'TEST', 1, 536, 3)
DBCC TRACEOFF(3604)
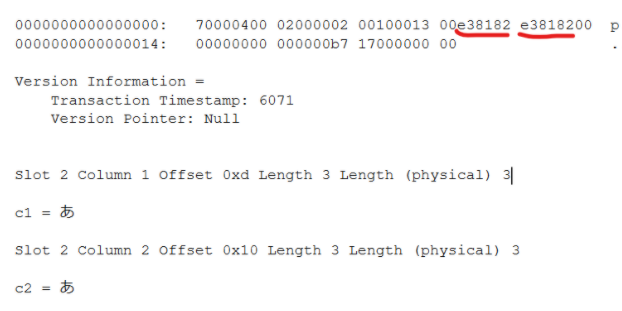
utf-16の時と違って、半角文字は1バイトで格納されていることが分かります。
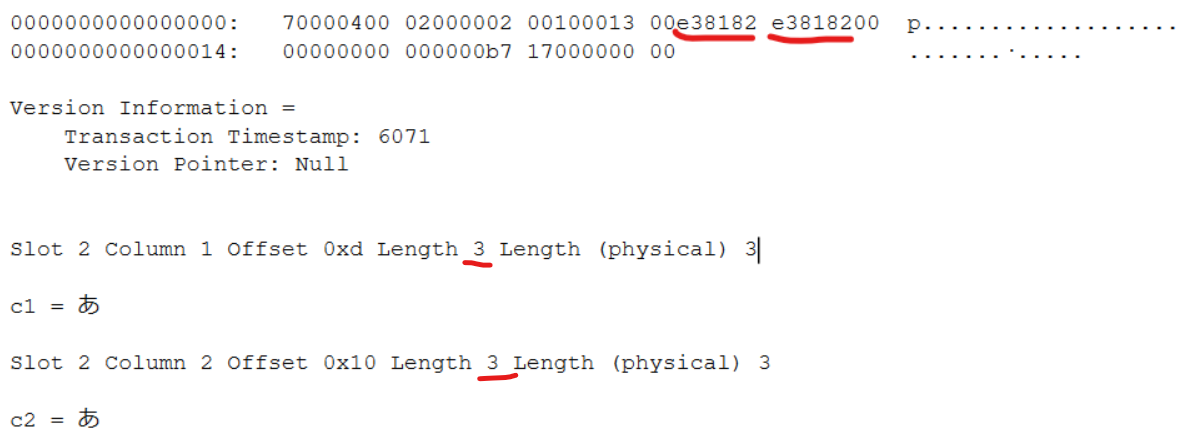
utf-8の場合は全角で3バイトつかっていることが分かります。
したがって、全角文字と半角文字が混在して格納されるカラムの場合は、全角文字が多ければUTF-16を、半角文字が多ければUTF-8を採用したほうが格納サイズを小さく保つことができるといえます。
まとめ
いろいろと検証して、文字コードへの理解が深まりました。