1. 動的管理ビューとは
・サーバーの状態情報が格納されたViewのこと。沢山種類がある
・動的管理ビュー(Dynamic Management View: DMV) と、動的管理関数(Dynamic Management Function: DMF) の2種類がある
・スコープはサーバースコープ(=どのDBでSELECTを実行しても結果が同じ)と、データベーススコープ(=各DBによってSELECTの実行結果が変わる)の二種類
・サーバースコープのDMVのSELECTにはVIEW SERVER STATE権限が、データベーススコープにはVIEW DATABASE STATE権限がそれぞれ必要(VIEW SERVER STATE権限があればVIEW DATABASE STATE権限は不要)
・内部状態を管理しているVIEWなので、基本SELECTしか投げない(更新はSQL Server内部でよろしくやってくれてる)
・SELECTするときは、スキーマ名(sys)を必ずつけないとだめ。 例:select * from sys.dm_os_wait_stats
開発者がDMVを使うメリットは?
「DMVがつかえる=サーバー全体の情報がみれる」
■ パフォーマンス評価の精度向上
いままで:自分でSSMS上でクエリ実行またはクエリを発行している機能を触ってレスポンスの体感速度で問題ないかを判断していた(人もいるかと思います)
これから:サーバー全体のパフォーマンス情報を数値で取得できるので、より正確な速度やCPU負荷に関する評価が可能
■ トラブルシューティング
いままでのシナリオ:
急にタイムアウトエラーが多発している。エラーログから該当のクエリを特定。中身をチェックしてみると、テーブルの更新処理でタイムアウトしている模様。ロックがかかっているのかな。。?でもはっきりとは分からない。該当のテーブルは1時間に1回バッチ処理で大量更新が走っていることは知っていたので、タスクスケジューラでタスクの状況を見ると「実行中」になっていた。このタスクが怪しいけど、強制終了するのも怖い。そうこうしているうちに、タスクは完了し、それに伴いタイムアウトエラーも収まった。この結果を受けて、やはりバッチでの大量更新が怪しそうだと判断。バッチ内の一括でupdateする処理を、カーソルによって1行ずつupdateさせていく処理に書き換えた。この対応が当たって、それ以降エラーは起きなくなった。
→仮説ベースなのでしんどい。そして仮説と対応が正しかったかどうかは修正クエリのリリース後でないと分からない。
これからのシナリオ:
急にタイムアウトの500エラーが多発している。エラーログから該当のクエリと接続先DBを特定。SSMSで該当DBサーバーに接続し、現在実行中のクエリリストをDMVを使って取得。すると該当クエリだけが大量に実行中で数秒~数十秒かかっている。waittypeからロックの取得待ちだと判明。ブロックしているプロセスを見ると、バッチ処理を実行しているサーバーでのクエリだった。このバッチ処理が原因であると確定。一括updateによりテーブル単位でロックを取得していたようなので、カーソルによって1行ずつupdateさせていく処理に書き換えた。それ以降エラーは起きなくなった。
→できるかぎり事実ベースで判断できる。そのため原因特定や対応の確度が高い。
■ 他にも勉強になる等いろいろメリットはありそう
実践的なサンプルクエリ
Microsoft MVPの小澤さんのGithubに沢山サンプルクエリがあります。
・SQL Server
https://github.com/MasayukiOzawa/SQLServer-Util
・SQL Database
https://github.com/MasayukiOzawa/SQLDatabase-Util
2. 実際に使ってみよう
select *
from sys.dm_exec_requests --動的管理ビュー
outer apply sys.dm_exec_sql_text(sql_handle) --動的管理関数
order by text
ポイント
・カラム数が多いので、全カラムの意味を分かってる必要は全くない
・意味が知りたいカラムはリファレンスに説明がのっている
sys.dm_exec_requests
sys.dm_exec_sql_text
3. 実践編:クエリパフォーマンス評価
※チューニングに関する話は今回はせずに、評価についてフォーカスします。
チューニングや新規ストアド/新規クエリ作成時に、こんな評価してませんか?
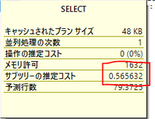
「推定コストが1以下だから大丈夫だろう」
「チューニング前よりコストが下がったからチューニング成功だ」
→ 基本的にはコストが低いほど実行は速い、という傾向がありますが、あくまで傾向のため「チューニング前よりコストが下がったのに遅くなった気がする、、、」みたいなことも全然あります。
パフォーマンス評価の指標としては曖昧なもので使うべきではないと考えます。(参考として記録しておくのは良いと思うけど、他の数値も提示するべき)
「チューニング前よりあきらかに速くなってる。成功だ」
→ チューニング前よりあきらかに速くなっているので素晴らしい成果なのですが、せっかく成果が出たのであれば、より正確に数値化したほうがインパクトがあります。
評価時に使う2つの指標
・ユーザーの待ち時間に直結する「実行時間(Duration)」
・サーバーの負荷に直結する「CPU時間(CPU)」
※他に「読み取りページ数(Reads)」という数値もとれます。(logical / physicalどちらもあります)
DurationとCPUの計測方法
リリース前に計測する場合:set statics time on
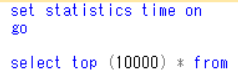
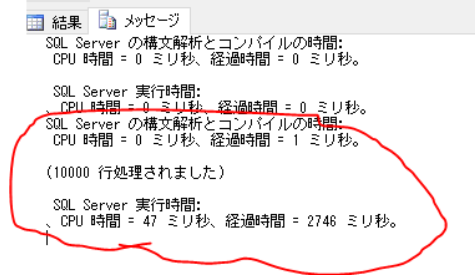
↑の例だと、コンパイル時間はCPU/Duration共に0ミリ秒で、実行時間はCPUが47ミリ秒、Durationが2746ミリ秒。
※赤丸かこまれてないコンパイル時間と実行時間は、set statistics time onを処理したときの時間なので無視でOKです。
※並列実行だと、各コアで使ったCPU時間の合算になるので、CPU時間>Duration となるケースもあります。
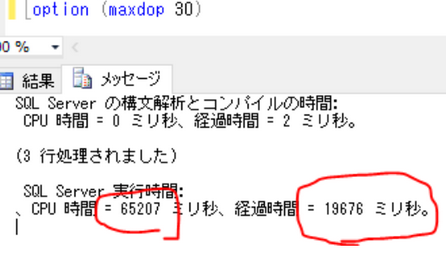
↑並列処理の次数=30にセット(次数=コア数)
CPU時間がDurationを上回ってますが、ユーザーの体感待ち時間はDurationの約20秒です。
CPU時間はサーバー負荷、Durationはユーザー待ち時間の指標だと考えればOKです。
リリース後に計測する:sys.dm_exec_query_stats
https://msdn.microsoft.com/ja-jp/library/ms189741(v=sql.120).aspx
キャッシュされたクエリプランのパフォーマンス統計が取得できます。
■ ポイント
・このビューには、キャッシュされたプランに関するパフォーマンス統計が格納される
・プランがキャッシュから削除されると、そのプランに紐づく統計データも削除される
・粒度はステートメント単位(=1ストアド内で3クエリ実行するようなストアドだと3行できる)
■ 評価用クエリ
select top 100 DB_NAME(qt.dbid) as database_name
--query text
,qt.text as parent_query
,SUBSTRING(qt.text, qs.statement_start_offset / 2, (case when qs.statement_end_offset = - 1 then LEN(CONVERT(nvarchar(MAX), qt.text)) * 2 else qs.statement_end_offset end - qs.statement_start_offset) / 2) as statement
-- average
,total_worker_time / qs.execution_count / 1000 as average_CPU_time_ms
,total_elapsed_time / qs.execution_count / 1000 as average_duration_ms
,total_physical_reads / qs.execution_count / 1000 as average_physical_reads_ms
-- execution count
,qs.execution_count as execution_count
-- creation / execution time
,last_execution_time
,creation_time
-- total
,total_worker_time / 1000 as total_CPU_time_ms
,total_elapsed_time / 1000 as total_duration_ms
,total_physical_reads / 1000 as total_physical_reads_ms
-- query plan
,qp.query_plan -- プランもみたいときはコメント外す
from sys.dm_exec_query_stats qs
outer apply sys.dm_exec_sql_text(qs.sql_handle) as qt -- クエリテキスト用
outer apply sys.dm_exec_query_plan(plan_handle) as qp -- プランプラン用
where qt.text like '%%' -- ストアド名等で絞り込みたいときはここ使う
order by total_worker_time / qs.execution_count desc --平均実行時間が長い順(目的に応じて変更する)
■ 評価用クエリを使ったチューニングの評価方法
1.リリース前の数値(cpu/duration)を取得
2.チューニングしたクエリ、ストアド等をリリース
3.リリース後の数値(cpu/duration)を取得
4.リリース前後の平均cpu/durationをそれぞれ比較した結果〇%改善された、みたいな結論を出す
例:
1.リリース前の数値(cpu/duration)を取得

2.チューニングしたクエリ、ストアド等をリリース
3.リリース後の数値(cpu/duration)を取得

4.リリース前後の平均cpu/durationをそれぞれ比較した結果〇%改善された、みたいな結論を出す
→平均実行時間が1000msから10msに減っているので、「チューニングの結果、実行時間を1000msから10msへと、99%削減できた」という結論に。
■ 注意点
・アドホッククエリの場合は1クエリごとに1レコードがsys.dm_exec_query_statsにできてしまうので、先頭30文字とかでgroup byする必要があります。
・sys.dm_exec_query_statsにはコンパイル時間は含まれません。
・ストアド内に複数クエリ存在する場合はsys.dm_exec_query_statsに複数レコードできるので、評価の際に工夫が必要な場合あり
4. 実践編:トラブルシューティング
こんなトラブル経験ありませんか?
「バッチ処理のプログラム(wsf/vbs)を作って実行したのだけど、めちゃめちゃ遅い。でもなんで遅いか分からない」
「突然あるDBサーバーのCPU使用率が100%に張り付いちゃったけど、原因不明」
「いつもはサクサクのBOのとある機能が、なぜか必ずタイムアウトしちゃう」
→サーバー上で現在実行されているクエリリストを取得できればほとんどのケースで原因が分かります。
■ 参考:現在実行中クエリのリアルタイムトラブルシューティング
https://qiita.com/maaaaaaaa/items/83e4f984e63fee4dae34
実行中リクエスト一覧を取得するクエリ(改良版)
select top 100 der.session_id
,DB_NAME(der.database_id) as database_name
,des.host_name
,des.program_name
,der.status -- Status of the request. (background / running / runnable / sleeping / suspended)
,dest.text as command_text
,SUBSTRING(dest.text, der.statement_start_offset / 2, (case when der.statement_end_offset = - 1 then LEN(CONVERT(nvarchar(MAX), dest.text)) * 2 else der.statement_end_offset end - der.statement_start_offset) / 2) as current_running_stmt
,datediff(s, der.start_time, GETDATE()) as time_sec
,wait_resource --ロックされているリソース名
,last_wait_type --最後または現在の待機の種類の名前
,der.wait_time as wait_time_ms
,der.blocking_session_id
,der.open_transaction_count
,der.command
,der.percent_complete --一部コマンドの進捗状況を表示してくれるらしい
,der.cpu_time
,(case der.transaction_isolation_level when 0 then 'Unspecified' when 1 then 'ReadUncomitted' when 2 then 'ReadCommitted' when 3 then 'Repeatable' when 4 then 'Serializable' when 5 then 'Snapshot' else cast(der.transaction_isolation_level as varchar) end) as transaction_isolation_level
,der.granted_query_memory * 8 as granted_query_memory_kb --キロバイト単位
,deqp.query_plan -- 実行プラン
from sys.dm_exec_requests der
join sys.dm_exec_sessions des on des.session_id = der.session_id
outer apply sys.dm_exec_sql_text(sql_handle) as dest
outer apply sys.dm_exec_query_plan(plan_handle) as deqp
where des.is_user_process = 1 and datediff(s, der.start_time, GETDATE()) >= 1 -- 例:1秒以上実行中のクエリに限定
and dest.text like '%%' -- クエリの中身でlike検索したいときはここを編集
order by datediff(s, der.start_time, GETDATE()) desc
調査手順
1.このクエリを実行し、まずは本当にサーバー上でクエリが実行中なのかをチェックする。
2.クエリが実行中の場合は、last_wait_typeカラムをチェック。
3.何度かクエリを実行し直してみて、last_wait_typeカラムがずっと同じ値のままであれば、そのwait_typeが原因でクエリの完了を待っているという判断を下す。
→ 1回のクエリ実行でさまざまな待ち状態が発生するのは普通のことなので、↑のクエリ実行のたびにlast_wait_typeが変化している場合は気にしなくてよい場合が多い。
4.wait_typeによって待つしかないのか、何かしらのアクションが可能なのかを判断する。
→ 例えば、wait_typeでロック獲得待ちが続いていると分かった時は、どのクエリが先にロックを獲得したのかを調べる。誰かがデータ更新で直接実行した場合はいったん止めてもらうといった判断もできる。
よく出てくるwaittype達
・PAGEIOLATCH_SH:物理的にディスクからデータを読み込む場合に、その完了を待っている状態。
・RESOURCE_SEMAPHORE:メモリリソースの獲得待ち。
・SOS_SCHEDULER_YIELD:CPUリソースの獲得待ち。
・LCK_M_xxx:ロックの獲得待ちです。xxxにはU/S/Xなどいろんな文字が入ります。この待ち状態が続くときは、他のプロセスによってロックの獲得がブロックされ続けている可能性が高いです。
・ASYNC_NETWORK_IO:DB側での実行は終わっているけど、そのレコードセットを使うプログラム側で(ループ処理などが原因で)長時間レコードセットを使用し続けている場合にこの待ち状態が続きます。
・CXPACKET:並列クエリを実行中にこの待ち状態になる。
ロックについて
ロック互換性
https://technet.microsoft.com/ja-jp/library/ms186396(v=sql.105).aspx
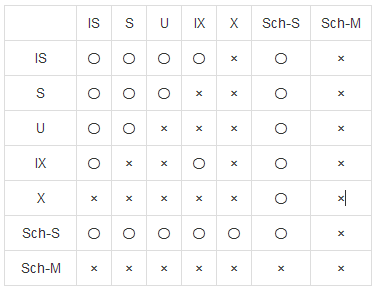
ポイント
・ロックは、リソースに旗を立てるイメージ。Sの旗は2本同時に立てられるけど、SとXの旗を同時に立てることはできず、片方が待たされる、みたいな。
・with(nolock)をつけるとスキーマ安定ロック(Sch-Sロック)が取得される
・スキーマ修正ロック(Sch-Mロック)はどのロックとも競合する一番強いロック。滅多にかかることないけど、begin tranの中でtruncateしたときなど、予期せぬタイミングでSch-Mロックかかることもあるので注意。
ロック粒度
https://technet.microsoft.com/ja-jp/library/ms189849(v=sql.105).aspx

出典:https://technet.microsoft.com/ja-jp/library/ms189849(v=sql.105).aspx
ポイント
・ロック互換性や粒度を暗記する必要はない。ロックは様々なリソースにかけることができ、操作によって異なる種類のロックが取得され、場合によっては競合するということさえ理解できれいればOK。
5. まとめ
開発者が知っておくと使えるDVMを使ったパフォーマンス評価手法と、トラブルシューティング手法について紹介しました。