弊社のサービスではDBMSとしてMicrosoft社のSQL Serverを使用している箇所があります。
本記事では、2020年1月1日からスタートしたZOZOTOWN冬セールにおける負荷対策の一環で実施した、SQL ServerのCPUチューニングについてご紹介します。
内容としては主に「どうやってプロダクション環境においてCPUボトルネックなクエリを見つけ出すか」についてです。
そのため、SQL Server以外のDBをお使いの方にも、「SQL Serverではこんな情報がとれるのか。MySQLだったら〇〇でとれる情報だな」というように比較しながら読んでいただけると嬉しいです。
※本記事はゾゾテクノロジーズ掲載のテックブログと同様の内容になります。
チューニング実施に至った経緯
初めに、なぜCPUベースのチューニングを実施したかについてお話します。
一言でいうと「ZOZOTOWNの冬セールで一部DBのCPUが負荷に耐えきれない試算となったから」です。
ZOZOTOWNでは定期的に売上を多く記録するイベントが開催されています。
その中でも毎年1月1日からスタートする冬セールは、1年間で最も売り上げが多いイベントの1つです。
したがって、DBサーバーの負荷も高くなる傾向にあります。
10月ごろに開催されたイベントで、とあるDBのCPU負荷が高騰しました。
このイベントは乗り切ったのですが、冬セールの方がより多くのトラフィックを見込んでいました。
そのため、このままでは確実にCPUボトルネックによるスロークエリが多発すると判断し、チューニングを実施することにしました。
なお、チューニング対象のSQL Serverはオンプレミスのため、スケールアップという手段は考えないこととします。
SQL Serverにおける情報収集の方法
SQL Serverのチューニングにおいて使用することが多い情報収集の方法を4種類説明します。
動的管理ビュー(DMV)
サーバーの状態情報が格納されたVIEWのことを指し、沢山種類があります。
リアルタイムで更新される情報のため、チューニングだけでなく、即応性が求められるトラブルシューティングでも活躍します。
例えば、以下のDMVを使ったクエリを実行すると
・キャッシュされたクエリの総実行時間
・総CPU時間
・実行回数
・実行プラン
などを確認できます。
SELECT TOP 100
qt.text
,total_worker_time
,total_elapsed_time
,qs.execution_count
,qp.query_plan
FROM sys.dm_exec_query_stats qs
OUTER APPLY sys.dm_exec_sql_text(qs.sql_handle) AS qt
OUTER apply sys.dm_exec_query_plan(plan_handle) as qp

他にも、
・インデックスの容量、使用回数(seek/scan/lookupごと)、最終アクセス日、断片化などの情報
・現在実行中のクエリの抽出(獲得しているメモリサイズ、実行時間、待ち事象など)
・現在のロック取得状況
など、豊富な種類の情報を取得することが可能です。
各DMVのデータ保持期間は、「現在の状態のスナップショット」か「サーバー起動後の累積値」のいずれかに大別されます。
DMVを使った情報収集用のクエリを、私のgithubでいくつか公開しています。
また、Microsoft MVPの小澤さんのgithubで豊富なDMVクエリが公開されており、おすすめです。
拡張イベント
様々なイベントをキャッチできるトレースツール、といったイメージです。
ドキュメントには「拡張イベントは、SQL Server に関する問題の監視とトラブルシューティングを行うために必要なデータを収集できるようにする、軽量なパフォーマンス監視システムです。」とあります。
SQL Server 2008 R2までの主流だったSQL Server ProfilerやSQL トレースが現在では非推奨となり、代わりに拡張イベントの使用が推奨されています。
拡張イベントの方が、情報収集時の負荷がより軽量になったとされています。
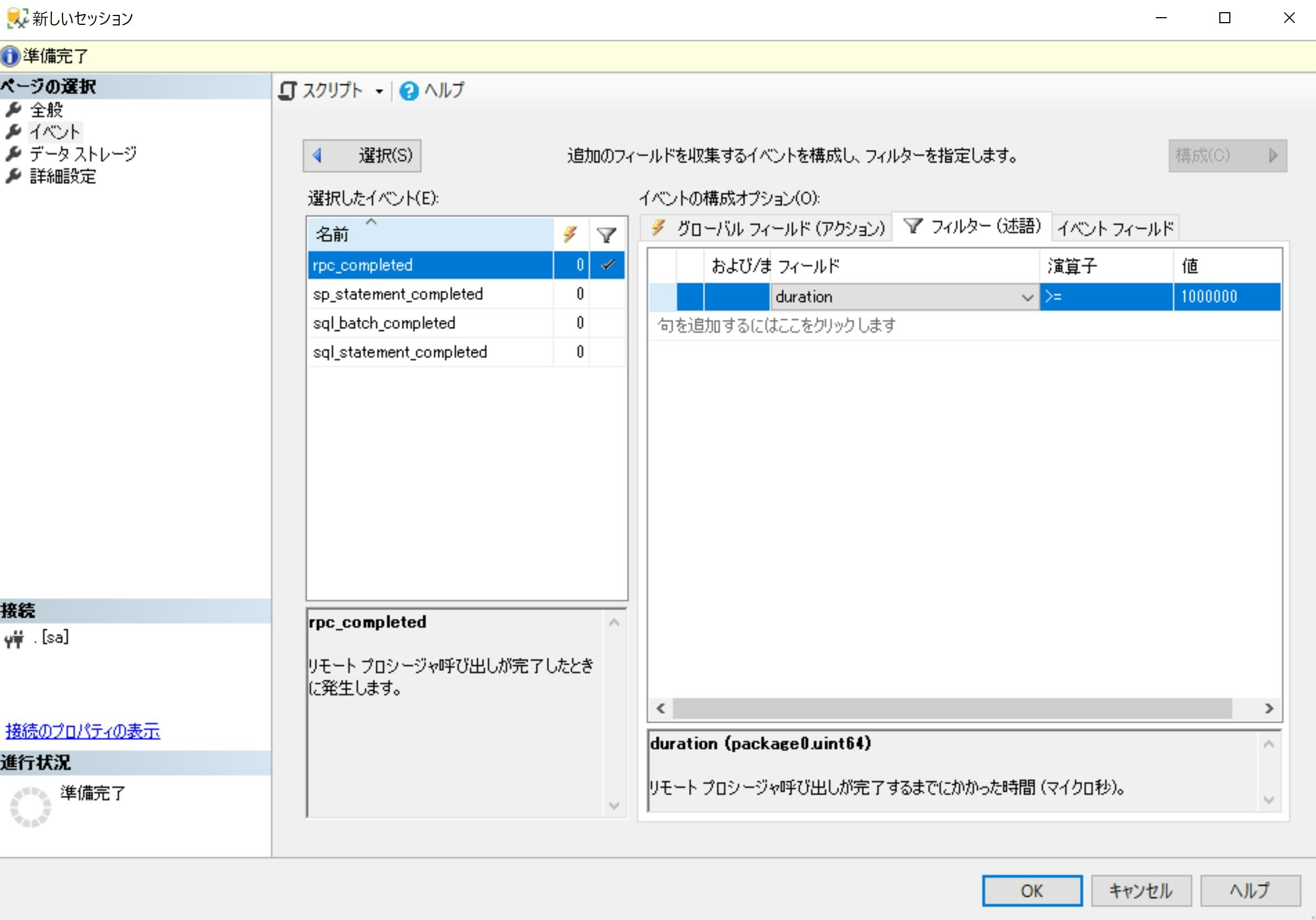
設定はクエリベースでも、以下のようにGUIベースでも可能です。
例として、下図では「実行完了に1秒以上かかったクエリ」をキャッチする設定を実施しています。
試しに5秒間waitするコマンドを実行した後にデータを表示すると、以下のようにイベントがキャッチできていることが分かります。
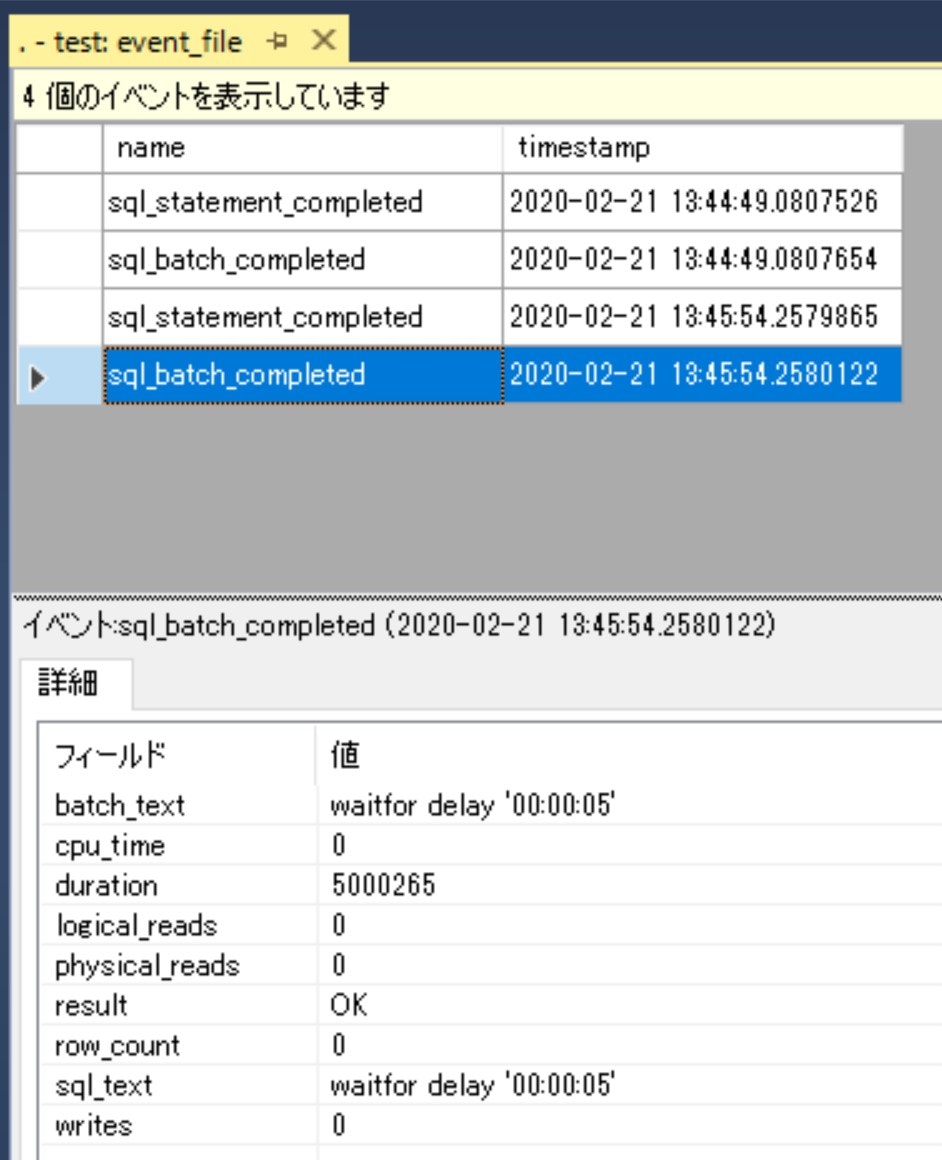
キャッチしたイベントは上図のようにGUIベースでも確認できますが、キャッチしたイベント量が多くなると確認や集計が難しくなります。
その場合は、テーブルにエクスポートすることも可能なので、SQLを使って好きなように絞り込みや集計を行うことも可能です。
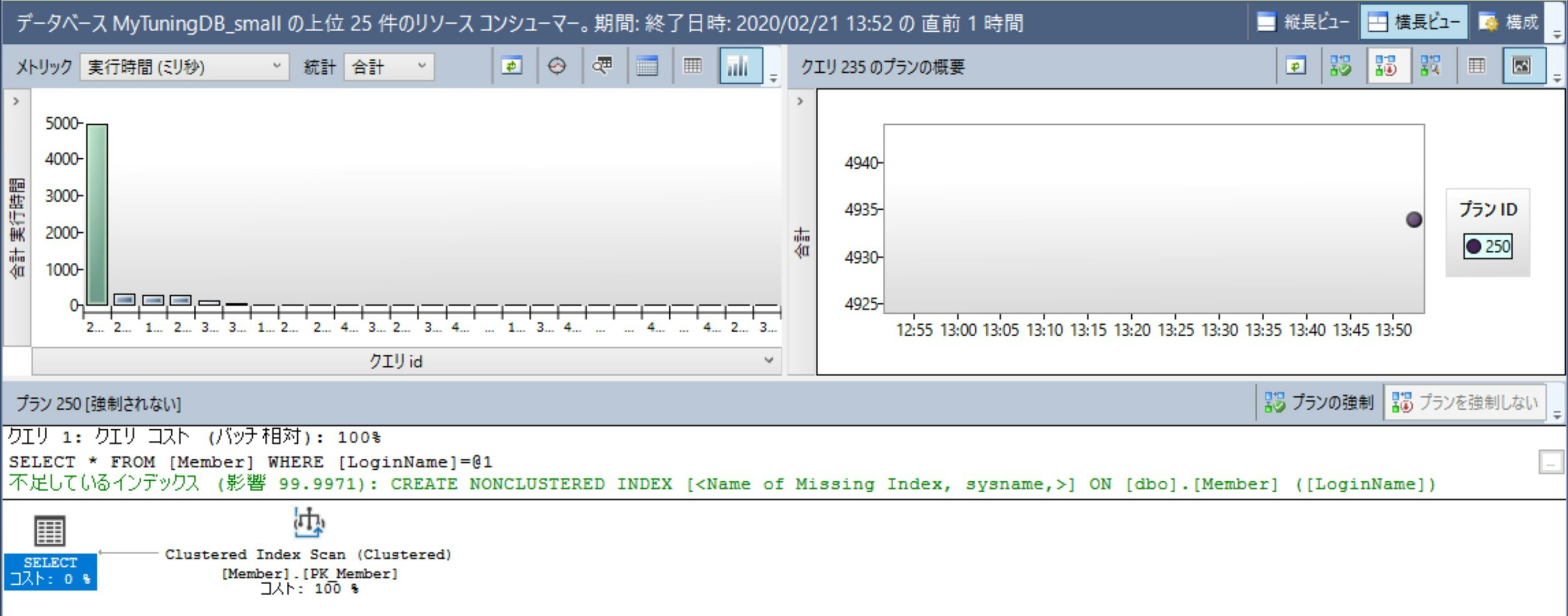
クエリストア
クエリの実行統計を自動で保存してくれます。クエリの実行時間やCPU時間、実行プランの変化などを後から追うことができます。
CPUベースのチューニングなどを行う際にかなり強力な機能となります。
また、実行プランの変化によりパフォーマンスが劣化したことを把握する目的では最も便利な機能です。
以下のようにGUIも用意されていますが、クエリベースで解析していくことも可能です。
システムモニター
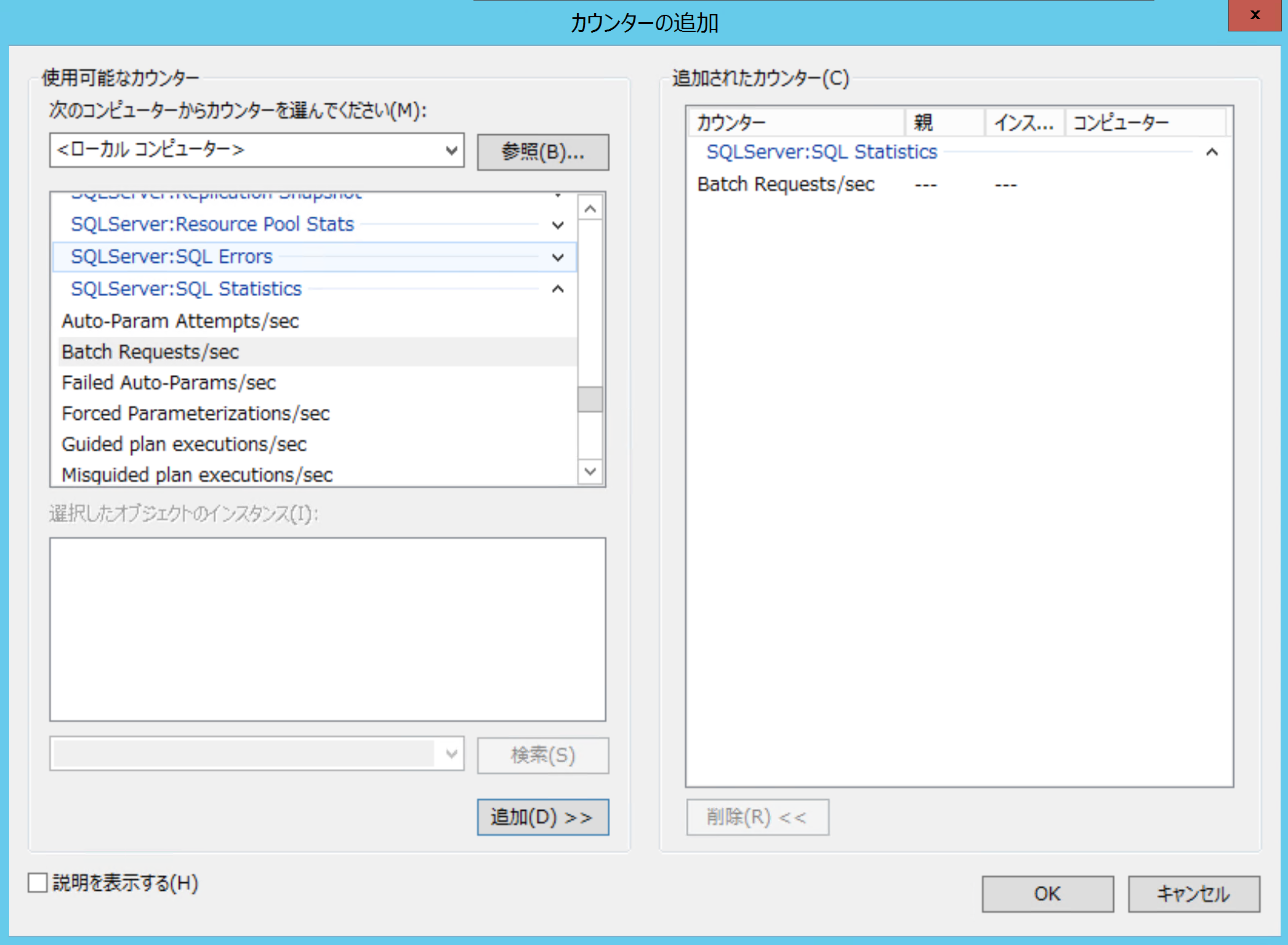
Windowsに標準で提供されている、メトリクス収集機能です。Windowsサーバー観点でのメトリクス(CPU使用率など)と、SQL Server観点でのメトリクス(秒間のバッチ実行数など)を取得できます。
パフォーマンスモニターと呼ばれることも多い印象です。
以下のようにGUIで収集するメトリクスを選択できます。
収集間隔は最短で1秒です。そのため、DatadogやZabbixといった監視製品よりも短い間隔で情報を収集したいときにも重宝します。
私の肌感では、今回紹介した4つの情報取得機能の中では最も軽量です。この機能を有効化していることでの負荷増が気になったことはありません。
今回の調査で何がチャレンジングなのか
理想的には、全てのクエリが使用したCPU時間を収集できれば、確実にCPUボトルネックなクエリを洗い出すことができます。
この目的に最も適している機能は、拡張イベントです。ただし、今回の調査では拡張イベントは使用しませんでした。
理由としては、拡張イベントを有効化したことで、トランザクションログの書き込み量が常に約2倍に増加してしまったためです。
拡張イベントはSQL Server2016から提供開始した機能で、現在ではSQL Serverにおける定番の情報収集ツールという位置づけになっています。
しかしながら、今回のサーバーでは物理リソースへの負荷の増加が許容できる範囲を超えてしまったため、拡張イベントを停止した状態で調査を実施しました。
(拡張イベントに関連した設定により改善される可能性もあるため、今後は拡張イベントの使用を再開する予定です。)
したがって、動的管理ビュー、拡張イベント、システムモニターを使ってCPUボトルネックなクエリを調査する必要があります。
拡張イベントでも全クエリのCPU時間をキャッチすることは可能ですが、プロダクション環境での負荷増につながるため現実的ではありません。
種々の情報を組み合わせながらボトルネックなクエリをどうやって探していくかがチャレンジングな部分になります。
システムモニターを使った調査
Batch Resp Statistics オブジェクトを使うことで、サーバーで実行されているクエリのCPU負荷の分布を確認することができます。
例えば、[CPU使用時間が10ms以上20ms未満のクエリの総実行時間]などです。
Batch Resp Statistics(CPU Time:Total(ms))を積み上げ面グラフにしたものと、そのときのCPU負荷(Processor(_Total)% Processor Time)をグラフにしたものを並べると同じような波形を示します。
例として、ある日のCPU高負荷となった時間帯に収集した値をグラフ化したものを以下に示します。
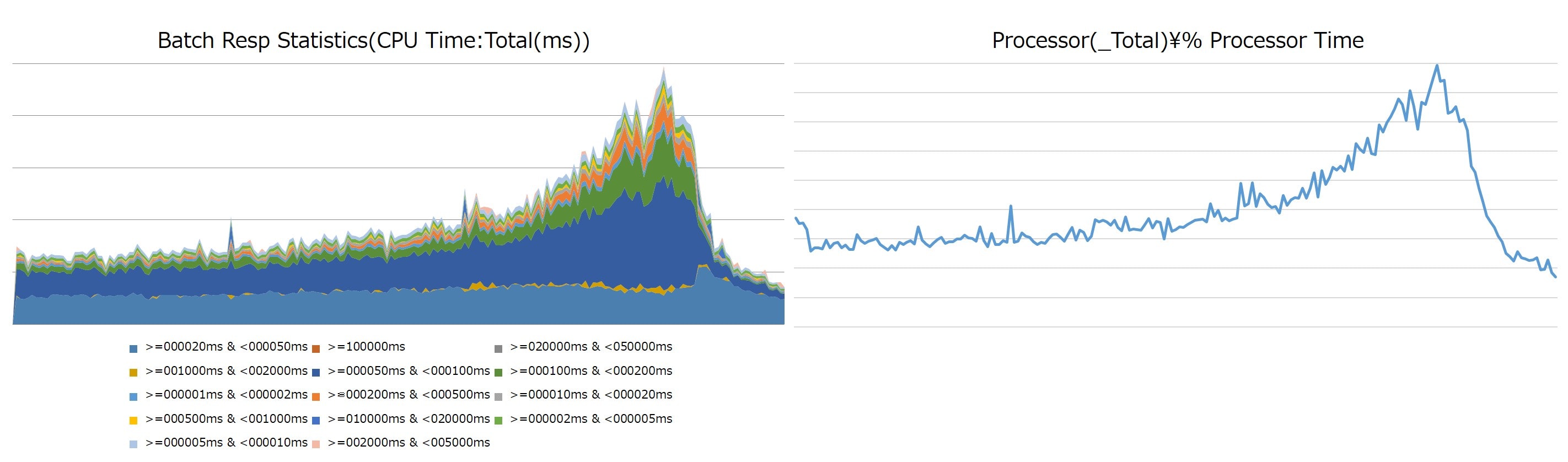
この面グラフを確認することで、CPU負荷増に最も寄与しているのはCPU時間50ms-100msのバッチ(濃い青色)だと判断できます。ミリ秒単位の、単体ではなんら問題の無いクエリが大量に実行されたことでCPU負荷につながっているケースでした。
数秒から数分単位でCPU時間を使用しているような、単体で高負荷なクエリがボトルネックとなるケースもあるため、CPU負荷をかけているクエリの性質をざっくり把握するのには非常に便利です。具体的なクエリまではこの方法では分からないのですが、拡張イベントで「CPU使用時間が50ms-100msのクエリ」をキャッチすることでクエリを特定することができます。
拡張イベントでは全てのクエリ完了イベントをキャッチすることは負荷増につながる懸念があるため、Batch Resp Statisticsを使って「CPU使用時間をどの範囲でフィルタするか」を決定するという方法は有用です。
DMVを使った調査
ドキュメントには、DMVの一種であるsys.dm_exec_query_statsを使った、CPUボトルネックなクエリを特定するクエリサンプルとして、以下のSQLが紹介されています。

出典:こちら
sys.dm_exec_query_statsには、以下の性質があります。
キャッシュしているクエリがリコンパイルされると
1.plan_generation_numがカウントアップ
2.creation_timeがコンパイル時間にアップデート
3.execution_count / total_worker_time / total_elapsed_time 等が0にリセットされる
正確には、古いplan_generation_numの値をもったレコードが削除され、新しいplan_generationi_numの値をもったレコードがINSERTされるような気もしますが。。
また、ドキュメントには以下の記載があります。
つまり、プランがキャッシュから削除されると、対応する行もこのビューから削除されます。
上記性質を踏まえると、MSのドキュメントに記載されているクエリは、「クエリがリコンパイルされることなく、かつ一切キャッシュアウトしない」という前提のもとで正確な値がとれる、ということになります。
しかし、多くのクエリが実行されているプロダクション環境においては、クエリの再コンパイルが頻繁に起き、キャッシュアウトされることも想定されます。
また、ドキュメントで紹介されているクエリは「平均のCPU使用時間が高いクエリ」を抽出することはできますが、サーバーにCPU負荷をかけているクエリを特定する、という目的であれば、「CPU負荷が高い時間帯における、総CPU使用時間が高いクエリ」を特定したいところです。
こうした背景を踏まえて、DMVを使ってできる限り正確にCPU高負荷なクエリを見つける方法を考えてみました。
プロダクション環境でのリコンパイル発生状況を確認する
sys.dm_exec_query_statsを使ってリコンパイル発生状況を確認してみます。
select *
,SUBSTRING(qt.TEXT, qs.statement_start_offset / 2, (
CASE
WHEN qs.statement_end_offset = - 1
THEN LEN(CONVERT(NVARCHAR(MAX), qt.TEXT)) * 2
ELSE qs.statement_end_offset
END - qs.statement_start_offset
) / 2) as statement
from sys.dm_exec_query_stats qs
OUTER APPLY sys.dm_exec_sql_text(qs.sql_handle) AS qt -- クエリテキスト用
OUTER apply sys.dm_exec_query_plan(plan_handle) as qp -- プランプラン用
where creation_time > dateadd(SECOND, -60, getdate())
and execution_count >= 10
このクエリは、「過去60秒以内にリコンパイルされ、リコンパイル後の実行回数が10回以上」なクエリを抽出します。
このクエリを実行してレコードがとれる場合は、「本当はCPUを沢山使っているけど、頻繁にリコンパイルされてtotal_worker_timeがリセットされているためにtotal_worker_timeが小さな値になっている」ような状況が発生してる可能性があります。
アイデア
特定の2点におけるsys.dm_exec_query_statsの情報を全てダンプして保存した場合、各レコードはクエリAまたはクエリBのいずれかに該当します。
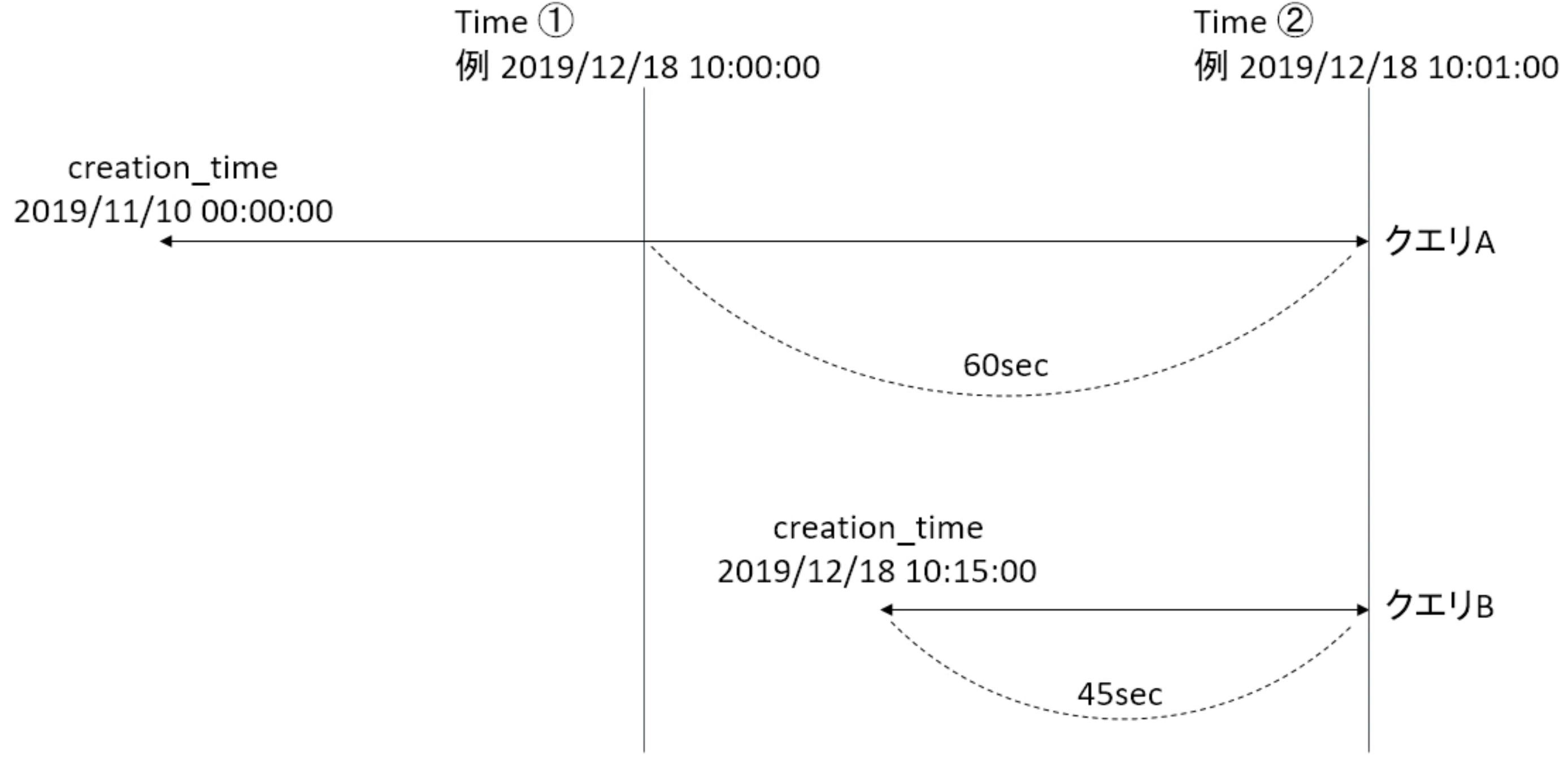
クエリA:creation_time <= Time①
クエリB:creation_time > Time①
※last_execution_time = Time② であると仮定します。プロダクション環境で常に実行され続けているようなクエリばかりの場合はこの仮定で問題ありません。
このとき、Time①とTime②の間の時間帯におけるCPU使用時間が高いクエリを見つけるために、クエリAとクエリBにおいて以下の計算を実施します。
クエリA:Time②のtotal_worker_time - Time①のtotal_worker_time
クエリB:Time②のtotal_worker_time * (Time② - Time①) / (Time②-creation_time)
これにより、コンパイル時間(=total_worker_timeの算出開始時間)が異なるクエリ達であっても、同一の時間間隔における使用CPU時間を推定し、その値が大きい順に並び替えることでCPUボトルネックなクエリを推定できると考えました。
作成したクエリと、クエリを使った解析手順
1.このクエリを実行してまずダンプ用のテーブルを作成します。
2.このクエリを(1分に1回など)定期的に実行します。最低2回取得できればOKです。
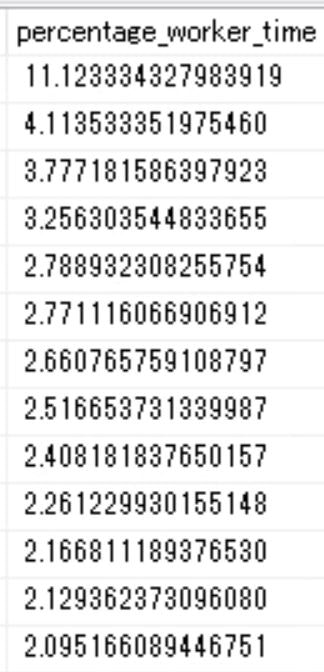
3.このクエリの、@snapshot_time_earlierと@snapshot_time_laterの2か所に、実在するcollect_dateの値を入れて実行します。
下図のように、CPU使用時間の寄与率が高い順に結果が表示されるので、これらのクエリがチューニングできないかを検討すればOKです。
チューニングについて
チューニング対象を特定できたら、あとは実際にクエリチューニングを実施し、同程度のトラフィックに対してCPU負荷がどの程度減少するかを評価します。
本記事ではCPU観点でのボトルネッククエリの調査手法をメインに扱いますので、具体的なクエリチューニングの方法については触れません。
結果
下図は、チューニング実施前後における、同程度のバッチ実行数に対するCPU使用率の推移のグラフです。
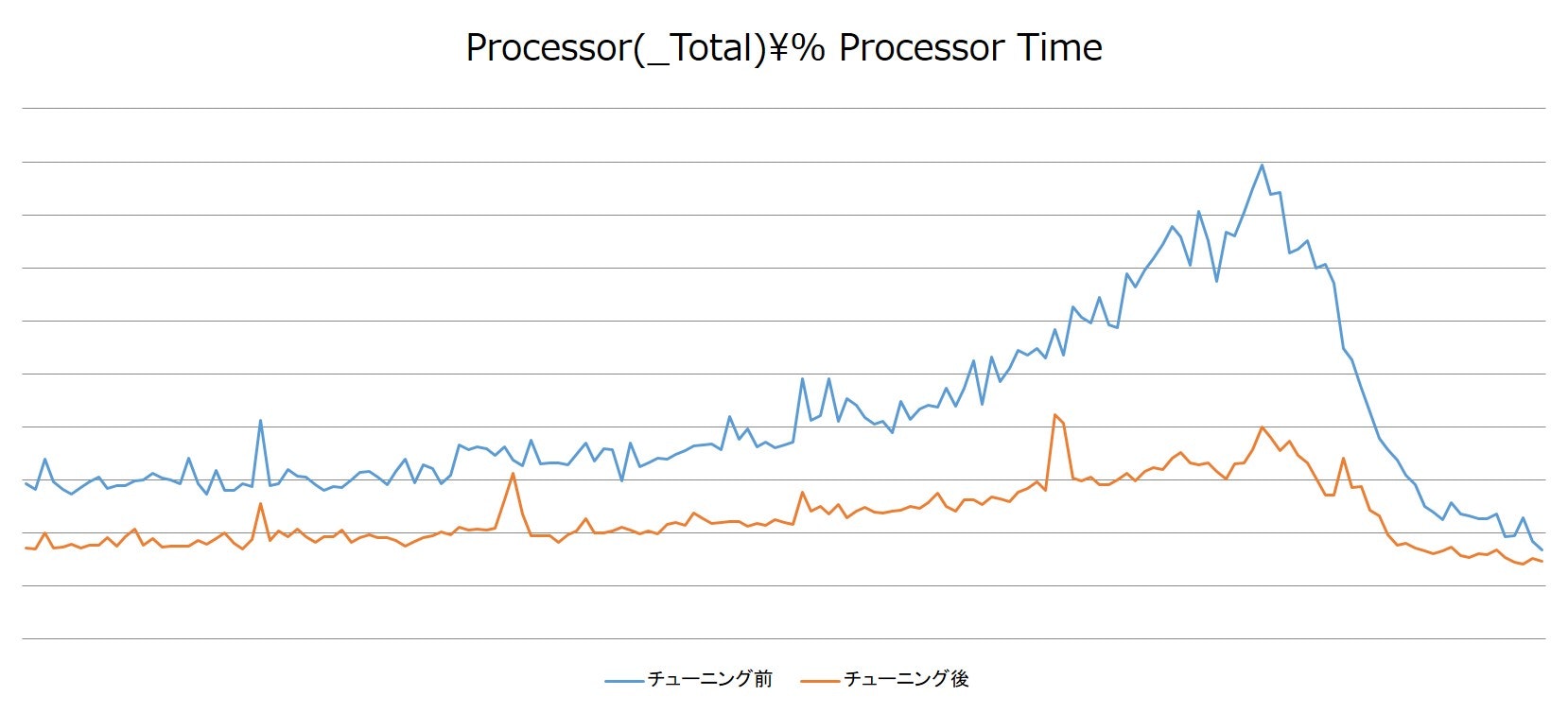
クエリチューニングを実施したことで、ピーク時間帯におけるCPU負荷を50%以上削減できました。
本対応の結果、2020年1月の冬セールで該当DBの負荷がボトルネックとなることは一切ありませんでした。
このDBで実行されているクエリは1000種類以上あり、その中でチューニングしたのは10種類ほどでしたので、一部のクエリがCPU負荷へ大きく寄与していた結果となりました。
まとめ
本記事では、CPU使用率を下げる目的でチューニングを実施する際の調査手法について紹介しました。
プロダクション環境でCPU過負荷となっていたサーバーに対して実際に調査を実施し、結果としてピーク時のCPU負荷を50%以上削減しました。
今回の調査では、DMVを使ってボトルネックなクエリを特定し、チューニング前後の評価にはシステムモニターを使用しました。
調査を実施しているときはアプリケーションについての知識は必要ありません。
ただし、実際にクエリをチューニングしていく際は、アプリケーションの開発者と協力してチューニングを進めていく方が良い結果が得られやすいということを体感しました。
例えば、開発者であれば重いクエリの一部のJOINが現在では不要なので削除できる、といった判断を下すことができます。
DBの調査を得意とする人と、アプリケーションの仕様を熟知した人とが一緒になってチューニングを実施するとより良い結果が得られると思います。