本記事では、昨年障害が発生してしまったZOZOTOWNの福袋発売イベントについて負荷対策を実施し、今年の福袋イベント期間を無傷で乗り切った話をご紹介したいと思います。
大規模サイトの障害に関する生々しい話はあまり公開されていないように思いますので、長くなってしまいましたが詳細に書いてみました。尚、今回のお話は弊社のサービスで使用しているDBMSの1つである、SQL Serverに関する話題がメインです。
※本記事はゾゾテクノロジーズ掲載のテックブログと同様の内容になります。
福袋イベント「ZOZO福袋2019」とは
年に1度、多数のブランドの福袋が一斉に発売される、ZOZOTOWNの年末の風物詩的イベントです。
今年は450以上のブランド様にご参加いただきました。お客様からも毎年大変ご好評いただいており、年間を通して最も多くのトラフィックを記録するイベントの1つです。
アクセスが殺到するが故に、昨年は福袋の発売直後からエラーが多発し、一時的に買い物し辛い状態を発生させてしまいました。昨年も負荷対策を実施していたのですが、それでもエラーが多発する状況となってしまい、エンジニア一同、お客様にご不便をおかけして申し訳ない気持ちで一杯でした。
今年こそは絶対に何事もなく福袋イベントをお客様に楽しんでいただこうと、負荷対策に力をいれましたので、順を追って紹介します。
昨年の福袋イベントで発生した障害について
昨年の福袋イベントにおける障害を時系列でまとめると以下のようになります。
12:00
福袋発売開始。
12:01
開始直後のみエラー無く好調だったものの、1分後から大量のエラーが発生。
主にDBサーバーへの接続エラーであった。
必ずエラーが発生する状態ではないものの、購入フローの途中でエラーとなるケースが多発。
注文し辛い状態が続く。
13:40
エラー多発状況が自然解消され、スムーズに注文ができるようになる。
注文数の推移からも、障害の影響が確認できます。

最初の1分間のみ多くの注文が入っています。しかし、その後急激に注文が入らなくなっています。13時40分ごろ急激に注文数が増大したことから、潜在的にはより多くのご注文をいただける余地があったと考えられます。購入フローにおいて、注文確定までの数回の遷移のいずれかでDBの接続エラー発生によりなかなか注文完了できなかったと思われます。
障害の原因調査
適切な負荷対策を実施するためには、昨年発生した障害の原因を突き止める必要があります。そのために調査を実施しました。原因調査には、障害発生時にリアルタイムで収集しておいた動的管理ビューの情報と、弊社で導入している監視製品のSpotlightを使用しました。
Spotlightについて簡単に説明しますと、サーバーの様々な情報を定期的に収集しておいて、後から任意の時間帯のサーバー状況を確認できるソフトウェアです。CPUやメモリなどのリソース使用状況や、秒間バッチ実行数、コネクション数などの各種メトリクスから実行中のクエリテキストまで様々な情報が保存されます。そのため、事後調査の際に重宝します。
サーバーの状況をSpotlightで追っていきます。秒間のバッチ実行数をSpotlight上で確認します。
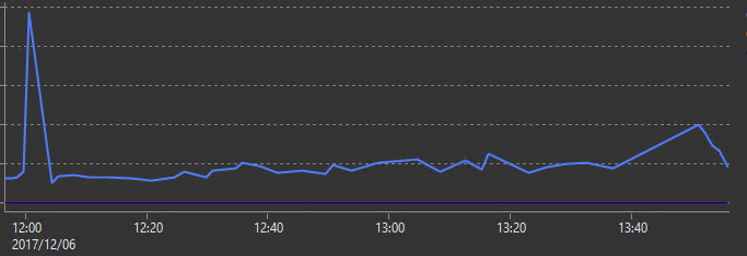
12時の開始直後は普段の約5倍のクエリ実行要求があったようです。その後急速にバッチ実行数が低下しています。この波形が自然でないことは、エラーが大量に発生していた事実からも、注文数の推移からもいえると思います。一度は大量のバッチ実行数を記録したDBサーバーが、何らかの原因で実行数を抑えつけられているようです。DBの内部で起きていたことをさらに調査していきます。
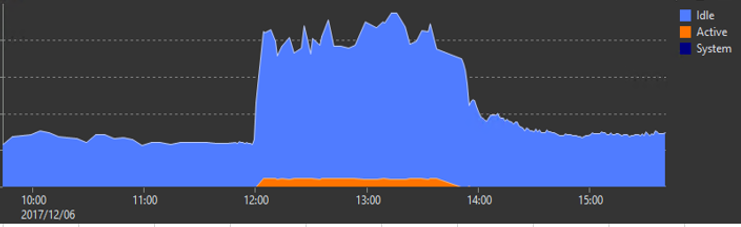
コネクション数の推移です。SQL Serverは仕様で同時接続数が最大32,767と決められており、上限を超えるとクライントにはエラーが返されます。平常時より高いコネクション数で推移しているものの、上限値まで達するということは無く余裕があり、コネクションボトルネックではありませんでした。
次に、障害発生中のDBサーバーの待ち状態の傾向を確認します。
SQL Serverでは、クエリ実行要求を受け付けてから実行完了するまでの間に生じた待ち時間を、ロックなどの待ち事象の項目ごとに確認できます。この情報は動的管理ビューの1つであるsys.dm_os_wait_statsから取り出すことができます。SpotlightからもこのViewと同等の情報を確認できます。
秒間の累積待ち時間が多い順に並び替えると、平常時は以下のような傾向を示します。
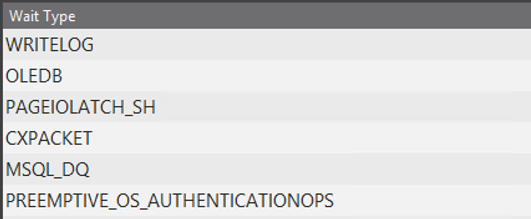
一方で、障害発生時は以下のような状況でした。平常時と比べて、まったく違う傾向を示していました。また、各項目の待ち時間も非常に高い数値を示していました。

ここでは、上位5つのWaitTypeについて紹介します。
THREADPOOL : ワーカースレッドの確保待ち
LCK_M_S : 共有ロックの獲得待ち
PAGELATCH_SH : 共有ページラッチの獲得待ち
LCK_M_U : 更新ロックの獲得待ち
PAGELATCH_EX : 排他ページラッチの獲得待ち
「ワーカースレッド」と「ページラッチ」については、聞いたことのない方もいらっしゃるかもしれませんので、それぞれの用語について少し補足をしておきたいと思います。
ワーカースレッドとは、SQL Serverのクエリ実行時にスレッドで使用されるリソース、ページラッチは、SQL Serverのデータ格納領域である「ページ」の一貫性を保つための排他制御の仕組みとイメージしていただければと思います。
(SQL Serverでは、1ページあたり8KBで管理され、ページの中には同一テーブルのレコードが複数入っています。1ページあたり何レコード格納されるかは、1レコードあたりのデータサイズに依存します。)
先ほどの、障害発生時の待ち事象の1位はTHREADPOOLのwaitが圧倒的に多く、次いでページラッチ系とロック系のwaitが2位から5位までを占めていました。平常時は、これらのwaitが多く発生することはありません。
CPUリソース不足時に高い数値を示すSOS_SCHEDULER_YIELDの値はTHREADPOOL待ち時間の100分の1程度でした。そのため、CPU負荷もボトルネックでは無いと判断しました。
THREADPOOL waitが圧倒的に多かったため、多発していたエラーとの関連性を調べるために、ローカル環境のDBでワーカースレッドを意図的に枯渇させてクエリを実行してみました。その結果、本番環境で多発していたものと同様のエラーが発生することを確認できました。
このことから、多発していたDB接続に関するエラーは、ワーカースレッドが枯渇したことが、原因の一つであると判断しました。ということで、昨年の福袋の障害の原因は、DBの状態としては「ワーカースレッドの枯渇により大量のTHREADPOOL waitが発生した」ということが確認できました。
ここで、「ではワーカースレッドの最大数を増やせば解決するのでは?」という疑問がわきます。
ただし、現状のワーカースレッドでも平常時の5倍の要求を一時的に受け付けていることから、単純にワーカースレッド数を増やせば解決する問題でもなさそうです。
次に、ワーカースレッドが枯渇してしまった原因について調べました。Spotlightを使って、エラー発生時に実行中だったクエリリストを確認します。
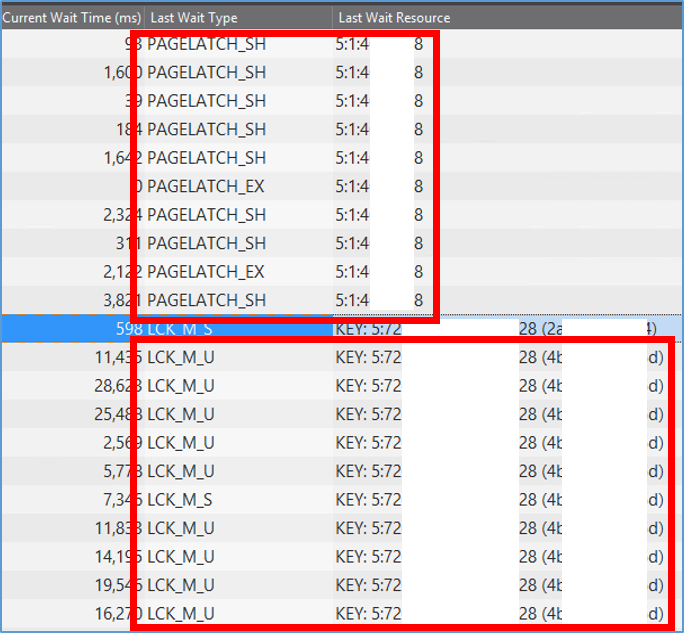
「Last Wait Type」「Last Wait Resource」から、同一のリソースに対して、大量のページラッチ獲得待ち(PAGELATCH_****)と、キーロック獲得待ち(LCK_M_**)がそれぞれ発生していることが確認できます。「LCK_M_U」の情報から、獲得しようとしているロックの粒度がKEYであるため、特定のレコードに対する読み取り要求、更新要求が大量に実行されていることが分かります。
「PAGELATCH_SH」「LCK_M_U」の「Last Wait Resource」に表示されているリソースの値だけでは「どのデータが対象になっていたのか」までは、判断することができません。そこで、次の方法を使用して、データの取得を行いました。
PAGELATCH_SH で出力されていた、Last Wait Resourceの値を使って、具体的にどのテーブルのどのようなレコードが含まれているページへのアクセスであるかを調査しました。
ページラッチ待ちが多発しているLast Wait Resourceの値と「DBCC PAGE」を使ってページの中身をダンプさせます。
DBCC TRACEON(3604)
DBCC PAGE (N'DB名', 1, 4xxxxx8, 3)
DBCC TRACEOFF(3604)
次に、ロック待ち(LCK_M_U)が多発しているLast Wait Resourceについて対応するテーブルとレコードを特定します。KEY:DBID:hobt_id(%%lockres%%)という構成になっているため、下記のクエリを使います。
--1.hobt_idを指定してテーブル名を取得
select sc.name as schema_name
,so.name as object_name
,si.name as index_name
from sys.partitions as p
join sys.objects as so on p.object_id = so.object_id
join sys.indexes as si on p.index_id = si.index_id
and p.object_id = si.object_id
join sys.schemas as sc on so.schema_id = sc.schema_id
where hobt_id = 72xxxxxxxxxxxxx28;
--2.取得したテーブルのレコードを、%%lockres%%を使って絞り込んで特定
SELECT
*
FROM テーブル名
WHERE %%lockres%% = '(4bxxxxxxxx5d)';
以上のクエリを実行した結果、ページラッチとロックは同じテーブルの特定レコードに関連する待ちであることが分かりました。購入フローの中でDB上の在庫に関するデータを更新する処理があるのですが、人気福袋の購入希望者が殺到したことで読み取り要求、更新要求の競合が多発してボトルネックとなっていたようです。
図示すると以下のようになります。
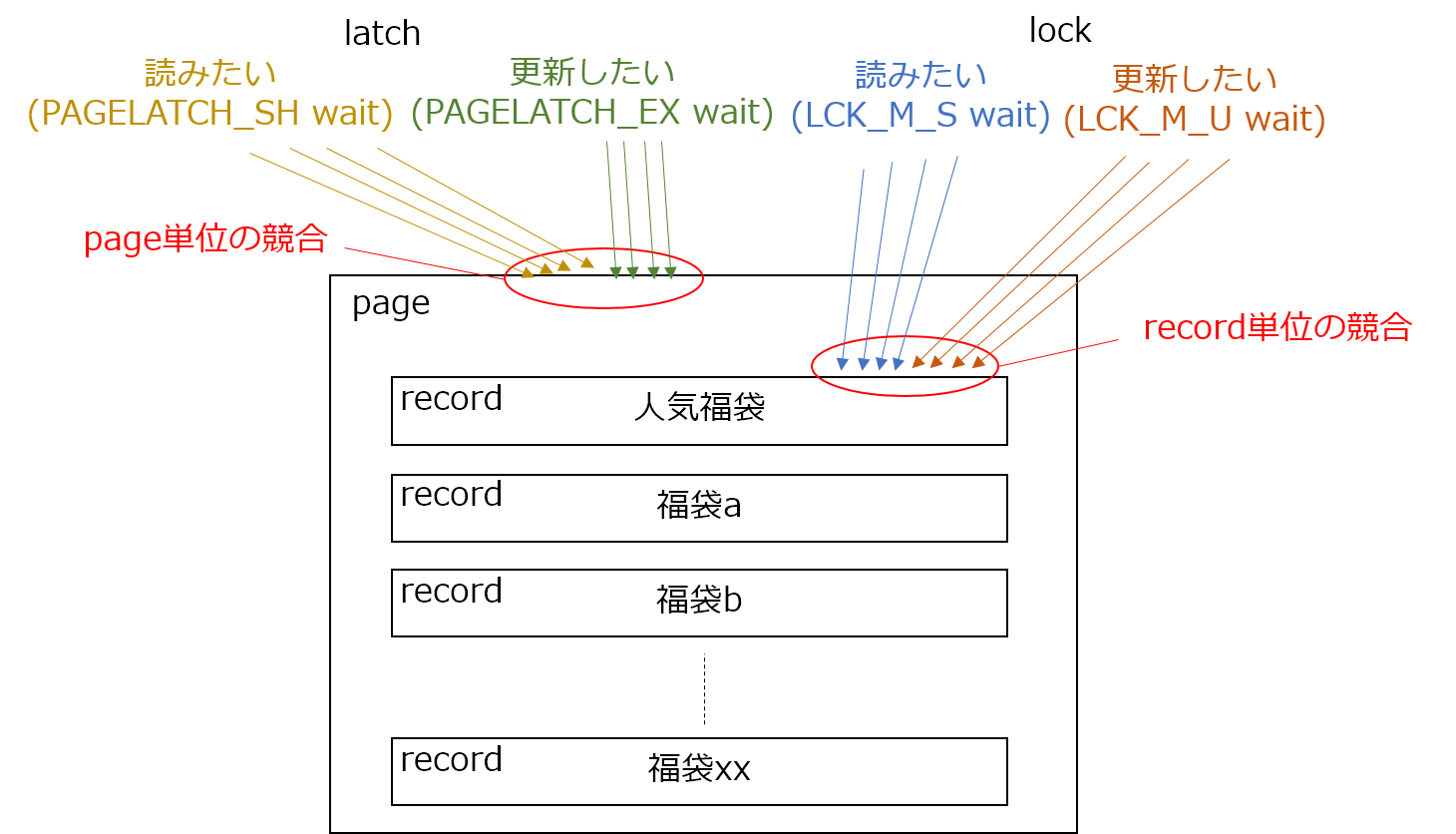
ロックはレコード単位で競合するのに対し、ページラッチはページ単位で競合します。そのため、ページラッチについては、人気福袋と同一ページにある他の福袋商品へのアクセスとも競合してしまっていました。
障害発生中、ページラッチ待ちとロック待ちが発生しているクエリは、実行中の全クエリの約半分を占めていました。そのため通常よりワーカースレッド解放に時間がかり、大量のDBアクセスを捌ききれなくなり、ワーカースレッド確保待ちが大量に発生してエラーの多発につながったと考えられます。
この状況を図示します。まず、SQL ServerのCPUのアーキテクチャの概要図です。
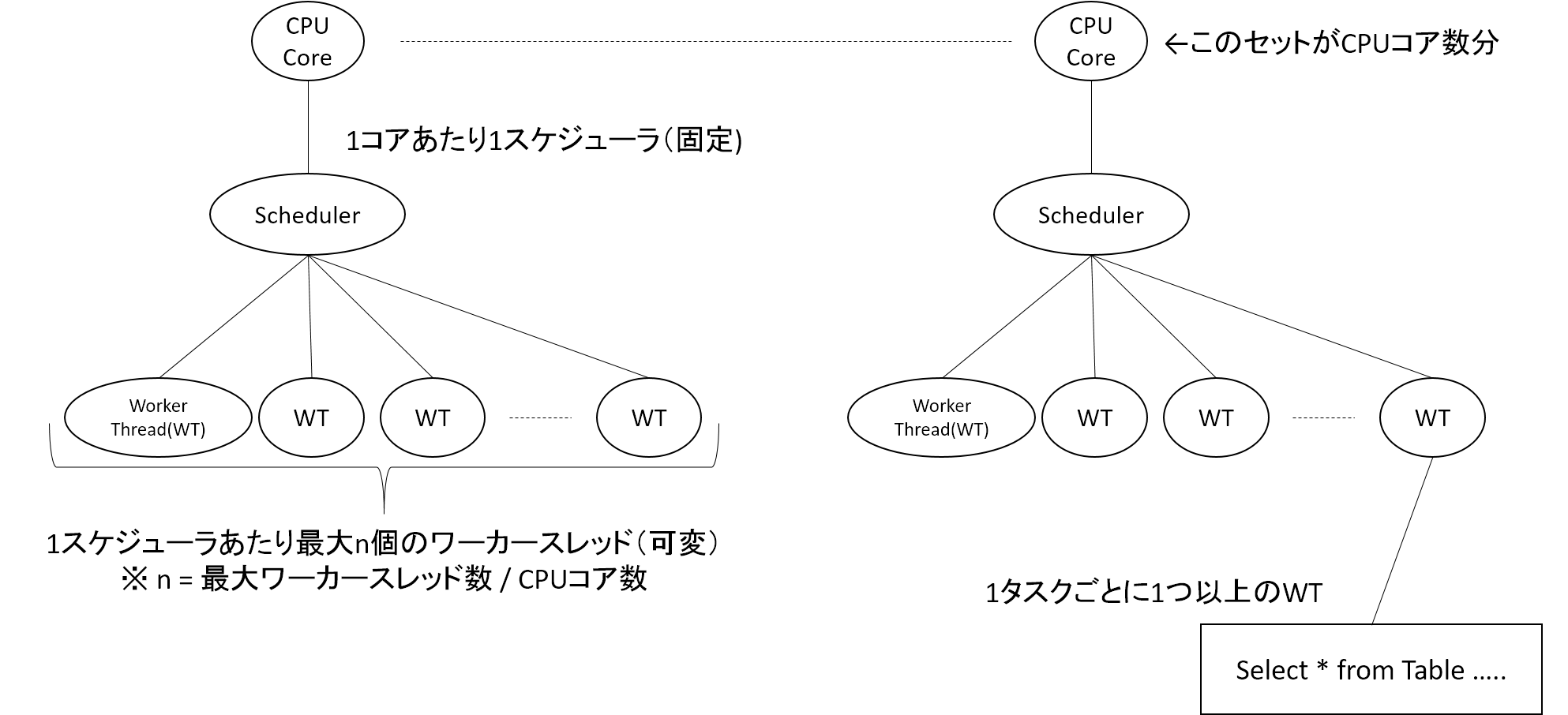
SQL ServerはCPU1コアにつき1つのスケジューラが割り当てられます。各スケジューラに対して複数のワーカースレッドが割り当てられます。クエリ実行時にワーカースレッドが1つ以上利用され、クエリの実行が行われます。SQL Server では、作成できるワーカースレッドの数に上限があります。(作成できるワーカースレッド数の上限は、「max worker thread」という設定で変更できます。)
実行されていたクエリのうち、ページラッチとロック競合が発生していなかったクエリは全体の半分を占めていました。これらのクエリではワーカースレッドの利用と解放が高速に行われていました。一方で、解放および競合が発生していたもう半数のクエリでは、ページラッチやロックといったリソース獲得待ち状態で、ワーカースレッドの解放が遅くなっていました。結果として利用可能なワーカースレッドの低下による全体のスループットが低下し、にもかかわらずクエリの要求数は増え続け、慢性的なワーカースレッド枯渇状態に陥って大量のエラー多発、というシナリオだと思います。
人気商品以外の商品を閲覧、購入されていたお客様は、ワーカースレッドが確保できてしまえば、高速に要求を処理できていたと考えられます。一方で人気商品へのアクセスは、ワーカースレッドを運よく確保できたとしても、実行時にロック獲得待ちなどの理由で実行時間がかなり伸びてしまいます。そのためタイムアウトも発生しやすい状況であったはずです。
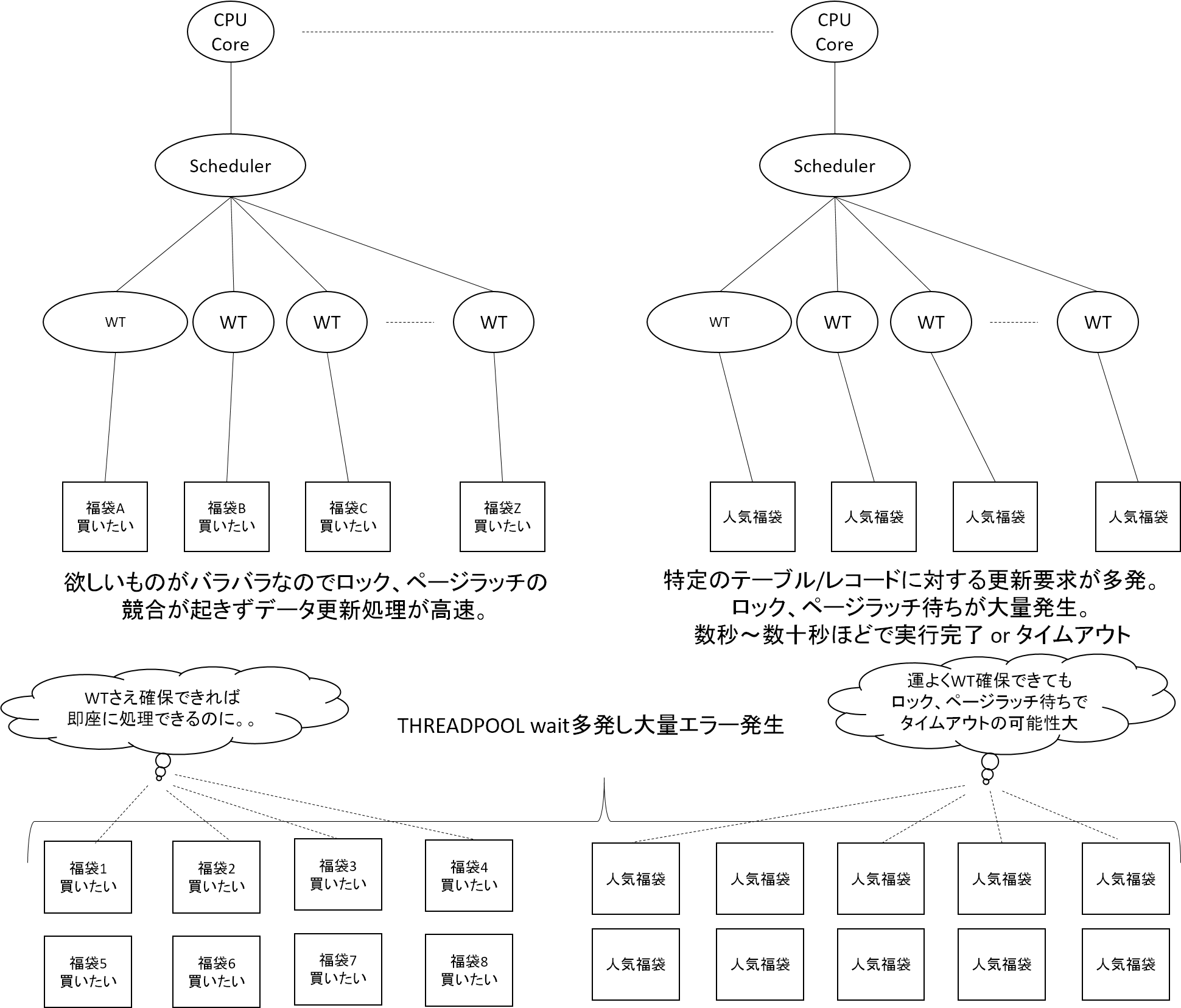
ただし、12時からの1分間は大量に注文が入っていることから、その後のエラー多発状態へと移行したタイミングで何が起きていたかの説明はできていません。
12時1分を過ぎたタイミングから、ロックおよびページラッチ獲得待ちが大量に発生していることから、ブロッキング(ロック競合)が発生していたと考えられるため、Spotlightでブロッキングのグラフを確認しました。
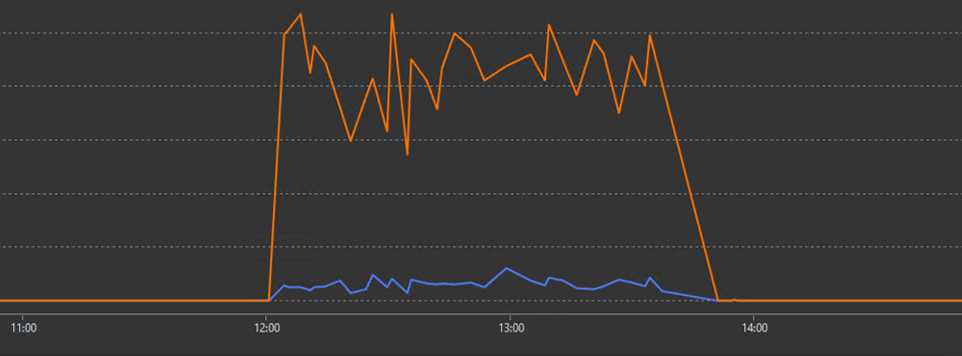
ブロッキングが大量に発生しています。ブロックされているプロセス(オレンジ色)が多数あるのに対して、ブロックを引き起こしているプロセス(青色)の数は多くありません。少数のプロセスがその他大勢のプロセスをブロックしていることが分かります。ブロッキングの情報をさらに追っていきます。

↑13時15分時点のブロッキング情報の一部です。Head Blocker(黄色線の情報、ブロッキングを発生させる原因となっているプロセス)のStatusが「Seeping, blocking」となっています。つまり、スリープしているプロセスが、大量のプロセスをブロックしていたことになります。「スリープしてるのにブロックしてる」とはどういう状況なのだろうと調べてみたところ、同じような症状に関する記事を見つけました。
Sleeping SPID blocking other transactions
この記事によると、明示的なトランザクションを張ったまま途中でタイムアウトしてしまうと、クエリの実行方法によっては、ロールバックされずトランザクションが継続された状態になります。したがってロックを獲得している場合はロックも保持し続けることになります。ローカル環境にて実験したところ、確かに再現しました。
ただし、ローカル環境で試す中でタイムアウト後に即座にロールバックされる場合もありました。調べたところ、明示的にトランザクションを開始し、ロックを保持したままタイムアウトした場合、そのロックの解放タイミングは「コネクションプールに戻ったコネクションが別のクエリによって再利用されるとき」でした。それは0.1秒後かもしれないし、数分後かもしれません。
※コネクション/コネクションプールの仕組みについてはこの記事で非常に詳しく書かれていました。
昨年の福袋イベントのケースにあてはめて考えると、大量にアクセスされていた状況ならすぐにコネクションが再利用されることでロックが解放されてもおかしくないのでは?という疑問がわきます。この疑問を検証するために実験を行ったところ、ロールバックされるためには、コネクションの再利用時にまずワーカースレッドを確保する必要があるとの結論に至りました。
これらの調査を踏まえて、福袋発売後に以下のシナリオが発生してバッチ実行数が著しく低下したと考えました。
1.購入フローにおいて、人気商品に関するデータへの読み取り要求、更新要求が大量に発生。
それに伴い特定のレコードに対してのロック、ページラッチの獲得待ちが発生。
2.人気商品データのロックを獲得したプロセスAが処理の途中でタイムアウト。
ロールバックされず、取得したロックが解放されないままコネクションプールに戻る。
3.別プロセスが該当コネクションの再利用を試みるも、
ワーカースレッド枯渇のためTHRADPOOL waitが長時間発生してエラー発生。
そのためロールバックとロックの解放が長時間おこなわれなかった。
4.プロセスAが保持したロックによって、他のプロセスが大量にブロックされる。
(複数の人気商品において2~4の事象が発生)
5.ブロッキングによって各プロセスの実行速度が急速に低下。
ワーカースレッドの解放が遅くなり全体としてスループットが低下した。
昨年の障害発生原因を踏まえた対応を実施
ここまでのまとめ
・昨年の福袋イベント中にエラーが多発したのは、DB内部でワーカースレッド確保待ちが大量発生したため
・ワーカースレッド確保待ちが大量発生したのは、人気福袋データに対するクエリ実行要求が集中し、かつタイムアウトしたプロセスがロックを解放しないことでブロッキングが急激に増大したため
・昨年の障害発生時には、以下の五項目の待ち時間が圧倒的に多かった
THREADPOOL
LCK_M_U
LCK_M_S
PAGELATCH_SH
PAGELATCH_EX
以降では、昨年の障害調査を踏まえて実施した負荷対策についてまとめます。
対策1. プロセスをSleepingかつBlockingにさせない
タイムアウトしたプロセスがそのままロックを掴みっぱなしになっていたことが、ブロッキングの状況を加速度的に悪化させた原因のため、タイムアウト時のトランザクションを適切に処理する必要があります。
対応方法としては、SET XACT_ABORT ONをトランザクション開始前に設定しました。このオプションは、トランザクション内でエラーが発生すると即座にロールバック+ロックの解放を行うように指示できるオプションです。
この対策を実施することで、特定のクエリがタイムアウトした途端にブロッキングが加速するというリスクを無くすことができます。
対策2. 昨年多く発生していた待ち事象を減らす
■ THREADPOOL
この待ち事象は、ブロッキングが大量に発生したためにワーカースレッドの解放が遅れたことが原因と考えられるため、THREADPOOL Waitを減らすためには、ブロッキングを減らす必要があります。ただし、万一ブロッキングが大量発生する等の理由でワーカースレッドが枯渇するときのことを考慮し、ワーカースレッドの最大数を2倍に増やしました。合わせて、maxサーバーメモリの値を減少させました。これは、ワーカースレッドの確保にはメモリが必要となり、このメモリはバッファプール用に確保しているメモリ(maxサーバーメモリ)とは別の領域から確保する必要があるためです。
そのため、maxサーバーメモリを減少させ、ワーカースレッドを作成する際に必要なメモリを確保できるように、メモリサイズの調整を行いました。
この対応により、THREADPOOL Waitを削減できるわけではありませんが、大量にワーカースレッドを使用する環境下においては同時実行性能の向上が期待できます。
■ LCK_M_U
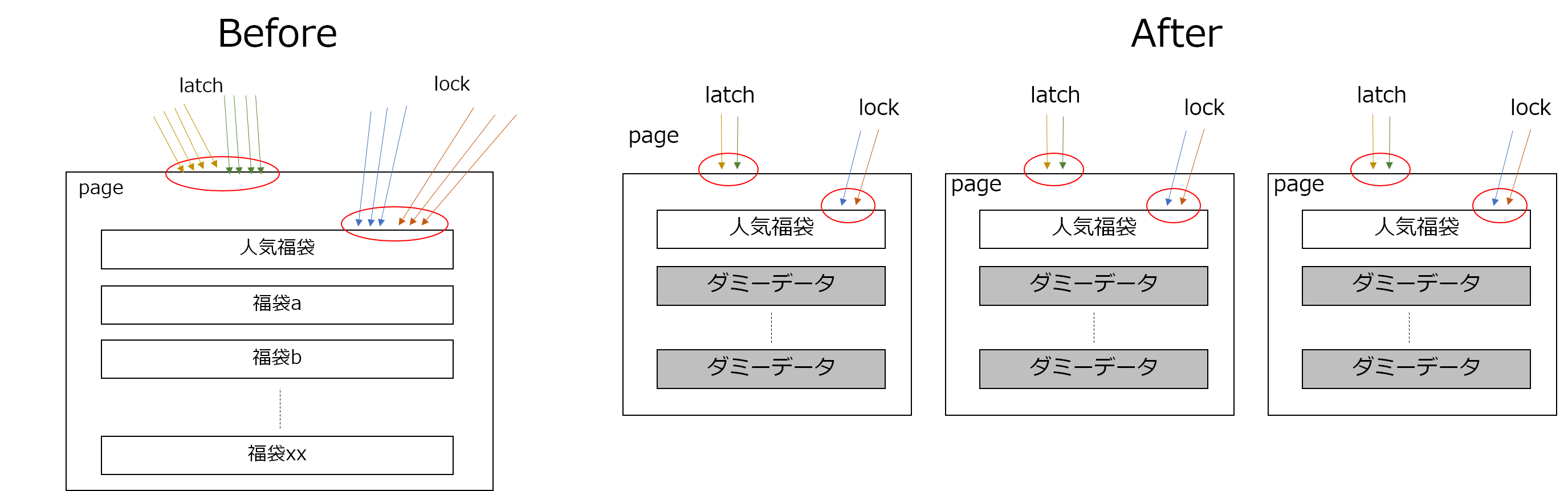
購入フローの一部にDB上の在庫に関するデータを更新する箇所があり、人気商品の購入希望者が殺到すると、人気商品の在庫に関するデータレコードの更新処理で大量のブロッキングが発生していました。これを軽減させるために、人気商品に関しては、サイト上の見え方およびユーザーには影響ない形で在庫に関するデータを分割して販売しました。
■ LCK_M_S
一部のクエリにwith(nolock)というロックヒントを付与することで、Sロックよりも競合が少ないSch-Sロックを取得するに留めさせました。もちろん、ダーティリードを許可できる箇所である、というのが前提となります。
■ PAGELATCH_SH / PAGELATCH_EX
獲得できるページラッチは1ページあたり1つだけのため、同一ページ内の異なるレコードへの更新要求同士であってもページラッチの競合は発生します。そのため、1ページの中に福袋商品の在庫に関するデータレコードが1つだけ存在する状況を意図的に作り出しました。具体的には、福袋商品以外のレコードは、サイト上からは見えないダミーの在庫に関するデータレコードで埋めました。これにより、ページラッチ競合の改善が期待できます。
これらをすべて対応した際のイメージを以下の図にまとめました。
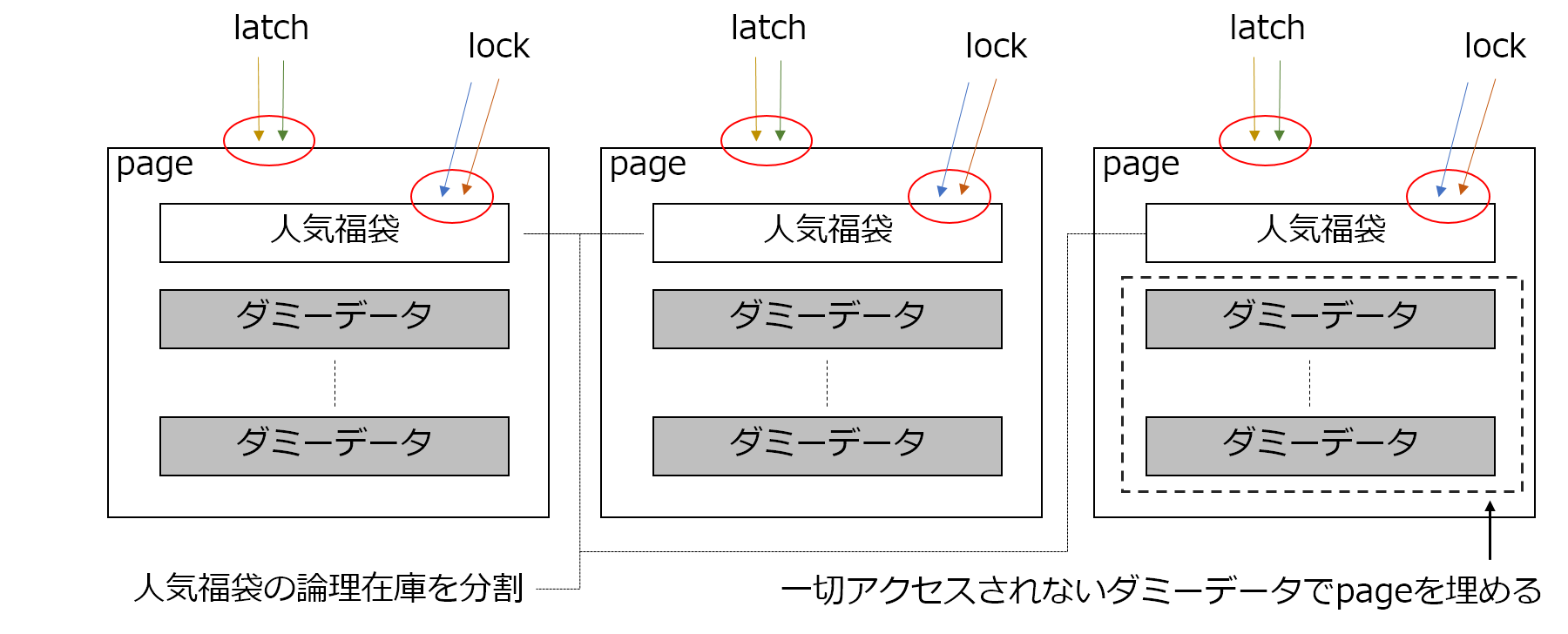
昨年の状況と比較すると、以下のように読み取り要求、更新要求に伴う排他制御の分散が期待できます。
当日のモニタリング環境の整備
昨年の障害時はワーカースレッドが枯渇していたため、クライアントソフトから情報収集のためのクエリを実行することすらできない時間帯がありました。そこで今回は、ワーカースレッドの枯渇に備えて、DACで事前に接続しておき、いかなる状況でもDBから情報を採取できる体制を整えておきました。DACで接続すると、専用のワーカースレッドをつかえるので、ワーカースレッド枯渇時でもクエリが実行できます。今年はワーカースレッドが枯渇することはありませんでしたが、準備しておいたことでいつでも情報取得できるという安心感につながりました。
今年の福袋イベントについて
本記事で紹介した負荷対策を実施したことで、今年は福袋イベントを障害無しで乗り切ることができました。
以下のグラフは、去年と今年の福袋イベントにおける、分間注文数の推移をグラフにしたものです。
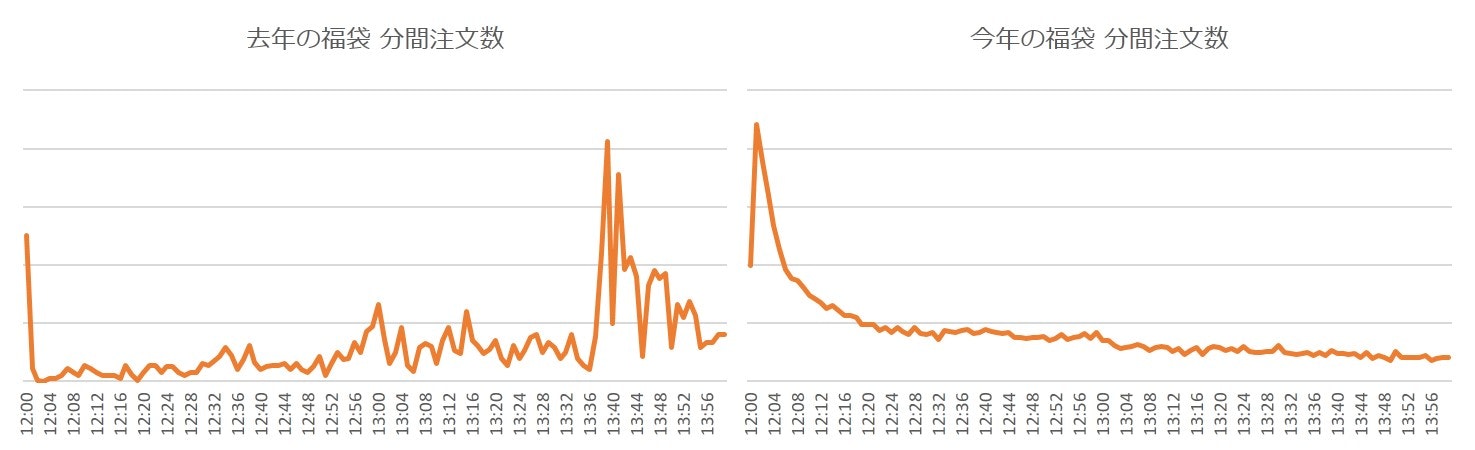
今年は、開始と同時に瞬間的に注文数が跳ね上がり、その後ゆるやかに減少しています。今年はほぼエラーが起きていないため、あるべき注文数の推移であり、お目当ての商品をスムーズに購入していただけたようです。昨年と今年の波形と比較すると、昨年は障害発生によって注文数の波形が不自然であることがよくわかります。
また、DB起因のエラーも、昨対比で99.99%以上削減でき、平常時とほぼ同じようなサーバー負荷状況でした。
まとめ
本記事では、昨年障害を発生させてしまった福袋イベントについて、障害原因に関する調査内容をご紹介しました。また、調査結果を踏まえて今年実施した負荷対策についても紹介しました。
人気商品にアクセスが集中するという特定の性質をもったワークロードにおいて、同時実行性能をできる限り向上させることに注力したことが功を奏しました。性質が異なれば実施すべき対応策も変わってくるため、ワークロードの性質を適切に把握することと、障害発生時はできる限り根本的な原因を特定することが、何よりも大切だなと感じました。
今年はお客様にストレスなく福袋イベントを楽しんでいただけたと思いますので、エンジニア一同がんばってよかったです!