背景
DMV(動的管理ビュー)はDBの各種調査で重宝します。
例えば、以下のクエリを実行することで「現在1秒以上実行中のクエリ」を取得することができます。
select top 100
getdate() as collect_date
,der.session_id as spid
,der.blocking_session_id as blk_spid
,datediff(s, der.start_time, getdate()) as elapsed_sec
,db_name(der.database_id) as db_name
,des.host_name
,des.program_name
,der.status
,dest.text as command_text
,replace(replace(replace(substring(dest.text, (der.statement_start_offset / 2) + 1, ((case der.statement_end_offset when - 1 then datalength(dest.text) else der.statement_end_offset end - der.statement_start_offset) / 2) + 1), char(13), ' '), char(10), ' '), char(9), ' ') as current_running_stmt
,datediff(s, der.start_time, getdate()) as time_sec
,wait_resource
,wait_type
,last_wait_type
,der.wait_time as wait_time_ms
,der.open_transaction_count
,der.command
,der.percent_complete
,der.cpu_time
,(case der.transaction_isolation_level when 0 then 'Unspecified' when 1 then 'ReadUncomitted' when 2 then 'ReadCommitted' when 3 then 'Repeatable' when 4 then 'Serializable' when 5 then 'Snapshot' else cast(der.transaction_isolation_level as varchar) end) as transaction_isolation_level
,der.granted_query_memory * 8 as granted_query_memory_kb
,der.reads
,der.writes
,der.logical_reads
,der.query_hash
,der.query_plan_hash
,des.login_time
,des.login_name
,des.last_request_start_time
,des.last_request_end_time
,des.cpu_time as session_cpu_time
,des.memory_usage
,des.total_scheduled_time
,des.total_elapsed_time
,des.reads as session_reads
,des.writes as session_writes
,des.logical_reads as session_logical_reads
from sys.dm_exec_requests der
join sys.dm_exec_sessions des on des.session_id = der.session_id
outer apply sys.dm_exec_sql_text(sql_handle) as dest
where des.is_user_process = 1
and datediff(s, der.start_time, getdate()) >= 1
and datediff(s, der.start_time, getdate()) < (3600 * 10)
option (maxdop 1)
ただし、あくまでリアルタイムでの情報取得となるため、障害等が発生して過去の情報を追いたいときに、「2020/06/29 22:00時点で1秒間実行中だったクエリ」を後追いすることはできません。
専用のテーブルを作成し、例えば1分間隔などで実行結果をダンプ(INSERT)しておけば、後から特定の日時のDBの状態を後追いすることができるようになり、各種調査が格段にしやすくなります。
- どのDMVをダンプしておけばいいか
- 取得した情報をどのように解析すればいいか
という2点について考えてクエリの作成まで実施したので紹介したいと思います。
クエリはgithubで公開しています。
クエリの解説
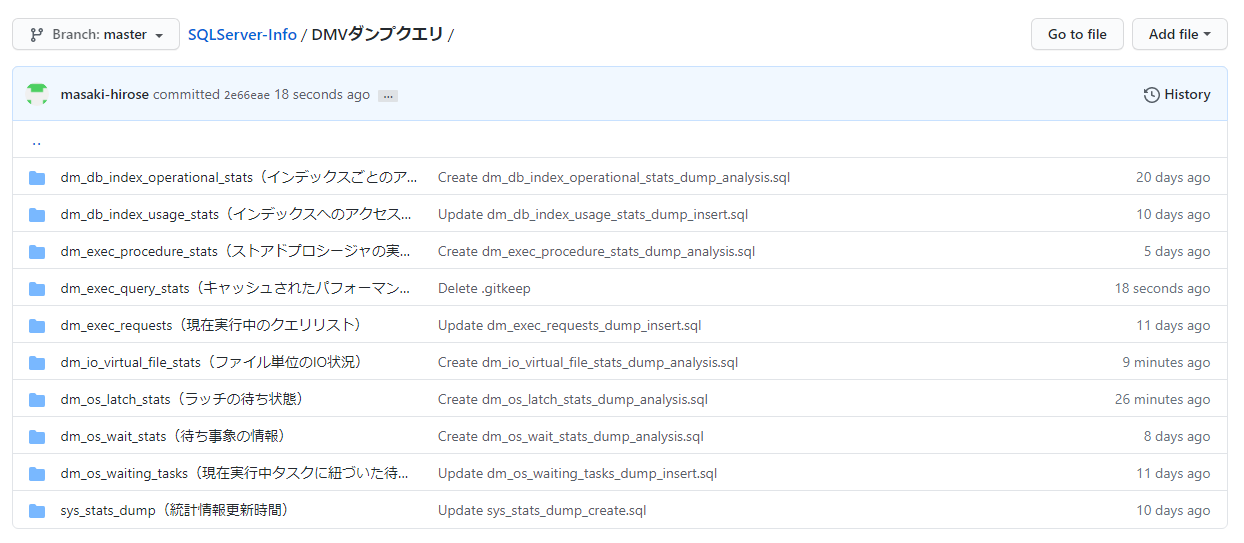
全部で10種類のDMVダンプクエリを作成しました。
dm_db_index_operational_stats(インデックスごとのアクセス状況)
dm_db_index_usage_stats(インデックスへのアクセス状況)
dm_exec_procedure_stats(ストアドプロシージャの実行統計)
dm_exec_query_stats(キャッシュされたパフォーマンス情報)
dm_exec_requests(現在実行中のクエリリスト)
dm_io_virtual_file_stats(ファイル単位のIO状況)
dm_os_latch_stats(ラッチの待ち状態)
dm_os_wait_stats(待ち事象の情報)
dm_os_waiting_tasks(現在実行中タスクに紐づいた待ち事象)
sys_stats_dump(統計情報更新時間)
各ディレクトリは以下のファイル構成となっています。
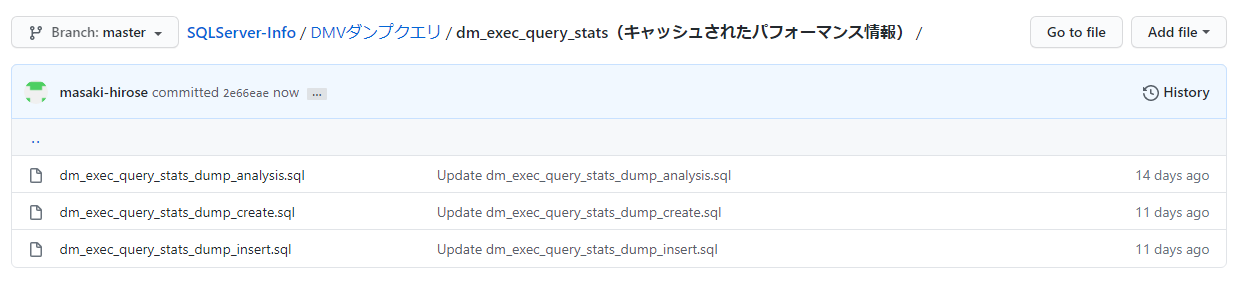
- ***_create.sql
- ダンプ用のテーブルを作成するクエリ。一度だけ実行すればOK
- ***_insert.sql
- ダンプ用テーブルにクエリ実行結果をINSERTしていくためのクエリ。1分間など定期的な間隔で実行しておけばOK
- ***_analysis.sql
- ダンプしたテーブルから、特定の時間帯の情報を取得するためのクエリ。
***_analysis.sqlについて
解析用のクエリは2パターンあります。
①特定の時間帯を指定することで、そのタイミングの情報が取得できるパターン
例えばsys.dm_exec_requestsのダンプでは、「そのタイミングで1秒以上実行中だったクエリ」を取得したいので、シンプルにWHERE句でcollect_date(取得日時)を指定すればOKです。
select * from dm_exec_requests_dump
where collect_date = '2020-06-29 17:54:11.027'
②2点間の日時を指定することで、その間に各カラムの数値がどれだけ変化したかを取得できるパターン
例えばsys.dm_os_wait_statsのダンプでは、各ダンプは「そのタイミングでの各待ち事象の累積値」しか分からないため、2つの日時の情報を取得し、それらの差分を出すことで、例えば「2020/06/29 12:00-12:05の5分間での待ち時間が多い待ち事象」などを取得することができます。
2点間の差分を出すため、クエリが多少複雑になります。
また、2点間の時間帯における、各カラム値の合計を100%としたときに、各値が全体の何%を占めるかまで算出するようにしているため、「2020/06/29 12:00-12:05の5分間では、LCK_M_Sが全体の9割の待ち時間を占めていた」といった、そのタイミングでインパクトのあった待ち時間を判断することも可能です。
declare @total_waiting_tasks_count bigint
declare @total_wait_time_ms bigint
declare @total_max_wait_time_ms bigint
declare @total_signal_wait_time_ms bigint
declare @snapshot_time_earlier datetime
declare @snapshot_time_later datetime
set @snapshot_time_earlier = '2020-06-21 23:50:10.970' --collect_dateに存在する日時を設定(古い方)
set @snapshot_time_later = '2020-06-22 00:15:11.023' --collect_dateに存在する日時を設定(新しい方)
select
@total_waiting_tasks_count = sum(waiting_tasks_count)
,@total_wait_time_ms = sum(wait_time_ms)
,@total_max_wait_time_ms = sum(max_wait_time_ms)
,@total_signal_wait_time_ms = sum(signal_wait_time_ms)
from
(
select
a.wait_type
,a.collect_date
,(a.waiting_tasks_count - b.waiting_tasks_count) as waiting_tasks_count
,(a.wait_time_ms - b.wait_time_ms) as wait_time_ms
,(a.max_wait_time_ms - b.max_wait_time_ms) as max_wait_time_ms
,(a.signal_wait_time_ms - b.signal_wait_time_ms) as signal_wait_time_ms
from
(
select * from
dm_os_wait_stats_dump
where collect_date = @snapshot_time_later
) as a
join
(
select * from
dm_os_wait_stats_dump
where collect_date = @snapshot_time_earlier
) as b
on a.wait_type = b.wait_type
where (a.waiting_tasks_count - b.waiting_tasks_count) > 1 --待ち頻度が少ないクエリを除外
) as c
select
*
,(100.0 * waiting_tasks_count / (1+@total_waiting_tasks_count)) as percent_waiting_tasks_count
,(100.0 * wait_time_ms / (1+@total_wait_time_ms)) as percent_wait_time_ms
,(100.0 * max_wait_time_ms / (1+@total_max_wait_time_ms)) as percent_max_wait_time_ms
,(100.0 * signal_wait_time_ms / (1+@total_signal_wait_time_ms)) as percent_signal_wait_time_ms
from
(
select
a.wait_type
,a.collect_date
,(a.waiting_tasks_count - b.waiting_tasks_count) as waiting_tasks_count
,(a.wait_time_ms - b.wait_time_ms) as wait_time_ms
,(a.max_wait_time_ms - b.max_wait_time_ms) as max_wait_time_ms
,(a.signal_wait_time_ms - b.signal_wait_time_ms) as signal_wait_time_ms
from
(
select * from
dm_os_wait_stats_dump
where collect_date = @snapshot_time_later
) as a
join
(
select * from
dm_os_wait_stats_dump
where collect_date = @snapshot_time_earlier
) as b
on a.wait_type = b.wait_type
where (a.waiting_tasks_count - b.waiting_tasks_count) > 1 --待ち頻度が少ないクエリを除外
) as c
order by wait_time_ms desc
まとめ
これまでの経験から、定期的にダンプしておくと後追いの際に便利なDMVについて10パターン列挙し、それぞれ
- ダンプ用テーブルの作成クエリ
- 定期的なINSERT用のクエリ
- 解析用のクエリ
という3点のクエリを作成し、githubで公開しました。
とても便利なので、是非お試しください。
監視製品を使っている場合でも、補完的に作用すると思います。