はじめに
Go言語で開発された有名な製品はDockerやKubernetesを筆頭に数多く存在します。アプリケーション開発としてもWebAPIのバックエンドやCLIツール開発で利用されることも増えていると感じます。IoTの文脈ではTinyGoなど組み込みプログラム領域でも進化を続けていて、WebAssembly(WASM)向けビルドと相まって今後さらなる拡張に期待を持っている人も多いかと思います。
一方で、大規模(1台のサーバに収まらない)データの分散処理分野では、Apache Spark(もちろんHadoop, YARN, etc.)とそのエコシステムが圧倒的に強いと感じます。AWS上であればSparkのマネージドサービスたるAWS Glueがありますし(EMRもありますが)、GCPだとDataprocでSpark(DataflowをApache Beamで扱うことが多そうですが)が広く使われていると思います。
Apache SparkはGoバインドのSDKはありますがαステータス1、Apache BeamもPySparkのようなGo SDK がありますが、experimental2でプロダクション利用は非推奨とのこと。そのため、Goで大規模データに対する分散処理を含んだアプリケーションのロジックを実装するのは既存のフレームワークでは厳しい状態だたと思います。私自身、少なくても日本でこの領域にGoで処理しているという話は聞いたことがないです3。この領域でのGoの存在感は意外なほど小さいです。
Bigslice

The Bigslice gopher design was inspired by Renee French.
Bigslice is a system for fast, large-scale, serverless data processing using Go.
(Bigsliceは、Goを利用した高速かつ大規模データ処理のためのサーバーレスな仕組みです。)
■Bigslice(公式)
https://bigslice.io/
そんな分散処理界隈ですが、Bigsliceというデータ処理フレームワークが存在します。サーバレスを謳っています。公式ドキュメントにもApache SparkやFlume Javaとの違いを触れていますが、カテゴリーとしては同様と扱って良いと思います。
Map, Filter, Reduce, Joinなどデータのコレクション操作のようなAPIを提供し、Bigslice側でクラウド上にアドホックなクラスタを作成し、透過的に分散処理を行ってくれるとのことです(スゴイ)。通常のGoパッケージと同じくBigsliceパッケージをimportして既存のGoコードと同じ用にコンパイルができるとのこと。これだけだとその凄さが分かるようであまり分からないので、早速使ってみましょう。
サンプルを実行(ローカル端末で実行)
まずは公式ドキュメントのGetting startedにかかれているサンプルコードです。この界隈だとよくある Word Count です。
package main
import (
// 省略
"github.com/grailbio/bigslice"
// 省略
)
var wordCount = bigslice.Func(func(url string) bigslice.Slice {
slice := bigslice.ScanReader(8, func() (io.ReadCloser, error) { // 入力読み込み。8はシャード数(分散数)
resp, err := http.Get(url)
if err != nil {
return nil, err
}
if resp.StatusCode != 200 {
return nil, fmt.Errorf("get %v: %v", url, resp.Status)
}
return resp.Body, nil
})
slice = bigslice.Flatmap(slice, strings.Fields) // 入れ子をフラットに変換
slice = bigslice.Map(slice, func(token string) (string, int) { // 1単語ごとに数値1と表現(変換)
return token, 1
})
slice = bigslice.Reduce(slice, func(a, e int) int { // 集計処理
return a + e
})
return slice
})
bigsliceパッケージを利用していることが分かると思いますが、ここに分散コレクション操作を実装していきます。最初の func(url string) bigslice.Slice に渡される 引数urlはmain関数から渡されます。
その内部の実装としては以下のようなイメージです。
- bigslice.ScanReaderで入力の読み込み。ここではURLのテキストを読み込み
- bigslice.FlatmapでSliceと呼ばれるbigsliceの分散データ表現に変換。ここでは文字列に変換
- bigslice.Mapで射影(変換処理)。ここでは入力トークンを、キーと数値1に変換
- bigslice.Reduceで集計。先程のトークンが同じ場合にReduceが呼ばれ、個々では単語ごとにカウントを合算
この wordCount をmain関数から呼び出します。シェークスピアのテキストファイル(5.2MBほど)をワードカウントしてみます。
package main
import (
// 省略
"github.com/grailbio/bigslice/sliceconfig"
)
const shakespeare = "https://ocw.mit.edu/ans7870/6/6.006/s08/lecturenotes/files/t8.shakespeare.txt"
type counted struct {
token string
count int
}
func main() {
sess := sliceconfig.Parse()
defer sess.Shutdown()
ctx := context.Background()
// 処理の開始
tokens, err := sess.Run(ctx, wordCount, shakespeare)
if err != nil {
log.Fatal(err)
}
// 結果読み込み
scanner := tokens.Scanner()
defer scanner.Close()
var (
token string
count int
counts []counted
)
for scanner.Scan(ctx, &token, &count) {
counts = append(counts, counted{token, count})
}
if err := scanner.Err(); err != nil {
log.Fatal(err)
}
// 出現数で降順ソート
sort.Slice(counts, func(i, j int) bool {
return counts[i].count > counts[j].count
})
// 上位10件を表示
for _, count := range counts {
fmt.Println(count.token, count.count)
}
}
実行してみます。
$ go run main.go
2020/11/28 14:32:34 http: serve :3333
the 23242
I 19540
and 18297
to 15623
of 15544
a 12532
my 10824
in 9576
you 9081
is 7851
無事ワードカウントができたようです。the, I, and, to, ofなどが出現数が多いようですね。
Windows環境だと下記エラーが出てしまい実行できないようなので、試すときはWSLなどで実行してみてください。
> go run main.go
# github.com/grailbio/base/status
..\..\..\..\pkg\mod\github.com\grailbio\base@v0.0.9\status\stream.go:112:23: undefined: syscall.SIGWINCH
..\..\..\..\pkg\mod\github.com\grailbio\base@v0.0.9\status\term.go:120:8: undefined: syscall.Termios
..\..\..\..\pkg\mod\github.com\grailbio\base@v0.0.9\status\term.go:121:31: not enough arguments in call to syscall.Syscall6
略
AWS環境で実行
透過的にといういうくらいなので、AWSのスポットインスタンスで上記のワードカウントを動かすことができるようです。なんとなくHadoopのMapReduceを思い出します(YARNコンテナではなく、EC2が起動するのはなかなか強いなと思いますね)
仕組みとしては、grailbio/bigmachineを利用しています。こちでEC2を起動しssh経由でEC2にバイナリを送りつける仕組みなようです。
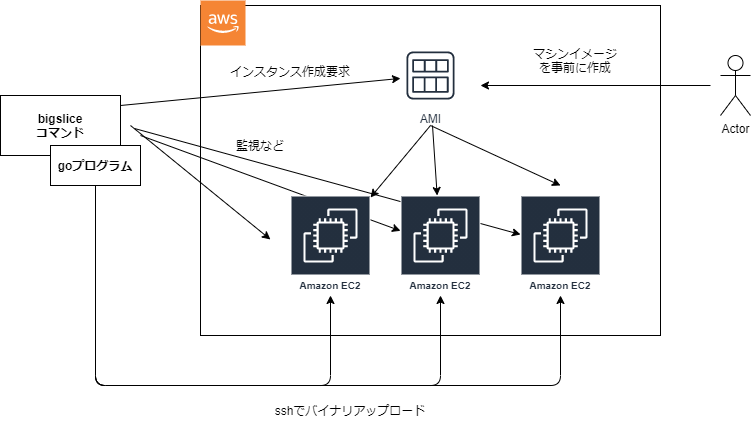
こうした背景から、事前に公開鍵で認証済みのAMIを作成したり、ssh(22)やHTTPS(443)のインバウンドを許可したセキュリティグループを作成しておいたり、ローカル端末で動かす場合はEC2インスタンスの起動権限を付与したIAMユーザを払い出す必要があります。
ちなみに、AWS上にSecurityGroup名はデフォルトで bigslice です。諸々準備を終えて以下のコマンドで動くとドキュメントに書いています。別記事でこのあたりの設定方法はまとめていきたいと思います。
ざっくり書くと、
①セキュリティグループ+EC2 AMIを作成(ここが長い)
②コマンドインストール($GOPATH/binをPATHに追加していない場合は忘れないように)
GO111MODULE=on go get github.com/grailbio/bigslice/cmd/bigslice@latest
③AWSキーを環境変数に載せる。bigsliceはProfileには非対応なようです
$ export AWS_ACCESS_KEY_ID=AKIAIOSFODNN7EXAMPLE
$ export AWS_SECRET_ACCESS_KEY=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
$ export AWS_REGION=ap-northeast-1
④セットアップコマンドを実行します。
$ bigslice setup-ec2
bigslice: found existing bigslice security group sg-0f061b686f38ab36b
bigslice: set up new security group sg-0f061b686f38ab36b
bigslice: wrote configuration to /home/mano/.bigslice/config
⑤ ~/.bigslice/conifg のAMI-IDを書き換え
$ head /home/mano/.bigslice/config
instance aws aws/env
param aws/env region = "ap-northeast-1" // the default AWS region for the session
param bigmachine/ec2system (
// 省略
ami = "ami-0f5253b670d69a556" // ★書き換えます
// 省略
⑥bigsliceコマンドの実行
GO111MODULE=on bigslice run main.go
2020/11/30 23:10:18 http: serve :3333
2020/11/30 23:10:18 slicemachine: 0 machines (0 procs); 1 machines pending (3 procs)
2020/11/30 23:10:18 slicemachine: 0 machines (0 procs); 2 machines pending (6 procs)
2020/11/30 23:10:18 slicemachine: 0 machines (0 procs); 3 machines pending (9 procs)
...
そうすると、下記のようにEC2がデフォルトで3台起動します。端末のbigsliceを殺すとEC2インスタンスが起動しっぱなしになるためご注意ください。

内部詳細
少しですが公式ドキュメントに記載がありました。
- Bigsliceのデータ表現について
- 並列処理(内部でDAGに変換され、CPU1コアを1Procリソースとして分割する記述
まとめ
EC2をオンデマンドに起動し、分散処理を行うBigsliceパッケージを紹介しました。
GCP、Azureなどには対応していなかったり、AWSでもEC2のみの対応のようですが非常に心くすぐられるパッケージです。
ドキュメントなどがまだ出揃っておらず、試行錯誤が必要ですが上手くハマれば非常に面白いプロダクトであると思います。
今後大規模データに対する分散処理の領域もGo言語でアプリケーションを書く機会が増えていけば良いなと思います。
-
2020/11/28現在、READMEを読む限り「2016-07-27: First very alpha version.」と書かれていたことから判断 ↩
-
2020/11/28現在、「The Go SDK is currently experimental, does not yet offer any compatibility guarantees and is not recommended for production usage. It supports most features, but not all.」とドキュメントに記載 ↩
-
少なくても日本では?。Apache KafkaやAWS Kinesis DataStream などメッセージングサービスを使った逐次処理で比重が傾いて、そもそもこういった需要が減ったからが理由な気がしないでもないです。 ↩