Azure のMachine Learningで無料で、ものすごく簡単にディープラーニングを体験できましたので、お勉強ついでに投稿しました。
チュートリアルを進めていくだけで体験できますが、それぞれのステップと簡単な解説もしてみました。
拙い英語力とディープラーニング初心者ですので、不足点があったらツッコミいただけると幸いです 笑。
そもそもディープラーニングって何?
簡単に言うと、データの中から特徴量や概念を見つけて、そのかたまりを使って、もっと大きなかたまりを見つけるとても優れた技術のようです。
2012年にGoogleがディープラーニングで猫を認識できるようになったと話題になりましたが、最近ではソフトバンクがPepperにディープラーニングを搭載して盛り上がりをみせてきているようで、とても興味深い技術ですね。
概要の理解にこちらのサイトや書籍が参考になりました。
ディープラーニングとは(ケータイWach)
人工知能は人間を超えるか ディープラーニングの先にあるもの (角川EPUB選書)
チュートリアルを使ってみる
それでは、早速体験してみようと思います。
今回は人口統計情報に基づいて所得水準を予測するチュートリアルのようです。
事前準備:
1.AzureのMachine Learninngの体験ページにアクセスします。
2.「今すぐご利用ください」をクリックして、「Guest Access」をクリックします。
Guest Accessだと8時間無料で使い続けることができるようです。
3.Would you like a tour of Azure ML?
Azureのツアーをご希望ですか?と聞かれているので、
「Take Tour」をクリックして、チュートリアルを開始します。
+New Experimentをクリックして、名前が入力されます。
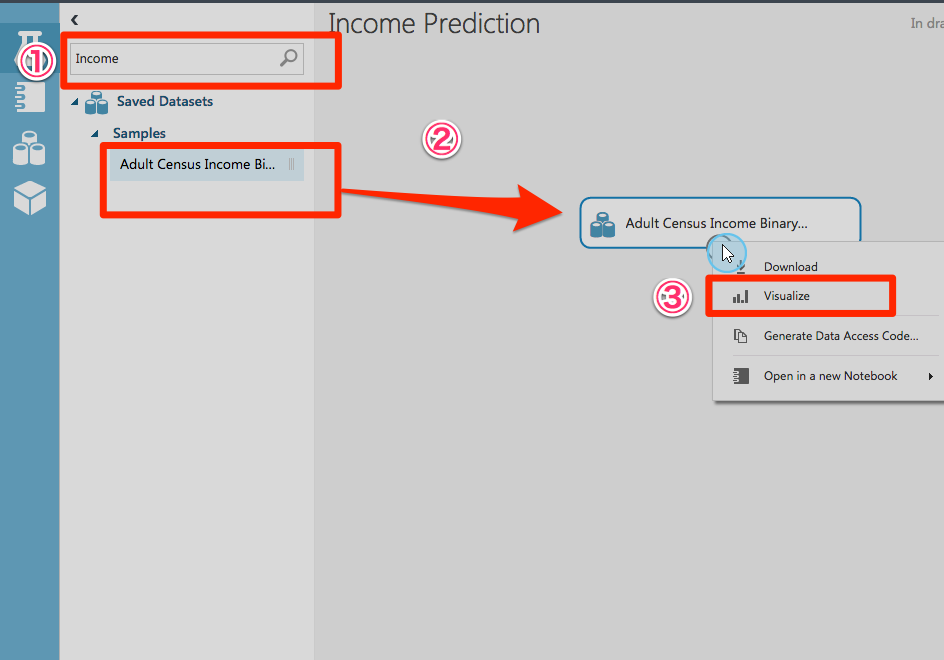
STEP1:Add a dataset from samples
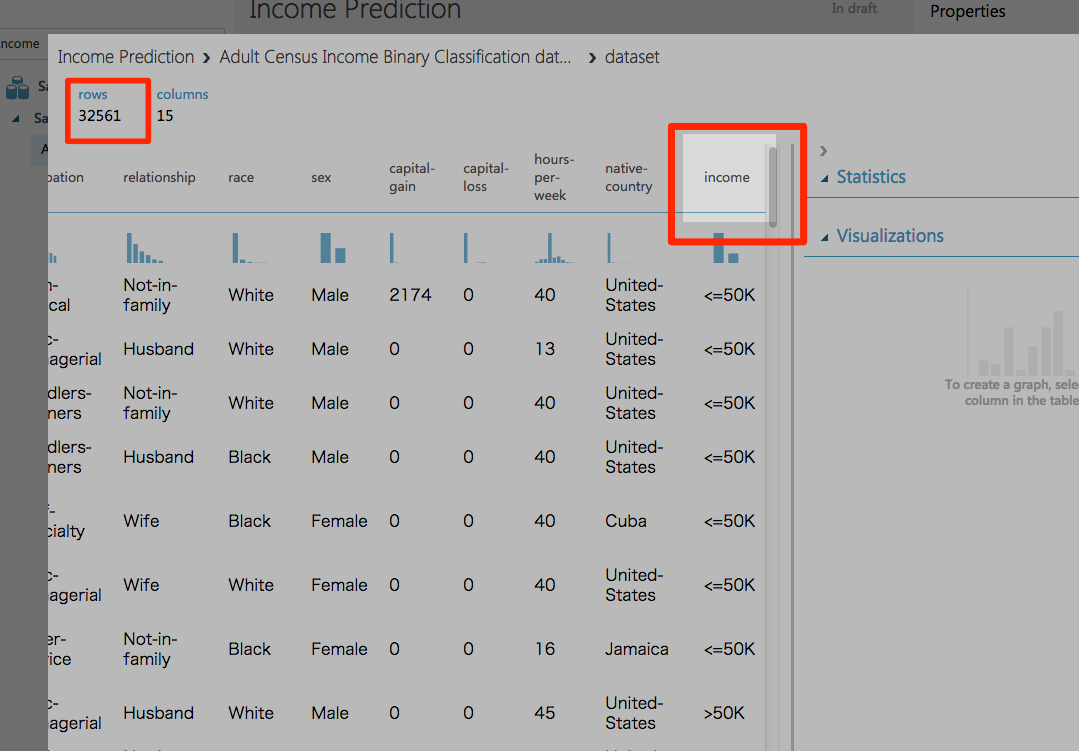
サンプルからデータセットを追加しています。
このサンプルのデータセットでは、約32,000人の人口調査や所得情報が含まれています。
STEP2:Split dataset
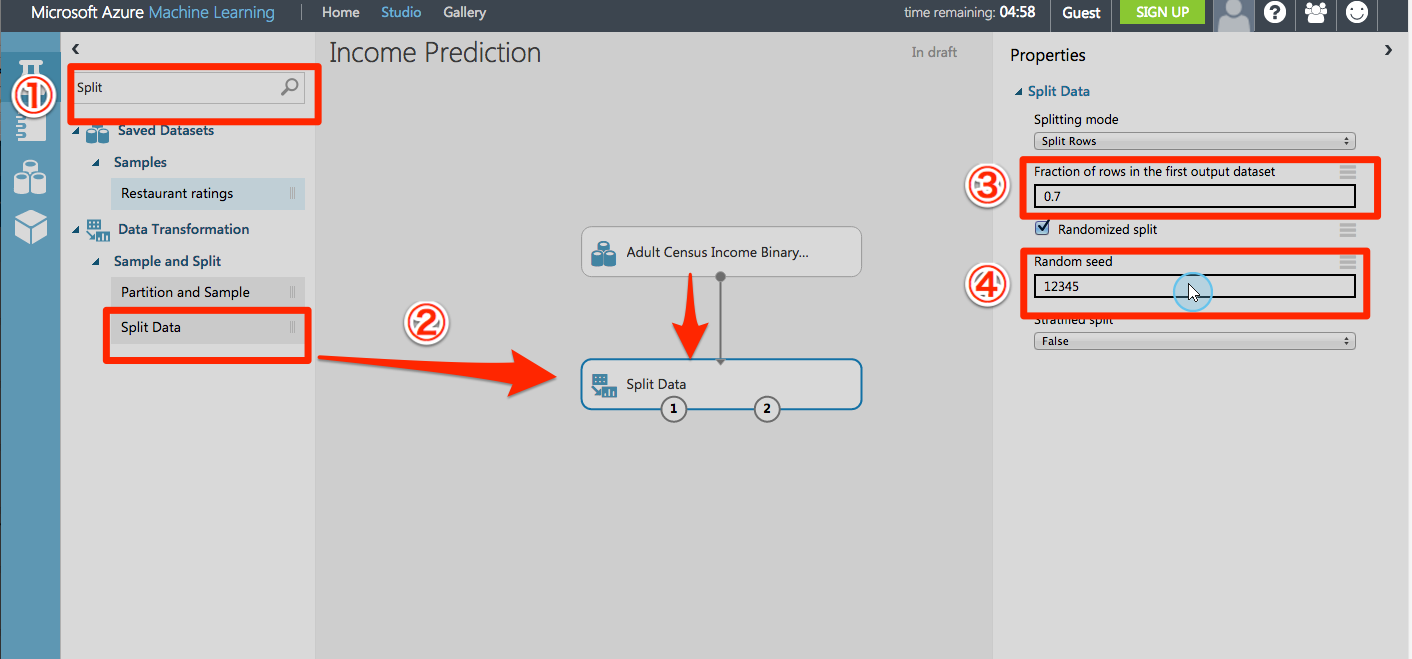
データセットを分割しています。
ランダムに訓練セット( 70 %)およびテストセット( 30 % )にデータセットを分割しています。
下記で訓練セット70%の指定と、乱数のシード値を指定しているようです。
シード値とはその値を基にして特定の演算により乱数を生成するそうで、同じシード値を使用した場合、発生する乱数(結果)はまったく同じものとなるそうです。
STEP3:Select an ML algorithm
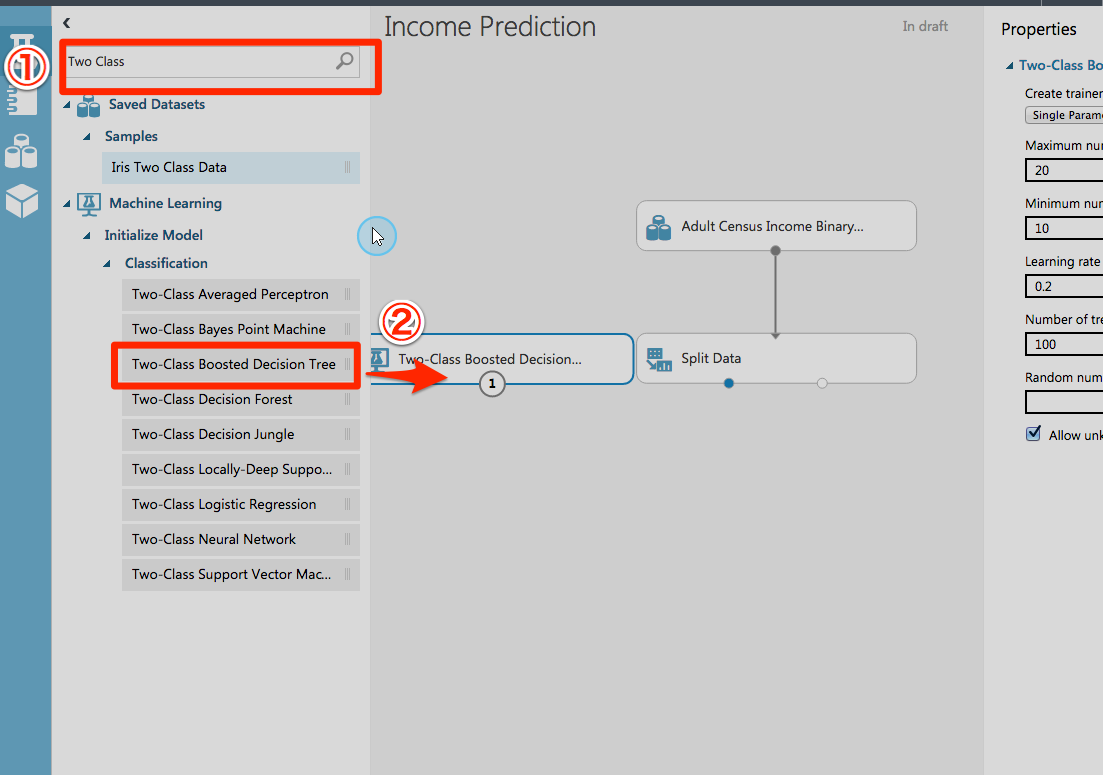
ディープラーニング実行のためのアルゴリズムを選択します。
アルゴリズムで二分木を選択し、STEP2で準備したデータセットで訓練しています。
「select a single model」で予測したいカラムを指定しています。
ここではincome(所得)を指定しています。
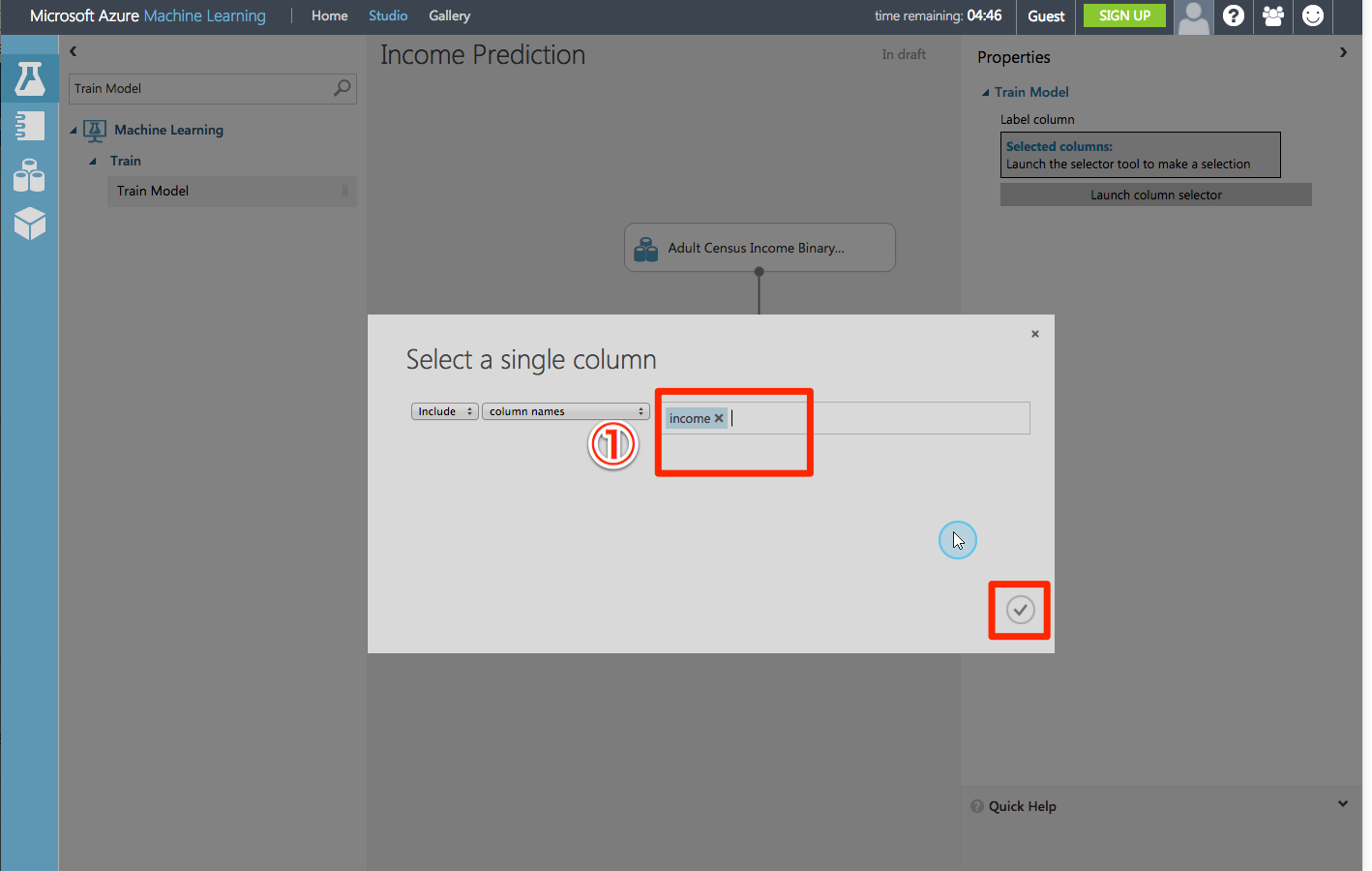
STEP4:Make predictions
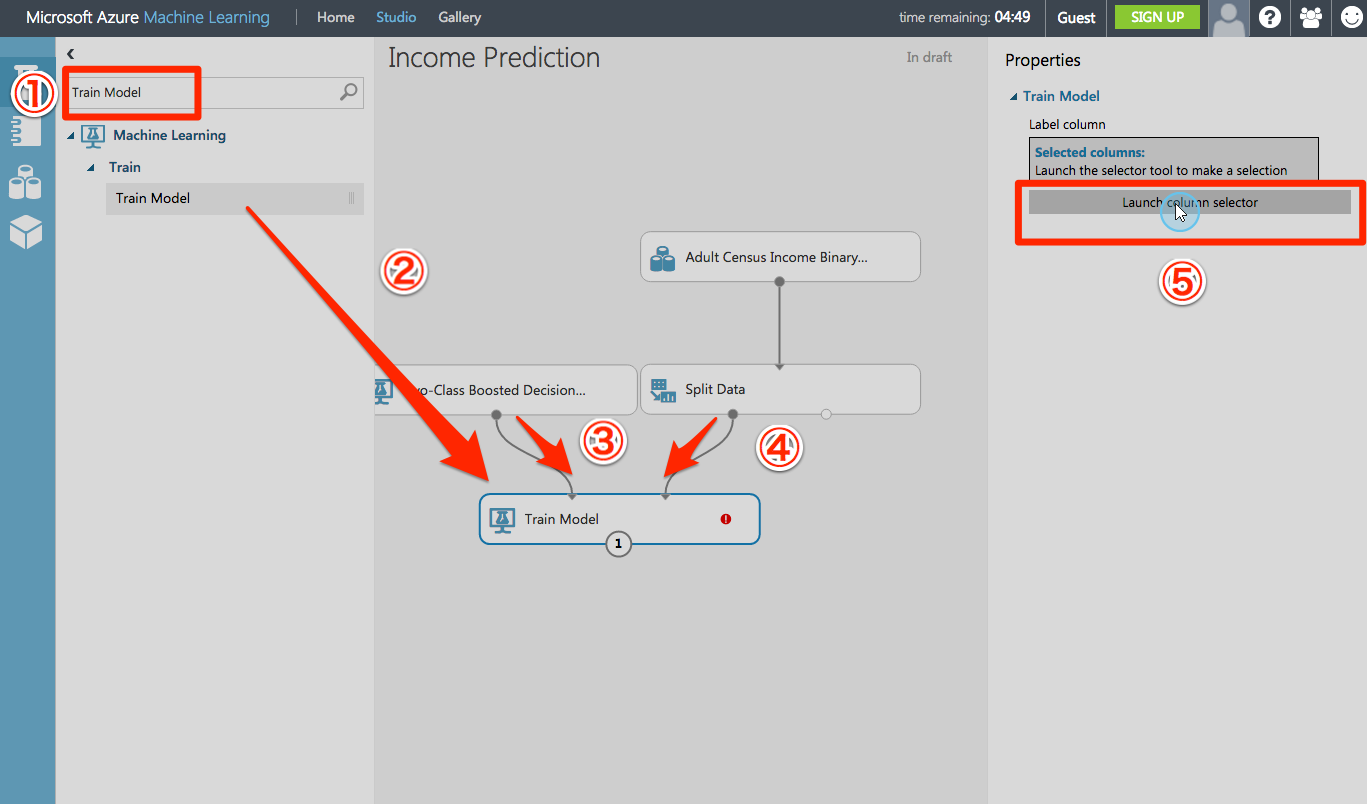
予測を行います。
テストデータセットを予測するためにSTEP3で訓練したモデル(Train Model)を使います。
Score Model・・・STEP2で訓練されたモデルを記録するモデルのようです。
Evaluate Model・・・標準的な測定基準を用いて評価するモデルのようです。
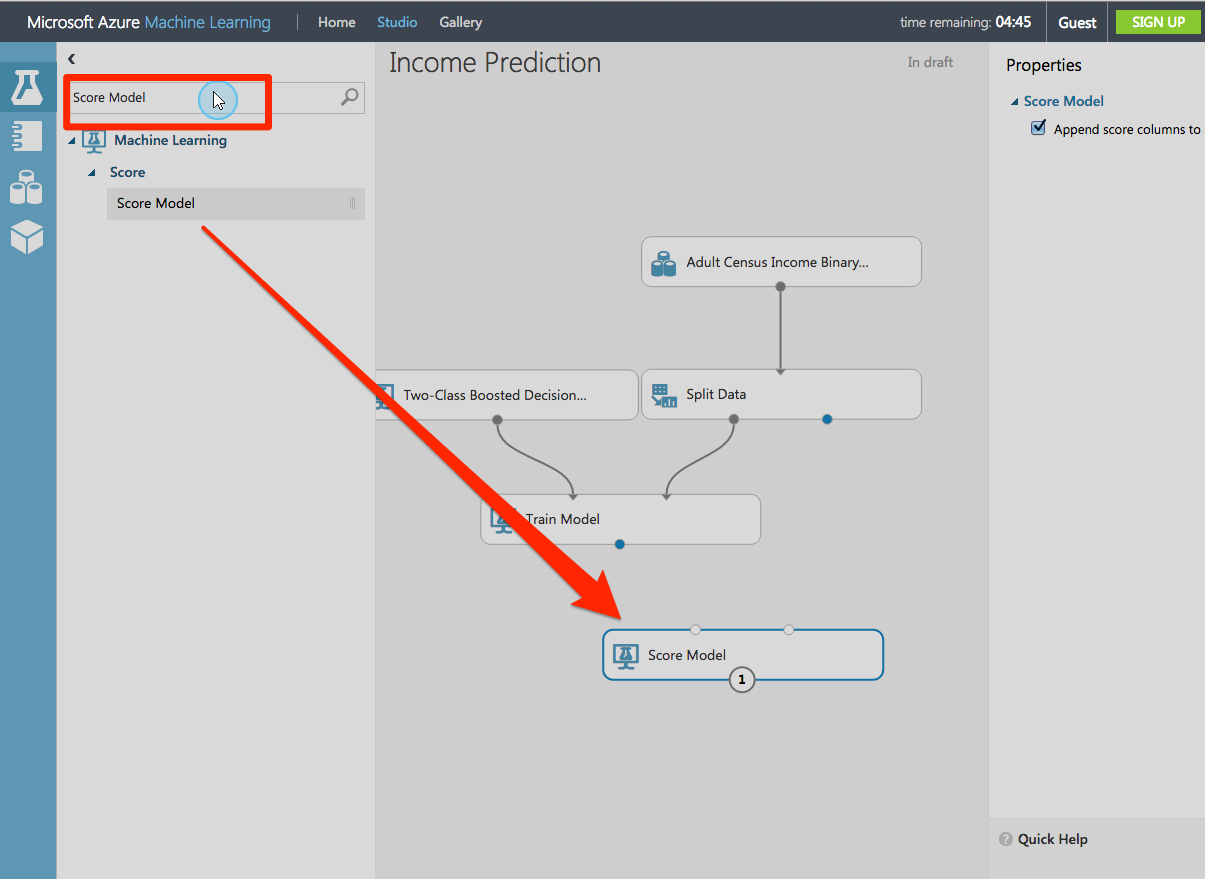
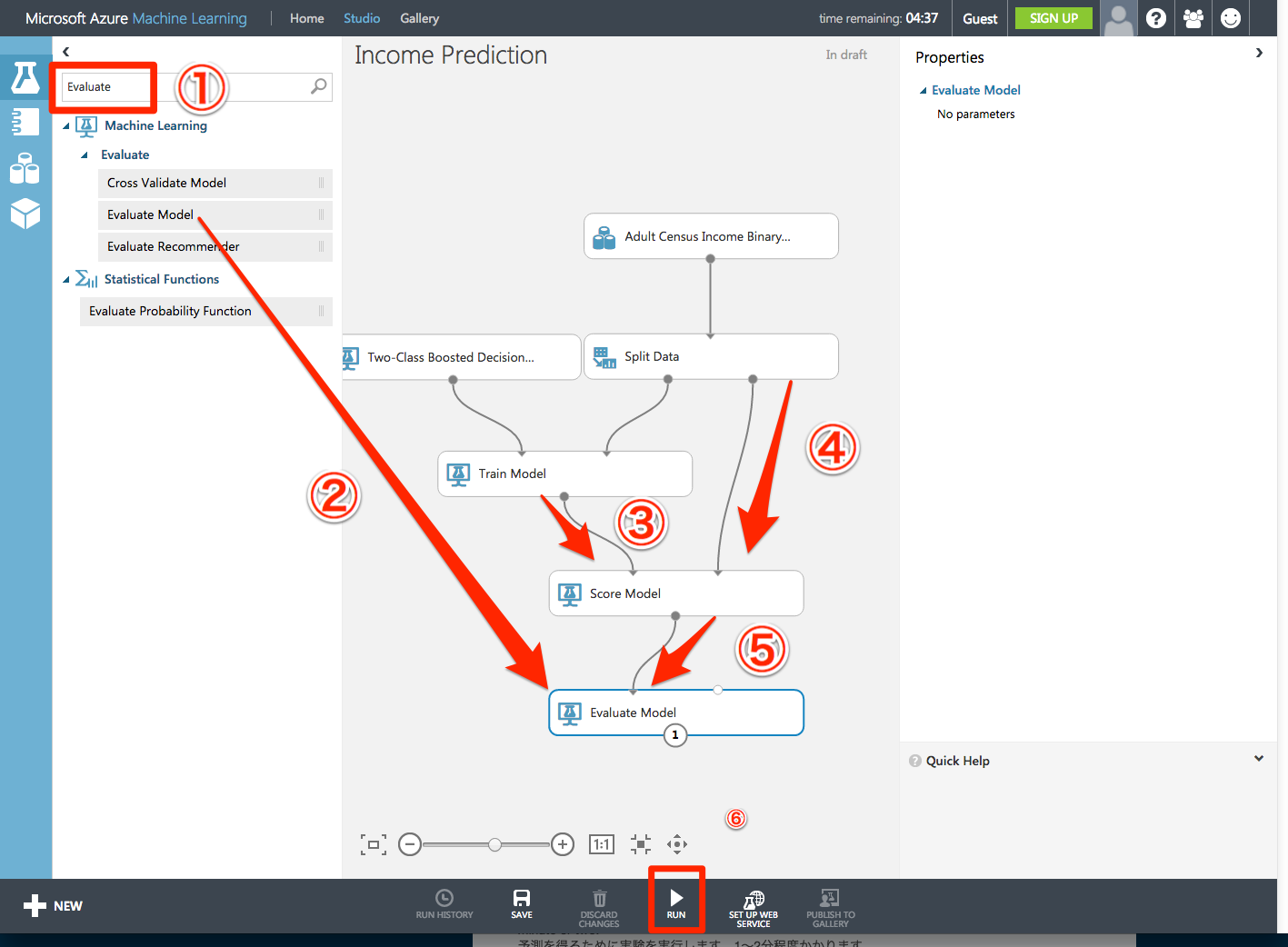
STEP5:Run the experiment
「Run」をクリックして実験を実行します。
1分以内で実行は完了して、機械学習モデルの構築に成功します。
Evaluation Results(評価結果)を開くと、
予測したデータに対して、1589件が正解で残りの532件は不正解。
「その他」と予測したデータに対して、6242件が正解で残りの696件は不正解であった事が分かります。
下記を確認すると、おおよそ70%ほどの正解率という状況のようです。
Accuracy:正確度
Precision:精度、適合率
Recall:再現率
F-Score:F値 (F-measure)
AUC:ROC曲線下面積(Area Under the Curve)

評価結果の見方は下記サイトが参考になりました。
機械学習の学習日記
という感じで、スイスイとディープラーニングを体験することができました。
ディープラーニングはAWSでは環境構築が大変そうに感じていたのですが、ここまで簡単にできると使い方次第で爆発的に普及しそうですね!
次回は画像認識にチャレンジしてみたいと思います。