はじめに
K6ってご存知ですか?
負荷試験ツールなのですが、JmeterやGatlingなどと比べ、軽量でJSで書けたりと、負荷試験がやりやすくなるので、使用したことない方はぜひ一度試してみてもらいたいです。
K6の紹介記事はそこそこあると思うので、今回は負荷試験時の整合性の取れた大量データを入れる時に役に立つことをお伝えできればと思います。
データ積みが面倒
負荷試験を実施するとき、個人的にはデータ準備が一番面倒なんですよね。。
ダミーデータで件数積む時は、SQLでパパッとできたりするのですが、たまに整合性の取れた、そこそこな量のデータを積まないといけないときがあるんですよね。
こういう時にK6使用するとデータ積むのが楽になります!
今回例として、以下のようなテーブルにデータを入れていきます。
実践編
貸出履歴と返却履歴テーブルに整合性の取れたデータを入れていきます。
book_id, user_idなどのマスタデータとの整合性も本来取るべきですが、省略します。
CREATE TABLE IF NOT EXISTS `loan_history` (
`loan_id` varchar(255) NOT NULL,
`book_id` varchar(255) NOT NULL,
`user_id` varchar(255) NOT NULL,
`loan_datetime` DATETIME DEFAULT CURRENT_TIMESTAMP,
`scheduled_return_datetime` DATETIME,
`created_at` DATETIME DEFAULT CURRENT_TIMESTAMP,
`updated_at` DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`loan_id`)
);
CREATE TABLE IF NOT EXISTS `return_history` (
`return_id` varchar(255) NOT NULL,
`book_id` varchar(255) NOT NULL,
`user_id` varchar(255) NOT NULL,
`loan_id` varchar(255) NOT NULL,
`return_datetime` DATETIME DEFAULT CURRENT_TIMESTAMP,
`created_at` DATETIME DEFAULT CURRENT_TIMESTAMP,
`updated_at` DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`return_id`)
);
これらのテーブルを使用して集計する機能の性能を見たい時、履歴テーブルなので、ユーザ数多いサービスだと数千万件や数億規模のデータが必要になると思います。
集計機能なので、整合性取れてないと性能見れないので、SQLで整合性取りながら、かつカーディナリティ意識するとなると大変だと思います。
ここでK6の出番です。
まず貸し出し履歴であるloan_historyにデータを入れていきます。
Jsonでリクエストを作ります。サンプルなので5パターンですが、件数多い場合は、GAS使用したり自動化してください。今回省略してますが、このようなテーブル構成だと本テーブルやユーザテーブルが存在します。先にそちらにデータを入れた後SQLでデータを取り出してJsonにフォーマットするのもおすすめです。
loan_data.json
[
{ "bookId": "20c22160-a72f-4b3b-9bf2-0d6832934e22", "userId": "usebc9e6634-89c6-4e93-b2c7-049a1e53cc71"},
{ "bookId": "20c22160-a72f-4b3b-9bf2-0d6832934e23", "userId": "usebc9e6634-89c6-4e93-b2c7-049a1e53cc72"},
{ "bookId": "20c22160-a72f-4b3b-9bf2-0d6832934e24", "userId": "usebc9e6634-89c6-4e93-b2c7-049a1e53cc73"},
{ "bookId": "20c22160-a72f-4b3b-9bf2-0d6832934e25", "userId": "usebc9e6634-89c6-4e93-b2c7-049a1e53cc74"},
{ "bookId": "20c22160-a72f-4b3b-9bf2-0d6832934e26", "userId": "usebc9e6634-89c6-4e93-b2c7-049a1e53cc75"}
]
K6のシナリオは以下のとおりです。
import http from 'k6/http';
// 外部ファイル 'loan_data.json' から配列データを読み込み
const data = new SharedArray('loan data', function () {
return JSON.parse(open('./loan_data.json'));
});
export default function () {
const url = 'http://localhost:8080/graphql'; // GraphQLエンドポイント
data.forEach(item => {
for (let i = 0; i < 10; i++) {
const payload = JSON.stringify({
query: `
mutation {
loan(bookId: "${item.bookId}", userId: "${item.userId}")
}
`,
});
// ヘッダー設定(JSON形式でリクエストを送る)
const params = {
headers: {
'Content-Type': 'application/json',
},
};
// POSTリクエストでGraphQLのMutationを送信
const res = http.post(url, payload, params);
// レスポンスのステータスコードが200であるかをチェック
check(res, {
'status was 200': (r) => r.status === 200,
});
}
});
}
簡単に説明すると、loan_data.jsonからリクエスト情報を1件ずつループして、10ループAPI叩いてます。
なので、今回だと5パターン×10ループで50件データを入れてます。
このようにJsonで定義するリクエストパターン数とループでデータを積んでいけます。
次に、返却履歴にデータを入れていきます。
このテーブルは貸し出し履歴と紐付けたいので、先ほど入れた貸し出し履歴から必要な情報をSQLで取得して、Jsonにします。
return_history_data.json(件数多いので一部のみ抜粋)
[
{
"bookId" : "20c22160-a72f-4b3b-9bf2-0d6832934e22",
"userId" : "usebc9e6634-89c6-4e93-b2c7-049a1e53cc71",
"loanId" : "027aa1da-2075-4907-8cc5-fc0d5bcd0101"
},
{
"bookId" : "20c22160-a72f-4b3b-9bf2-0d6832934e24",
"userId" : "usebc9e6634-89c6-4e93-b2c7-049a1e53cc73",
"loanId" : "033a992f-3dcf-4aa1-b527-d5a3c525786b"
}
・
・
・
]
K6のシナリオは以下の通りになります。
import http from 'k6/http';
// 外部ファイル 'return_history_data.json' から配列データを読み込み
const data = new SharedArray('return history data', function () {
return JSON.parse(open('./return_history_data.json'));
});
export default function () {
const url = 'http://localhost:8080/graphql'; // GraphQLエンドポイント
data.forEach(item => {
const payload = JSON.stringify({
query: `
mutation {
returnBook(bookId: "${item.bookId}", userId: "${item.userId}", loanId: "${item.loanId}")
}
`,
});
// ヘッダー設定(JSON形式でリクエストを送る)
const params = {
headers: {
'Content-Type': 'application/json',
},
};
// POSTリクエストでGraphQLのMutationを送信
const res = http.post(url, payload, params);
// レスポンスのステータスコードが200であるかをチェック
check(res, {
'status was 200': (r) => r.status === 200,
});
});
}
返却履歴は貸出履歴から取得したデータを元に作成しているので50件のデータが入っているはずです。
このように、Jsonを作るところを頑張れば比較的楽に整合性の取れた大量データ作れます!
結果
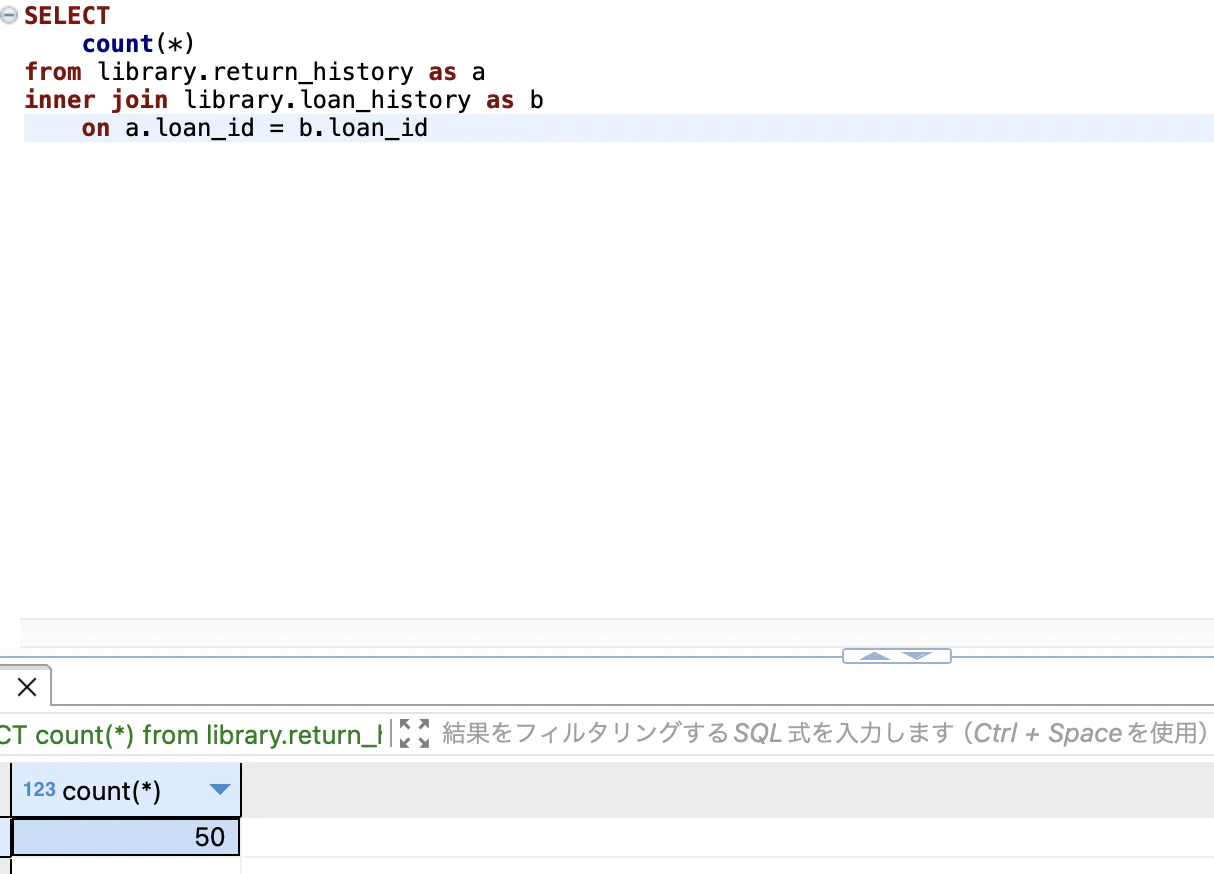
整合性の取れたデータが50件入っていることが確認できました。
注意点
・APIのレスポンスがそもそも遅い場合、データ積むのに時間がかかるので注意してください。
・K6はGo言語で作られているので、比較的軽量ですが、長時間動かす場合はCPUやメモリの使用量に注意してください。
・負荷かかりすぎるようでしたら、途中でスリープ入れるなど工夫が必要になる場合があります。
さいごに
今回紹介した方法でみなさんの作業が少しでも効率よくできればいいなと思ってます。
今回負荷試験での負荷の掛け方は紹介しませんでしたが、負荷試験でぜひK6を使用してみてもらいたいです。
Jmeterとかには戻れなくなるかもしれませんw