はじめに
- 育休中のエンジニアの私が、自宅でのウォームアップと勉強を兼ねてKaggleコンペに参加してみることにしたので、その記録を残したいと思う。
- 今回は、Kaggleの概略を知り、Begginer向けコンペへ参加することで、基本的な参加方法や使い方を理解することを目指す。
- Kaggleの概要~参加登録までの流れは、前回の「Kaggleコンペの参加チュートリアル(1.参加編)」参照。
「タイタニックの生存予測」モデル開発
- 前回、Beginner向けコンペである「タイタニックの生存予測」に参加し、データのダウンロードを行った。
- 今回は、ダウンロードしたデータの内容を確認し、データの前処理を行った後、実際にモデルの学習を行う。
モデル開発の流れ
- 基本的な流れは、以下の通り。
- ベースモデルの作成
- いきなり凝ったモデルを作ってしまうと、施した改良の良し悪しが判断できなくなってしまう。
- そのため、与えられた入力データに極力手を加えず、かつベーシックでシンプルな手法を使った「ベースモデル」を最初に開発する。
- 「ベースモデル」開発の流れは以下の通り。
- データの前処理
- データの全体像を確認し、入力データとして使える形に整形する。
- モデル選定
- 課題に即したベーシックなアプローチを選定する。
- モデル学習
- 1.と2.で実際に学習を行う。
- ここではあまり凝らずに、ある程度の精度が出れば良しとする。
- データの前処理
- 手法(ネットワーク構造)選定
- ここからモデル改良に入るが、基本は精度に、より大きく影響するものから順に着手する。
- まずは、問題設定にあったより高精度な最新の手法(DNNであればネットワーク構造)に変更してみる。
- Papers with codeでランキング上位の手法や、最近出た論文で良さそうなもののうち、コードが公開されている手法をチョイスすることが多い。
- 入力データの改良
- モデルのチューニング
- 最後に、モデルのパラメータチューニングを行う。
- 何パターンも学習する必要があり時間がかかること、また、手法や入力データを変更すると、モデルが変わるためやり直しになってしまうことから、最後に行うと良い。
- ランダム探索であたりをつけた後、ベイズ探索で細かくチューニングする。
- 優先順位としては
- ネットワークサイズ(ノード数、深さ)
- 学習率
- 正則化、ドロップアウト
- 活性化関数、ミニバッチ数、lrdecay 等
- ベースモデルの作成
ベースモデルの開発
- 今回はチュートリアルということで、ベースモデルを開発し、結果をコンペに投稿するところまでを行う。
データの前処理
-
まずはデータの前処理として、以下の手順を行う。
- データの全体像の確認
- train/testデータセットのデータ数
- 各データの内容(集計結果)
- 各データのデータ型
- 各データの欠損の有無 などを確認し、学習に使用するデータや、前処理が必要なデータを洗い出す。
- 未使用データの削除
- 入力データとして使用しないデータを削除する。
- 今回は、乗客ごとにユニークな値である、PassengerId/Name/Ticketと、欠損値が多すぎるCabinを削除する。
- 文字データ→数値データへの置換
- ニューラルネットワークでは、文字データを入力として扱えないため数値データに置換する。
- 今回は、Sex/Embarkedが文字データであり、このまま扱えないため数値データに置換する。
- 欠損データの挿入
- 非常に深い議論のある処理のようだが、ひとまずは簡単に中央値を使うこととする。
- 今回は、Ageに177、Embarkedに2の欠損があるので、各々を中央値で補う。
- データの全体像の確認
-
今回はpandasを使って上記の処理を行っていく。
1.データの全体像の確認サンプル
import pandas as pd
df = pd.read_csv("[filepath]\\train.csv")
pd.set_option('display.max_columns', 12)
// ひとまずデータをそのまま出力
df
> PassengerId Survived Pclass \
>0 1 0 3
>1 2 1 1
>2 3 1 3
>.. ... ... ...
>888 889 0 3
>889 890 1 1
>890 891 0 3
>
> Name Sex Age SibSp \
>0 Braund, Mr. Owen Harris male 22.0 1
>1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1
>2 Heikkinen, Miss. Laina female 26.0 0
>.. ... ... ... ...
>888 Johnston, Miss. Catherine Helen "Carrie" female NaN 1
>889 Behr, Mr. Karl Howell male 26.0 0
>890 Dooley, Mr. Patrick male 32.0 0
>
> Parch Ticket Fare Cabin Embarked
>0 0 A/5 21171 7.2500 NaN S
>1 0 PC 17599 71.2833 C85 C
>2 0 STON/O2. 3101282 7.9250 NaN S
>.. ... ... ... ... ...
>888 2 W./C. 6607 23.4500 NaN S
>889 0 111369 30.0000 C148 C
>890 0 370376 7.7500 NaN Q
>[891 rows x 12 columns]
// 各データ項目の分布を簡単に確認
df['Pclass'].value_counts()
>3 491
>1 216
>2 184
>Name: Pclass, dtype: int64
df['Survived'].value_counts()
>0 549
>1 342
>Name: Survived, dtype: int64
df['Pclass'].value_counts()
>3 491
>1 216
>2 184
>Name: Pclass, dtype: int64
df['Sex'].value_counts()
>male 577
>female 314
>Name: Sex, dtype: int64
df['SibSp'].value_counts()
>0 608
>1 209
>2 28
>4 18
>3 16
>8 7
>5 5
>Name: SibSp, dtype: int64
df['Parch'].value_counts()
>0 678
>1 118
>2 80
>5 5
>3 5
>4 4
>6 1
>Name: Parch, dtype: int64
df['Embarked'].value_counts()
>S 644
>C 168
>Q 77
>Name: Embarked, dtype: int64
// データ型の確認
df.dtypes
>PassengerId int64
>Survived int64
>Pclass int64
>Name object
>Sex object
>Age float64
>SibSp int64
>Parch int64
>Ticket object
>Fare float64
>Cabin object
>Embarked object
>dtype: object
// 欠損値を含むデータと、そのデータ数の確認
df.isnull().sum()
>Survived 0
>Pclass 0
>Sex 0
>Age 177
>SibSp 0
>Parch 0
>Fare 0
>Cabin 687
>Embarked 2
>dtype: int64
df.notnull().sum()
>Survived 891
>Pclass 891
>Sex 891
>Age 714
>SibSp 891
>Parch 891
>Fare 891
>Cabin 204
>Embarked 889
>dtype: int64
- 1.の確認で、以下のことが分かった。
- train/testデータセットのデータ数 → train 891/test 418
- 各データの内容 → 出力の通り
- 各データのデータ型 → Name/Sex/Ticket/Cabin/Enbarkedのデータがobject型(文字列)であり、数値への置換が必要
- 各データの欠損の有無 → Ageに177、Cabinに687、Embarkedに2のデータ欠損(NaN)がある
- これを踏まえ、2.~4.の処理を行っていく。
2.未使用データの削除サンプル
df = df.drop("PassengerId", axis=1)
df = df.drop("Name", axis=1)
df = df.drop("Ticket", axis=1)
df = df.drop("Cabin", axis=1)
df
> Survived Pclass Sex Age SibSp Parch Fare Embarked
>0 0 3 male 22.0 1 0 7.2500 S
>1 1 1 female 38.0 1 0 71.2833 C
>2 1 3 female 26.0 0 0 7.9250 S
>3 1 1 female 35.0 1 0 53.1000 S
>.. ... ... ... ... ... ... ... ...
>888 0 3 female NaN 1 2 23.4500 S
>889 1 1 male 26.0 0 0 30.0000 C
>890 0 3 male 32.0 0 0 7.7500 Q
>
>[891 rows x 8 columns]
- 2.では、推論にあまり寄与しなさそうなデータである、PassengerId/Name/Ticket/Cabinデータを削除した。
3.文字データ→数値データへの置換サンプル
df.groupby('Sex').size()
>Sex
>female 314
>male 577
>dtype: int64
df.groupby('Embarked').size()
>Embarked
>C 168
>Q 77
>S 644
>dtype: int64
df = df.replace({'Sex': {'male': 0, 'female': 1}})
df = df.replace({'Embarked': {'S': 0, 'C': 1, 'Q': 2}})
df
> Survived Pclass Sex Age SibSp Parch Fare Embarked
>0 0 3 0 22.0 1 0 7.2500 0.0
>1 1 1 1 38.0 1 0 71.2833 1.0
>2 1 3 1 26.0 0 0 7.9250 0.0
>.. ... ... ... ... ... ... ... ...
>888 0 3 1 NaN 1 2 23.4500 0.0
>889 1 1 0 26.0 0 0 30.0000 1.0
>890 0 3 0 32.0 0 0 7.7500 2.0
>
>[891 rows x 8 columns]
df.dtypes
>Survived int64
>Pclass int64
>Sex int64
>Age float64
>SibSp int64
>Parch int64
>Fare float64
>Embarked float64
- 3.では、文字データであるSex/Embarkedを、以下の通り数値データに置き換えた。
- Sex → male:0, female:1
- Embarked → C:0, Q:1, S:2
4.欠損データの挿入
df[{'Age','Embarked'}].median()
>Age 28.0
>Embarked 0.0
>dtype: float64
df = df.fillna({'Age': 28, 'Embarked': 0})
df.isnull().sum()
>Survived 0
>Pclass 0
>Sex 0
>Age 0
>SibSp 0
>Parch 0
>Fare 0
>Embarked 0
>dtype: int64
// 以下の1行でも中央値での補間が可能。同様に平均値mean()も指定できる。
// df = df.fillna(df.median())
df.to_csv('[前処理済学習データのファイル名].csv', index=False)
// その他、よく使いそうな処理の例
// 1つでもNaNを含むデータ列を削除する
// df = df.dropna(how='any')
// 特定のデータ列が’NaN’のデータ行を削除する
// df = df.dropna(subset=['Age'])
// 特定のデータ列がnullの行を抽出する
// df[df['Age'].isnull()]
// 特定のデータ列のNaNを前後の値で補間する。センサデータなどの連続データでは有効。
// df['Age'] = df['Age'].interpolate
// 他に行いたい処理があればリファレンスを確認すると良い。
// https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.dropna.html
- 4.では、Age/Embarkedの欠損値を中央値(28/0)で置換した。
- これでデータの前処理がやっと完了。
- 上記ではtrainデータのみ処理したが、testデータも同様の処理を行う。
モデル選定
- 個人的な事情だが、KaggleではファーストアプローチとしてメジャーなGDBTは、仕事で使う機会がなさそうなので習得に時間をかけたくない。
- そこで、今回はテーブルデータではあるが、ニューラルネットワークを使ったアプローチとする。
- 以下のようなベーシックな構成にした。
- 入力データ : 前項で前処理済のデータ8種
- 入力データの前処理 : 正規化のみ
- モデル : シンプルなMLP
- データ分割 : 学習データ4:評価データ1の5分割
モデル学習
- 学習コードは以下の通り。
- ローカルPCでも数分で学習できるが、今回はAmazon Sagemaker上のJupyter Labで実行した。
train.ipynb(学習コード)
%load_ext autoreload
%autoreload
import os
from datetime import datetime
import torch
from torch.utils.data import DataLoader
from src.dataset.dataset import DatasetWithTag, DatasetNoTag
from src.network.simplefcn import SimpleFCN
import torch.optim as optim
import torch.nn as nn
# config
TRAIN_FILE = "./data/train_prepro.csv"
LR = 0.001
EPOCH = 50
BATCH_SIZE = 8
INPUT_N = 7
OUTPUT_N = 2
NODE_N = 64
DATASPLITNUM = 4
VALDATANO = 3
if __name__ == '__main__':
# dataloader
dataset = DatasetWithTag(TRAIN_FILE, div=DATASPLITNUM, valno=VALDATANO)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=1)
# Network
net = SimpleFCN(INPUT_N, OUTPUT_N, NODE_N)
# Create Log Folder
foldertime = datetime.now().strftime("%Y%m%d_%H%M%S")
modeldir = './model/' + foldertime
os.mkdir(modeldir)
# Training
criterion = nn.CrossEntropyLoss() #sigmoid->log->softmax->NLLloss #nn.BCEWithLogitsLoss() #sigmoid->BCELoss
optimizer = optim.Adam(net.parameters(), lr=LR)
for epoch in range(EPOCH):
total_loss = 0
for i, (batch, y) in enumerate(dataloader):
optimizer.zero_grad()
output = net(batch)
#print(output.shape, y.shape)
loss = criterion(output, y.long())
loss.backward()
optimizer.step()
total_loss += loss.item()
result = torch.max(net(batch).data, 1)[1]
train_x, train_y = dataset.get_all_train()
val_x, val_y = dataset.get_all_val()
if epoch % 5 == 4:
# print log
result = torch.max(net(train_x).data, 1)[1]
acc_train = sum(train_y.data.numpy() == result.numpy()) / len(train_y.data.numpy())
loss_train = criterion(net(train_x), train_y.long())
result = torch.max(net(val_x).data, 1)[1]
acc_val = sum(val_y.data.numpy() == result.numpy()) / len(val_y.data.numpy())
loss_val = criterion(net(val_x), val_y.long())
print('epoch {:03d} , loss_train={:0.4f}, loss_val={:0.4f}, acc_train={:3.1f}%, acc_val={:3.1f}%'.format(epoch, loss_train, loss_val, acc_train*100, acc_val*100))
# save model
path = modeldir + '/{:03d}_losstrain_{:0.4f}_lossval_{:0.4f}.pth'.format(epoch, loss_train, loss_val)
torch.save(net.state_dict(), path)
print('save model to ' + path)
src/dataset/dataset.py(datasetクラス)
# for Dataset
import torch
from torch.utils.data import Dataset
import pandas as pd
import numpy as np
class DatasetWithTag(Dataset):
def __init__(self, filepath, div=4, valno=3, mixup=False):
super(DatasetWithTag, self).__init__()
# load data
data = pd.read_csv(filepath).values
data_x = data[:, 1:] #[data_n, 8]
data_y = data[:, 0] #[data_n]
data_y = data_y.reshape((data_y.shape[0]))
#train_y = np.eye(len(np.unique(train_y)))[train_y] #convert one-hot
# standardization
data_x, data_mean, data_std = self._z_score(data_x)
# split train/val
data_len = data_x.shape[0]
div_len = int(data_len / div)
train_x = data_x[np.r_[0:valno*div_len, (valno+1)*div_len:data_len]]
train_y = data_y[np.r_[0:valno*div_len, (valno+1)*div_len:data_len]]
val_x = data_x[valno*div_len : (valno+1)*div_len]
val_y = data_y[valno*div_len : (valno+1)*div_len]
self.train_x = torch.from_numpy(train_x).float()
self.train_y = torch.from_numpy(train_y)
self.val_x = torch.from_numpy(val_x).float()
self.val_y = torch.from_numpy(val_y)
self.data_mean = data_mean
self.data_std = data_std
self.mixup = mixup
def _z_score(self, x, axis=0):
x_mean = np.mean(x, axis=axis, keepdims=True)
x_std = np.std(x, axis=axis, keepdims=True)
return (x-x_mean)/x_std, x_mean, x_std
def get_all_val(self):
return self.val_x, self.val_y
def get_all_train(self):
return self.train_x, self.train_y
def get_mean_std(self):
return self.data_mean, self.data_std
def __len__(self):
return self.train_x.shape[0]
def __getitem__(self, idx):
if self.mixup:
lamda = np.random.rand()
search_idx2 = True
while search_idx2:
idx2 = np.random.randint(0, self.__len__())
if self.train_y[idx] == self.train_y[idx2]:
search_idx2 = False
x = lamda*self.train_x[idx] + (1 - lamda)*self.train_x[idx2]
y = self.train_y[idx]
else:
x = self.train_x[idx]
y = self.train_y[idx]
return x, y
class DatasetNoTag(Dataset):
def __init__(self, filepath, mean, std):
super(DatasetNoTag, self).__init__()
# load data
test = pd.read_csv(filepath).values
test_x = test[:, :] #[data_n, 8]
# standardization
test_x = (test_x - mean) / std
self.test_x = torch.from_numpy(test_x).float()
def __len__(self):
return self.test_x.shape[0]
def __getitem__(self, idx):
return self.test_x[idx]
src/network/simplefcn.py(ネットワーククラス)
# for Network
import torch.nn as nn
import torch.nn.functional as F
class SimpleFCN(nn.Module):
def __init__(self, inputn, outputn, noden=64):
super(SimpleFCN, self).__init__()
self.fc_in = nn.Linear(inputn, noden)
nn.init.kaiming_normal_(self.fc_in.weight)
self.bn_in = nn.BatchNorm1d(noden)
self.fc_middle1 = nn.Linear(noden, noden)
nn.init.kaiming_normal_(self.fc_middle1.weight)
self.bn_middle1 = nn.BatchNorm1d(noden)
self.fc_middle2 = nn.Linear(noden, noden)
nn.init.kaiming_normal_(self.fc_middle2.weight)
self.bn_middle2 = nn.BatchNorm1d(noden)
self.fc_middle3 = nn.Linear(noden, noden)
nn.init.kaiming_normal_(self.fc_middle3.weight)
self.bn_middle3 = nn.BatchNorm1d(noden)
self.fc_middle4 = nn.Linear(noden, noden)
nn.init.kaiming_normal_(self.fc_middle4.weight)
self.bn_middle4 = nn.BatchNorm1d(noden)
self.fc_middle5 = nn.Linear(noden, noden)
nn.init.kaiming_normal_(self.fc_middle5.weight)
self.bn_middle5 = nn.BatchNorm1d(noden)
self.fc_out = nn.Linear(noden, outputn)
nn.init.kaiming_normal_(self.fc_out.weight)
def forward(self, x):
x = F.relu(self.bn_in(self.fc_in(x)))
x = F.relu(self.bn_middle1(self.fc_middle1(x)))
x = F.relu(self.bn_middle2(self.fc_middle2(x)))
x = F.relu(self.bn_middle3(self.fc_middle3(x)))
x = F.relu(self.bn_middle4(self.fc_middle4(x)))
x = F.relu(self.bn_middle5(self.fc_middle5(x)))
x = self.fc_out(x)
return x
- 学習結果
epoch 004 , loss_train=0.4303, loss_val=0.4126, acc_train=81.5%, acc_val=80.2%
save model to ./model/20210618_063522/004_losstrain_0.4303_lossval_0.4126.pth
epoch 009 , loss_train=0.4188, loss_val=0.4052, acc_train=82.2%, acc_val=83.3%
save model to ./model/20210618_063522/009_losstrain_0.4188_lossval_0.4052.pth
epoch 014 , loss_train=0.4109, loss_val=0.3797, acc_train=82.5%, acc_val=85.6%
save model to ./model/20210618_063522/014_losstrain_0.4109_lossval_0.3797.pth
epoch 019 , loss_train=0.4061, loss_val=0.4041, acc_train=83.0%, acc_val=82.9%
save model to ./model/20210618_063522/019_losstrain_0.4061_lossval_0.4041.pth
epoch 024 , loss_train=0.4052, loss_val=0.3824, acc_train=82.7%, acc_val=85.6%
save model to ./model/20210618_063522/024_losstrain_0.4052_lossval_0.3824.pth
epoch 029 , loss_train=0.4027, loss_val=0.3593, acc_train=83.9%, acc_val=86.0%
save model to ./model/20210618_063522/029_losstrain_0.4027_lossval_0.3593.pth
epoch 034 , loss_train=0.4003, loss_val=0.3895, acc_train=83.0%, acc_val=83.3%
save model to ./model/20210618_063522/034_losstrain_0.4003_lossval_0.3895.pth
epoch 039 , loss_train=0.3917, loss_val=0.3835, acc_train=83.7%, acc_val=84.2%
save model to ./model/20210618_063522/039_losstrain_0.3917_lossval_0.3835.pth
epoch 044 , loss_train=0.3861, loss_val=0.3648, acc_train=83.4%, acc_val=83.8%
save model to ./model/20210618_063522/044_losstrain_0.3861_lossval_0.3648.pth
epoch 049 , loss_train=0.3914, loss_val=0.3814, acc_train=83.9%, acc_val=84.2%
save model to ./model/20210618_063522/049_losstrain_0.3914_lossval_0.3814.pth
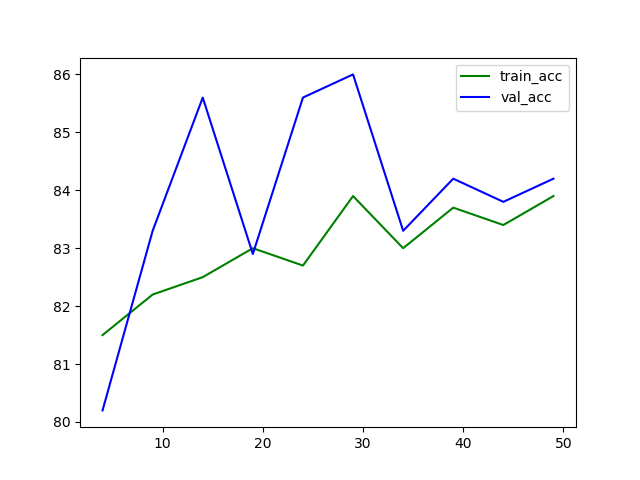
- データセットを先頭からシンプルに5分割した影響もあり、評価データのAccuracyが安定しない・・・
- ひとまず、50 epoch学習時点のモデルを採用する。
最後に
- 今回は、「タイタニックの生存予測」コンペのデータを使い、実際にモデルの学習を行った。
- 次回は「Kaggleコンペの参加チュートリアル(3.推論ファイル投稿編)」で、学習済モデルを使って投稿用の推論ファイルを作成し、コンペに投稿する。