はじめに
- とあるコンペに参加するため、Papers with codeでランキング上位の論文を調べていたら、「Transformer」がベースになっているようだった。
- 「Transformer」ってNLPで使うモデルじゃなかったっけ?言語処理扱わないから勉強してこなかったんだけど・・・もはや画像処理にも使われてるの!?
- ということで、論文や解説サイトを見ながら、概要を理解していくとともに、メモを残したい。
論文概要
- タイトル:Attention Is All You Need
- 著者 :Ashish Vaswani(Google Brain). et al.
- 発表 :2017, NeurlIPS
- タイトルがシンプルかつキャッチー。
Abstruct
- 再帰や畳み込み(RNNやCNN)を一切使わず、Attention機構のみを用いたシンプルなネットワークアーキテクチャ「Transformer」を提案。
- WMT2014の翻訳タスクで当時のSoTAを達成。並列化により学習時間が大幅に短縮可能であることもポイント。
Attention機構とは?
- 下図は自然言語処理のseq2seqモデルの例。
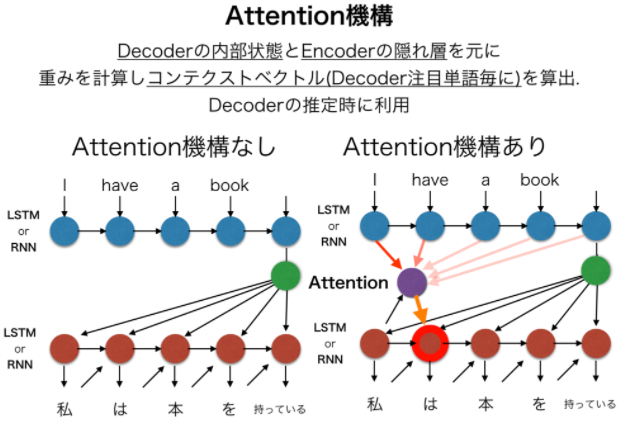
- 左図のベースとなるseq2seqモデルは、Encoder(青●)の時系列モデルが入力文字列を特徴ベクトルに変換し、最後の特徴ベクトルを入力として受け取ったDecoder(赤●)の時系列モデルが出力文字列を生成する仕組み。
- 右図のAttention機構を追加したモデルは、Encoder(青●)の各隠れ層の出力ベクトルを全て受け取り、それらに重みベクトルを乗算して重みづけをした「コンテキストベクトル」をDecoder(赤●)の推論に用いるのが特徴。
- Attentnion機構の概要説明は以下。

- キーアイデアを整理すると、
- Encoderの全隠れ層ベクトルをDecoderの入力に用いること
- それらに重みベクトルを乗算して重み付けをした「コンテキストベクトル」を生成すること
- 「コンテキストベクトル」と、Decoderの1つ前の内部状態を用いて、次のDecoderの内部状態を求めること と考える。
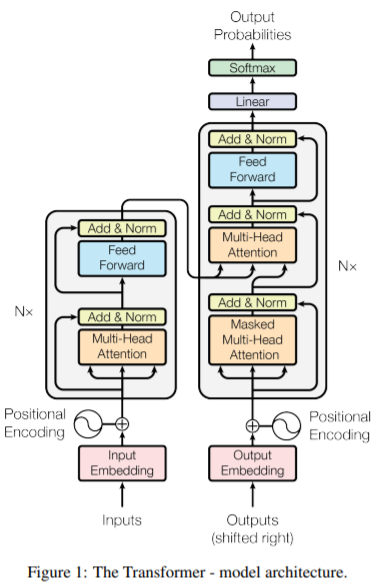
「Transformer」のモデルアーキテクチャ
-
Encoder
- 以下の2つのサブレイヤからなるレイヤをN=6個ストックした構造。
- マルチヘッド()のSelf-Attention
- 全結合のFeed Forward
- 各サブレイヤの後に、以下の2つの手法を適用。
- residual connection(ResNetで登場した手法。これを実装するため、各サブレイヤは出力をd=512に固定。)
- layer Normalization(Batch Normとは反対に、1つの入力データにおける、各レイヤーの隠れ層の値の平均・分散で正規化する手法)
- 以下の2つのサブレイヤからなるレイヤをN=6個ストックした構造。
-
Decoder
- Encoderと同じ2つのサブレイヤに、Encoderからの出力を加えてSelf-Attentionを行うサブレイヤを追加。
- この3つのサブレイヤをN=6個ストックした構造。
- 「Masked」の部分では、未来の出力(未知のはずのもの)を使わないようMaskするよう注意。
-
Attention機構
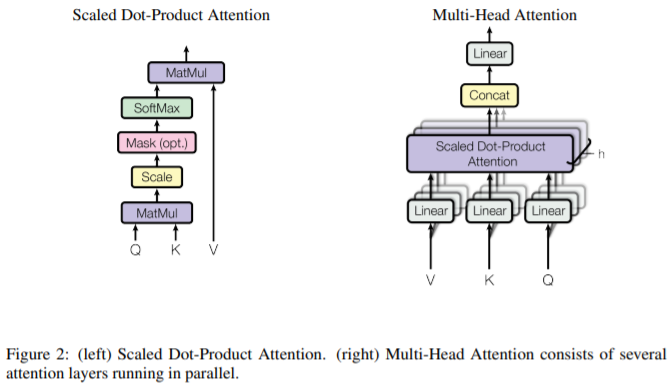
- Scaled Dot-Product Attention
- QueryとKey(いずれもdk次元のベクトル)-Value(dv次元のベクトル)の値のセットを、出力にマッピングする機構。
- Q,K,Vは、1段目では入力単語Embedding Xに、重み WQ,WK,WVを掛け合わせたものが入力される。
- 全てのQueryとKeyの内積を取り(MatMul)、1/√dkでスケーリングした後、Softmaxを取り、Valueの重み付けを求める。
- 高速なdot-product attentionを用いつつ、dkが大きい場合に精度が落ちる問題に対応するため、スケーリングを追加している。
- Multi-Head Attention
- Query, Key, Valueを線形変換(全結合層?)したものを複数用意し、並列して学習させると有益であることが分かった。
- h=8層のAttantion Layerと、dk = dv = dmodel/h = 64を使用。
- Scaled Dot-Product Attention
-
Position-wise Feed-Forward Networks
- input/outputがd=512、ノード数2048、線形変換2つの間に活性化関数ReLUを含む構造。
-
Positional Encoding
- 再帰や畳み込みのないネットワーク構造であるため、モデルがシーケンスの順序情報を利用できるように情報を含めてやる必要がある。
- 多くの選択肢があるが、ここでは単純にsin/cos関数を使用。
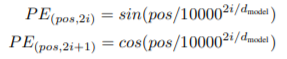
実験と結果
- 割愛するが、翻訳問題で当時のSoTAを記録するとともに、学習時間を1/4に削減するなど大幅な高速化に成功。
- これまでのRNN/CNNを用いた手法では、文章量に応じて計算量が増大していたが、本手法では、計算量を文章の長さに応じず定数時間O(1)に収めることができた、など非常に実用的な手法であることが示されている。
- さらに、論文内では自然言語処理のみに適用されているが、動画・画像処理などの多くの分野に応用できる可能性が示されており、応用範囲の広い画期的なアイデアであることが分かる。
参考にさせていただいた文献たち
- @omiitaさん, とても分かり易くTransformerをまとめられているQiita
- 元論文 Vaswani, A. et al.(2017) Attention Is All You Need
- Attention機構の解説
- Ryobotさん, 技術的な経緯や背景を含めて分かり易くTransformerを解説されているはてなブログ