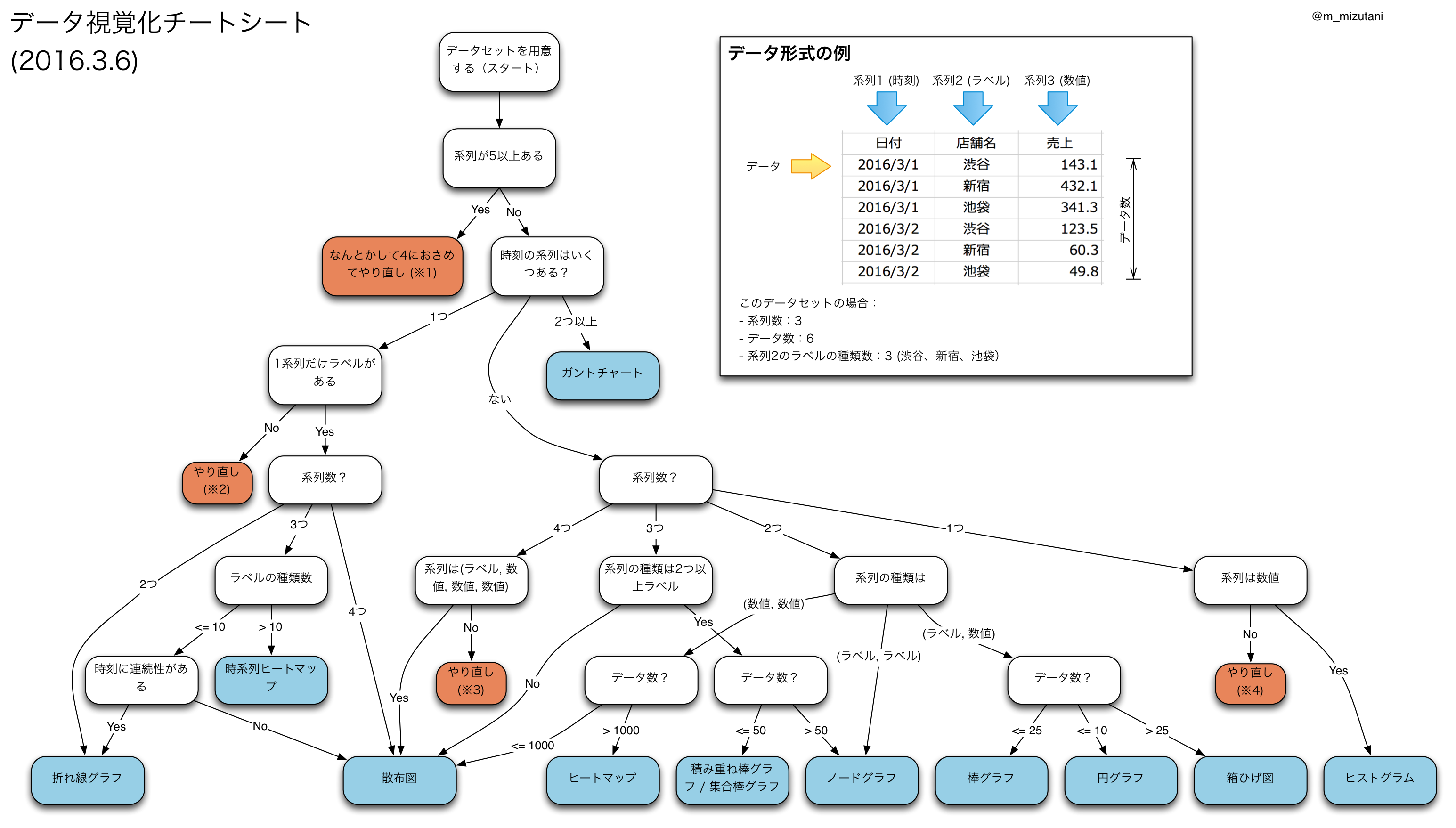
はじめに
データ可視化では、データの性質によって概ねどのような可視化ができるのか決まる場合があります。データ可視化は探索的なデータ分析をする場合や、データ分析した結果を誰かに伝えるために重要であり、その時々の目的に合わせた可視化を選択するべきですが、そもそも可視化手法の特性とデータの性質があっていないとあまり効果がない場合があります。筆者が業務においてデータ可視化する際にデータの性質から可視化手法を導く場合の道のりを整理し、チートシートとしてまとめてみました。
もちろん、調べたい・表現したい内容によって自分で自由に選んでもまったく問題無いですが、データを前にして「どうやって可視化しよう?」と悩んでいる方の一助になれば幸いです。
また、この記事では主に一般的な可視化(グラフ)手法にフォーカスしており、イラスト的な要素を含むインフォグラフィックなどについては触れていません。(が、だいたいのデータは一般的なグラフで十分表現ができると筆者は考えています)
データの性質について
図中に示している通り、データセットの各カラムを系列、一つの行をデータ、データセットに出現するデータ総数をデータ数と呼んでいます。各系列の種類については以下のように分類しています。
- ラベル:文字などで表現される要素です。尺度水準で言うとおおむね名義尺度と順序尺度がラベルになります。
- 数値:そのまま数値です。主に間隔尺度や比例尺度のものを指します。
- 時刻:本来は間隔尺度や比例尺度としてあつかわれますが、可視化の性質上、絶対時間(N秒、などではなくY年M月D日のようなもの)を日付・時間をひっくるめて時刻とします。
グラフの選び方
図中の質問にこたえることで、データの性質にあった可視化(グラフの種類)を選ぶことができます。
各グラフについて
ガントチャート
 出典: [dhtmlxGantt 2.0: Interactive JavaScript Gantt Chart](http://www.dhtmlx.com/blog/dhtmlxgantt-2-0-interactive-javascript-gantt-chart/)
出典: [dhtmlxGantt 2.0: Interactive JavaScript Gantt Chart](http://www.dhtmlx.com/blog/dhtmlxgantt-2-0-interactive-javascript-gantt-chart/)
主な対応データ形式:(時刻, 時刻, ラベル)
本来はプロジェクトの進捗管理の状況を管理するための可視化手法で、一般的には可視化にはあまり使われない印象。時刻を複数持つデータを表すには適しているが、系列数やラベルの種類数ではなくデータ数に応じてグラフのサイズが大きくなってしまうため、あまり多くのデータを表現できないのが弱点。
折れ線グラフ
 出典: [Multi-Series Line Chart](http://bl.ocks.org/mbostock/3884955)
出典: [Multi-Series Line Chart](http://bl.ocks.org/mbostock/3884955)
主な対応データ形式:(時刻, ラベル, 数値)
いわゆる普通の折れ線グラフ。連続した数値の変化を表す定番グラフ。ただしラベルの種類数が10を超えたあたりから線が重なるなどで見づらくなってしまう。できればラベルの種類数5以下が望ましい。もしより多くのラベルの種類数をグラフ化したいなら複数のグラフにわけたほうが無難。
時系列ヒートマップ
 出典: [日本IBM 2015年下半期 Tokyo SOC 情報分析レポート 図31](https://www-304.ibm.com/connections/blogs/tokyo-soc/entry/tokyo_soc_report2015_h2?lang=ja)
出典: [日本IBM 2015年下半期 Tokyo SOC 情報分析レポート 図31](https://www-304.ibm.com/connections/blogs/tokyo-soc/entry/tokyo_soc_report2015_h2?lang=ja)
主な対応データ形式:(時刻, ラベル, 数値)
折れ線グラフで表現しきれないほどのラベルの種類数があった場合でも数値の時間推移を表現できる。色の濃さや色温度で各時間帯の数値の大小を表現する場合が多い。円などの記号に置き換えて記号の大小で表現することもえきる。紙面でもラベルの種類数が100ぐらい、ページスクロールができるなら数百の種類数を表現できる。ただし、色や大きさだと繊細な数値の大小比較が難しいという点に注意しなければならない。
散布図
 出典: [Scatterplot](http://bl.ocks.org/mbostock/3887118)
出典: [Scatterplot](http://bl.ocks.org/mbostock/3887118)
主な対応データ形式:(時刻 or 数値, 数値, ラベル), (時刻 or 数値, 数値, 数値, ラベル)
2つの数値(時刻含む)を座標としてとらえたときのデータの偏りを調べる手法。1つの系列が時刻の場合はX軸を時刻にわりあてる場合が多い。2つ以上数値がある場合はX軸、Y軸をそれぞれ座標にとって、3つ目の数値がある場合は各点の大きさで大小を表現することができる。ただし、見る人が対象となるラベルをじっとみて見つけなければならないため、折れ線グラフや時系列ヒートマップのように時間的な数値の増減を表現するのは苦手。あくまで「どこに偏りがあるか?」を見るのに使う。また、極端にデータが重なったときに、どれくらい重なりがあるかが分からないので、データ数が多くなった時にはヒートマップの方が適している場合もある。
ヒートマップ
 出典: [2D random terrain: iterative diamond-square algorithm](https://joecrossdevelopment.wordpress.com/2012/04/30/2d-random-terrain-iterative-diamond-square-algorithm/)
出典: [2D random terrain: iterative diamond-square algorithm](https://joecrossdevelopment.wordpress.com/2012/04/30/2d-random-terrain-iterative-diamond-square-algorithm/)
主な対応データ形式:(数値, 数値, 数値)
数値2つを座標として、3つ目の数値をその座標の色を決定するために使うことで、全体の数値のバラつきや、高い・低い値の集中しているエリアを知ることができる。数値の代わりに時刻にすることもできなくはないが、あまりそういうグラフは見たことがない。
あと、座標の代わりに住所情報を用いて国ごと、県ごと、州ごとに色を設定し数値の高い、低いを表現する場合もある。この場合は(ラベル=住所, 数値) というデータ形式になるのだが、若干特殊なケースなのでチートシートからは省いた。
 出典: [US State Map](http://bl.ocks.org/NPashaP/a74faf20b492ad377312)
出典: [US State Map](http://bl.ocks.org/NPashaP/a74faf20b492ad377312)
積み重ね棒グラフ / 集合棒グラフ
 出典: [Grouped Bar Chart](http://bl.ocks.org/mbostock/3887051)
出典: [Grouped Bar Chart](http://bl.ocks.org/mbostock/3887051)
主な対応データ形式:(ラベル, ラベル, 数値)
2つのラベルと1つの数値があったときに、これらの数値の大小を比較する方法。2つ以上のラベルをうまく表現できる数少ない方法だと思うが、データ数(≒2つのラベルの組み合わせ数)が50を超えたぐらいから図が煩雑になって読み取りが難しくなってしまう。また、図のような集合棒グラフと、ひとつの棒に要素を積み重ねていく積み重ね棒グラフを両方同時に使うことも可能ではあるが、これもまた読み取りが難しい図ができあがりがちなので、あまりお勧めできない。
ノードグラフ
 出典: [Labeled Force Layout](http://bl.ocks.org/mbostock/950642)
出典: [Labeled Force Layout](http://bl.ocks.org/mbostock/950642)
主な対応データ形式:(ラベル, ラベル), (ラベル, ラベル, 数値), (ラベル, ラベル, ラベル)
2つのラベル間のつながりを表現するのに適した可視化。ある2つのラベル同士につながりがあるかを表現するのにも有効だが、さらにその先に何がつながっているのか、つながりで辿っていった場合にどこまで繋がっているのか、あるいは途切れているのかをとてもわかり易く表現できる。基本はラベルを2つとって、お好みでリンクに3つ目の系統として数値やラベルの情報を付与する。ソーシャルグラフの分析結果の表現方法としてよく利用されている。
かなり多くのデータ数を扱えるが、レイアウト計算のアルゴリズムがだいたいO(N^2) 以上の計算量なので、今日の計算機でもラベルの種類数がある一定を超えたあたり(経験則的には数万ほど)から描画処理が終わらなくなる。その場合は前処理としてデータ数を削るなどが必要。
棒グラフ・円グラフ
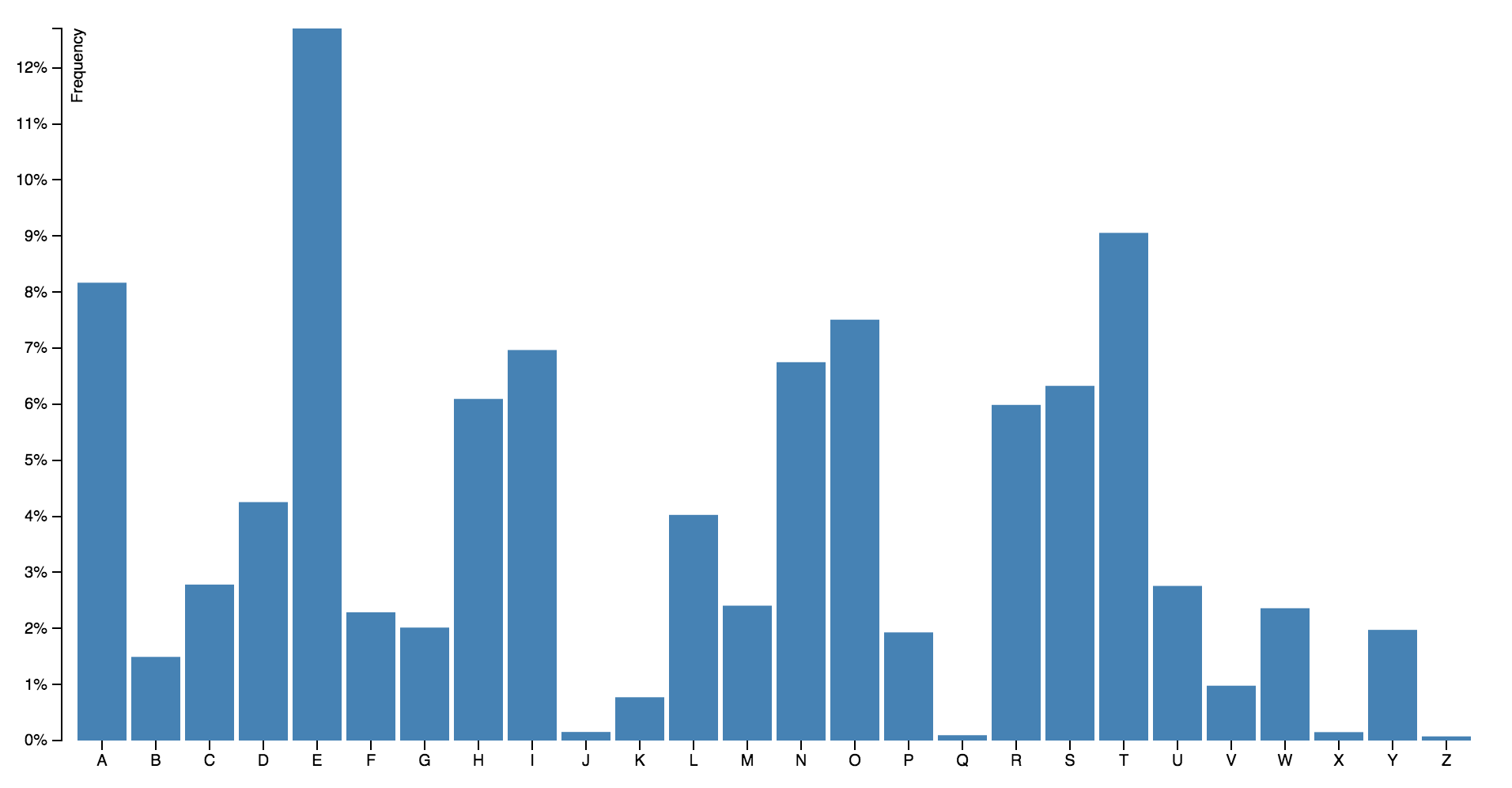 出典:[Bar Chart](http://bl.ocks.org/mbostock/3885304)
出典:[Bar Chart](http://bl.ocks.org/mbostock/3885304)
 出典:[d3pie](http://d3pie.org/)
出典:[d3pie](http://d3pie.org/)
主な対応データ形式:(ラベル, 数値)
いわゆる普通の棒グラフ・円グラフ。どちらもラベルと数値の組み合わせを表現する。それぞれ明確な上限はないが、経験則として円グラフはデータ数10、棒グラフはデータ数25を超えるとグラフとして見づらくなってくる。
箱ひげ図
 出典:[Box and Whisker Plot](http://www.datavizcatalogue.com/methods/box_plot.html)
出典:[Box and Whisker Plot](http://www.datavizcatalogue.com/methods/box_plot.html)
主な対応データ形式:(ラベル, 数値)
データの分散をあらわすための可視化。図中では線の両端が最小値・最大値。箱の左側が第1四分位点、赤と緑の間の線が中央値、右側が第3四分位点となる。これによってラベル毎に数値のばらつきがどの程度あるか?ということを概ね理解することができる。この箱の部分が狭いほどその範囲に数値が集中していることを意味し、箱が広いほど数値がばらついていると読み取ることができる。たまに平均値を算出して棒グラフで表現するグラフを見かけるが、それだと数値が一部に集中しているのか、それともばらけているのか、ということまで分からないため、データの性質を見るという目的なら箱ひげ図のほうが望ましい。
チートシートではラベルの種類数が5以下ならヒストグラム、5より大きければ箱ひげ図と書いたが、おおむね3つ以上であれば箱ひげ図で表現する場合が多い。
ヒストグラム
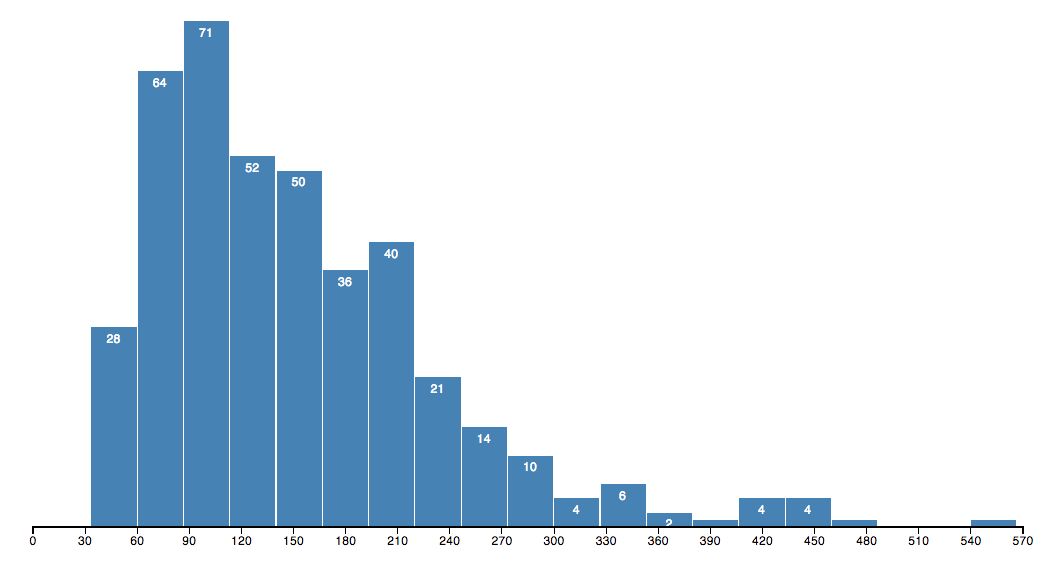
出典:StackOverflow How to fix shifted columns on histogram?
主な対応データ形式:(数値)
箱ひげ図と同じく、どのようにデータが分散しているかを表現する可視化手法。箱ひげ図では中央値や四分位点がどこにあるかを示すだけだったが、どのヒストグラムではどの数値帯にデータが何件(または全体データ数の何%)が出現したかを表現するため、データのばらつきが克明にわかる。基本的に1系列の数値データのみしか扱えないので複数のラベルについて調べたいという場合はラベル毎に別々にグラフを作成する必要があるが、数値データの性質を調べるためには強力な可視化手法。各数値帯を棒グラフ状に表す方法の他に折れ線グラフを使う方法、または累積度数分布として表現する方法などもある。
(ラベル, 数値)のようなデータ形式に対して、複数のラベルのヒストグラムを同じグラフに描画することもできるが、粒度の粗いデータだと線の重なりが起きたときなどに調整が必要なため、素直に1系列でグラフ化するのがお勧めである。
「やり直し」についての解説
※1 データ系列が5以上ある
実データというのは多くの系列が含まれている場合があり、思わず全部まとめて可視化したくなってしまいます。もちろん、複数の可視化手法を組み合わせて使うことでより多くの系列を含むデータを可視化できますが、大体の場合はできた図が煩雑になり見る人(それが自分だとしても)にとって優しくない図になります。まずはどういう情報に着目したいか、ある程度あたりをつけながらやるのがオススメです。
※2 時刻付きのデータにラベルが2系列以上ある
ラベル3系列になるともう手がおえませんが、ラベル2系列であればなんとか時系列ヒートマップの応用で表現することができます。以下の様な図で、1つ目のラベルを右側のように行として表記し、円で描かれている部分を2つ目のラベルに応じて記号を変え(例えば□や☆などにする)たり、色を変えることで表現はできます。ただ、同じ行で2つ以上重なった場合にとても見づらくなってしまうため、うまく表現するためには繊細な調整が必要となるため、あまりお勧めできません。
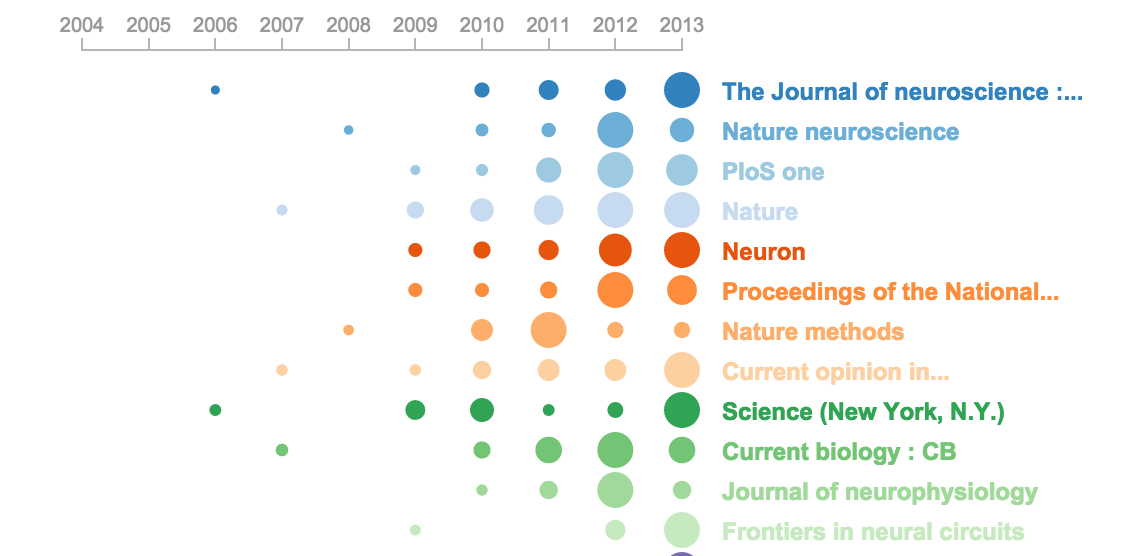 出典: [Journals, Asif Rahman](http://neuralengr.com/asifr/journals/)
出典: [Journals, Asif Rahman](http://neuralengr.com/asifr/journals/)
※3 ラベル2系列以上を含む4系列のデータ
ラベル2系列以上ある時点でだいたいはノードグラフ一択になります。これに対して数値やラベルがひとつならノード間のリンクの太さや距離、あるいはリンクの注釈として表現することができますが、これが2つとなってくると図がかなり煩雑になってしまいます。これも※2と同様にうまく見せるためにはかなり繊細な調整が必要なので、素直に使うデータの系列を見なおしたりするのがお勧めです。
※4 ラベル1系列だけ
1系列でラベルだけだとほぼ何もできません。もしデータ数>ラベルの種類数なのであればラベルの種類毎にそのラベルが何回出現したかをカウントし、(ラベル, 数値) の形式にしてから再度可視化を検討することをおすすめします。