TL; DR
アルバイト中に研修タスクとしてHugging Face NLP Course 3章をモデルを日本語に置き換えて取り組んだので、自分の理解度確認と初心者向けの参考記事としてアウトプットします。
実行したコードとできる限りの説明を付け加えてあります。
モデル:cl-tohoku/bert-base-japanese-v3
データセット: paws-x/ja
学習結果: 3エポック学習して、accuracy:0.51, F1 score: 0.55
実行環境
Google Colab Pro V100ランタイム
使ったモデル
cl-tohoku/bert-base-japanese-v3
トークナイザにfugashiとunidic-liteを使っているとのことですので、これもインストールする必要があります。
使ったデータセット
paws-x/ja
日本語を含む7つの言語を収録しています。2つの文章のペアが同じ意味の文の言い換え(パラフレーズ)であるかどうかを判断するタスクです。
実行したコード
インストール
! pip install datasets evaluate transformers[sentencepiece,torch]
! pip install accelerate -U #マルチGPUの場合速くなる
! pip install fugashi unidic-lite
モデルとトークナイザをロード
Hugging Faceの公式で、AutoTokenizerクラスやAutoModel**クラスを使うのが推奨されています。モデルごとのトークナイザやモデルを使うこともできますが、Auto**クラスを使うことでチェックポイントに合わせたクラスを自動でロードしてくれます。
from transformers import AutoTokenizer, AutoModelForSequenceClassification
checkpoint = "cl-tohoku/bert-base-japanese-v3"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
データセットをロードする
from datasets import load_dataset
raw_datasets = load_dataset('paws-x', 'ja') # 日本語部分のみロードする
raw_datasets
訓練用49491件、検証/テスト用にそれぞれ2000件ずつの文章ペアがあることがわかります。
DatasetDict({
train: Dataset({
features: ['id', 'sentence1', 'sentence2', 'label'],
num_rows: 49401
})
test: Dataset({
features: ['id', 'sentence1', 'sentence2', 'label'],
num_rows: 2000
})
validation: Dataset({
features: ['id', 'sentence1', 'sentence2', 'label'],
num_rows: 2000
})
})
データセットを全部学習させると20分くらい時間がかかるので、10%だけサンプリングして使いました。
# データセットを10%だけサンプリングする
seed = 42
train_size = len(raw_datasets['train'])
val_size = len(raw_datasets['validation'])
test_size = len(raw_datasets['test'])
raw_datasets['train'] = raw_datasets['train'].shuffle(seed=seed).select(range(int(train_size * 0.1)))
raw_datasets['validation'] = raw_datasets['validation'].shuffle(seed=seed).select(range(int(val_size * 0.1)))
raw_datasets['test'] = raw_datasets['test'].shuffle(seed=seed).select(range(int(test_size * 0.1)))
前処理
トークナイズ処理はdatasets.map()メソッドを使って行います。
def tokenize_function(example):
return tokenizer(example['sentence1'], example['sentence2'], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
tokenized_datasets
最後に、各入力はこの段階だと長さが違うため、パディングをして長さを揃える必要があります。また、モデルに入力するためにPyTorchのテンソルに変換する必要があります。
この2つをやるためのクラスがDataCollatorWithPaddingです。ここでは定義のみしておき、後ほどTrainerクラスのインスタンス化時に引数として渡すことで学習時に自動で実行されます。
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
評価指標の設定
今回はaccuracyとF1スコアを指標として用います。実装は簡単のためにHugging FaceのEvaluateクラスを用います。
compute_metrics()関数の中で指標を計算し、この関数をTrainerクラスに引数として渡すことで訓練中に自動で評価を行ってくれます。
def compute_metrics(eval_preds):
metric = evaluate.load("glue", "mrpc") # GLUEベンチマークのMRPCデータセットに紐付いた評価指標。F1とAccuracyを同時にかえしてくれる
logits, labels = eval_preds
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
ハイパーパラメータの定義
Hugging Faceでは、ハイパーパラメータは全てTrainingArgumentsというクラスが持っています。定義は簡単です。
training_args = TrainingArguments("test-trainer", evaluation_strategy="epoch")
最初の引数は結果のモデルを保存するディレクトリ、evaluation_strategyは学習時に評価を行うタイミングを示しています。この設定だと毎エポックの終わりに評価を行います。その他の値は全てデフォルトで大丈夫です。学習は3エポック行われます。
学習の実行
ここまで作ったものをすべてTrainerクラスに渡します。
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
trainer.train() #学習を実行
結果
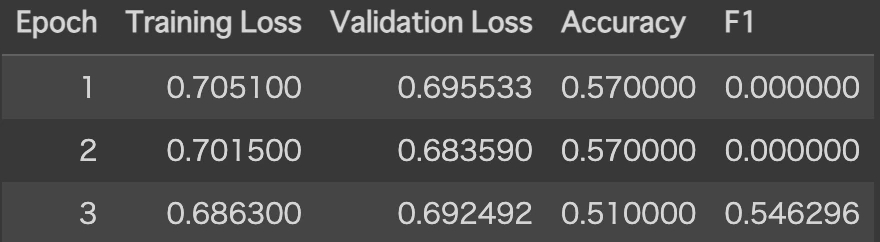
全然ダメなように見えます