Semantic Volumeとは
自然言語処理の勉強の一貫として、以下の論文で提唱されている文章要約について勉強しました。
Extractive Summarization by Maximizing Semantic Volume, Dani Yogatama, Fei Liu, Noah A. Smith
https://www.aclweb.org/anthology/D/D15/D15-1228.pdf
自然言語処理で文章要約をするとはどういうことかすらも知らずに論文を読んだけど、文章要約は以下のような最大化問題として定式化して考えるようです。
\max_{\mathcal{S} \subseteq \mathcal{D},\ length(\mathcal{S})\leq L} score(\mathcal{S})
ただし、$\mathcal{D}:=$ { $ s_1, s_2, \cdots, s_N$ } は要約したい元の文章、 $L\in \mathbb{N}$ は要約したい文字数
$score$をどのように定義するかが文章要約のキモの1つと思われますが、本論文では文章を埋め込んだ空間($\mathbb{R}^K$)での体積(?)とみなすようです。これをsemantic volumeと言っているようです。
2次元で考えるとわかりやすいです。7つの文章ベクトルを2次元に圧縮してプロットしたら以下のようになったとすると、
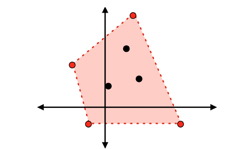
上記の赤い点の文章は黒い点の文章の意味を内包しているはずだ、という考え方のよう。
注意点
文章要約だと聞いて、たまに勘違いされる方がいるかもしれませんが、このロジックはあくまで上記の最大化問題を考えたときの特徴的と判断された文章を原文から抽出しているだけです。
AIが原文の内容を読み取って、文章を一から生成しているわけではありません。
実装
もっといい方法はいろいろ考えられるかもですが、あくまで論文で提唱されている内容を実装することが目的なので、文章の$\mathbb{R}^K$への埋め込みはとりあえずwikipediaコーパスによるword2vecを使いました。
学習済みモデルは以下からお借りしました。
http://aial.shiroyagi.co.jp/2017/02/japanese-word2vec-model-builder/
その他、以下の条件で(とりあえず)実装しています。
- 形態素解析にはMeCab(辞書はneologd)を利用し、品詞は名詞(名詞-数は除く)、自立動詞、形容詞を利用した
- 文章ベクトルは単語ベクトルの平均とした
- 要約する文字数はとりあえず200文字以下とした
要約する文章は以下から夏目漱石の「こころ」をお借りしました
http://www.aozora.gr.jp/
2019.6.19 追記
第1要約文、第2要約文が抽出されてなかったり、コードがダサすぎたりしたので、
クラス化するなど、ソースコードを見直しました。依然としてしょうもないコードかもしれませんがご容赦ください。
import re
import MeCab
import numpy as np
from gensim.models import Word2Vec
class SemanticVolume:
def __init__(self):
# MeCabのtokenizer設定。辞書はneologdを使う
self.neologd = "/usr/local/lib/mecab/dic/mecab-ipadic-neologd"
self.available_pos = ["名詞", "動詞-自立", "形容詞"]
self.not_available_pos = ["名詞-数"]
self.tokenizer = MeCab.Tagger("-Ochasen -d " + self.neologd)
# 分散表現セットアップ
self.model_name = "word2vec.gensim.model"
self.model = Word2Vec.load(self.model_name)
self.features = model.vector_size
# 要約したい元の文書を格納
self.original_sentence = []
# 要約後の文書を格納
self.summarized_sentence = []
# 形態素解析する
def make_wakati(self, sentence):
result = []
chasen_result = self.tokenizer.parse(sentence)
for line in chasen_result.split("\n"):
elems = line.split("\t")
if len(elems) < 4:
continue
word = elems[0]
pos = elems[3]
if True in [pos.startswith(w) for w in self.not_available_pos]:
continue
if True in [pos.startswith(w) for w in self.available_pos]:
result.append(word)
return result
# 文章をベクトルに変換する(単語の平均ベクトル)
def wordvec2docmentvec(self, sentence):
docvecs = np.zeros(self.features, dtype="float32")
# 文章に現れる単語のうち、モデルに存在しない単語をカウントする
denomenator = len(sentence)
# 文章内の各単語ベクトルを足し合わせる
for word in sentence:
try:
temp = self.model[word]
except:
denomenator -= 1
continue
docvecs += temp
# 文章に現れる単語のうち、モデルに存在した単語の数で割る
if denomenator > 0:
docvecs = docvecs / denomenator
return docvecs
# 重心を計算する
def compute_centroid(self, vector_space):
centroid = np.zeros(self.features, dtype="float32")
for vec in vector_space:
centroid += vec
centroid /= len(vector_space)
return centroid
# Proj を計算
def projection(self, u, b):
return np.dot(u, b) * b
# 基底ベクトル
def basis_vector(self, v):
return v / np.linalg.norm(v)
# Distance(u_i, B)
def span_distance(self, v, span_space):
proj = np.zeros(self.features, dtype="float32")
for span_vec in span_space:
proj += self.projection(v, span_vec)
return np.linalg.norm(v - proj)
# index of sentence that is farthest from the subspace of Span(B).
def compute_farthest_spanspace(self, sentences_vector, span_subspace, skip_keys):
all_distance = [self.span_distance(vec, span_subspace) for vec in sentences_vector]
for i in skip_keys:
all_distance[i] = 0
farthest_key = all_distance.index(max(all_distance))
return farthest_key
def execute(self, input_document, summary_length):
corpus_vec = []
sentences = []
self.summarized_sentence = []
# 文章は。区切りとみなす
sentences = input_document.split("。")
# 文章をベクトル化
for sent in sentences:
self.original_sentence.append(sent)
wakati = self.make_wakati(sent)
docvec = self.wordvec2docmentvec(wakati)
corpus_vec.append(docvec)
# 要約対象の文章ID
summarize_indexes = []
# 重心を計算
centroid = self.compute_centroid(corpus_vec)
# 重心から一番遠いベクトルを求める
# これを1つ目の要約文章とする
# adc = all distance from centroid
adc = [np.linalg.norm(centroid - vec) for vec in corpus_vec]
first_summarize_index = adc.index(max(adc))
summarize_indexes.append(first_summarize_index)
# 1つ目の要約文章から一番遠いベクトルを求める
# これを2つ目の要約文章とする
# adfss = all distance from first summarize sentence
adfss = [np.linalg.norm(corpus_vec[first_summarize_index] - vec) for vec in corpus_vec]
second_summarize_index = adfss.index(max(adfss))
summarize_indexes.append(second_summarize_index)
# total length
total_length = len(self.original_sentence[first_summarize_index]) + len(self.original_sentence[second_summarize_index])
# first basis vector
first_basis_vector = self.basis_vector(corpus_vec[second_summarize_index])
span_subspace = [first_basis_vector]
# 3つ目以降の要約文章を求める
while True:
farthest_index = self.compute_farthest_spanspace(corpus_vec, span_subspace, summarize_indexes)
if total_length + len(self.original_sentence[farthest_index]) < summary_length:
span_subspace.append(corpus_vec[farthest_index])
total_length += len(self.original_sentence[farthest_index])
summarize_indexes.append(farthest_index)
else:
break
# 要約文章のインデックスをソートして文書内の出現順に並び替えて要約文章を完成させる
summarize_indexes.sort()
for idx in summarize_indexes:
self.summarized_sentence.append(sentences[idx])
return
結果
ちょこちょこ間違ってるかもしれませんが、その際はご指摘いただけると幸いです。
上のクラスを呼び出して、「こころ」を要約してみる
with open("kokoro.txt","r", encoding="utf-8") as f:
document = f.read()
# もろもろ正規表現等でノイズ除去
# 文章の単位を。区切りとしたいために改行とかを。に変換
document = re.sub(r"《[^》]*》", "", document)
document = document.replace("\u3000", "")
document = re.sub(r"\n\n[.*\n\n", "。", document)
document = re.sub(r"[\n]", "。", document)
document = re.sub("[。]+", "。", document)
sv = SemanticVolume()
sv.execute(document, 200)
for s in sv.summarized_sentence:
print(s)
要約結果がこちら
「そりゃまたなぜです」
「無論いましたわ
いうから」
「こりゃ手織りね
「何をですか」
「それもそうね
「また当分お目にかかれませんから」
「どうするって……」
町はまだ宵の口であった
こんな時こそ」
お前もさぞ草臥れるだろう」
実に面目次第がない
とくに死んでいるでしょう」
父は首肯いた
しかし恐れてはいけません
俄然として心づいたのです
また迷いました
偉大でした
Kはむしろ平気でした
するとKも留まりました
何言っとるかさっぱりわからん
そもそも自分が「こころ」を読んだことないので、これが要約されてる感でてるかわからん
太宰治の「人間失格」でも試してみる
しかし、嗚呼、学校!
助けてね
おや?と思いました
「あら、いやだ
あなたでしょう?」
「行こう!」
前後不覚になりました
「だめ」
「ほんとうかい?」
あなたの気持です」
「画家です」
ほんとうに
「用事って、どんな?」
「あ、これは」
豪気だなあ
堀木は、にわかに活気づいて、
「ばからしい
「どうして、ダメなの?」
あなたでしょう?)
わかるかい」
「わからない」
「してよ」
「あら、いやだ
「からかわないでよ
「コメ
恥
半分ね」
芥川龍之介の「羅生門」
ある日の暮方の事である
盗人が棲む
それから、何分かの後である
下人には、勿論、何故老婆が死人の髪の毛を抜くかわからなかった
「おのれ、どこへ行く
丁度、鶏の脚のような、骨と皮ばかりの腕である
「何をしていた
云え
云わぬと、これだぞよ
けれども、老婆は黙っている
そこで、下人は、老婆を見下しながら、少し声を柔らげてこう云った
「きっと、そうか
下人は、すばやく、老婆の着物を剥ぎとった
プロットしてみた
semantic volumeの考え方は体積が最大になるように文章ベクトルを選択しているのであれば、文章をプロットしたときに端のベクトルをうまく選択しているはず
ということで、文章ベクトルをtsneで2次元に圧縮してプロットし、要約文章として選ばれた文章ベクトルだけ赤色にしてプロットしてみたのが以下になります。
(太宰治の「人間失格」で試しました。)
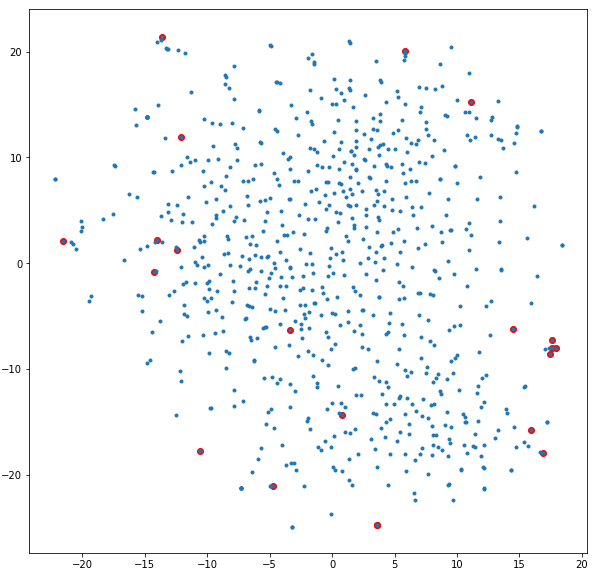
なんか真ん中らへんのベクトルも選んでいるようですが、概ね端のベクトルを選択しているようです。