はじめに
TLM(Task-drive language Modeling)という手法を提唱する論文を読んで、内容が面白そうだったので、実際に実装してみて、TLMの効果を検証してみました。
実装する上で色々と勉強になったので、誰かのためになるのでは、と思い記事としてまとめてみようと思います。
TLM: Task-drive language Modelingとは?
NLP From Scratch Without Large-Scale Pretraining:
A Simple and Efficient Frameworkという論文で紹介されている手法です。
TLMの課題背景は以下のような感じです。
- 近年のNLPはとんでもなく巨大なデータセットで何十億や何百億のパラメータを持つTransformerベースのモデルを扱うのが主流の1つに感じますが、そんな巨大なデータを扱えるのはごく一部の巨大企業だったりして、個人レベルでは事前学習モデルの学習段階から改良しようと思ってもコスト面でなかなか難しい
- このような課題感はNLPの研究において大きな障壁となってて、NLPの長期的な発展を考えると言語モデルの事前学習の効率化を研究・改善する取り組みが重要である
アブストを簡単にまとめると
- 昨今のNLPは大規模なリソースで事前学習されたモデルを扱うことが主流だけど、事前学習モデルは学習コストが大きく誰でも簡単に作れるわけじゃない
- TLMは大規模な事前学習モデルを必要とせず、特定のタスクを効率的に解くフレームワークである
- 4つのドメインの8つの分類データセットにおいて、TLMは学習FLOPを2桁削減しながら、事前に学習した言語モデル(例:RoBERTa-Large)と同等以上の結果を達成した。
→高い精度と効率性を持つTLMが、自然言語処理の民主化と開発の促進に貢献することを期待する、だそうです。

TLMの手法
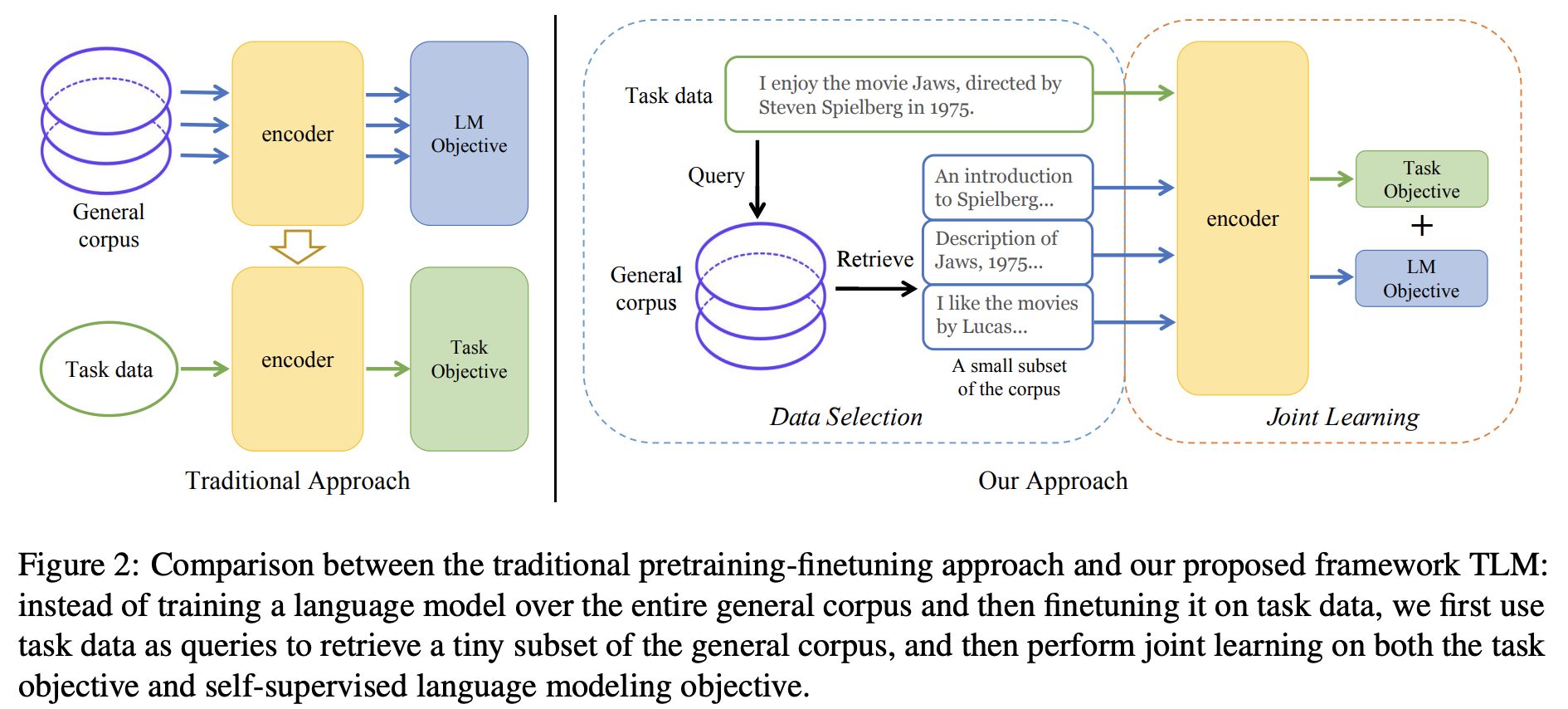
ここで用語の定義をしときます。
- 一般コーパス: Wikipediaやcc100など事前学習に使われる巨大なデータセットを想定
- 固有タスクデータ: Fine Tuningで使うデータ(livedoorニュースコーパスのデータなど)を想定
TLMの手法はとてもシンプルで以下の3stepで構成されます。
-
Data Selection
固有タスクデータ($\cal{T}$)を検索クエリーとして一般コーパスのデータを検索(※1)し、一般コーパスの部分集合$\cal{S}$を取得する -
Joint Learning
一般コーパスデータ$\cal{S}$と、固有タスクデータ$\cal{T}$を使って、事前学習タスク(MLMなど)と固有タスク(分類タスクなど)を同時に学習させる。その際、最適化させる損失関数は以下の通りで、$\rho_1$と$\rho_2$はハイパーパラメータ(※2)である
 1. **Fine Tuning**
最後に固有タスクデータ$\cal{T}$でFine Tuningする。
1. **Fine Tuning**
最後に固有タスクデータ$\cal{T}$でFine Tuningする。
上記の3ステップを得ることで、大規模なデータで事前学習されたモデルに頼ることなく、下流タスクを効率的に解けるよ、ってのかTLMの主張です。
手法に関して2点ほど補足があります。
※1: Data Selectionのステップの検索アルゴリズムはBM25を用いています。もちろんここでの検索の目的は$\cal T$に似ているデータセットを用意することなわけで、BM25よりも何かしらの埋め込み表現を使った類似度検索のほうが検索精度は良いでしょう。ただTLMは効率性に重きを置いているため、学習とかが必要なく素早く精度良く検索するためにBM25を用いているようです。
※2: $\rho_1, \rho_2$の決め方は固有タスクによって最適値が全然違うようです。詳しくは論文を参照していただきたいですが、論文ではグリッドサーチで決定しているようです。この$\rho_1, \rho_2$を最適化するのにかなりの計算コストかかってるんじゃないかと予想してて、全体的に本当に効率化されているのかやや懐疑的に思います。
実装
TLMの主張をだいたい理解したところで実際にTLMの手法を試してみて、効率的に下流タスクが解けるのか検証してみようと思います。
検証の対象は以下とします。
- アーキテクチャー
日本語BERT-base. 東北大の事前学習済BERTモデルを比較対象とします。 - 一般コーパス
Wikipedia - 固有タスクデータと下流タスク
Livedoorニュースコーパスで、本文のカテゴリー分類問題を解くことを目的とします。
実装は論文の著者のGithubを参考にしています。本記事と合わせてご参照ください。
上で紹介した3ステップを1つ1つ実装で確認していきます。
注意
本記事を検証した際のtransformersのバージョンは以下の通りです。今後のtransformersのバージョンアップにより、本記事で紹介している実装が動作しなくなる可能性があります。
transformers 4.15.0
datasets 1.18.0
Step1. Data Selection
固有タスクデータを準備する
まず、事前にカテゴリー、タイトル、本文に分けたLivedoorニュースコーパスを手元に用意します。
import pickle
import pandas as pd
with open('./livedoor_data.pickle', 'rb') as r:
df = pickle.load(r)
display(df.sample(3))

Livedoorニュースコーパスを学習データとテストデータに分けます。
from sklearn.model_selection import train_test_split
train_df, test_df = train_test_split(df, train_size=0.8)
print('train size', train_df.shape)
print('test size', test_df.shape)
# train size (5900, 3)
# test size (1476, 3)
# カテゴリーのID列を付与しておく
categories = df['category'].unique().tolist()
category2id = {cat: categories.index(cat) for cat in categories}
train_df['category_id'] = train_df['category'].map(lambda x: category2id[x])
test_df['category_id'] = test_df['category'].map(lambda x: category2id[x])
上で分けた学習データを$\cal T$とし、Wikipediaを検索する上での検索クエリーに使います。
一般コーパスを準備する
huggingfaceが提供しているdatasetsライブラリを使って簡単にWikipediaデータを取得することができます。2022年1月20日時点のデータを以下のようにダウンロードすると、キャッシュとして、18GBのデータが保存されます。(これ、結構時間かかりました。。。パース?する処理がかなり時間かかります。)
キャッシュは$HOME/.cache/huggingface/datasets/wikipediaに保存されてました。2回目以降はキャッシュをロードするだけなので、すぐにwikipediaデータを呼び出すことができます。
from datasets import load_dataset
wiki_dataset = load_dataset("wikipedia",
language="ja",
date="20220120",
beam_runner="DirectRunner"
)
wiki_dataset = wiki_dataset['train']
wiki_dataset
# Dataset({
# features: ['title', 'text'],
# num_rows: 1624858
# })
Elasticsearchを使ってBM25で一般データを検索する
参考にしているGithubのソースコードでもそうしているように、BM25による検索はElasticsearchを使います。
こういうニーズのためなのか、datasetsライブラリにはElasticsearchと連携する機能が備わっています。
まずはElasticsearch本体を裏で起動しておく必要があるのですが、公式サイトを参考にDockerで起動しました。
Elasticsearchを起動させた状態にして、python側では以下のように実行します。
# 事前にpipでElasticsearchクライアントをインストールしておきましょう
# pip install elasticsearch
from elasticsearch import Elasticsearch
es = Elasticsearch(
[{"host": "localhost", "port": "9200"}],
timeout=300,
)
es_config = {
"settings": {
"number_of_shards": 1,
"analysis": {"analyzer": "kuromoji"},
},
"mappings": {
"properties": {
"text": {
"type": "text",
"analyzer": "standard",
"similarity": "BM25"
},
}
},
}
# Elasticsearchにwikipediaデータのindexをはる
wiki_dataset.add_elasticsearch_index(
'text',
es_client=es,
es_index_name='wiki_es_bm25',
es_index_config=es_config,
)
ElasticsearchにWikipediaデータのindexがはれたところで、固有タスクデータで検索をします。TLMの論文では固有タスクデータ1件に対して類似度TOP50件のデータを一般コーパスから検索したりしてますが、Top50件はさすがに結構な量になってしまいますので、今回はTOP1件だけにしときましょう。
from tqdm import tqdm
nearest_corpus = []
train_corpus = train_df['body'].tolist()
# elasticsearchの検索クエリーは1024文字以内にしないといけないので、冒頭1024文字でカットしています。
train_corpus = [t[:1024] for t in train_corpus]
query_batch = 100
for i in tqdm(range(0, len(train_corpus), query_batch)):
query_corpus = train_corpus[i:i+query_batch]
# バッチ検索が早くて便利ですが、メモリに注意!
nearest_batch = wiki_dataset.get_nearest_examples_batch('text', query_corpus, k=1)
for batch in nearest_batch.total_examples:
nearest_corpus += batch['text']
# もちろん異なる検索クエリーに対して同一データがTop1でヒットする可能性もあるので、重複削除します。
print(len(nearest_corpus)) # 5900
nearest_corpus = list(set(nearest_corpus))
print(len(nearest_corpus)) # 3226
上で作成されたnearest_corpusが論文でいうところの$\cal S$になるんじゃないかと思います。$\cal T$はtrain_dfですね。
Data Selectionのステップは以上になります。
Step2. Joint Learning
Joint Learningってつまりはマルチタスク事前学習なわけですが、BERTの事前学習モデルはhuggingfaceのTrainerクラスを使い倒すことで実現が容易になります。Trainerクラスを使うために、TLM用のDataset、DataCollator、モデルの3つを準備します。
以降のソースコードで変数名の接頭詞にinternalとかexternalとかを使いますが、internal→$\cal T$、external→$\cal S$に関する変数だと理解していただければと思います。
今回の実装でここが一番難しいところでした。というのも、今回のデータは$\cal S$と$\cal T$で損失を計算する上でのラベルが違います。$\cal S$はMLMのラベルだけで良いですが、$\cal T$はMLM+クラス分類ラベルが必要です。そのように目的変数が異なるデータをまとめて1つのDatasetとして学習させたいです。論文著者のGithubのソースコードでは$\cal S$と$\cal T$のDataLoaderを分けて実装していますが、TrainerクラスはDatasetを1つしか受け取ることができないので、論文著者はTrainerクラスをスクラッチで実装しています。さすがにそれはかなり大変なので、Datasetを1つでまとめる代わりにバッチ内に目的変数が異なるデータを混在させながら、Joint Learningを実現することを試みます。
Datasetを準備
MLMの正解ラベルの付与は次に出てくるDataCollatorForLanguageModelingに丸投げしたいです。(自分でMLMを実装しようとするとちょっと大変だと思ったので)。
DataCollatorForLanguageModelingはtoken id列に変換したデータを受け取ることを想定しているっぽいので、Datasetは以下のようなデータ構造をもつものとして用意したいです。
print(tlm_dataset[0])
{'input_ids': [2, 70, 657, 12, 5,・・・
'class_labels': 2,
'data_type': 1}
ここで、data_typeはこのデータが$\cal S$のデータなのか$\cal T$のデータなのかを区別する識別子を想定しています。後続のモデルを作成する際のforward関数内で使う予定です。(がなくても実装できる気がする。。。)
class_labelsはLivedoorニュースコーパスのカテゴリーIDです。
実際のDatasetクラスは以下のように実装しました。
from tqdm import tqdm
from torch.utils.data import Dataset, DataLoader
from transformers import AutoTokenizer
class TLMDataset(Dataset):
def __init__(self, tokenizer, external_corpus=None, internal_df=None, max_length=512):
self.sentences = []
# external data
if external_corpus is not None:
external_sentences = []
for text in external_corpus:
# wikipediaデータを軽く前処理しとく
text = text.replace('\u3000', ' ') # 全角スペースを半角スペースに変換
text = text.replace('\n\n', '\n').replace('\n', ' ')
sents = text.split('。')
external_sentences += [sent+'。' for sent in sents]
# 重複削除
external_sentences = list(set(external_sentences))
# 外部データはカテゴリーのラベルはないので、-100をセットする
# -100はCrossEntropyLossのignore_indexで、-100のデータの損失は計算されません。
external_sentences = [{
'input_ids': tokenizer(text, truncation=True, max_length=max_length)['input_ids'],
'class_labels': -100,
'data_type': 0
} for text in tqdm(external_sentences)]
self.sentences += external_sentences
# internal data
if internal_df is not None:
internal_sentences = [{
'input_ids': tokenizer(row.body, truncation=True, max_length=512)['input_ids'],
'class_labels': row.category_id,
'data_type': 1
} for row in tqdm(internal_df.itertuples(), total=internal_df.shape[0])]
self.sentences += internal_sentences
def __len__(self):
return len(self.sentences)
def __getitem__(self, idx):
return self.sentences[idx]
# Tokenizerは東北大BERTのtokenizerを拝借します。
tokenizer = AutoTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
tlm_dataset = TLMDataset(tokenizer, external_corpus=nearest_corpus, internal_df=train_df)
DataCollatorを用意
用意も何も、transformersのDataCollatorForLanguageModelingを使うだけです。
from transformers import DataCollatorForLanguageModeling
tlm_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=True,
mlm_probability= 0.15
)
ここまでで用意したDatasetとDataCollatorが想定する動きをするか確認しましょう。
tlm_loader = DataLoader(tlm_dataset, collate_fn=tlm_collator, batch_size=8, shuffle=True)
batch = next(iter(tlm_loader))
print(batch.keys())
# dict_keys(['input_ids', 'class_labels', 'data_type', 'attention_mask', 'labels'])
print(batch)
# {'input_ids': tensor([[ 2, 26992, 9, 36, 4, 17358, 28454, 38,・・・
# 'class_labels': tensor([-100, -100, -100, -100, -100, -100, -100,・・・
# 'data_type': tensor([0, 0, 0, 0, 0, 0, 0, 0]),
# 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1・・・
# 'labels': tensor([[ -100, -100, -100, -100, 630, -100, -100, -100,・・・}
問題なく実装できてそうです。
モデルを用意
上の動作確認で見たbatchをモデルが受け取ることになります。
MLMのweightについて
data_typeによってMLMの損失のweight($\rho_1, \rho_2$)を調整できるように実装したいです。論文では解きたいタスクによって$\rho_1, \rho_2$の値は様々なようですが、論文内のAGNewsデータによる検証が今回のLivedoorニュースコーパスに近いデータかなと思われるので、AGNewsデータの検証時に使われたパラメータ$\rho_1 = 4$、$\rho_2 = 20$を今回は採用しようと思います。
ネットワークの実装について
著者のGithubのソースコードを参考にしています。BERT本体はBertConfigでアーキテクチャーを設定して、それをBertModelに渡すだけです。BertModelの最終層の出力のうち、CLSベクトルはカテゴリー分類問題を解く用のネットワークに、各トークンベクトルはMLMを解く用のネットワーク(BertOnlyMLMHead)に渡してやります。Trainerクラスはモデルのアウトプットにlossという名前のkeyに最適化したい損失が格納されていることを前提としているので、モデルのアウトプットはその要件を満たすように実装します(Githubの実装と同様にMaskedLMOutputを使います)。
import torch
from torch import nn
from torch.nn import CrossEntropyLoss
from transformers import BertConfig, BertModel
from transformers import PreTrainedModel
from transformers.models.bert.modeling_bert import BertOnlyMLMHead
from transformers.modeling_outputs import MaskedLMOutput
class BertForTLM(PreTrainedModel):
def __init__(self, config, num_labels, external_mlm_weight=4, internal_mlm_weight=20):
super().__init__(config)
self.config = config
self.bert = BertModel(config, add_pooling_layer=False)
self.mlm_head = BertOnlyMLMHead(config)
# Githubの実装を参考にしていますが、普通にnn.Linearだけだとどうなるかも気になる
self.class_head = nn.Sequential(
nn.Linear(config.hidden_size, config.hidden_size),
nn.GELU(),
nn.Linear(config.hidden_size, num_labels)
)
# batch内の各tensorのlossをそのまま保持するためにreduction='noone'を設定
# defaultはreduction='mean'、つまりbatchのlossの平均を返す
self.loss_function = nn.CrossEntropyLoss(reduction='none')
# TLMの論文のρ1とρ2に相当
# タスクによって最適な重みは全然違うようです
self.external_mlm_weight = external_mlm_weight
self.internal_mlm_weight = internal_mlm_weight
def _get_mean_loss(self, loss):
return loss.sum() / (loss != 0.).sum().clamp(min=1)
def forward(self, input_ids, attention_mask, class_labels=None, labels=None, data_type=None):
outputs = self.bert(input_ids, attention_mask=attention_mask)
outputs = outputs['last_hidden_state']
cls_vec = outputs[:, 0, :]
class_outputs = self.class_head(cls_vec)
class_loss = 0.0
# このモデルを学習後、推論時など正解のラベルがないときでもこのモデルを使えるように
# class_labelsが与えられたときだけlossを計算するようにしています。
if class_labels is not None:
class_loss = self.loss_function(class_outputs, class_labels)
class_loss = self._get_mean_loss(class_loss)
if data_type is not None:
mlm_weight_tensor = (data_type == 0).int() * self.external_mlm_weight + (data_type == 1).int() * self.internal_mlm_weight
mlm_weight_tensor = torch.stack([mlm_weight_tensor] * input_ids.shape[1]).T.flatten()
mlm_loss = 0.0
# このモデルを学習後、推論時など正解のラベルがないときでもこのモデルを使えるように
# labelsが与えられたときだけlossを計算するようにしています。
if labels is not None:
mlm_outputs = self.mlm_head(outputs)
mlm_loss = self.loss_function(mlm_outputs.view(-1, self.config.vocab_size), labels.view(-1))
mlm_loss *= mlm_weight_tensor
mlm_loss = self._get_mean_loss(mlm_loss)
total_loss = class_loss + mlm_loss
return MaskedLMOutput(
loss=total_loss,
logits=class_outputs
)
num_labels = len(categories) # Livedoorニュースコーパスのカテゴリー数(9つ)
config = BertConfig(vocab_size=len(tokenizer))
model = BertForTLM(config, num_labels)
事前学習
後は上で実装したtlm_dataset, tlm_collator, modelをTrainerクラスに渡して学習するだけです。バッチサイズがやや大きめで設定していますが、colabなどで学習する場合は8くらいで12GBほどGPUメモリを喰いました。エポック数はもう少し多くてもいいかもしれませんが、エポック数3でもバッチサイズ32で3時間30分ほど学習に時間かかります。(バッチサイズ8でcolab上で実行すると30時間ほどかかる試算でした。なんだかんだ結構時間かかっちゃいます。。。)
from transformers import TrainingArguments
from transformers import Trainer
training_args = TrainingArguments(
output_dir= './pretrained_TLM',
overwrite_output_dir=True,
num_train_epochs=3,
per_device_train_batch_size=32,
save_steps=10000,
save_total_limit=2,
prediction_loss_only=True
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=tlm_collator,
train_dataset=tlm_dataset
)
trainer.train()
学習が終わったらパラメータを保存します。以下では2つの方法でモデルを保存しています。trainer.save_modelで保存すると、その後AutoModel.from_pretrainedでいつもの呼び出し方で学習済モデルをロードできますが、その際class_headのパラメータのロードの仕方がよくわかりませんでした。class_headの学習済パラメータもロードしたいときはtorch.saveでmodel.state_dict()を保存し、呼び出すときは、BertForTLMのインスタンス変数に対してload_state_dictでパラメータをロードすれば良いです。
TLMの手法は事前学習の段階で下流タスクも学習させているので、下流タスク用のhead(class_head)のパラメータをFine Tuningに使うべきかなと思っているのですが、実際に検証してみたところ、学習済class_headを使っても、Fine Tuning時に新しくhead(例えばnn.Linear)を追加して学習してもさほど結果は変わらなかったです。この辺はどうするべきかは模索中です。
trainer.save_model('./pretrained_TLM')
torch.save(model.state_dict(), './pretrained_TLM/tlm_params.pth')
Step3. Fine Tuning
TLMの方法で事前学習したモデルと東北大が提供しているBERTモデル(cl-hotoku/bert-base-japanese-whole-word-masking)
のFine Tuningにおける精度を比較してみます。
Fine Tuningの方法は上の学習のところでも触れたようにtrainer.save_modelで保存したモデルに対して、Fine Tuning用のhead(nn.Linear)を追加して学習する方法を取りました。(つまり、TLMの方法で学習されたBERTモデルの部分のパラメータの比較をしているイメージです。)
論文でも行っているように、$\cal S$だけで事前学習した場合と一般コーパスからランダムにデータをピックアップしてJoint Learningしたときの精度も合わせて確認してみました。
まず、Fine Tuningで使うネットワークはこんな感じで実装します。
import torch
import torch.nn as nn
class LivedoorNet(nn.Module):
def __init__(self, pretrained_model, num_labels):
super().__init__()
self.hidden_size = pretrained_model.config.hidden_size
self.bert = pretrained_model
self.linear = nn.Linear(self.hidden_size, num_labels)
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids, attention_mask=attention_mask)
outputs = outputs['last_hidden_state']
outputs = outputs[:, 0, :]
outputs = self.linear(outputs)
return outputs
Fine Tuningで学習させるところはこんな感じで実装しました。とりあえず10エポック学習させてみました。
from tqdm import tqdm
from sklearn.metrics import f1_score
import torch.optim as optim
from transformers import AutoModel, AutoTokenizer
# GPU使う
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
tokenizer = AutoTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
loss_function = nn.CrossEntropyLoss()
pretrained_model = AutoModel.from_pretrained('./pretrained_TLM/')
# pretrained_model = AutoModel.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
# Sだけで事前学習した場合
# pretrained_model = AutoModel.from_pretrained('./pretrained_only_random_external')
# ランダムに抽出したデータセットだけで事前学習した場合
# pretrained_model = AutoModel.from_pretrained('./pretrained_only_external')
# DatasetとDataLoaderを定義
# collatorはTLMの事前学習時に使ったtlm_collatorを使ってます。これ使うともちろんMLMのlabelもbatch内に含まれてしまいますが、まぁいいでしょう。
train_dataset = TLMDataset(tokenizer, internal_df=train_df)
test_dataset = TLMDataset(tokenizer, internal_df=test_df)
train_loader = DataLoader(train_dataset, collate_fn=tlm_collator, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, collate_fn=tlm_collator, batch_size=64, shuffle=False)
net = LivedoorNet(pretrained_model, len(categories))
# GPU2枚並列で使います。
net = nn.DataParallel(net, device_ids=[0, 1])
net.to(device)
# nn.DataParallel使うときはnet.”module”が必要ですが、nn.DataParallel使わないときは不要です。
# 事前学習済のパラメータ学習率を小さめに設定
optimizer = optim.Adam([
{'params': net.module.bert.parameters(), 'lr': 5e-5},
{'params': net.module.linear.parameters(), 'lr': 1e-4},
])
test_fscores = []
for epoch in range(10):
# 学習ステップ
all_loss = 0
net.train()
for batch in tqdm(train_loader):
optimizer.zero_grad()
input_ids = batch['input_ids'].cuda()
attention_mask = batch['attention_mask'].cuda()
y = batch['class_labels'].cuda()
pred = net(input_ids, attention_mask=attention_mask)
loss = loss_function(pred, y)
loss.backward()
optimizer.step()
all_loss += loss.item()
# 推論ステップ
answer = []
prediction = []
net.eval()
with torch.no_grad():
for batch in tqdm(test_loader):
input_ids = batch['input_ids'].cuda()
attention_mask = batch['attention_mask'].cuda()
y = batch['class_labels'].cuda()
pred = net(input_ids, attention_mask=attention_mask)
_, pred = torch.max(pred, 1)
prediction += list(pred.cpu().numpy())
answer += list(y.cpu().numpy())
test_fscore = f1_score(answer, prediction, average='macro')
test_fscores.append(test_fscore)
print("epoch", epoch, "\ttrain loss", all_loss, "\ttest fscore", test_fscore)
最初にテストデータとして分けたデータのエポック毎のF1-scoreを比較してみます。

- 東北大BERTモデルが圧倒的に強い
- TLMと$\cal S$のみで事前学習したモデルを比較すると、ややTLMが優勢?
- ランダムにピックアップして事前学習したモデルは立ち上がりの精度が悪く、Fine Tuningでだいぶ精度が上がったけど、他のモデルに劣る
東北大BERTには勝てなかったけど、TLMの手法であるJoint Learningの効果も少し実感できたかなという印象です。(自分の実装方法や検証方法が微妙なのかもですが、もう少し良い結果を期待してましたが。。。)
TLMのモデルの精度を向上させるためには、BM25による検索をTOP1だけじゃなく、論文でもやってるようにTOP50とかにして$\cal S$のデータ量をもっと増やすとか、$\rho_1, \rho_2$を調整する、とかが必要かも。事前学習時のエポック数も合わせて増やしたほうがいいかも。
Attention weightの分析
最後に論文でも紹介されているAttention weightの分析を紹介します。

詳しくは論文をご参照してほしいのですが、Multi-head Attentionの各weightの傾向として以下の2点が知られているようです。
positional head
最大のAttention weightの90%以上が隣接するトークンに割り当てられるheadであり、これらのheadはモデルの最終予測に重要な貢献をしている。(上図の赤枠)
vertical head
ほとんどの最大のAttention weightが[CLS],[SEP]またはピリオドトークン(".")に割り当てられているもので、これらは潜在的にあまり意味的または構文的な情報をエンコードしない。(上図のグレーアウトしている箇所)
これらの観点で上図を見てみるとTLMのほうが比較対象のBERT-baseやRoBERTa-baseと比べて、positional headの数が多く、vertical headの数が少ないです。つまり、TLMのほうがより情報量の多いAttentionを学習していることを示唆する、ようです。他の文章で実験してみても同様の傾向があるようで、この分析の仕方面白いなぁと思ったので、今回のケースでも各Attention headのweightを可視化してみました。
インプットに使った文章はこちらです。
[CLS]音楽とスポーツをファッショナブルに楽しむためのヘッドホンが誕生[SEP]

軸の説明がなくて恐縮ですが、左から右にかけてhead1->head12、上から下にかけてLayer1->Layer12のAttention weightを可視化しています。
vertical headは今回はスルーしちゃってます。パット見これはpositional headだろうな、と思った箇所を青枠で囲って見ました。
精度評価でそもそも東北大BERTのほうが全然良かったので、ある意味その結果の裏付けみたいになっちゃいますが、論文で紹介されているような結果にはならなかったです。東北大BERTのほうがpositional headの数が明らかに多いし、特に層が深くなるにつれて、positional headの数が増えているのに対し、TLMは層が深くなるとpostional headが出てこなくなる、という結果になってしまいました。
おわりに
大規模データによる事前学習の強さを改めて実感しました。実際のところBERTやRoBERTaなんかは日本語の事前学習済モデルが公開されているわけですし、それをありがたく使えばいいわけですが、もっと新しい独自のネットワークによる事前学習モデルを作りたい、けど大規模データを用意できない、とか学習コストが高すぎでそこまで事前学習してられない、ってときにはこのTLMの手法で事前学習モデルを作ってみるのもいいかもしれませんね。
ただTLMの論文でも書かれていますが、事前学習モデルの汎用性(Fine Tuningするだけでいろんなタスクを高精度で解ける)はどうしてもTLMは劣るようなので、いろんなタスクにモデルを転用したいという場合はやはり大規模データによる事前学習モデルに頼らざるを得ないですかねぇ。
おわり