GloVe(Global Vectors)による単語の分散表現の作り方メモ
ほとんど以下の記事の写経です。
GloVeとは?
ググるとだいたい以下のようなことが書かれている印象
- Word2Vecの後発となる単語分散表現の取得方法
- Stanfordが開発
- コーパス全体から得られる単語間の共起行列を学習に使っている
- 小さいコーパスでもいける
- 精度が良い
- 学習が早い
これだけ見てもよくわからんので、実際に触ってみます。
インストール
cloneしてmakeするだけでOK
git clone http://github.com/stanfordnlp/glove
cd glove && make
buildフォルダの中にGloVeで分散表現を作成するために必要なコマンドが入っています。
$ cd build
$ ls
cooccur glove shuffle vocab_count
単語分散表現を作る
学習対象のコーパス用意や形態素解析
- コーパスはlivedoorニュースコーパス(https://www.rondhuit.com/download.html) を使用
- 形態素解析エンジンはMeCabを使用(辞書やStopwordsとかは特に指定しない)
GloVeはfastTextと同様に、コマンドにコーパスを渡す際は、コーパスを形態素で分割したものをファイルとして保存しておく必要があります。
そのファイルは1行1文でちゃんと学習してくれるっぽいです。
以下でコーパスを準備して、形態素で分割して外部ファイル(livedoor_corpus.txt)に保存しています。
import re, MeCab
from glob import glob
# 分かち書きはMeCabで適当に
tagger = MeCab.Tagger("-Owakati")
def make_wakati(sentence):
# MeCabで分かち書き
sentence = tagger.parse(sentence)
# 半角全角英数字除去
sentence = re.sub(r'[0-90-9a-zA-Za-zA-Z]+', " ", sentence)
# 記号もろもろ除去
sentence = re.sub(r'[\._-―─!@#$%^&\-‐|\\*\“()_■×+α※÷⇒—●★☆〇◎◆▼◇△□(:〜~+=)/*&^%$#@!~`){}[]…\[\]\"\'\”\’:;<>?<>〔〕〈〉?、。・,\./『』【】「」→←○《》≪≫\n\u3000]+', "", sentence)
# スペースで区切って形態素の配列へ
wakati = sentence.split(" ")
# 空の要素は削除
wakati = list(filter(("").__ne__, wakati))
return wakati
# livedoorニュースコーパスを全て分かち書きして1つのファイルに書き込む
# カテゴリを配列で取得
categories = [name for name in os.listdir('text') if os.path.isdir("text/" +name)]
with open("livedoor_corpus.txt", "w", encoding="utf-8") as w:
for cat in categories:
path = "text/" + cat + "/*.txt"
files = glob(path)
for text_name in files:
with open(text_name, "r", encoding="utf-8") as f:
data = f.read()
wakati = make_wakati(data)
w.write(" ".join(wakati) + "\n")
パラメータ
以下の記事に引数に関してまとめられています。
引数の説明やデフォルト値はソースコードも参考
| 引数名 | 説明 | デフォルト値 |
|---|---|---|
| -min-count | 単語出現頻度がこの数値以下の単語は学習対象外とする | 5 |
| -verbose | 学習中の標準出力の内容 | 2 |
| -memory | 使用する最大メモリ数(GB) | 3 |
| -window-size | 学習を考慮する周辺単語数 | 15 |
| -threads | スレッド数 | 8 |
| -binary | ファイルの出力形式。2ならテキスト、バイナリの両方のモデルを出力 | 2 |
| -x-max | 極端に小さいコーパスを使う場合は調整が必要らしい | 100 |
| -vector-size | ベクトル次元数 | 50 |
| -iter | 学習のループ数 | 25 |
GloVeで単語分散表現を作成
以前ご紹介したfastTextで分散表現作るときみたいにPythonから外部コマンドを呼び出す形でPython上で実行します。
GloVeで単語分散表現を作るためには、
- ボキャブラリー作成(vocab_count)
- 共起行列計算(cooccur)
- 共起行列のシャッフル(shuffle)
- 分散表現作成(glove)
の順番で処理を実行する必要があります。
ボキャブラリー作成(vocab_count)
import os
vocab_count = "/Users/〜〜/glove/build/vocab_count"
min_word_count = "-min-count 5"
verbose = "-verbose 2"
input_file = "livedoor_corpus.txt"
output_file = "vocab.txt"
command_list = [vocab_count, min_word_count, verbose, "<", input_file, ">", output_file]
command = " ".join(command_list)
os.system(command)
# 0
Jupyter Notebookを使っている場合はterminalに以下のような出力がされています。
BUILDING VOCABULARY
Processed 3648306 tokens.
Counted 79677 unique words.
Truncating vocabulary at min count 5.
Using vocabulary of size 28878.
共起行列計算(cooccur)
cooccur = "/Users/〜〜/glove/build/cooccur"
memory = "-memory 8"
vocab_file = "-vocab-file vocab.txt"
window_size = "-window-size 10"
output_file = "cooccurrence.txt"
command_list = [cooccur, memory, vocab_file, window_size, "<", input_file, ">", output_file]
command = " ".join(command_list)
os.system(command)
# 0
出力
COUNTING COOCCURRENCES
window size: 10
context: symmetric
max product: 26461224
overflow length: 76056712
Reading vocab from file "vocab.txt"...loaded 28878 words.
Building lookup table...table contains 117737177 elements.
Processed 3648306 tokens.
Writing cooccurrences to disk........2 files in total.
Merging cooccurrence files: processed 10442384 lines.
共起行列のシャッフル(shuffle)
shuffle = "/Users/〜〜/glove/build/shuffle"
output_file = "cooccurrence_shuffle"
command_list = [shuffle, memory, verbose, "<", "cooccurrence.txt", ">", output_file]
command = " ".join(command_list)
os.system(command)
# 0
出力
SHUFFLING COOCCURRENCES
array size: 510027366
Shuffling by chunks: processed 10442384 lines.
Wrote 1 temporary file(s).
Merging temp files: processed 10442384 lines.
分散表現作成(glove)
glove = "/Users/〜〜/glove/build/glove"
save_file = "-save-file vectors"
threads = "-threads 2"
input_file = "-input-file cooccurrence_shuffle"
x_max = "-x-max 100"
iter_num = "-iter 10"
vector_size = "-vector-size 200"
binary = "-binary 2"
vocab_file = "-vocab-file vocab.txt"
command_list = [glove, save_file, threads, input_file, x_max, iter_num, vector_size, binary, vocab_file]
command = " ".join(command_list)
os.system(command)
# 0
出力
TRAINING MODEL
Read 10442384 lines.
Initializing parameters...done.
vector size: 200
vocab size: 28878
x_max: 100.000000
alpha: 0.750000
10/19/19 - 02:47.30PM, iter: 001, cost: 0.027430
10/19/19 - 02:47.37PM, iter: 002, cost: 0.016721
10/19/19 - 02:47.44PM, iter: 003, cost: 0.015251
10/19/19 - 02:47.52PM, iter: 004, cost: 0.014308
10/19/19 - 02:47.59PM, iter: 005, cost: 0.013367
10/19/19 - 02:48.07PM, iter: 006, cost: 0.012413
10/19/19 - 02:48.13PM, iter: 007, cost: 0.011525
10/19/19 - 02:48.20PM, iter: 008, cost: 0.010780
10/19/19 - 02:48.26PM, iter: 009, cost: 0.010145
10/19/19 - 02:48.33PM, iter: 010, cost: 0.009597
Gensimで呼び出す
GloVeで単語ベクトルを得るで説明があるように、gensim.models.KeyedVectorsで読み込めるようにします。
import pandas as pd
import numpy as np
from gensim.models import KeyedVectors
# 単語ラベルをインデックスにしてDataFrameで読み込む
vectors = pd.read_csv('./vectors.txt', delimiter=' ', index_col=0, header=None)
with open('./vectors.txt', 'r') as original, open('./gensim_vectors.txt', 'w') as transformed:
vocab_count = vectors.shape[0] # 単語数
size = vectors.shape[1] # 次元数
transformed.write(f'{vocab_count} {size}\n')
transformed.write(original.read())
glove_vectors = KeyedVectors.load_word2vec_format('./gensim_vectors.txt', binary=False)
glove_vectors.most_similar('男性')
# [('女性', 0.9495656490325928),
# ('年上', 0.9018761515617371),
# ('にとって', 0.8997328281402588),
# ('既婚', 0.8956040143966675),
# ('年齢', 0.8919621109962463),
# ('働く', 0.8764708042144775),
# ('女', 0.8707152605056763),
# ('関係', 0.869656503200531),
# ('私たち', 0.866401195526123),
# ('夫婦', 0.8651594519615173)]
fastText、Word2Vecと比較してみる
せっかくなので、同じlivedoorニュースコーパスを同様のパラメータでfastText、Word2Vecで学習させたときの単語分散表現をちょっと比較してみます。
fastTextで単語分散表現を得る
from gensim.models.wrappers.fasttext import FastText
fasttext = "/Users/〜〜/fastText/fasttext"
algorithm = "skipgram"
input_file = "-input livedoor_corpus.txt"
output_model = "-output fasttext.model"
# 諸々のパラメータを指定
feature = "-dim 200"
negative = "-neg 10"
window_size = "-ws 10"
epoch="-epoch 10"
command_list = [fasttext, algorithm, input_file, output_model, feature, negative, window_size, epoch]
command = " ".join(command_list)
os.system(command)
model_name = "fasttext.model"
fastText_model = FastText.load_fasttext_format(model_name)
Word2Vecで単語分散表現を得る
Word2Vecはgensimで完結するので、gensimを使って学習
from gensim.models import Word2Vec
import logging
corpus = []
for cat in categories:
path = "text/" + cat + "/*.txt"
files = glob(path)
for text_name in files:
with open(text_name, "r", encoding="utf-8") as f:
data = f.read()
wakati = make_wakati(data)
corpus.append(wakati)
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
num_features = 200
min_word_count = 5
num_workers = 40
context = 10
downsampling = 1e-3
w2v_model = Word2Vec(corpus, workers=num_workers, hs = 0, sg = 1, negative = 10, iter = 10,
size=num_features, min_count = min_word_count, window = context, sample = downsampling, seed=1)
w2v_model.save("w2v.model")
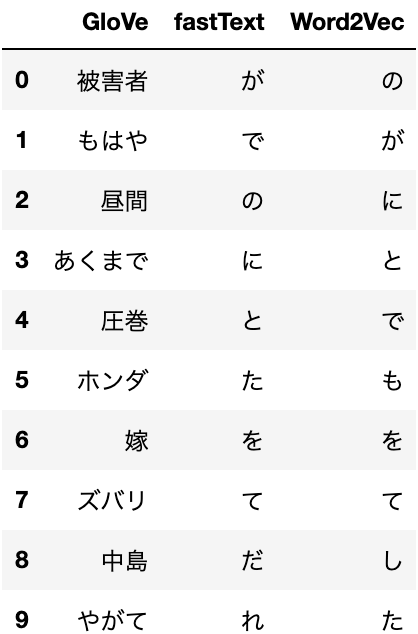
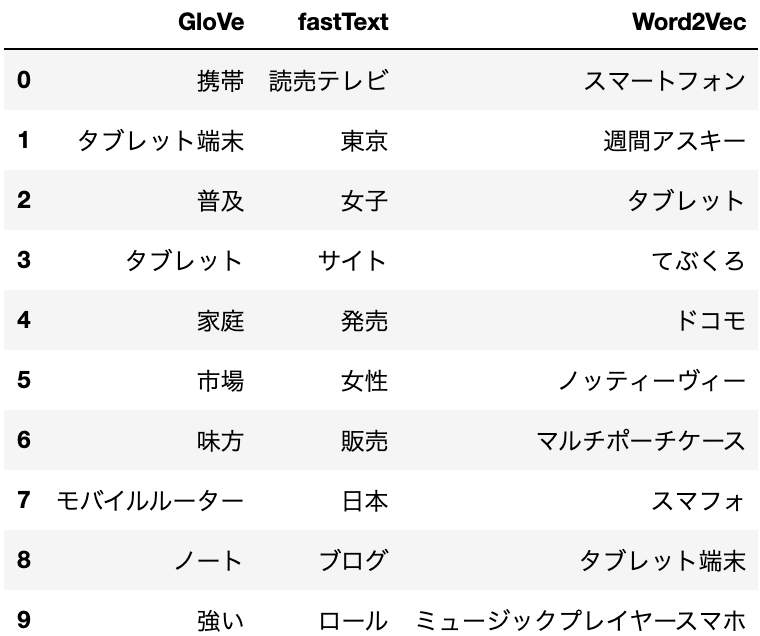
比較
import pandas as pd
word = "男性"
glove_similar = glove_vectors.most_similar(word)
fastText_similar = fastText_model.most_similar(word)
w2v_similar = w2v_model.wv.most_similar(word)
result = []
for g, f, w in zip(glove_similar, fastText_similar, w2v_similar):
row = [g[0], f[0], w[0]]
result.append(row)
df = pd.DataFrame(result, columns=["GloVe", "fastText", "Word2Vec"])
df
男性

スポーツ

は
スマホ
おわりに
livedoorニュースコーパスじゃ、コーパスのサイズが小さすぎてイマイチGloVeの良さがよくわからんかった。
もっと専門性の高いコーパスに対して使ってみよう
おわり