はじめに
LangGraphの勉強の備忘録として、タイトルの通り最新のトレンドを考慮した広告文生成をやってみます。
といっても内容は非常に薄く、LangChainやLangGraphのチュートリアルを少し書き換える程度のことしかしてませんが、誰かの参考になればうれしいです。
参考情報
以下が大変勉強になりました。
やることの概要
検索連動型広告(GoogleやYahooで検索したとき、検索結果の上部や下部に表示される広告のこと。リスティング広告ともいう)の見出し文を対象とします。
ユーザーは作成したい広告のジャンルのようなものを入力します。Agentがそのジャンルに関する最近の流行を検索し、内容をまとめ、流行を示す重要なキーワードを列挙し、そのキーワードをもとに広告文を生成させる、ということをLangGraphを使ってやってみようと思います。
ざっくり以下のようなことを実現したいです。

これくらいのことであれば、ChatGPTのUI使えば全然できる話かと思いますが、LangGraphの勉強がてら、上記の処理をLangGraphを駆使して実装してみようと思います。
準備
基本的に公式のチュートリアルをかいつまんだ実装になっていると思います。必要なライブラリのインストール方法はチュートリアルを参照してください。
あと、今回の実装ではTavily APIを使います。これはLangChainで簡単にネット検索ができる便利ツールなのですが、Tavily APIを使ってトレンド検索を行います。Tavily APIは無料でもある程度使えますが、アカウント登録をしてAPIキーを発行する必要があります。詳しくはこの辺から諸々参照してください。
さらにLangSmithも活用します。正直LangChainの実装をする上でLangSmithが便利すぎて、これないとつらいなと思えるレベルです。
LangSmithはLLM版のMLFlowのようなもので、LangChainのコードを全くいじることなく、LLMの挙動のあらゆる情報を自動で管理してくれます。LangChainのチュートリアルでも積極的にLangSmithの画面を見てLLMの挙動を確認してくれ、といっています。こちらも詳しくはこの辺を参照してください。
実装
今回はChatGPTのAPIを使います。APIのコストを少しでも抑えるために gpt-4o-mini を使います。
最初にカレントディレクトリに .env という名前で各種環境変数を設定しておきます。(後ほど dotenv を使って読み込みます。)
OPENAI_API_KEY="APIキーをここに入力"
LANGCHAIN_API_KEY="LangSmithのAPIキーを入力"
LANGCHAIN_TRACING_V2=true
LANGCHAIN_ENDPOINT=https://api.smith.langchain.com
LANGCHAIN_PROJECT="generate_ad_text"
TAVILY_API_KEY="Tavily APIキーを入力"
まずは必要なライブラリをインポートします
from dotenv import load_dotenv
load_dotenv()
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain.prompts import FewShotPromptTemplate, PromptTemplate
from langgraph.prebuilt import create_react_agent
from langgraph.graph import END, START, StateGraph
from langchain_community.tools.tavily_search import TavilySearchResults
from typing import List
from typing_extensions import TypedDict
from pydantic import BaseModel, Field
LLMの定義
今回、LLMを3つ定義します。1つ目は最初のユーザ入力を下にTavily APIを使ってトレンドを検索しまとめるLLM、2つ目はまとめられたトレンド情報を下にキーワードを抽出するLLM、3つ目はトレンドのキーワードを下に広告文を作成するLLMです。
このうち、2つ目と3つ目のLLMはアウトプットを構造的に持たせたいため、以下のような型を定義しておきます。
# トレンド情報からキーワードを抽出するLLMをこの形式で出力させる
class TrendKeywords(BaseModel):
trend_keywords: List[str] = Field(
description="流行における重要キーワード",
)
# 抽出されたキーワードを下に広告文生成するLLMをこの形式で出力させる
class AdvertisingInfo(BaseModel):
advertiser_name: str = Field(description="広告主名")
campaign_name: str = Field(description="広告のキャンペーン名")
genre: str = Field(desciption="広告のジャンル")
copy_texts: List[str] = Field(description="1文15文字程度の広告見出し文")
次にLangGraphの各ノードで動くLLMを宣言していきます。まずはTavily APIをツールとしてもつLLM(Agent)を作成します。
openai_model_version = "gpt-4o-mini"
llm = ChatOpenAI(model=openai_model_version)
# max_results: 何件分の検索結果を保持するか
tools = [TavilySearchResults(max_results=5)]
agent_executor = create_react_agent(llm, tools)
次にトレンド情報をもとにキーワードを抽出するLLMです。
extract_prompt = ChatPromptTemplate.from_messages(
[
("user", "以下で与えられるトレンド情報から重要なキーワードを5つ抽出してください。\n\n##トレンド情報\n{trend_text}"),
]
)
extract_trends = llm.with_structured_output(
TrendKeywords
)
trend_extractor = extract_prompt | extract_trends
そして最後にトレンドのキーワードを下に広告文を生成するLLMです。こちらのLLMでは上記で定義したAdvertisingInfoの構造で生成してほしいのですが、構造がちょっとだけ複雑だからなのか、単純なプロンプトだとやや想定している挙動ではなかったので、ここではあえてfew-shotでプロンプトを定義しようと思います。
つまり、まず以下のようなAdvertisingInfoの構造に即したサンプルデータを用意します。
examples = [
{"example": "advertiser_name: 'FinancePlus', campaign_name: '年末投資キャンペーン', genre: '金融', copy_text: ['安心の資産運用', '初心者向け投資ガイド', '年末限定の高利回り']"},
{"example": "advertiser_name: 'BeautyWorks', campaign_name: '冬のスキンケア特集', genre: '美容', copy_text: ['潤いを与える化粧水', '乾燥対策に最適', '透明感あふれる肌に']"},
{"example": "advertiser_name: 'FunZone', campaign_name: 'ホリデームービーキャンペーン', genre: 'エンタメ', copy_text: ['話題の映画が勢揃い', '家族で楽しむエンタメ', '新作を先取り']"},
{"example": "advertiser_name: 'RealEstateHub', campaign_name: '新生活応援キャンペーン', genre: '不動産', copy_text: ['理想の住まい探し', '初めての賃貸契約', '生活利便性抜群']"}
]
これらのサンプルデータは適当にChatGPTのUIを使って4oに生成させたものです。これらのサンプルデータをfew-shotとしてプロンプトに与えます。こちらのチュートリアルの通りに FewShotPromptTemplate を活用します。
OPENAI_TEMPLATE = PromptTemplate(input_variables=["example"], template="{example}")
fewshot_template = FewShotPromptTemplate(
prefix="以下は検索連動型広告に関するサンプルデータです。",
examples=examples,
suffix="これらの例を参考に検索連動型広告を10文作成してください。ただし作成する広告のジャンルは{genre}とし、以下に提示する2024年のトレンド情報を訴求してください。\n\n##トレンド情報\n{trend_keywords}",
input_variables=["genre", "trend_keywords"],
example_prompt=OPENAI_TEMPLATE,
)
generate_ads = llm.with_structured_output(AdvertisingInfo)
ads_generator = fewshot_template | generate_ads
LangGraphでグラフ構造を作る
まず、グラフのノード間を遷移する状態を以下のように定義しました。
class State(TypedDict):
input: str # ユーザが入力する最初のクエリーを管理
trend_text: str # 検索されたトレンド情報をLLMがまとめた結果を格納
advertiser_name: str # 生成される架空の広告主
campaign_name: str # 生成される架空の広告キャンペーン
genre: str # 生成させたい広告のジャンル
trend_keywords: List[str] # trend_textを下にLLMが抽出したキーワードを格納
copy_texts: List[str] # 生成された広告見出し文を格納
このStateが各ノードのinput/outputになるように記述していきます。
def search_trend(state: State):
response = agent_executor.invoke({"messages": [("user", state["input"])]})
state["trend_text"] = response["messages"][-1].content
return state
def extract_keywords(state: State):
response = trend_extractor.invoke(state)
state["trend_keywords"] = response.trend_keywords
return state
def generate_ads(state: State):
response = ads_generator.invoke(state)
state["advertiser_name"] = response.advertiser_name
state["campaign_name"] = response.campaign_name
state["copy_texts"] = response.copy_texts
return state
あとは上記の処理をノードとして定義し、グラフを構築します。
(簡易的にするため、条件分岐とかのエッジは定義していません。ユーザ入力に対し、Agentがツールを使うと判断することを前提とした処理になっています。)
workflow = StateGraph(State)
workflow.add_node("search_trend", search_trend)
workflow.add_node("extract_keywords", extract_keywords)
workflow.add_node("generate_ads", generate_ads)
workflow.add_edge(START, "search_trend")
workflow.add_edge("search_trend", "extract_keywords")
workflow.add_edge("extract_keywords", "generate_ads")
workflow.add_edge("generate_ads", END)
app = workflow.compile()
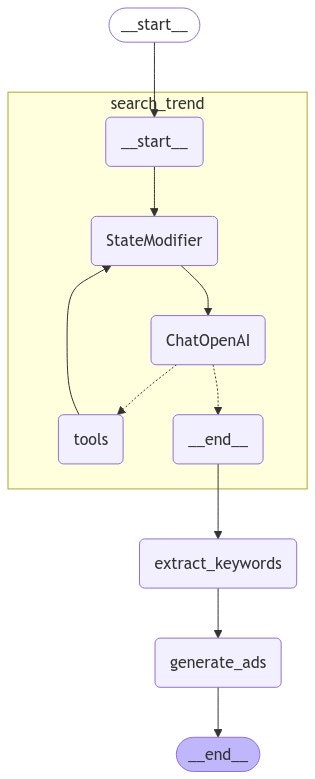
無事にグラフをコンパイルできたら、想定した処理の流れになっているか、グラフを描画して確認します。
from IPython.display import Image, display
display(Image(app.get_graph(xray=True).draw_mermaid_png()))
from IPython.display import Image, display
実行する
グラフに与える最初の状態を定義します
initial_state = State()
initial_state["input"] = "2024年において、Z世代で流行している美容は?"
initial_state["genre"] = "美容"
そもそもユーザの入力が単純に流行を聞いているだけなのに、グラフとしては広告文を生成してくるのってどうなんだ、という気持ちはありますが、今回は目をつぶります。
以下のコードでグラフを実行します。
for event in app.stream(initial_state):
for k, v in event.items():
if k != "__end__":
print(v)
printしてるので、各処理の結果が表示されますが、見辛いのでLangSmithで1つ1つのノードの挙動を確認するのがよいです。
挙動の確認
LangSmithの画面に以下のようなプロジェクトができているかと思います。
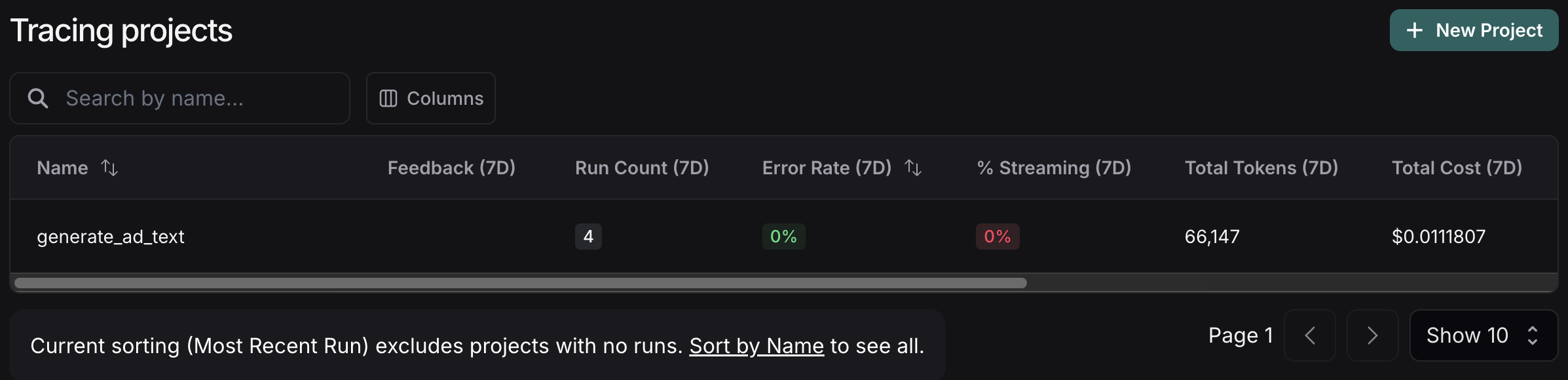
トータルのトークン数やコストまで表示してくれるのすごい便利です。
プロジェクトをクリックし、実行した処理を1つ選択すると、以下のように各ノードの処理のトレース情報が事細かに確認することができます。
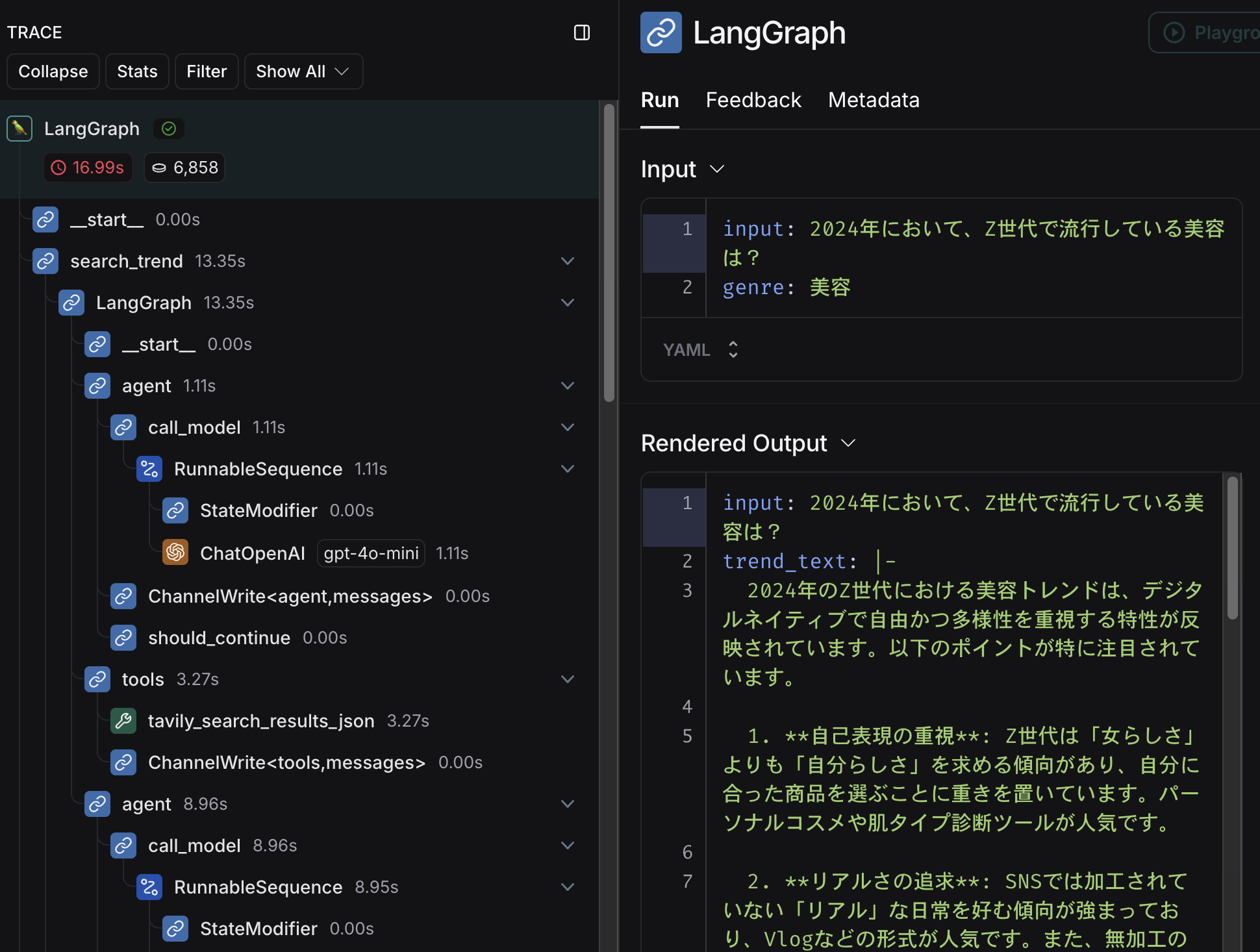
まずはユーザ入力からトレンド情報を検索しまとめる処理(search_trendノード)を見てみます。
ユーザ入力(2024年において、Z世代で流行している美容は?)に対し、検索クエリーが2024 Z世代 美容 流行として展開されており、検索結果をもとに最終的に以下のようなアウトプットを生成していました。
output
{
"input": "2024年において、Z世代で流行している美容は?",
"genre": "美容",
"trend_text": "2024年のZ世代における美容トレンドは、デジタルネイティブで自由かつ多様性を重視する特性が反映されています。以下のポイントが特に注目されています。\n\n1. **自己表現の重視**: Z世代は「女らしさ」よりも「自分らしさ」を求める傾向があり、自分に合った商品を選ぶことに重きを置いています。パーソナルコスメや肌タイプ診断ツールが人気です。\n\n2. **リアルさの追求**: SNSでは加工されていない「リアル」な日常を好む傾向が強まっており、Vlogなどの形式が人気です。また、無加工のSNS「BeReal」が流行しており、真実を重視する姿勢が見られます。\n\n3. **シェアコスメの人気**: ジェンダーレスな化粧品や、恋人とシェアできるコスメが注目されています。特に、男性も美容に関心を持つようになり、カップルでのコスメ選びが増えています。\n\n4. **高品質な商品への支出**: Z世代は消費に慎重ですが、自分にとって価値のある商品には投資を惜しまない姿勢を持っています。人と被らない独自のスタイルを求める傾向があります。\n\n5. **オンラインとオフラインの融合**: オンラインで情報を収集しつつ、実店舗で実際に商品を確認する動きが強まっています。特に化粧品では、テクスチャーや色味を確認したいというニーズが高まっています。\n\nこれらのトレンドは、Z世代のライフスタイルや価値観を反映したものであり、今後の美容業界において重要な要素となるでしょう。より詳細な情報については、参考リンクから確認できます。 \n\n- [ライジング・コスメティックスの記事](https://note.com/gifted_cosmos968/n/nbb14d1129cff)\n- [マタイクの記事](https://mataiku.com/articles/trendnews-b01-20240701/)"
}
次にキーワードを抽出するLLM(extract_keywordsノード)を見てみると、以下の5つのキーワードを抽出していました。
trend_keywords:
- 自己表現
- リアルさ
- シェアコスメ
- 高品質
- オンラインとオフラインの融合
それっぽいキーワードが抽出されてますが、BeRealとかのキーワードとかも拾ってほしかったなと思いました。(抽出するキーワードが5つってのが少なかったかもしれません)
最後に広告文を生成するLLM(generate_adsノード)を見てみます。
以下のような5つの広告文を生成していました。
advertiser_name: BeautyTrend
campaign_name: 2024年美容トレンド
copy_texts:
- 自己表現を楽しむメイク
- リアルな美しさを追求
- シェアしたくなるコスメ
- 高品質で満足度UP
- オンラインで見つける理想
- オフラインで体験する美
広告主名とキャンペーンはまぁどうでもいいとして、広告文自体はなんだかいい感じなんじゃないでしょうか。
とりあえず実現したかったことはできている感じです。
おわりに
正直上記のコードはへんてこなところがたくさんあるでしょうし、LangChainやLangGraphの書き方もまだまだ理解が及んでいませんが、この程度のコード量でこれだけのことができることに驚きです。LangGraph楽しい。
おわり