はじめに
huggingfaceを使ったEncoder-Decoderモデルの練習の一貫として、BERT2BERTによる文章生成をやってみました。
BERT2BERTはEncoder-Decoderモデルの一種で、Encoder層もDecoder層もBERTのアーキテクチャーを採用したモデルのことを言います。
ただし、Decoder層のBERTは通常のBERTと以下の2点で異なります。
- 最初のMutil Head AttentionがMusked Multi Head Attenion(単方向)になってる
- MMHAとFFNの間にCross Attention層があり、Encoderの特徴量を受け取れるようになってる
アーキテクチャーはほぼほぼTransformerと同様の認識ですかね。この辺の構造も含めて、Encoder-DecoderモデルやBERT2BERTの理論的なお話やhuggingfaceを使った実装例はhuggingfaceの公式ブログが非常に細かくて参考になりますので、理論面や仕組みの説明はこちらをご参照ください。
今回の記事の内容は単に上記ブログを日本語データでやってみたらどうなるかをなぞってるだけです。
BERT2BERTの応用例としては、人工知能学会2021で以下のような内容が紹介されています。応用例としてとても参考になりますね。
それでは早速実装例の紹介に入ろうと思います。
データ準備
データはいつものようにlivedoorニュースコーパスを使います。ニュース本文を入力して、タイトルを生成するようなモデルを考えます。
ニュースコーパスは事前に以下のようにカテゴリー、タイトル、本文の3カラムでDataFrameにまとめた状態で用意していたものをロードしています。
(ただし今回はカテゴリーの値は使いません)
# 必要なライブラリは諸々最初にimportしておきます
import pickle
import pandas as pd
import datasets
from transformers import AutoTokenizer
from transformers import EncoderDecoderModel
from transformers import Seq2SeqTrainingArguments, Seq2SeqTrainer
from tqdm import tqdm
tqdm.pandas()
import matplotlib.pyplot as plt
import torch
import random
# 事前にlivedoorニュースコーパスをカテゴリー、タイトル、本文の3カラムでまとめたDataFrameを用意する
with open('./livedoor_data.pickle', 'rb') as r:
livedoor_df = pickle.load(r)
display(livedoor_df.sample(5))

データの文長を確認
公式ブログでもやってるように、扱うデータの文長(tokenizerによるtoken数)を確認しておきます。
tokenizer = AutoTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
# 本文の文字数を確認する
livedoor_df['body_len'] = livedoor_df['body'].progress_apply(lambda x: len(tokenizer.tokenize(x)))
# タイトルの文字数を確認する
livedoor_df['title_len'] = livedoor_df['title'].progress_apply(lambda x: len(tokenizer.tokenize(x)))
# 文字数の分布を確認しておく
plt.subplots(1,2, figsize=(15, 4))
plt.subplot(1,2,1)
plt.title('body length')
livedoor_df['body_len'].hist(bins=100)
plt.plot([512, 512], [0, 700])
plt.subplot(1,2,2)
plt.title('title length')
livedoor_df['title_len'].hist(bins=50)
print('本文の長さが512以内のデータ割合', livedoor_df.query('body_len <= 512').shape[0] / livedoor_df.shape[0])
# 0.385439262472885
print('タイトルの最大長さ', livedoor_df['title_len'].max())
# 74
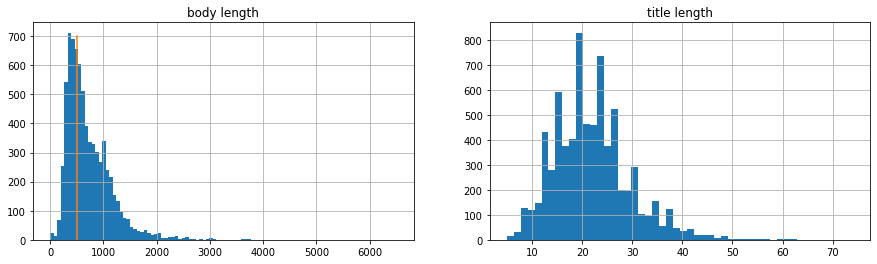
タイトルは最長でも74なので、BERTで扱う分には全然問題なしですね。
ただ、本文はニュース記事ともあって、BERTが受け付ける最大長512トークンを大幅に超えるデータがかなりありますね。公式ブログでも言及してますが、本来であれば、LongformerやXLNetなどの長い文章を扱えるアーキテクチャーにすべきかもしれませんが、今回はBERT2BERTの実装確認を重視するため、本文は先頭512トークンまでを扱い、それ以降は切り捨てとしましょう。
Dataset作成
以下の実装で、全データをtokenizerに通して、tensor型に変換しています。
こちらの実装はストックマーク社のBERT本を参考にしています。
BODY_MAX_LENGTH = 512
TITLE_MAX_LENGTH = livedoor_df['title_len'].max() + 2 # CLSトークンとSEPトークンを含めた最大長(74+2=76)
# 全データをtokenizerに通して、tensorに変換
encodings = []
for row in tqdm(livedoor_df.itertuples(), total=livedoor_df.shape[0]):
inputs = tokenizer(row.body, padding='max_length', truncation=True, max_length=BODY_MAX_LENGTH)
outputs = tokenizer(row.title, padding='max_length', truncation=True, max_length=TITLE_MAX_LENGTH)
inputs['decoder_input_ids'] = outputs['input_ids']
inputs['decoder_attention_mask'] = outputs['attention_mask']
inputs['labels'] = outputs['input_ids'].copy()
inputs['labels'] = [-100 if token == tokenizer.pad_token_id else token for token in inputs['labels']]
inputs = {k:torch.tensor(v) for k, v in inputs.items()}
encodings.append(inputs)
encodingsの中身はこんな感じになってます。
print(encodings[0])
# {'input_ids': tensor([ 2, 1055, 19, 213, 37, 40, 747, 955, 19, 127,・・・
# 'token_type_ids': tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,・・・
# 'attention_mask': tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,・・・
# 'decoder_input_ids': tensor([ 2, 9680, 2739, 6315, 679, 30664, 12101, 2010,・・・
# 'decoder_attention_mask': tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,・・・
# 'labels': tensor([ 2, 9680, 2739, 6315, 679, 30664, 12101, 2010, 7,・・・
# }
学習データと検証データに分けます。学習データ量を95%としてますが、単に少しでも学習用にデータを確保したかったのと、後続の検証ステップを短縮したかったためです。ちゃんと検証するためには8:2くらいにすべきですかね。
random.shuffle(encodings)
train_size = int(len(encodings)*0.95)
train_data = encodings[:train_size]
val_data = encodings[train_size:]
print('train size', len(train_data))
# train size 7007
print('val size', len(val_data))
# val size 369
BERT2BERTモデルを用意
いつも使うBertModelと同様に.from_pretrainedで事前学習済Encoder-Decoderモデルをロードできるようですが、もう1つのモデルの読み込み方法.from_enoder_decoder_pretrainedがあります。これはこれからEncoder-Decoderモデルを作成したい、という人向けに、効率的に事前学習を行うために使われるようで、Encoder層、Decoder層それぞれに事前学習済BERTモデルのパラメータをセットできます。
以下の例ではEncoder層、Decoder層の初期パラメータとして東北大乾研が作成された日本語BERTモデルをセットしています。
japanese_bert2bert = EncoderDecoderModel.from_encoder_decoder_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking',
'cl-tohoku/bert-base-japanese-whole-word-masking')
大量にwarning的なものがでます。(内容はこちら)
Some weights of the model checkpoint at cl-tohoku/bert-base-japanese-whole-word-masking were not used when initializing BertModel: ['cls.predictions.transform.dense.weight', 'cls.predictions.transform.dense.bias', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.decoder.weight', 'cls.seq_relationship.bias', 'cls.predictions.bias', 'cls.seq_relationship.weight']
- This IS expected if you are initializing BertModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of the model checkpoint at cl-tohoku/bert-base-japanese-whole-word-masking were not used when initializing BertLMHeadModel: ['cls.seq_relationship.bias', 'cls.seq_relationship.weight'] - This IS expected if you are initializing BertLMHeadModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertLMHeadModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of BertLMHeadModel were not initialized from the model checkpoint at cl-tohoku/bert-base-japanese-whole-word-masking and are newly initialized: ['bert.encoder.layer.7.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.2.crossattention.output.dense.weight', 'bert.encoder.layer.9.crossattention.self.query.bias', 'bert.encoder.layer.6.crossattention.self.query.bias', 'bert.encoder.layer.4.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.7.crossattention.self.key.bias', 'bert.encoder.layer.1.crossattention.self.value.bias', 'bert.encoder.layer.0.crossattention.self.key.bias', 'bert.encoder.layer.0.crossattention.self.query.bias', 'bert.encoder.layer.7.crossattention.output.dense.bias', 'bert.encoder.layer.4.crossattention.self.value.weight', 'bert.encoder.layer.10.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.11.crossattention.self.query.weight', 'bert.encoder.layer.5.crossattention.self.query.bias', 'bert.encoder.layer.1.crossattention.self.key.bias', 'bert.encoder.layer.0.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.0.crossattention.self.query.weight', 'bert.encoder.layer.1.crossattention.output.dense.bias', 'bert.encoder.layer.9.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.2.crossattention.self.key.weight', 'bert.encoder.layer.10.crossattention.self.key.weight', 'bert.encoder.layer.11.crossattention.self.value.bias', 'bert.encoder.layer.7.crossattention.self.value.weight', 'bert.encoder.layer.11.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.1.crossattention.self.query.bias', 'bert.encoder.layer.10.crossattention.output.dense.weight', 'bert.encoder.layer.1.crossattention.output.dense.weight', 'bert.encoder.layer.0.crossattention.output.dense.bias', 'bert.encoder.layer.5.crossattention.self.key.weight', 'bert.encoder.layer.2.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.9.crossattention.self.key.weight', 'bert.encoder.layer.8.crossattention.self.value.bias', 'bert.encoder.layer.0.crossattention.self.value.weight', 'bert.encoder.layer.6.crossattention.self.value.bias', 'bert.encoder.layer.3.crossattention.self.key.weight', 'bert.encoder.layer.9.crossattention.self.value.weight', 'bert.encoder.layer.5.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.9.crossattention.self.key.bias', 'bert.encoder.layer.11.crossattention.self.key.bias', 'bert.encoder.layer.11.crossattention.output.dense.bias', 'bert.encoder.layer.5.crossattention.self.query.weight', 'bert.encoder.layer.3.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.7.crossattention.output.dense.weight', 'bert.encoder.layer.4.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.9.crossattention.output.dense.bias', 'bert.encoder.layer.10.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.6.crossattention.self.key.weight', 'bert.encoder.layer.8.crossattention.self.key.bias', 'bert.encoder.layer.3.crossattention.self.value.bias', 'bert.encoder.layer.6.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.7.crossattention.self.query.weight', 'bert.encoder.layer.0.crossattention.self.value.bias', 'bert.encoder.layer.0.crossattention.self.key.weight', 'bert.encoder.layer.6.crossattention.output.dense.bias', 'bert.encoder.layer.2.crossattention.self.query.weight', 'bert.encoder.layer.10.crossattention.self.query.bias', 'bert.encoder.layer.6.crossattention.self.key.bias', 'bert.encoder.layer.4.crossattention.self.value.bias', 'bert.encoder.layer.9.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.4.crossattention.self.query.bias', 'bert.encoder.layer.1.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.6.crossattention.output.dense.weight', 'bert.encoder.layer.1.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.2.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.6.crossattention.self.value.weight', 'bert.encoder.layer.2.crossattention.output.dense.bias', 'bert.encoder.layer.11.crossattention.self.value.weight', 'bert.encoder.layer.7.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.9.crossattention.self.value.bias', 'bert.encoder.layer.9.crossattention.self.query.weight', 'bert.encoder.layer.3.crossattention.self.query.weight', 'bert.encoder.layer.5.crossattention.output.dense.bias', 'bert.encoder.layer.7.crossattention.self.key.weight', 'bert.encoder.layer.8.crossattention.output.dense.weight', 'bert.encoder.layer.2.crossattention.self.key.bias', 'bert.encoder.layer.8.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.5.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.4.crossattention.output.dense.weight', 'bert.encoder.layer.3.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.11.crossattention.self.query.bias', 'bert.encoder.layer.9.crossattention.output.dense.weight', 'bert.encoder.layer.4.crossattention.self.query.weight', 'bert.encoder.layer.1.crossattention.self.value.weight', 'bert.encoder.layer.8.crossattention.output.dense.bias', 'bert.encoder.layer.3.crossattention.self.query.bias', 'bert.encoder.layer.11.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.5.crossattention.self.value.bias', 'bert.encoder.layer.6.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.1.crossattention.self.query.weight', 'bert.encoder.layer.7.crossattention.self.value.bias', 'bert.encoder.layer.8.crossattention.self.key.weight', 'bert.encoder.layer.2.crossattention.self.value.bias', 'bert.encoder.layer.11.crossattention.self.key.weight', 'bert.encoder.layer.8.crossattention.self.value.weight', 'bert.encoder.layer.5.crossattention.self.key.bias', 'bert.encoder.layer.4.crossattention.self.key.weight', 'bert.encoder.layer.8.crossattention.self.query.weight', 'bert.encoder.layer.10.crossattention.output.dense.bias', 'bert.encoder.layer.0.crossattention.output.dense.weight', 'bert.encoder.layer.1.crossattention.self.key.weight', 'bert.encoder.layer.6.crossattention.self.query.weight', 'bert.encoder.layer.4.crossattention.output.dense.bias', 'bert.encoder.layer.10.crossattention.self.key.bias', 'bert.encoder.layer.10.crossattention.self.value.weight', 'bert.encoder.layer.3.crossattention.self.key.bias', 'bert.encoder.layer.3.crossattention.output.dense.bias', 'bert.encoder.layer.0.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.3.crossattention.output.dense.weight', 'bert.encoder.layer.8.crossattention.self.query.bias', 'bert.encoder.layer.4.crossattention.self.key.bias', 'bert.encoder.layer.3.crossattention.self.value.weight', 'bert.encoder.layer.8.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.10.crossattention.self.value.bias', 'bert.encoder.layer.2.crossattention.self.query.bias', 'bert.encoder.layer.7.crossattention.self.query.bias', 'bert.encoder.layer.10.crossattention.self.query.weight', 'bert.encoder.layer.5.crossattention.self.value.weight', 'bert.encoder.layer.5.crossattention.output.dense.weight', 'bert.encoder.layer.11.crossattention.output.dense.weight', 'bert.encoder.layer.2.crossattention.self.value.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
これを実行すると、大量のwarning的なものが出力されると思います。この辺はブログにも詳しく数式レベルでの説明がされていますが、Decoder層には日本語BERTモデルにはないCross Attention層があり、そのCross Attention層のパラメータは初期値をセットします、ということを言ってます。
それ以外のDecoder層は日本語BERTモデルのパラメータをセットしてくれているので、Encoder層Decoder層の内部のパラメータは一定の言語理解ができる状態からスタートすることになり、効率的にEncoderDecoderモデルの学習ができそうですね。
configの設定
ロードしたモデルのconfigにいくつかEncoderDecoderモデルの学習に必要なパラメータをセットします。
この辺は公式ブログを参考にしていますが、beam searchのパラメータはちょこちょこいじってます。この辺の勘所がよくわからんので、とりあえずえいやで設定しておきました。
# set special tokens
japanese_bert2bert.config.decoder_start_token_id = tokenizer.cls_token_id
japanese_bert2bert.config.eos_token_id = tokenizer.sep_token_id
japanese_bert2bert.config.pad_token_id = tokenizer.pad_token_id
# sensible parameters for beam search
japanese_bert2bert.config.vocab_size = japanese_bert2bert.config.decoder.vocab_size
japanese_bert2bert.config.max_length = 100
japanese_bert2bert.config.min_length = 20
japanese_bert2bert.config.no_repeat_ngram_size = 1
japanese_bert2bert.config.early_stopping = True
japanese_bert2bert.config.length_penalty = 2.0
japanese_bert2bert.config.num_beams = 20
評価関数の用意
学習時の評価データ用のメトリクスの設定を行います。公式ブログでは要約タスクを扱っているので要約タスクに使われるROUGEという指標をメトリクスとして設定しています。
タイトル生成もまぁ要約みたいなもんか、と思ったので、公式ブログの内容をそのまま拝借しています。
ROUGEについては以下の記事がとても参考になると思います。
rouge = datasets.load_metric("rouge")
def compute_metrics(pred):
labels_ids = pred.label_ids
pred_ids = pred.predictions
pred_str = tokenizer.batch_decode(pred_ids, skip_special_tokens=True)
labels_ids[labels_ids == -100] = tokenizer.pad_token_id
label_str = tokenizer.batch_decode(labels_ids, skip_special_tokens=True)
rouge_output = rouge.compute(predictions=pred_str, references=label_str, rouge_types=["rouge2"])["rouge2"].mid
return {
"rouge2_precision": round(rouge_output.precision, 4),
"rouge2_recall": round(rouge_output.recall, 4),
"rouge2_fmeasure": round(rouge_output.fmeasure, 4),
}
学習パラメータの設定
Encoder-Decoderモデルを学習させるときは、Seq2SeqTrainerクラスを使います。BERTモデルの事前学習に使うTrainerクラスと同様の使い方ができます。
こちらも公式ブログを参考に今回は以下のように設定しました。
BERTモデルが2つ連結しているような構造をしているのでかなりメモリを消費します。下記の例では概ね60GBのGPUメモリを消費しました。
colabなどで回す場合はper_device_train_batchは6くらいが限度ですかね。6で約10GB消費しました。
各パラメータの詳細は公式リファレンスに委ねることとします。
training_args = Seq2SeqTrainingArguments(
output_dir='./',
evaluation_strategy="steps",
per_device_train_batch_size=16,
per_device_eval_batch_size=8,
predict_with_generate=True,
logging_steps=10,
save_steps=500,
eval_steps=300,
warmup_steps=1000,
overwrite_output_dir=True,
save_total_limit=3,
fp16=True,
num_train_epochs=10
)
# instantiate trainer
trainer = Seq2SeqTrainer(
model=japanese_bert2bert,
tokenizer=tokenizer,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=train_data,
eval_dataset=val_data,
)
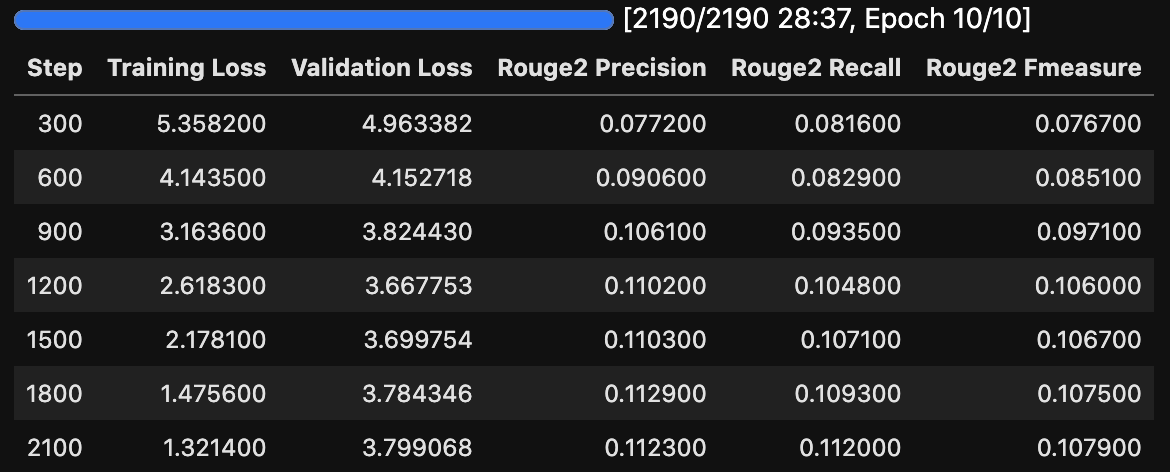
trainer.train()で学習を開始できます。Seq2SeqTrainingArgumentsのeval_stepsで指定したステップ毎にROUGEスコアの値をeval_datasetから算出してくれます。
trainer.train()
# TrainOutput(global_step=2190, training_loss=3.3364614382182083,metrics={'train_runtime': 1722.4901, 'train_samples_per_second': 40.679, 'train_steps_per_second': 1.271, 'total_flos': 4.936563987683328e+16, 'train_loss': 3.3364614382182083, 'epoch': 10.0})
タイトルの生成
学習が終わったので、早速ニュース記事からタイトルを生成してもらいましょう。
まずは手始めにvalidatioin dataとして学習から避けておいたデータをランダムにピックアップして、タイトルを生成させてみます。
生成方法は.generate()関数で簡単にできます。今回は10件生成させてみました。
(生成数を指定するnum_return_sequencesはconfigに設定したnum_beams以下である必要があります。)
random.shuffle(val_data)
sample_data = val_data[0]
input_ids = sample_data['input_ids'].unsqueeze(0).cuda()
label_ids = sample_data['labels'].unsqueeze(0)
attention_mask = sample_data['attention_mask'].unsqueeze(0).cuda()
print('【本文】')
print(tokenizer.batch_decode(input_ids, skip_special_tokens=True)[0].replace('。', '。\n').replace(' ', ''))
print('-'*30)
print('【タイトル】')
print(tokenizer.batch_decode(label_ids, skip_special_tokens=True)[0].replace(' ', ''))
out = japanese_bert2bert.generate(input_ids, attention_mask=attention_mask,
num_return_sequences=10, top_p=0.95, top_k=40, no_repeat_ngram_size=1)
output_str = tokenizer.batch_decode(out, skip_special_tokens=True)
print('-'*30)
print('【生成タイトル】')
print(output_str)
【本文】
1月末の深夜、マンションの駐車場で転倒して右腕をひどく擦りむいた麻美さん(28歳)。
消毒薬などがなかったことから、近くの病院の救急外来にお世話になったのだが...。
「医者からは『この程度なら家でケアできるでしょう』って嫌みを言われました。
それに、救急外来って高いんですよね。
まあ、それでもケガは大したことなかったし、化膿することもなかったので助かりましたが...」と話してくれた。
「自宅に薬や湿布などが無くてちょっとしたケガや病気に対応できなかった」という話はときどき耳にする。
麻美さんの体験談は人ごとではないのだ。
特に、自分以外に頼る人がいない一人暮らし場合は、救急箱の中身をキチン確認して、必要なものを揃えておきたい。
市販の救急セット(応急用)を調べたところ、消毒液、消毒用のウェットティッシュ、絆創膏、傷あてパット、綿棒5・滅菌ガーゼ、コットンなどが入っていた。
ちょっとした旅行ならこれで十分なのかもしれないが、家に置くならもう少し充実させたい。
ドラッグストアに勤務する薬剤師・真澄さんにアドバイスをお願いした。
「まずは、体温計と冷却ジェルシート(冷えピタなど)、包帯や湿布も揃えておきたいですね。
最近は、重ねて巻くだけでくっつく包帯などもあります。
利き手をケガしたときなどはとても便利です。
湿布はひどい肩こりや筋肉痛のときにも使えます。
あとは包帯などを切る小さいハサミやトゲヌキなども一緒にあると便利です」東日本大震災の際、家まで数時間かけて徒歩で帰宅した人の中には「脚が痛くて眠れなかった」という人も多かった。
その晩使うだけでも湿布があったなら、だいぶ痛みも楽になっただろう。
次に、救急箱に入れておきたい「薬」について真澄さんに伺った。
「お薬は人によって違いがありますが、基本的には胃腸薬や整腸剤、風邪薬
------------------------------
【タイトル】
チェックしよう!一人暮らしの救急箱
# paddingを-100に置き換えていたので大量に[UNK]が出ますが、こちらでは削除しています。
------------------------------
【生成タイトル】
['「 気 を つけ て!」 と 言わ れる 人 が 多数 いる! あなた の 手ぶら マッサージ 体験 法',
'「 気 を つけ て!」 と 言わ れる 人 が 多数 いる! あなた の 心臓 マッサージ 術 って なに?',
'「 気 を つけ て!」 と 言わ れる 人 が 多数 いる! あなた の 手ぶら マッサージ 体験 サイト',
'「 気 を つけ て!」 と 言わ れる 人 が 多数 いる! あなた の 心臓 マッサージ 術 って どう?',
'「 気 を つけ て!」 と 言わ れる 人 が 多数 いる! あなた の 手ぶら マッサージ 体験 記',
'「 気 を つけ て!」 と 言わ れる 人 が 多数 いる! あなた の お 手 に は アリ?',
'「 気 を つけ て!」 と 言わ れる 人 が 多数 いる! あなた の 手ぶら マッサージ 室',
'「 気 を つけ て!」 と 言わ れる 人 が 多数 いる! 既婚 者 の お 手入れ 術',
'「 気 を つけ て!」 と 言わ れる 人 が 多数 いる! あなた の 心臓 マッサージ 術 って?',
'「 気 を つけ て!」 と 言わ れる 人 が 多数 いる! あなた の お 手入れ 術']
本文が途中で切れてますが、正解タイトルを生成するのに必要な情報は含まれているように感じます。
生成された文章を見てみると、全然微妙ですね。。。マッサージなんで言ってないし。最初の「気をつけて!」ってあたりは後続のテキストによっては今回の記事のタイトルっぽいフレーズになりそうですが。
せっかくなので、最近のlivedoorニュース記事を拝借してタイトル生成も行ってみましょう。
text = '''
楽天の田中将大投手(33)が8日、自身の公式インスタグラムを更新し、今シーズンの思いをつづった。
楽天はシーズン3位でクライマックスシリーズのファーストステージに進出も、2位ロッテに6日の第1戦4―5、7日の第2戦4―4の1敗1分けで敗退。第3戦の先発予想だった田中は出番がなく日本球界復帰1年目を終えた。
田中は「昨日、楽天イーグルスの2021年シーズンが目標にしていた所に届かず終わりを迎えました」と報告。「このような大変な状況の中でも最後まで試合が無事に出来た事、サポートをしてくださった方々、応援してくださった方々には感謝しかありません!ありがとうございました」と感謝を記した。
だが、最後に「悔しい!俺は悔しいよ」と本音をつづって締めた。
'''
actual_title = "楽天・マー君「悔しい!俺は悔しいよ」 日本球界復帰1年目を終え「応援してくださった方々には感謝」も"
input_ids = tokenizer(text, truncation=True, max_length=512, return_tensors='pt')['input_ids'].cuda()
out = japanese_bert2bert.generate(input_ids, num_return_sequences=10, top_p=0.95, top_k=40, no_repeat_ngram_size=1)
output_str = tokenizer.batch_decode(out, skip_special_tokens=True)
print('【本文】')
print(text)
print('-'*30)
print('【実際のタイトル】')
print(actual_title)
print('-'*30)
print('【生成タイトル】')
print(output_str)
【本文】
楽天の田中将大投手(33)が8日、自身の公式インスタグラムを更新し、今シーズンの思いをつづった。
楽天はシーズン3位でクライマックスシリーズのファーストステージに進出も、2位ロッテに6日の第1戦4―5、7日の第2戦4―4の1敗1分けで敗退。第3戦の先発予想だった田中は出番がなく日本球界復帰1年目を終えた。
田中は「昨日、楽天イーグルスの2021年シーズンが目標にしていた所に届かず終わりを迎えました」と報告。「このような大変な状況の中でも最後まで試合が無事に出来た事、サポートをしてくださった方々、応援してくださった方々には感謝しかありません!ありがとうございました」と感謝を記した。
だが、最後に「悔しい!俺は悔しいよ」と本音をつづって締めた。
------------------------------
【実際のタイトル】
楽天・マー君「悔しい!俺は悔しいよ」 日本球界復帰1年目を終え「応援してくださった方々には感謝」も
------------------------------
【生成タイトル】
['【 Sports Watch 】 楽天 ・ 田中 、 引退 宣言 を 表明 し た 理由 と は?',
'【 Sports Watch 】 楽天 ・ 田中 、 無念 の プレー を 報告 し た 理由 と は?',
'【 Sports Watch 】 楽天 ・ 田中 、 無念 の プレー を 報告 し た 理由 は?',
'【 Sports Watch 】 楽天 ・ 田中 、 無念 の プレー に 「 僕 は 普通 です ね 」',
'【 Sports Watch 】 楽天 ・ 田中 、 無念 の プレー に 「 僕 は 普通 です けど ね 」',
'【 Sports Watch 】 楽天 ・ 田中 、 引退 宣言 を 表明 し た 理由 は?',
'【 Sports Watch 】 楽天 ・ 田中 、 無念 の プレー に 「 僕 は 諦め ない です ね 」',
'【 Sports Watch 】 楽天 ・ 田中 、 無念 の プレー を 報告 し た こと に は?',
'【 Sports Watch 】 楽天 ・ 田中 、 無念 の プレー に 「 僕 は 普通 です けど......」',
'【 Sports Watch 】 楽天 ・ 田中 、 無念 の プレー に 「 僕 は 諦め ない です けど 」']
実態のタイトルとは程遠いですし、マー君日本に戻ってきて1年目でもう引退宣言したことになっちゃってますね。とんでもないデマタイトルが生成されてしまいました。。。
ただ「無念のプレー」や「僕は諦めてない」といったフレーズはタイトルに使えそうな感じがします。
おわりに
正直生成文章はとてもイマイチな結果になりました。データ量が少ないでしょうし、学習の仕方ももう少し工夫が必要なのかもしれません。
前回の記事ではGPT-2を使って同様にニュース記事のタイトル生成をやってみましたが、GPT-2のほうが日本語が流暢だったなぁという印象です。
ともあれ、BERT2BERTを動かすことはできたっぽいので、これを機にいろんなデータでBERT2BERTを動かしてみたいです。
おわり