機械学習プロフェッショナルシリーズ「統計的因果探索」の最後にソフトウェアとしていろんなLiNGAMアプローチを扱ったソースコードが紹介されています。
今回はその中からLiNGAMのベイズ的アプローチである「BayesLiNGAM」を動かして見ます。
BayesLiNGAMの理論についてはこれから勉強します。(とりあえずまずは動かしたかった)
BayesLiNGAMに関連する参考文献を挙げておきます。
- BayesLiNGAMのホームページ?
- 元論文
- [潜在クラスが存在する場合のベイズ的アプローチによる非ガウス因果構造推定法(PDFファイルがダウンロードされます)]
(https://jsai.ixsq.nii.ac.jp/ej/index.php?action=pages_view_main&active_action=repository_action_common_download&item_id=335&item_no=1&attribute_id=1&file_no=1&page_id=13&block_id=23) - LiNGAMを用いた因果関係同定による工数データセットの分析
- A→Bなのか、B→Aなのかをデータから見抜くことはできるだろうか?(LiNGAMのシミュレーションをしてみた)
パッケージのインストール
BayesLiNGAMのホームページ的なところにRのソースコードが置いてあるので、それをダウンロードします。
R上で以下のコマンドでインストールを試みる。
> install.packages("bayeslingam.tar.gz", repos=NULL, type="source")
ERROR: cannot extract package from ‘bayeslingam.tar.gz’
警告メッセージ:
install.packages("bayeslingam.tar.gz", repos = NULL, type = "source") で:
パッケージ ‘bayeslingam.tar.gz’ のインストールは、ゼロでない終了値をもちました
うまくインストールできません。どうやらソースの中身のパスの指定がおかしいようで、手動で書き換える必要があるようです。
以下のNagoya.RというRの勉強会の発表スライドにbayeslingamの動かし方が載っています。非常に助かりました。しかもBayesLiNGAMのユースケースまで書かれています。
因果分析LiNGAMを試してみた
ということで、上記のスライドのようにソースコードを書き換えていきます。
loud.R
元ファイル(bayeslingam/main/loud.R)
cauzality_path<<-"./../.."
loud<-function() {
source(sprintf('%s%s',cauzality_path,"/trunk/bayeslingam/loadbayeslingam.R"))
loadbayeslingam()
}
以下のように書き換えました。
cauzality_path<<-"/Users/(作業ディレクトリ)/bayeslingam"
loud<-function() {
source(sprintf('%s%s',cauzality_path,"/bayeslingam/loadbayeslingam.R"))
loadbayeslingam()
}
loadbayeslingam.R
元ファイル(bayeslingam/bayeslingam/loadbayeslingam.R)
# datadir<<-'/home/ajhyttin/svn/bayeslingam/trunk/personal/antti'
# this function loads all directories needed for the bayeslingam article project
loadbayeslingam <- function( ... ) {
#if cauzality_part is foun
if ( any( ls(envir=globalenv()) == "cauzality_path" ) ) {
common_dir<-sprintf("%s/trunk/common",cauzality_path)
bayeslingam_dir<-sprintf("%s/trunk/bayeslingam",cauzality_path)
rbayeslingam_dir<-sprintf("%s/trunk/bayeslingam/rbayeslingam",cauzality_path)
rlingam_dir<-sprintf("%s/trunk/rlingam",cauzality_path)
rdeal_dir<-sprintf("%s/trunk/rdeal",cauzality_path)
rpc_dir<-sprintf("%s/trunk/rpc",cauzality_path)
etudag_dir<-sprintf("%s/trunk/ETUDAG",cauzality_path)
}
source(sprintf("%s/sourcedir.R",common_dir))
sourceDir(bayeslingam_dir, trace=FALSE) #bayeslingam directory
sourceDir(rbayeslingam_dir, trace=FALSE) #the algorithm directory
sourceDir(rlingam_dir, trace=FALSE)
sourceDir(rdeal_dir, trace=FALSE)
sourceDir(rpc_dir, trace=FALSE)
sourceDir(common_dir, trace=FALSE)
sourceDir(etudag_dir, trace=FALSE)
}
以下のように書き換えました。(/trunkを消しただけ)
# datadir<<-'/home/ajhyttin/svn/bayeslingam/trunk/personal/antti'
# this function loads all directories needed for the bayeslingam article project
loadbayeslingam <- function( ... ) {
#if cauzality_part is foun
if ( any( ls(envir=globalenv()) == "cauzality_path" ) ) {
common_dir<-sprintf("%s/common",cauzality_path)
bayeslingam_dir<-sprintf("%s/bayeslingam",cauzality_path)
rbayeslingam_dir<-sprintf("%s/bayeslingam/rbayeslingam",cauzality_path)
rlingam_dir<-sprintf("%s/rlingam",cauzality_path)
rdeal_dir<-sprintf("%s/rdeal",cauzality_path)
rpc_dir<-sprintf("%s/rpc",cauzality_path)
etudag_dir<-sprintf("%s/ETUDAG",cauzality_path)
}
source(sprintf("%s/sourcedir.R",common_dir))
sourceDir(bayeslingam_dir, trace=FALSE) #bayeslingam directory
sourceDir(rbayeslingam_dir, trace=FALSE) #the algorithm directory
sourceDir(rlingam_dir, trace=FALSE)
sourceDir(rdeal_dir, trace=FALSE)
sourceDir(rpc_dir, trace=FALSE)
sourceDir(common_dir, trace=FALSE)
sourceDir(etudag_dir, trace=FALSE)
}
実行
以下のライブラリを要求されます。Nagoya.RのスライドによるとfastICAだけあればとりあえずは動くようです。
要求ライブラリ
- 'deal' for GH-algorithm
- 'mclust' for MoG Bayeslingam
- 'combinat' for PC-algorithm
- 'ggm' for PC-algorithm
- 'fastICA' for standard LiNGAM
- 'gtools' some method's in ETUDAG use this package
R上でこんな感じで必要なライブラリをインストール
install.packages("fastICA", dependencies=TRUE)
因果グラフ
以下の因果グラフをBayesLiNGAMで推定してみようと思います。(外生変数は省略)

library('fastICA')
source('bayeslingam/main/loud.R')
loud()
x <- runif(1000,0,1)
y <- x + runif(1000,0,1)
z <- y + runif(1000,0,1)
w <- x + z + runif(1000,0,1)
d <- data.frame(x1=x, x2=y, x3=z, x4=w)
result <- bayeslingam(d)
なんか大量に出力されます。どうやら考えられる因果グラフを全て確率付きで出力しているようです。
Rに不慣れなのか、グラフ理論知らないからのかわかりませんが、最初、肝心の出力の見方が全然わかりませんでした。
result$DAGsを見れば良いのですが、そのフォーマットの意味がさっぱりでした。とりあえずDAG(有向非巡回グラフ、Directed acyclic graph)あたりで片っ端からググると、どうやらresult$DAGsはトポロジカル・ソートというルールで記載されていることがわかりました。
出力の見方
result <- bayeslingam(d)を実行した時点で大量に出力される内容のうち、以下のようなresult$DAGs(下記の1列〜10列)とresult$prob(下記の11列)に注目します。
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11]
〜省略〜
[46,] 1 2 3 4 1 0 1 1 0 1 9.511035e-01
〜省略〜
[189,] 3 2 1 4 1 0 1 1 0 0 3.055634e-202
〜省略〜
[530,] 4 3 1 2 1 1 0 1 0 1 6.300945e-233
〜省略〜
1列目〜4列目: 各変数を1列に並べた時の並び順を表します。例えば上記の189行目は z, y, x, w を意味します。
5列目〜10列目:有向線の有無を0,1で表しています。1列目〜4列目で並べた変数から左の変数への有向線の有無を表します。例えば、189行目であれば、5列目が1なのでz->y, 6列目が0なのでzからxへの有向線なし, 7列目が1なのでz->w, 8列目が1なのでy->x, 9列目が0なのでyからwへの有向線なし, 10列目が0なのでxからwへの有向線なし、つまり以下のような因果グラフを表します。

11列目はその行が表す因果グラフである推定確率を表します。
変数が4つもあると、どの因果グラフがもっとも確率高いか、因果グラフがどうなっているかがよくわかりませんが、先ほどのNagoya.Rのスライドでは綺麗にボルツマンマシンのような絵で出力させるスクリプトも用意されており、非常に便利です。
library(igraph)
par(mfrow=c(2,3))
prob <- round(result$prob,digits=4) * 100
n.node <- max(result$components$node)
case <- nrow(result$DAGs)
node <- result$DAGs[,1:n.node]
res <- as.matrix(result$DAGs[,-c(1:n.node)],nrow=case)
name <-paste("X",1:n.node,sep="")
for(i in order(prob,decreasing=T)[1:6]){
amat <- matrix(0,n.node,n.node)
index <- node[i,]
amat[lower.tri(amat,diag=FALSE)] <- res[i,]
amat <- t(amat[index,index])
g <- graph.adjacency(amat,mode="directed")
E(g)$label <- NA
pos <- layout.circle(g)
rot <- matrix(c(0,1,-1,0),nrow=2,byrow=T)
la <- pos %*% rot
if(n.node == 2)la <- matrix(c(-1,0.5,1,0.5),,nrow=2,byrow=T)
plot(g,layout=la,vertex.size=70,vertex.label=name)
mtext(paste(prob[i],"%"),line=0)
}
これによる出力が以下となりました。(x1=x, x2=y, x3=z, x4=w)
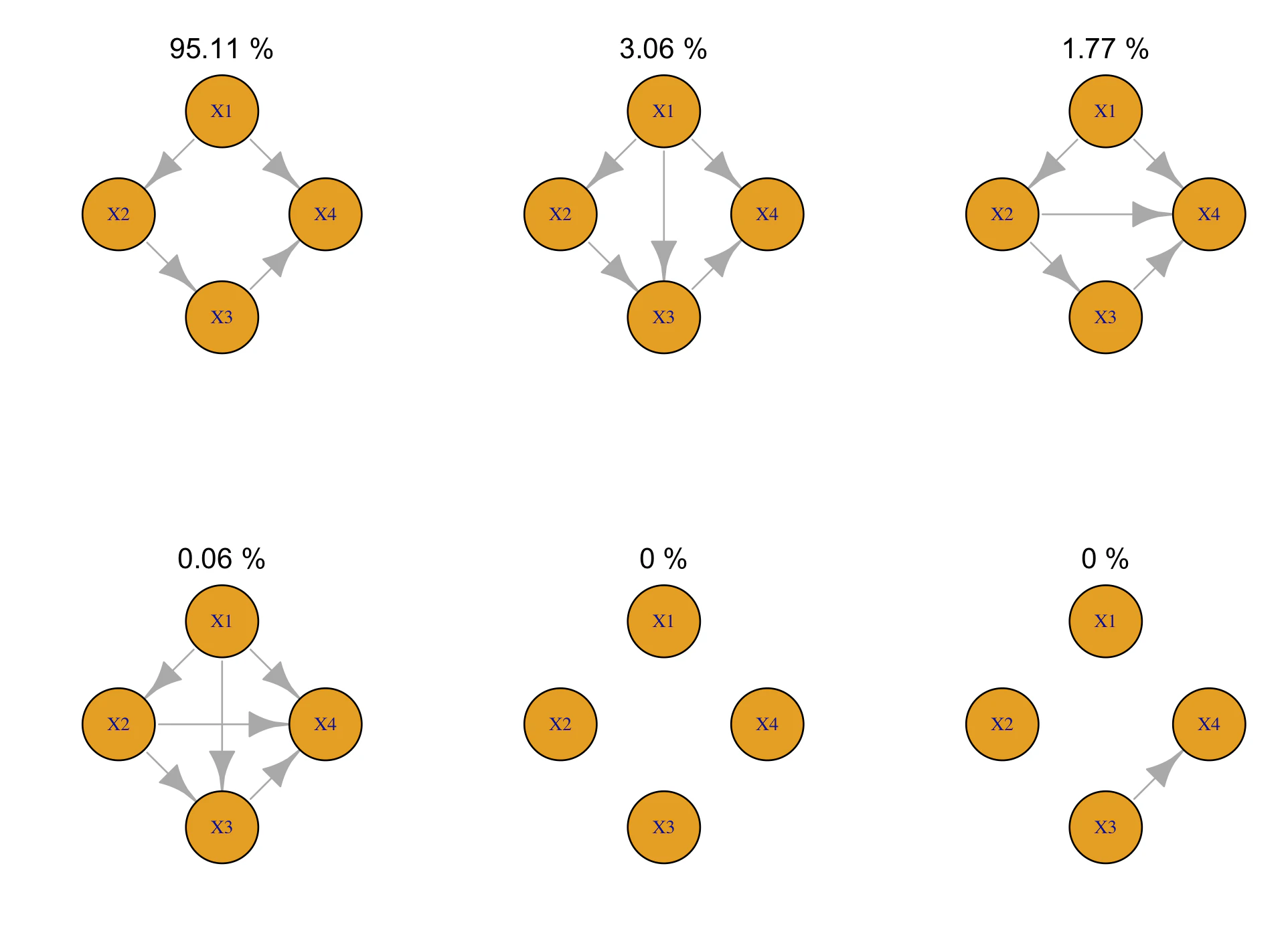
95.11%で因果グラフを特定しています。ズバリ因果関係を的中できたといってよいでしょう。
終わりに
LiNGAMの発展系の1つであるBayesLiNGAMを実行してみました。次こそは実データを扱いたい...
一点気になることとして、
このBayesLiNGAMは因果の強さまでは推定できるのだろうか?いろいろ動かして見ましたが、因果の強さを推定している出力があるのかよくわかりませんでした。(知っている方いらしたらぜひ教えてください。)
実務的なことを考えると、因果を特定してどの変数に対してアプローチすればいいかまでわかったとしてもそれに優先順位つけるために因果の強さまで特定できたほうがいいなぁと思いました。因果は特定できたけど、実は因果の強さはそんなに対したことない、みたいなこともあったりするかも。