はじめに
こちらは「生成AIを使った仕組みを考えてみた 第1回:アイデア出し編」の続きとなります。この記事では、前回考えたAWSサービスを用いて旅行プランを自動生成する仕組みの以下赤枠の箇所を解説します。
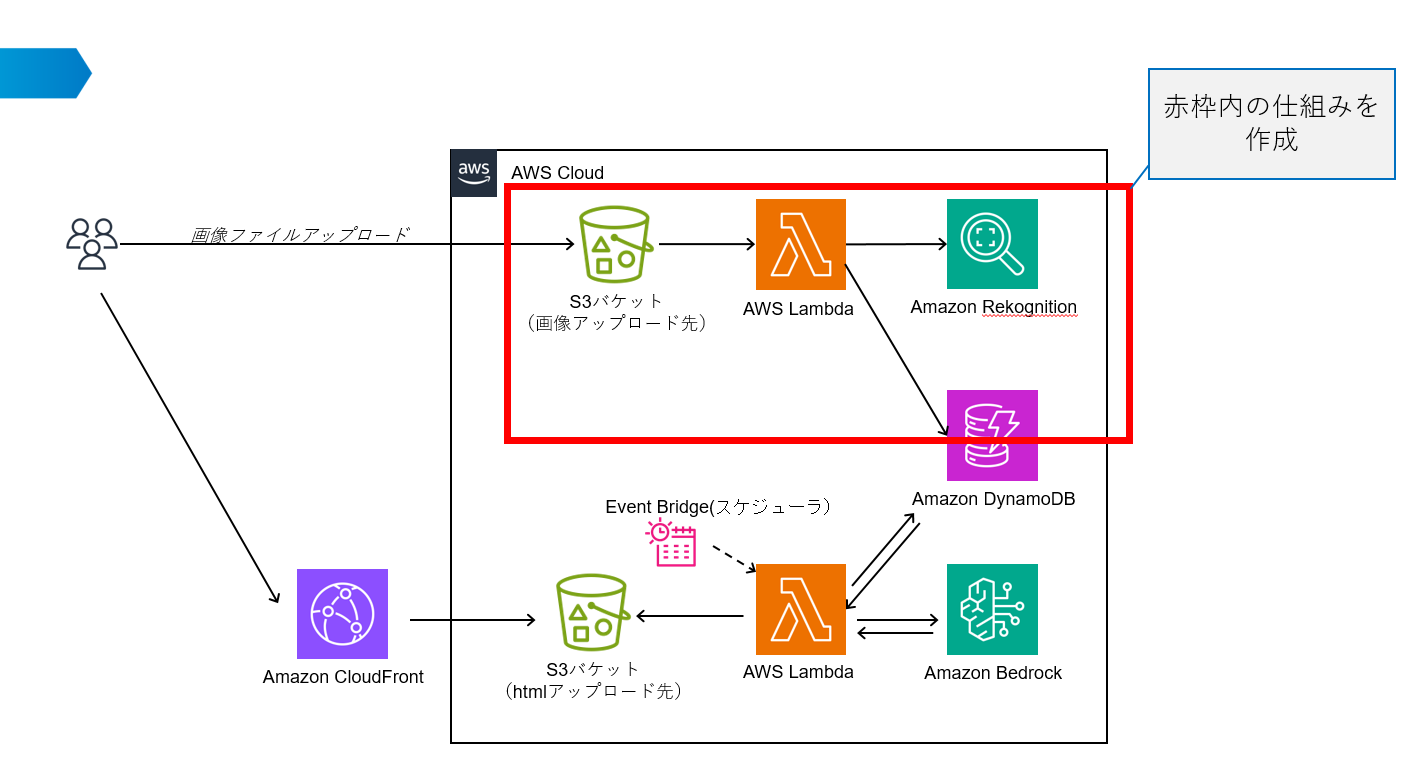
この記事では、赤枠内のAWSサービスを用いた旅行写真の解析とデータ蓄積を行う方法について詳しく解説します。大まかな作業順は以下の通りです。
- 写真データをアップロードするS3バケットの作成
- 分析した情報を保持するためのDynamoDBの作成
- LambdaとRekognitionを用いた画像解析処理の作成
- 動作確認
- まとめ
では次の章から実際に作り進めていきます
写真データをアップロードするS3バケットの作成
分析する画像を格納するためのS3バケットを作成します。
-
AWSマネジメントコンソールにログイン:
- AWS マネジメントコンソールにアクセスし、アカウントにログインします。
-
S3サービスを開く:
- コンソールの上部にある検索バーで「S3」と入力し、表示された「S3」サービスをクリックします。

- コンソールの上部にある検索バーで「S3」と入力し、表示された「S3」サービスをクリックします。
-
新しいバケットの作成:
- S3ダッシュボードの右上にある「バケットを作成」ボタンをクリックします。
-
バケット設定の指定:
基本的にはバケット名とリージョンを確認したら他はデフォルト設定で問題ありません。設定を確認したら「バケットを作成」ボタンを押下して新規S3バケットを作成します。- バケット名:一意の名前を指定します。バケット名はグローバルで一意である必要があります。このあとの手順で名称を入力するため、指定した名前を控えておきます。
-
リージョン:データを保存するリージョンを選択します。この後の手順で作成するDynamoDB、Lambdaとリージョンを一致させる必要があります。

分析した情報を保持するためのDynamoDBの作成
分析したデータを保存するためのDBを作成します。
-
DynamoDBサービスを開く:
- コンソールの上部にある検索バーで「DynamoDB」と入力し、表示された「DynamoDB」サービスをクリックします。
-
テーブルの作成:
- DynamoDBダッシュボードの左側にある「テーブル」メニューをクリックし、「テーブルを作成」を選択します。
-
テーブルの設定:
- テーブル名:一意の名前を指定します。このあとの手順で名称を入力するため、指定した名前を控えておきます。
- パーティションキーの設定:テーブルの主キー(パーティションキー、及び必要に応じてソートキー)を設定します。このあとの手順で、S3バケットにアップロードした画像ファイルのキーを格納するようにします。任意の名称でも構いませんが、後手順のPythonコードをそのまま利用する場合はimageという名称で作成してください。
- ソートキーの設定:プライマリーキーの2番目として設定します。任意の指定をしても構いませんが、後手順のPythonコードをそのまま利用する場合はlabelという名称で作成してください。

LambdaとRekognitionを用いた画像解析処理の作成
S3バケットに格納した画像をRekognitionで分析し、分析結果をDynamoDBに格納する処理を作成します。
AWS Lambda関数を新規に作成する手順は以下の通りです:
-
Lambdaサービスを開く:
- コンソールの上部にある検索バーで「Lambda」と入力し、表示された「Lambda」サービスをクリックします。
-
関数の作成:
- Lambdaダッシュボードの「関数」をクリックし、「関数の作成」ボタンを選択します。
-
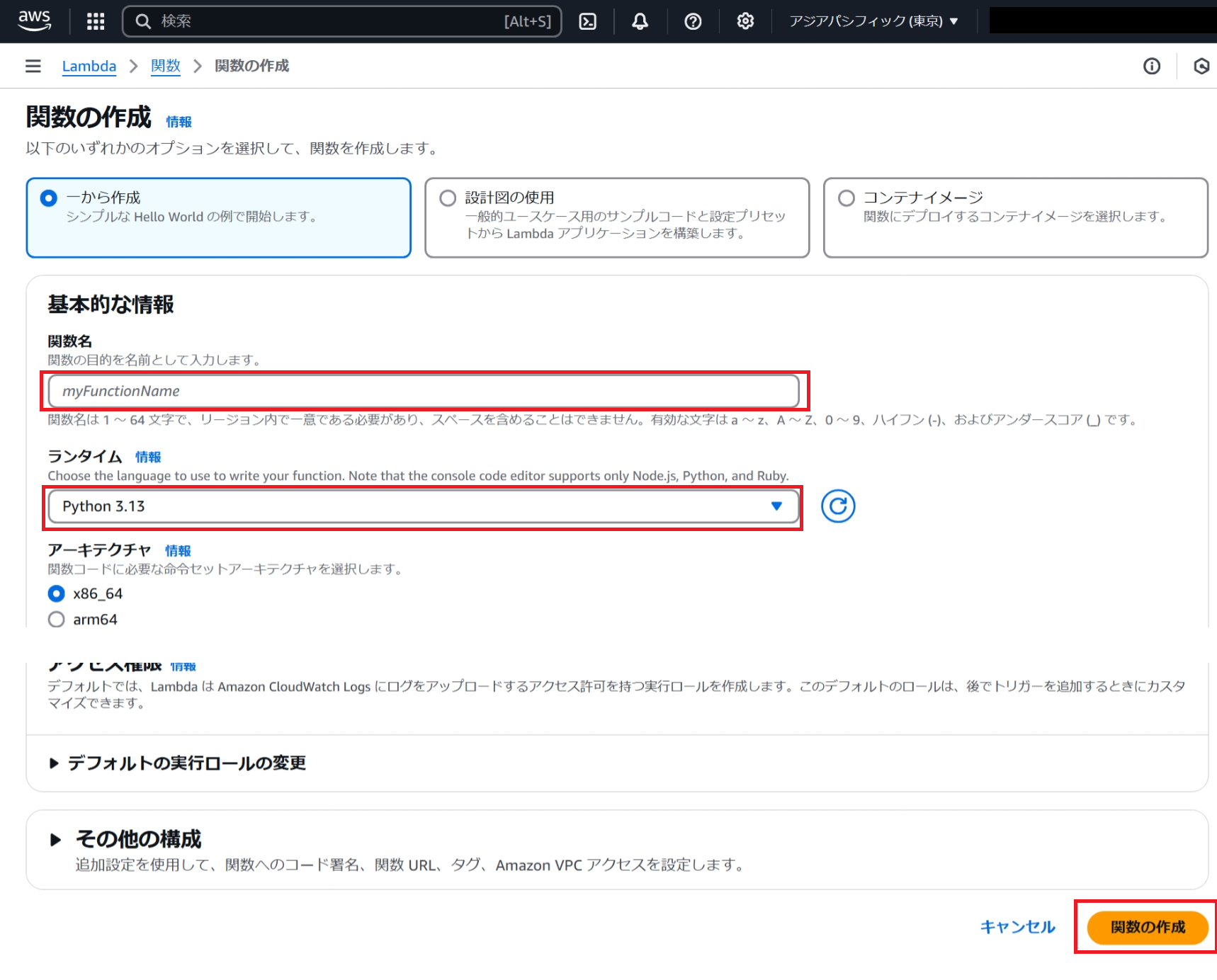
関数の設定:
以下の設定を行い「関数の作成」ボタンを押下します。- 関数の作成方法:いくつかのオプションの中から「一から作成」を選択します。
- 関数名:新しいLambda関数に一意の名前を付けます。
- ランタイム:関数のコードを実行するプログラミング言語を選択します(例:Python、Node.js、Java、など)。後続手順のPythonコードをそのまま利用する場合は、「Python 3.13」を選択します。
-
コードを書く:
新規作成したLambda関数を開きます。
画面をスクロールし「コード」タブを開き、デフォルトで作成されているlambda_function.pyファイルを開きます。(画像赤枠部分)
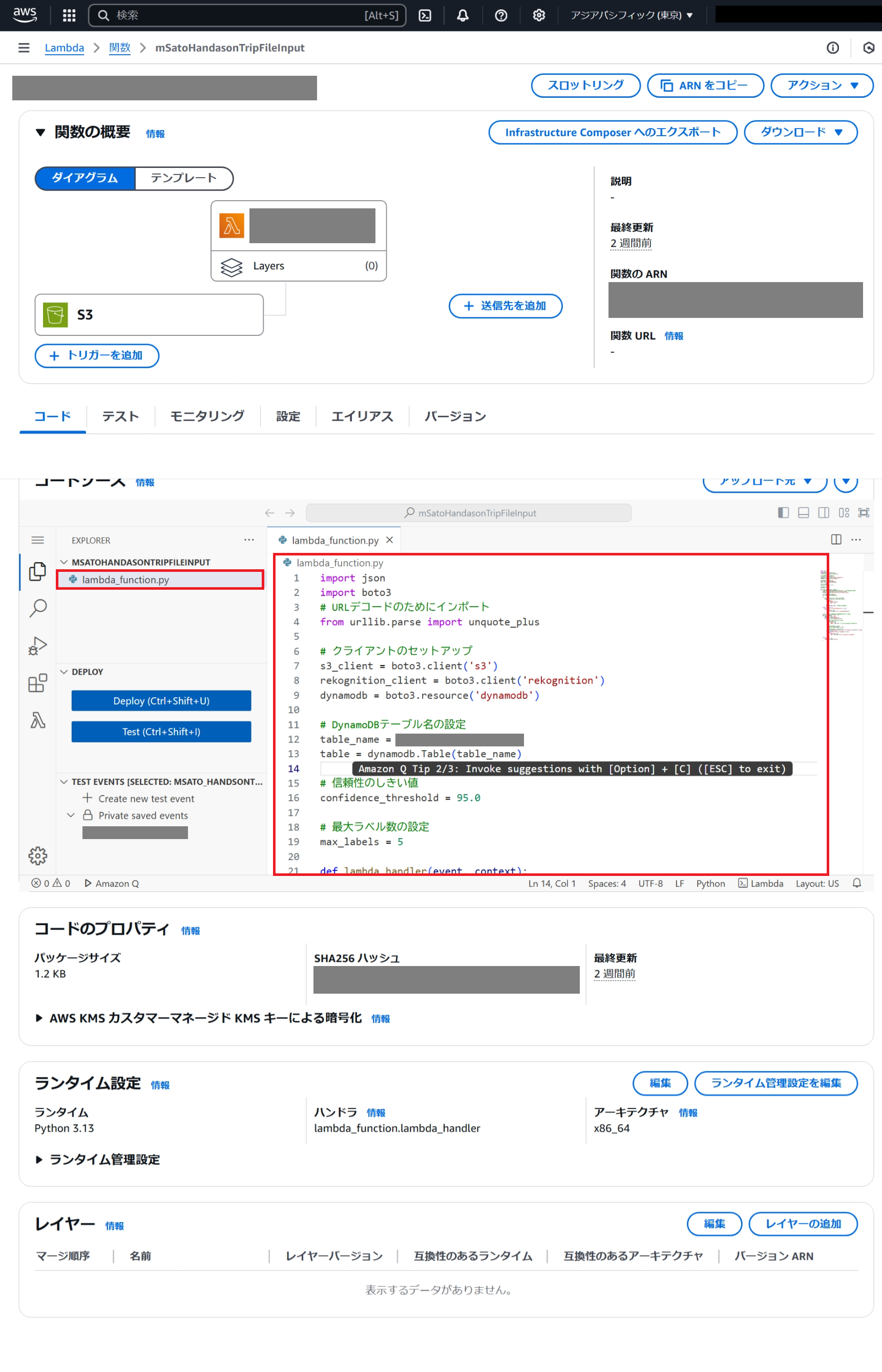
lambda_function.pyの中身を、以下のコードにすべて書き換えます。そのままコピー&ペーストします。
import json
import boto3
# URLデコードのためにインポート
from urllib.parse import unquote_plus
# クライアントのセットアップ
s3_client = boto3.client('s3')
rekognition_client = boto3.client('rekognition')
dynamodb = boto3.resource('dynamodb')
# DynamoDBテーブル名の設定
table_name = 'DynaoDB名称'
table = dynamodb.Table(table_name)
# 信頼性のしきい値
confidence_threshold = 95.0
# 最大ラベル数の設定
max_labels = 5
def lambda_handler(event, context):
# S3イベント情報からバケット名とエンコードされたオブジェクトキーを取得
bucket = event['Records'][0]['s3']['bucket']['name']
encoded_key = event['Records'][0]['s3']['object']['key']
# オブジェクトキーのデコード
key = unquote_plus(encoded_key)
try:
# Rekognitionを使って画像からラベルを解析
response = rekognition_client.detect_labels(
Image={
'S3Object': {
'Bucket': bucket,
'Name': key,
}
},
MaxLabels=max_labels, # 最大ラベル数を指定
)
except Exception as e:
print(f"Error in calling Rekognition: {str(e)}")
return {
'statusCode': 500,
'body': json.dumps('Error in calling Rekognition')
}
# 検出されたラベルを取得(信頼度のしきい値を超えるもののみ)
labels = response.get('Labels', [])
for label in labels:
label_name = label['Name']
confidence = label['Confidence']
if confidence >= confidence_threshold:
try:
# DynamoDBに保存するデータを準備
data_to_store = {
'image': key,
'label': label_name # ラベルを個々のエントリーとして保存
}
# DynamoDBにデータを保存
table.put_item(Item=data_to_store)
# 正常に保存された場合のログ出力
print(f"Stored label {label_name} with confidence {confidence} for image {key}")
except Exception as e:
print(f"Error storing in DynamoDB: {str(e)}")
return {
'statusCode': 500,
'body': json.dumps('Error storing data in DynamoDB')
}
return {
'statusCode': 200,
'body': json.dumps('Success')
}
-
変数の値の編集:
上記のコードでは「table_name」の値は適当なものになっているので、「分析した情報を保持するためのDynamoDBの作成」の手順で作成したDynamoDBの名称に書き換えます。 -
関数設定の変更:
-
「設定」タブの「編集」ボタンを押下してタイムアウト設定を変更します。画像の分析には時間がかかることがあるため1分以上で設定します。
-


-
-
トリガーの追加:
- 「設定」タブの「トリガー」から「トリガーを追加」して「写真データをアップロードするS3バケットの作成」の手順で作成したS3バケットを設定します。
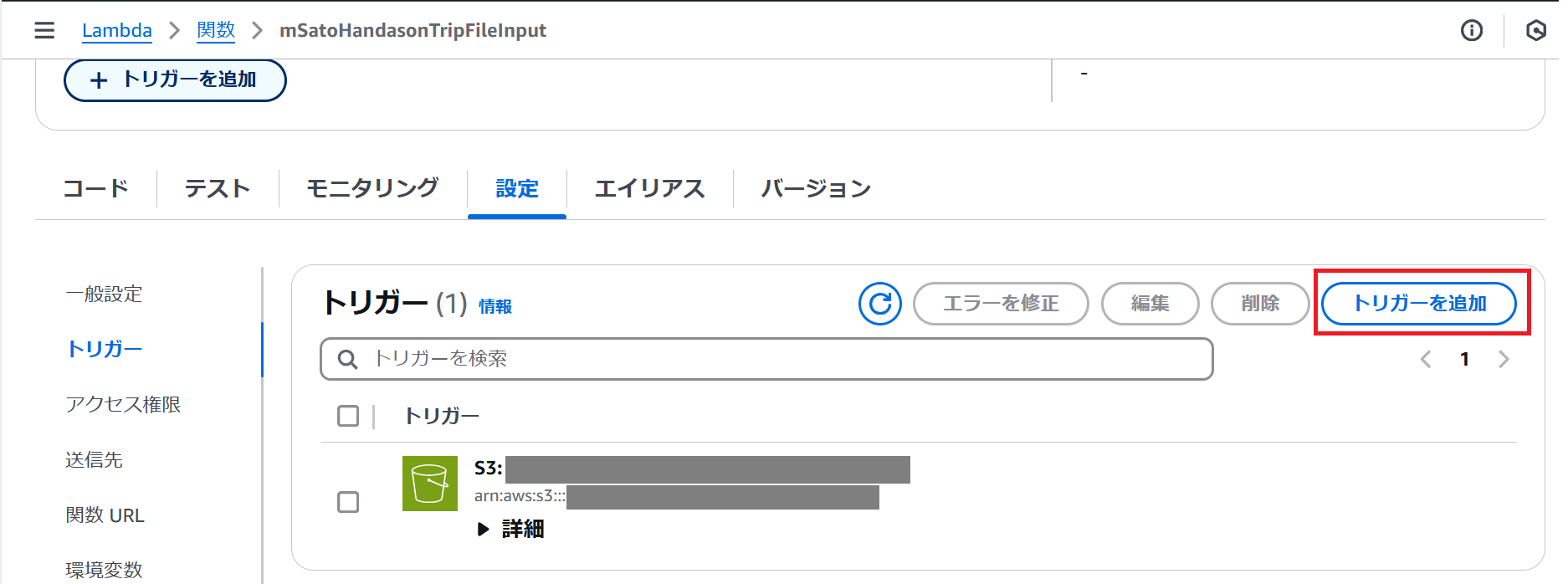
- 「設定」タブの「トリガー」から「トリガーを追加」して「写真データをアップロードするS3バケットの作成」の手順で作成したS3バケットを設定します。
以下のように設定します。「再帰呼び出し」の確認項目を読み、チェックを入れます。インプットとアウトプットの格納場所に同じS3バケットを設定すると処理が無限ループしコストが増大します。「再帰呼び出し」の確認項目はこの点についての注意喚起となりますが、今回はインプットはS3バケット、アウトプット場所はDynamoDBになるためあまり関係しません。
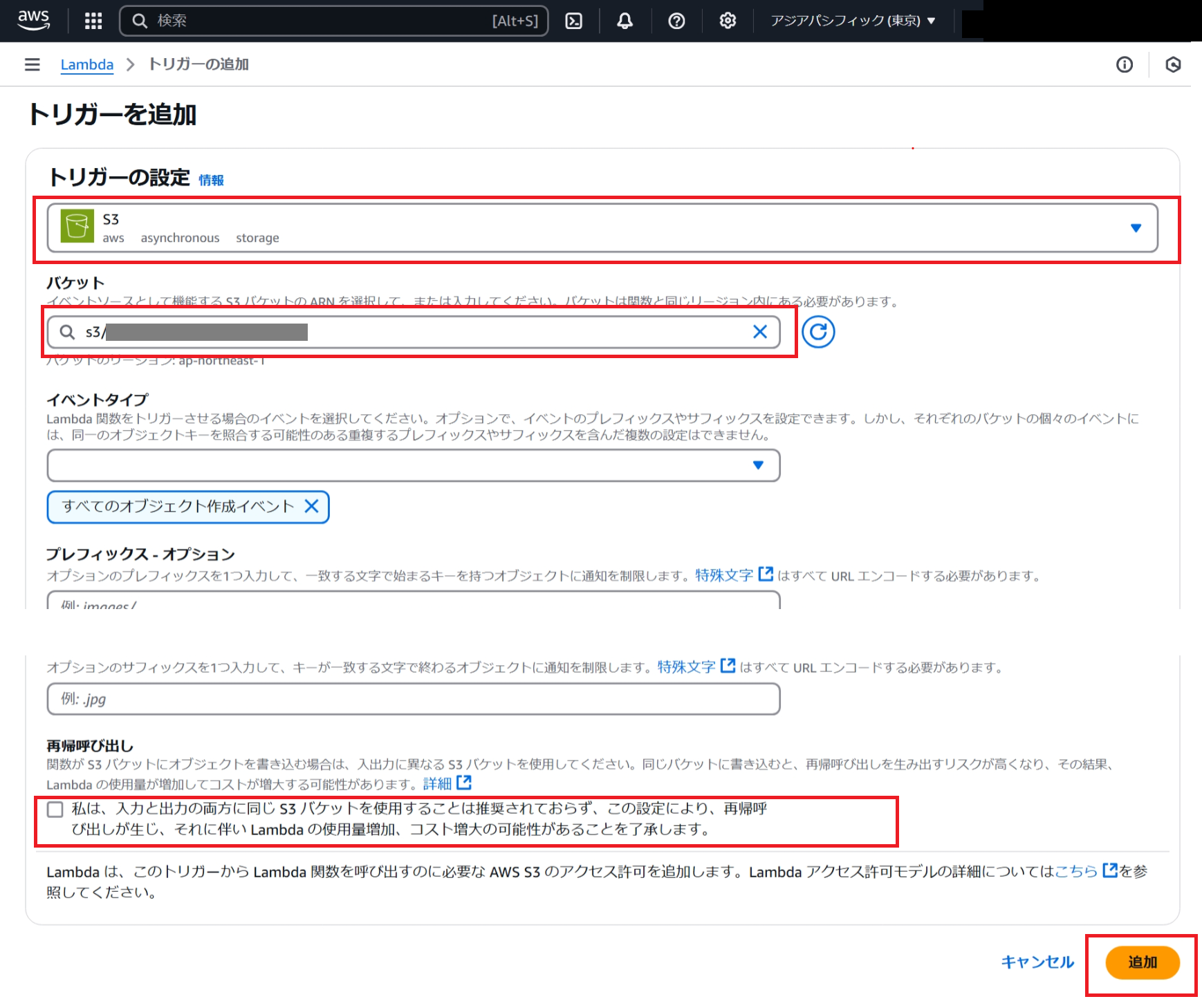
- ポリシーの追加:
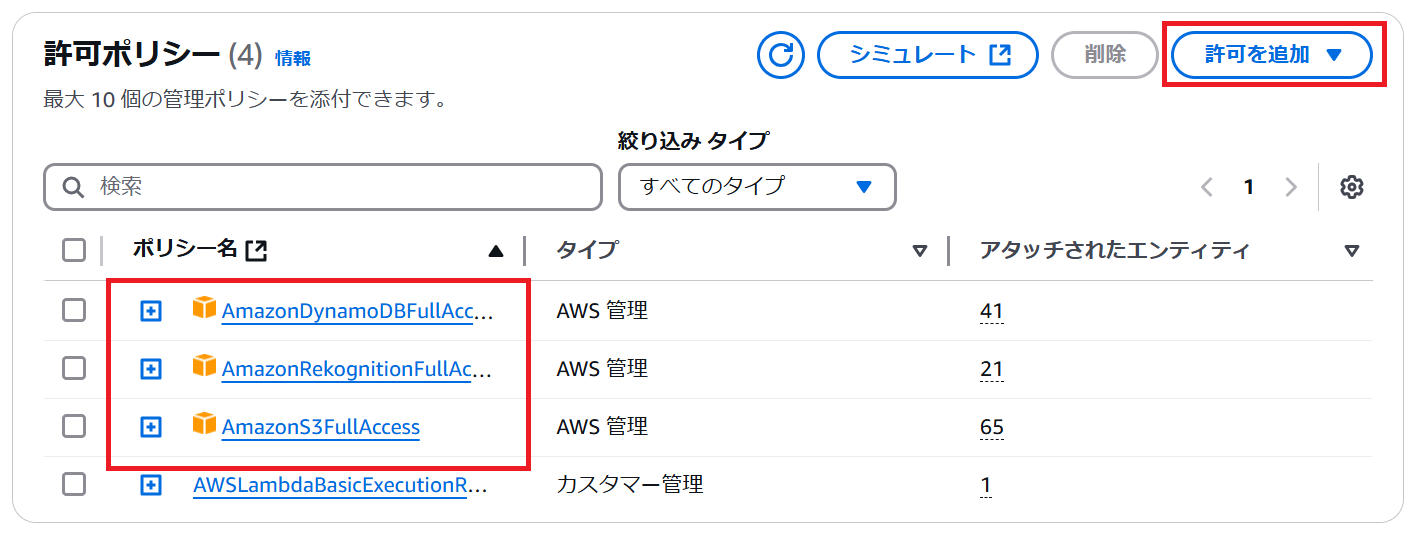
- 「設定」タブの「アクセス権限」を開きます。「ロール名」のリンクを開きLambda関数からS3バケット、DynamoDB、Rekognitionが利用できるようポリシーを追加します。

- ロール名のページから「許可を追加」⇒「ポリシーをアタッチ」を選択。以下3つのポリシーを選択し「保存」します。
- AmazonDynamoDBFullAccess
- AmazonRekognitionFullAccess
- AmazonS3FullAccess
以上でLambda関数の作成は完了です。
動作確認
Lambda関数をデプロイし、テスト実行します。
-
Lambdaのデプロイ:
Lambda関数の「コード」タブにある「Deploy」ボタンを押下します。これを押下しないと変更したコードを実行できません。

-
テストイベントの作成:
-
事前にテスト用の画像ファイルをS3バケットに上げておく。S3バケットを開いて、バケットの名称とオブジェクトキーをメモしておく。

-
lambda関数「Deploy」ボタンの下のほうにある「Create new test event」を選択します。
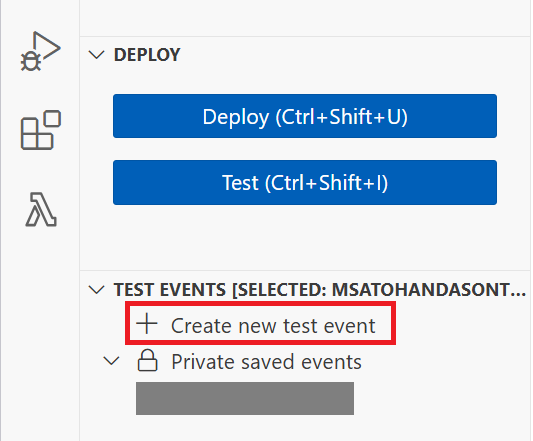
-
コードの右側に「Crate new test event」タブが表示されます。以下のように入力し「Save」ボタンを押下して保存します。

- EventName: 任意のテストイベント名称
- Template optional: Hello World ※書き換えるので任意のものでもOKです。
- Event JSON: 以下のJSONを入力。
{ "Records": [ { "s3": { "bucket": { "name": "トリガーに設定したS3バケットの名称" }, "object": { "key": "テストに利用する画像ファイルのオブジェクトキー" } } } ] }
-
-
テスト実行:
作成したテストイベントが「TEST EVENTS」に表示されるため再生ボタンを押下してテスト実行を行う。

実行結果が表示されるため結果を確認します。正常終了の場合DynamoDBを確認すると画像の分析結果がDBに格納されています。エラーが発生した場合は、エラー内容から問題を確認して解消します
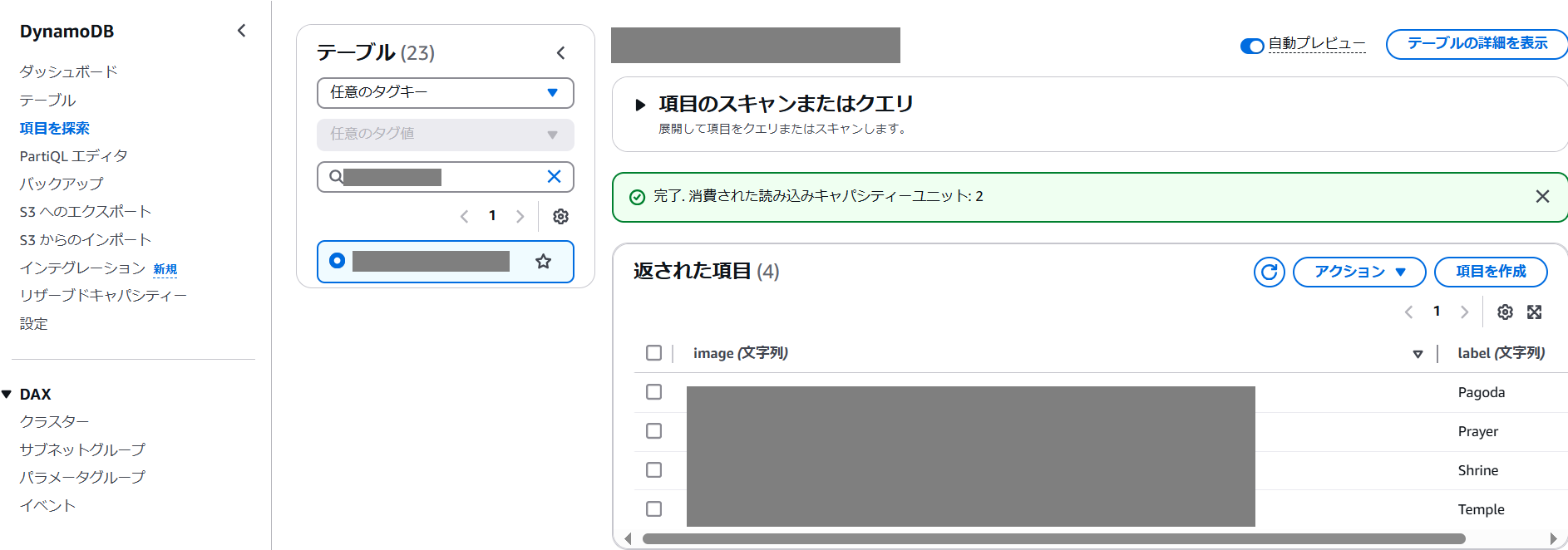
まとめ
以上で写真解析機能の実装は完了です。これで、AWSのサービスを使って簡単にデータが登録できました。
ご自身のIAMユーザーの権限やAWSアカウントの状態によっては手順が追加になることがあります。この手順を作成しているときも同様にエラーは発生しエラー内容をChatGPTなどの生成AIに聞くことで効率よくエラーが解消できましたのでご参考まで。
次回は「生成AIを使った仕組みを考えてみた 第3回:蓄積されたデータを基に旅行プランを生成する(蓄積データの活用編)」になります。この記事で作成したDynamoDBにためたデータをもとに生成AIで旅行プランを自動生成する仕組みを作成します。