はじめに
本記事ではプライバシー強化技術(PETs)の要素技術の一つである、連合学習(Federated Learning)をPytorchを用いて実装し、MNISTの分類を行います。連合学習やプライバシー強化技術全体についての説明は他記事をご覧ください。
検証の設定
連合学習にはデータの分割方法や参加するクライアントの数に応じて様々な分類があります。
今回は、少数の組織で学習を行うCross-Siloで、同じ特徴量・ラベルの組を保有する際に適用可能な水平連合学習(Horizontal Federated Learning)を行います。
連合学習の分類
- 学習に参加するクライアント(デバイス)数による分類
- Cross-Silo
少数のクライアントを対象に行う - Cross-Device
多数のデバイスを対象に行う
- Cross-Silo
- データの分かれ方
- Horizontal Federated Learning
それぞれの組織が同じ特徴量の項目をもつ異なるサンプルを保有する際に適用する手法。 学習に使用するデータのサンプル数が増えることで精度の高いモデルが学習できる。 - Vertical Federated Learning
それぞれの組織が同一のサンプルに対して異なる特徴量の項目をもつ際に適用する手法。学習に使用するデータの特徴量数が増えることで精度の高いモデルが学習できる。 - Hybrid Federated Learning
HorizontalとVerticalのハイブリッド手法
- Horizontal Federated Learning
FedAVG
連合学習の代表的な学習アルゴリズムであるFedAVG(FederatedAveraging)を実装します。
提案された論文中では、学習の各ラウンドにおいて一部のクライアントが学習に参加するアルゴリズムになっています。今回の検証では少数のクライアントで学習を行うため、各ラウンドで全ての組織が学習に参加する設定にしています。
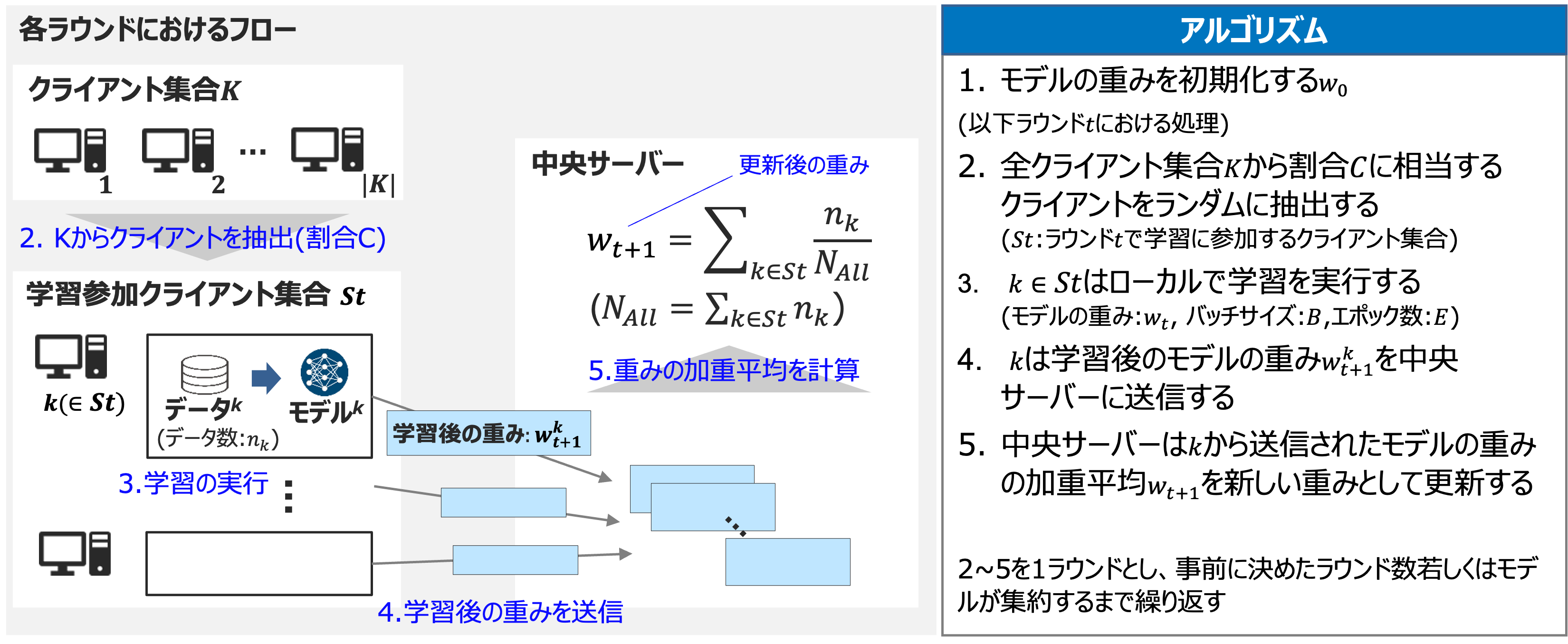
実装
実行環境
今回の実行環境は以下の通りです。
Python 3.8.18
numpy==1.22.3
torch==1.12.0
torchvision==0.9.1
ライブラリ・データの準備
最初に必要なライブラリをインポートします。
import os
import copy
import string
from tqdm import tqdm
import numpy as np
import torch
from torch.utils.data import Subset, DataLoader, random_split, ConcatDataset
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
次に必要なデータのダウンロードや前処理を行います。
#乱数を固定する
def set_seed(seed):
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
set_seed(42)
# デバイスの設定
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# パス設定
data_dir = "../data"
model_dir = "../model"
os.makedirs(model_dir, exist_ok=True)
# データセットのダウンロード・前処理
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, ), (0.5, ))])
trainset = torchvision.datasets.MNIST(root=data_dir,
train=True,
download=True,
transform=transform)
testset = torchvision.datasets.MNIST(root=data_dir,
train=False,
download=True,
transform=transform)
batch_size = 100
valtest_set_list = random_split(testset, [5000, 5000])
valloader, testloader = [DataLoader(dataset, batch_size = batch_size, shuffle = True, num_workers=2) for dataset in valtest_set_list]
# ネットワークの定義
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(28*28, 400)
self.fc2 = nn.Linear(400, 200)
self.fc3 = nn.Linear(200, 100)
self.fc4 = nn.Linear(100, 10)
def forward(self, x):
x = x.view(-1, 28*28) # flatten
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = torch.relu(self.fc3(x))
x = self.fc4(x)
return x
# テストを行う関数
def test(net, dataloader, device = "cpu", criterion = nn.CrossEntropyLoss()):
with torch.no_grad():
running_loss = 0
correct_preds = 0
total_preds = 0
for inputs, labels in dataloader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = net(inputs)
loss = criterion(outputs, labels)
running_loss += loss.item()
correct_preds += outputs.max(1)[1].eq(labels).sum().item()
total_preds += outputs.size(0)
loss = running_loss/len(dataloader)
acc = 100*correct_preds/total_preds
return loss, acc
# クライアント名のリストを生成する関数
def gen_clients_list(n):
alphabet = string.ascii_uppercase
result = []
for i in range(n):
sequence = ""
idx = i
while idx >= 0:
sequence = alphabet[idx % 26] + sequence
idx = idx // 26 - 1
result.append(sequence)
return result
クライアント・サーバーの実装
続いて、学習に参加するクライアント(Clientクラス)とクライアントから送られてきたモデルを集約する中央サーバー(Serverクラス)を実装します。
Clientクラスは学習に使用するデータとモデルを変数としてもち、ローカルで学習を行う関数・学習したモデルを中央サーバーに送る関数・サーバーから集約されたモデルを受け取る関数をメソッドとしてもちます。
# Clientクラスの定義
class Client():
def __init__(self, client_name, dataloader, device = "cpu"):
self.name = client_name
self.filename = f"client_{self.name}_model.pth"
self.dataloader = dataloader
self.num_data = len(self.dataloader.dataset)
self.device = device
self.set_model()
def set_model(self, net = None,criterion = nn.CrossEntropyLoss(), lr = 0.02):
if net != None:
self.net = net
else:
self.net = Net().to(self.device)
self.lr = lr
self.criterion = criterion
self.optim = optim.SGD(self.net.parameters(), lr = self.lr)
# ローカルでn_pochsの学習を行う関数
def train(self, n_epochs = 1):
running_loss = 0
correct_preds = 0
total_preds = 0
for _ in range(n_epochs):
for inputs, labels in self.dataloader:
inputs, labels = inputs.to(self.device), labels.to(self.device)
self.optim.zero_grad()
outputs = self.net(inputs)
loss = self.criterion(outputs, labels)
loss.backward()
self.optim.step()
running_loss += loss.item()
correct_preds += outputs.max(1)[1].eq(labels).sum().item()
total_preds += outputs.size(0)
print(f"Client {self.name}, Training loss: {running_loss/len(self.dataloader):.3f} - Accuracy: {100*correct_preds/total_preds:.3f}")
# 学習したモデルを中央サーバーに送る関数(今回はローカルのmodel_dirに保存する)
def send_model(self):
torch.save(self.net.state_dict(), os.path.join(model_dir, self.filename))
# サーバーからモデルを受け取る関数(今回はローカルのmodel_dirから読み込む)
def load_model(self, model_name = "agg_model.pth"):
agg_mlp = torch.load(os.path.join(model_dir, model_name),weights_only = True)
self.net.load_state_dict(agg_mlp)
self.net.to(device)
self.optim = self.optim = optim.SGD(self.net.parameters(), lr = self.lr)
中央サーバーはクライアントから送られてきたモデルのdict・集約したモデル・データ数の加重平均を取るために使用するクライアントごとのデータ数を変数として持ち、集約を行う関数・クライアントからデータを受け取る関数・集約したモデルをクライアントに送る関数をメソッドとしてもちます。
# モデルの集約を行う中央サーバーの定義
class CentralServer():
def __init__(self, data_num_dict):
self.client_model_dict = None
self.agg_net = None
self.client_datanum_dict = data_num_dict
# 集約を行う関数
def aggregate(self, net = Net()):
self.receive_model()
self.agg_net = copy.deepcopy(net) # ネットワーク構造をコピーする
layer_list = self.agg_net.state_dict().keys()
agg_params = {
layer : torch.sum(
torch.stack(
[ (self.client_model_dict[filename][layer] * self.client_datanum_dict[filename]) for filename in self.client_datanum_dict.keys()]
)
, dim = 0) / sum(self.client_datanum_dict.values())
for layer in layer_list
}
self.agg_net.load_state_dict(agg_params)
self.agg_net.to(device)
# クライアントからモデルを受け取る関数(今回はローカルのmodel_dirから読み込む)
def receive_model(self):
self.client_model_dict = {filename : torch.load(os.path.join(model_dir, filename), weights_only = True) for filename in self.client_datanum_dict.keys()}
# 集約したモデルをクライアントに送る関数(今回はローカルのmodel_dirに保存する)
def send_model(self):
torch.save(self.agg_net.state_dict(), os.path.join(model_dir, "agg_model.pth"))
学習部分の実装
今回は参加クライアント数を3としてMNISTデータを3分割し、10ラウンドの学習を行います。
n_clients = 3 # 学習に参加するクライアント数
clients_list = gen_clients_list(n_clients) # クライアント名のリストを作成
clients_data_rate = [1 / n_clients] * n_clients # データの分割割合を指定。今回は3等分する
clients_dataset_list = random_split(trainset, [int(rate * len(trainset)) for rate in clients_data_rate])
clients_dataloader_dict = {key : DataLoader(dataset,batch_size=batch_size,shuffle=True,num_workers=2) for key, dataset in zip(clients_list, clients_dataset_list)}
# 分割したデータを元にClientのインスタンスを作成
clients_dict = {client_name : Client(client_name, dataloader, device = device) for client_name, dataloader in clients_dataloader_dict.items()}
server = CentralServer(data_num_dict={client.filename : client.num_data for client in clients_dict.values()})
n_round = 10 # 学習のラウンド数
best_acc = 0
best_model = None
for round in range(n_round):
print(f"====round:{round}====")
print(f"----train----")
for client in clients_dict.values():
client.train()
client.send_model()
print(f"----aggregate----")
server.aggregate()
server.send_model()
val_loss, val_acc = test(server.agg_net, valloader, device = device)
print(f"Validation, loss: {val_loss:.3f} - Accuracy: {val_acc:.3f}")
if val_acc > best_acc:
best_acc = val_acc
best_model = copy.deepcopy(server.agg_net)
print("Replace Best Model")
for client in clients_dict.values():
client.load_model()
print()
test_loss, test_acc = test(best_model, testloader, device = device)
print(f"Test, loss: {test_loss:.3f} - Accuracy: {test_acc:.3f}\n")
比較のため、各クライアントがそれぞれのデータで個別にモデルを学習した場合の結果も確認します。
# 初期化のため再度clients_dictを作成
clients_dict = {client_name : Client(client_name, dataloader, device = device) for client_name, dataloader in clients_dataloader_dict.items()}
#それぞれのクライアントで10エポックの学習を実行
epochs = 10
for client in clients_dict.values():
best_acc = 0
best_model = None
print(f"========== Client : {client.name} ==========")
for epoch in range(epochs):
print(f"====epoch:{epoch}====")
client.train()
val_loss, val_acc = test(client.net, valloader, device = device)
print(f"Validation, loss: {val_loss:.3f} - Accuracy: {val_acc:.3f}")
if val_acc > best_acc:
best_acc = val_acc
best_model = copy.deepcopy(client.net)
print("Replace Best Model")
print()
test_loss, test_acc = test(best_model, testloader, device = device)
print(f"Test, loss: {test_loss:.3f} - Accuracy: {test_acc:.3f}")
実験結果
上記のコードによる連合学習モデルと各クライアントの個別モデルの結果は下図のようになります。

連合学習モデルのAccuracyが個別モデルと比べて低いことが分かります。乱数のseed値やハイパーパラメータ(学習率、ラウンド数、ネットワーク構造)を変えることで結果は変わるかもしれませんが、個別モデルの方がAcuuracyが高くなった理由としては2つ考えられます。
- 個別のモデルが十分に学習可能なサンプル数を保有している
今回行なった水平連合学習は、学習に使用するデータのサンプル数が増えることで精度の高いモデルが学習できる学習手法です。個別のモデルで学習可能なサンプル数を保有している場合は、水平連合学習を行うメリットが小さくなります。 - モデル構造のずれにより収束が遅くなっている
FedAVG等のノードごとに平均化を行う集約手法では、モデルの構造のずれによって性能が落ちる/収束が遅くなる可能性があります。
(例:モデルのあるパラメータXについて、個別モデルAの学習では「性別」特徴量の重みが大きかったのに対して、個別モデルBでは「年齢」特徴量の重みが大きく、平均化によって両モデルで学習した特徴が薄まってしまう)
実際0ラウンド目の学習において、個別モデルのAccuracyは35~40%近く出ていたのに対して、集約したモデルでは9.9%とランダムな予測と変わらない性能となっています。

ラウンドを経るごとに構造のずれが解消され、最終的には90%近いAccuracyとなっていますが、収束速度は連合学習における課題の一つです。
特徴をアラインメントすることでモデルの構造のずれを解決し、収束速度・性能を向上させる手法が提案されています。1
データの分割をアンバランスにした条件での検証
先ほどの検証ではデータを3等分しましたが、ラベルごとに分割の割合を変えてデータの分割をアンバランスにした設定で同様の検証を行います。
学習部分の実装(データの分割をアンバランスにする)
n_clients = 3
clients_list = gen_clients_list(n_clients)
# 10行n_client列のランダム行列を生成
split_rate_matrix = np.random.rand(10, n_clients)
# 各行の和が1になるように正規化
row_sums = split_rate_matrix.sum(axis=1, keepdims=True)
normed_split_rate_matrix = split_rate_matrix / row_sums
dataset_dict = { client_name : None for client_name in clients_list}
for extract_label in range(10):
rate_list = np.random.rand(n_clients)
normed_rate_list = rate_list / rate_list.sum()
print(f"label:{extract_label}, rate : {normed_rate_list}")
# datasetからextract_label==labelのsubsetを抽出する
indices = [i for i, (_, label) in enumerate(trainset) if extract_label == label]
# subsetをrateの割合で分割する
subset = Subset(trainset, indices)
split_sizes = [int(rate * len(subset)) for rate in normed_rate_list]
split_sizes[-1] += (len(indices) - sum(split_sizes))
split_subset = random_split(subset, split_sizes)
for i, client_name in enumerate(clients_list):
if dataset_dict[client_name] == None:
dataset_dict[client_name] = split_subset[i]
else:
dataset_dict[client_name] = ConcatDataset([dataset_dict[client_name], split_subset[i]])
clients_dataloader_dict = { client_name : DataLoader(dataset,batch_size=batch_size,shuffle=True,num_workers=2) for client_name, dataset in dataset_dict.items()}
clients_dict = {client_name : Client(client_name, dataloader, device = device) for client_name, dataloader in clients_dataloader_dict.items()}
server = CentralServer(data_num_dict={client.filename : client.num_data for client in clients_dict.values()})
各ラベルの分割割合は下図のようになります。(左から順にクライアントA,B,Cへの割り当て割合)

データ分割部分以外のコードは先ほどの検証と同じ手順で、連合学習モデルと個別モデルの性能を評価します。
実験結果
データの分割をアンバランスにした場合の結果は下図のようになります。

各個別のモデルでは学習に十分なデータ量がないラベルがありますが(クライアントAのlabel4、クライアントBのlabel2等)、連合学習をすることで、全てのラベルで十分なデータ量を学習に用いることが出来、個別モデルよりも性能が高くなっていることが分かります。
まとめ
本記事では、プライバシー強化技術の一つである連合学習をPytorchを用いて実装し、MNISTデータセットを用いた分類タスクを通じてその効果を検証しました。水平連合学習では、参加するクライアントが十分なデータ量を持つ場合、個別に学習したモデルの方が高い精度を示すことがある一方で、データ分割がアンバランスで十分なデータ量を持たない状況では、連合学習が全クライアントのデータを活用してより高い精度を実現できることが示されました。
Cross-Siloで行う水平連合学習においては、1組織で学習に十分なサンプル数(正例のサンプル数)を保有していないようなユースケースでの活用が見込まれます。
-
Yu, Fuxun, Weishan Zhang, Zhuwei Qin, Zirui Xu, Di Wang, Chenchen Liu, Zhi Tian, and Xiang Chen. “Fed2: Feature-Aligned Federated Learning.” Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’21), 2021. ↩