はじめに
courseraのMachine Learning(機械学習)学んだことメモ(1)の続きです。
前回は線形回帰モデルとロジスティック回帰モデルまででした。
今回は自分が元々勉強したかったNN(ニューラルネットワーク)です。
学習中いきなり文字認識(OCR)の実装に触ることになるのでテンションが上ります。
手動で実装しようとすると全く想像がつかない文字認識ですが、NNを使い、機械学習を行うことで、簡単に実装できてしまい感動します。
正直一つ一つの数式は丁寧に説明してくれるのでなんとか理解できるのですが(一部の偏微分は除く)
最終的に出来上がる動作はなんで動くんだーっと思ってしまいます。
脳って不思議です。
ニューラルネットワーク
パラメータの数が膨大に増えたりした場合の分類の問題をロジスティック回帰で解くには限界が来ます。
そのためにこのNNを使います。
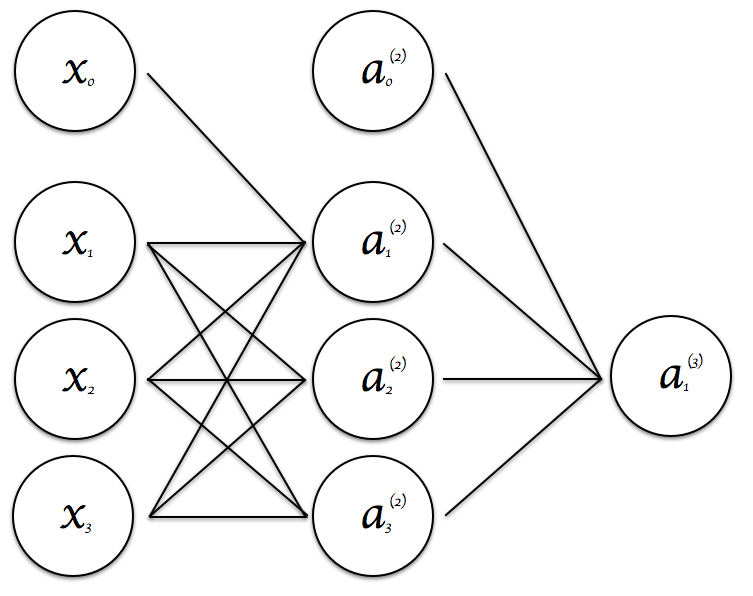
$a^{(j)}_i$ activation(出力) of unit i in layer j
$x_0$,$a_0$はバイアスユニットで常に1を取ります。
$\theta^{(j)}$ は重みづけ制御のための行列 layer j (input)からlayer j+1(output)のマッピングに対応
$a_1^{(2)} = g(\theta_{1,0}^{(1)} \cdot x_0 + \theta_{1,1}^{(1)} \cdot x_1 + \theta_{1,2}^{(1)} \cdot x_2 + \theta_{1,3}^{(1)} \cdot x_3 )$
$a_2^{(2)} = g(\theta_{2,0}^{(1)} \cdot x_0 + \theta_{2,1}^{(1)} \cdot x_1 + \theta_{2,2}^{(1)} \cdot x_2 + \theta_{2,3}^{(1)} \cdot x_3 )$
$a_3^{(2)} = g(\theta_{3,0}^{(1)} \cdot x_0 + \theta_{3,1}^{(1)} \cdot x_1 + \theta_{3,2}^{(1)} \cdot x_2 + \theta_{3,3}^{(1)} \cdot x_3 )$
$h_\theta (x) = a_1^{(3)} = g(\theta_{3,0}^{(2)} \cdot a_0^{(2)} + \theta_{3,1}^{(2)} \cdot a_1^{(2)} + \theta_{3,2}^{(2)} \cdot a_2^{(2)} + \theta_{3,3}^{(2)} \cdot a_3^{(2)} )$
networkについて、layer jのユニット数が$s_{j}$個で、layer j+1 のユニット数が $s_{(j+1)}$個の場合、
$\theta^{(j)}$ は $(s_{(j+1)}) \times (s_{j}+1)$次元の行列
コスト関数(cost function)
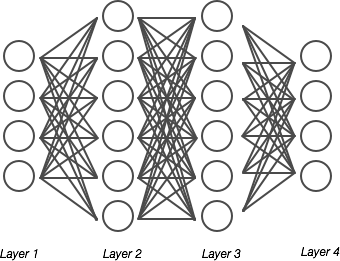
上記のようなNNを考えます。
Layer数Lを定義します。上図の場合はL=4となります。
各レイヤー毎のニューロンのユニット数$S_l$を定義します。(バイアスユニットは含まない)
上図の場合、$S_1=4$,$S_2=6$,$S_3=6$,$S_4=S_L=4$となります。
output unitの個数kを定義します。
$K=4$となります。
binaryClassfication
1 output unitの場合
$S_L=1$
$K=1$
$y \in 0,1$
$h_\theta(x) \in R$
Multi-class classfication(k classes)
k output unitsの場合
$S_L=k$
$K=k$
y = $R^k$
$h_\theta(x) \in R^k$
例 $\begin{eqnarray}
\left[\begin{array}{ccc} 1 \ 0 \ 0 \ 0 \end{array}\right],
\left[\begin{array}{ccc} 0 \ 1 \ 0 \ 0\end{array}\right],
\left[\begin{array}{ccc} 0 \ 0 \ 1 \ 0\end{array}\right],
\left[\begin{array}{ccc} 0 \ 0 \ 0 \ 1\end{array}\right]
\end{eqnarray} $
k >= 3であること。
コスト関数
$h_{\theta}(x) \in R^k$
$(h_{\theta}(x))_k $はk番目のoutputを意味します。
J(\theta)=\frac{1}{m}[\sum_{i=1}^{m}\sum_{k=1}^{K}y_k^{(i)}log(h_\theta(x))_k+
(1-y_k^{(i)})log(1-h_{\theta}(x))_k]
+ \frac{\lambda }{ 2m}\sum_{l=1}^{L-1}\sum_{i=1}^{S_{l}}\sum_{i=1}^{S_{l+1}}(\theta_{ji})^2
$\frac{\lambda }{ 2m}\sum_{l=1}^{L-1}\sum_{i=1}^{S_{l}}\sum_{i=1}^{S_{l+1}}(\theta_{ji})^2$の部分は一見わかりづらいですが、
バイアスユニットの$\theta$を除く全要素を2乗して足し合わせるってことです。
バックプロパゲーションアルゴリズム(back propagation algorithm)
layer $l$のノード$j$の出力$a^{(l)}_j$について
layer1は$a^{(1)}$,layer2は$a^{(2)}$,layer3は$a^{(3)}$,layer4は$a^{(4)}$と定義します。
$a^{(1)} = x$
$z^{(2)}=\theta^{(1)}a^{(1)}$
$a^{(2)} = g(z^{(2)})$ (add $ a_0^{(2)}$)
$z^{(3)}=\theta^{(2)}a^{(2)}$
$a^{(3)} = g(z^{(3)})$ (add $ a_0^{(3)}$)
$z^{(4)}=\theta^{(3)}a^{(3)}$
$a^{(3)} =h_{\theta}(x) = g(z^{(4)})$
layer $l$のノード$j$の誤差(error)を $\delta^{(l)}_j$ と定義します。
$\delta_j^{(4)}=a_j^{(4)} - y_j$ ($ a_{j}^{(4)} = (h_\theta(x))_{j} $)
$ \delta^{(4)} = a^{(4)} - y$
$ \delta^{(3)} = (\theta^{(3)})^{T} .* g^{'}(z^{(3)})$
$ \delta^{(2)} = (\theta^{(2)})^{T} .* g^{'}(z^{(2)})$
($g^{'}(z^{(3)}) = a^{(3)} .* (1-a^{(3)})$ )
($g^{'}(z^{(2)}) = a^{(2)} .* (1-a^{(2)})$ )
実装
Training set 定義
${ (x^{(1)},y^{(1)}), \ldots , (x^{(m)},y^{(m)}) }$
set $\Delta^{(l)}_{ij} = 0$
For i =1 to m
set $a^{(1)} = x^{(i)}$
$a^{(l)}$について、forward propagationの計算実行 $l=2,3,\ldots,L$
$\delta^{(L)} = a^{(L)} - y^{(i)} $を計算
$\delta^{(L-1)},\delta^{(L-2)},\ldots,\delta^{(2)}$と計算($\delta^{(1)}は入力に対応するため計算しない$)
$\Delta_{ij}^{(l)} := \Delta^{(l)}_{ij} + a^{(l)}_j \delta^{(l+1)}$
上記をベクトル演算とすると以下になる。
$\Delta^{(l)} := \Delta^{(l)} + \delta^{(l+1)}(a^{(l)} )^T$
EndFor
$j \neq 0$の時
$D_{ij}:=\frac{1}{m}\Delta_{ij}^{(l)} + \frac{\lambda}{m}\theta_{ij}^{(l)}$
$j = 0$の時
$D_{ij}:=\frac{1}{m}\Delta_{ij}^{(l)}$
$\frac{\delta}{\delta\theta_{ij}^{(l)}}J(\theta)=D_{ij}^{(l)}$
$j \neq 0$の時の対応は正規化のためで、要するにバイアスユニット以外について対応するってことです。
Gradient Checking
バックプロパゲーションアルゴリズム(back propagation algorithm)は実装がミスっている可能性があるため(難しいため)
テストするための仕組みとしてこれを学びます。
$\theta=R^n$
これはつまり、
$\theta = [\theta_1,\theta_2,\theta_3,\ldots,\theta_n]$
$J_\theta(x)$について、偏微分すると
\frac{\delta}{\delta\theta_1}J(x)\cong \frac{J(\theta_1+\epsilon,\theta_2,\theta_3,\ldots,\theta_n) - J(\theta_1-\epsilon,\theta_2,\theta_3,\ldots,\theta_n)}{2\epsilon} \\
\frac{\delta}{\delta\theta_2}J(x)\cong \frac{J(\theta_1,\theta_2+\epsilon,\theta_3,\ldots,\theta_n)
- J(\theta_1,\theta_2-\epsilon,\theta_3,\ldots,\theta_n)}{2\epsilon} \\
\frac{\delta}{\delta\theta_3}J(x)\cong \frac{J(\theta_1,\theta_2,\theta_3+\epsilon,\ldots,\theta_n)
- J(\theta_1,\theta_2,\theta_3-\epsilon,\ldots,\theta_n)}{2\epsilon} \\
\\\vdots\\
\frac{\delta}{\delta\theta_n}J(x)\cong \frac{J(\theta_1,\theta_2,\theta_3,\ldots,\theta_n+\epsilon) -
J(\theta_1,\theta_2,\theta_3,\ldots,\theta_n-\epsilon)}{2\epsilon}
$\epsilon$が十分小されば、一致する。
code 例
for i =1:n
thetaPlus = theta;
thetaPlus(i) = thetaPlus(i) + EPSILON;
thetaMinus(i) = thetaMinus(i) - EPSILON;
gradApprox(i) = (J(thetaPlus)- J(thetaMinus))/(2*EPSILON);
endfor;
gradApprox(l) を先ほどのBP(バックプロパゲーション)にて取得した$D^{(l)}$と比較する
ランダム初期化
$\theta$の初期値については線形回帰モデルとロジスティック回帰モデルでは0でしたが、
NNについては問題が起こります。
実際に $\theta_{ij}^{(l)} = 0$ とした場合
$a_1^{(2)} = a_2^{(2)} $になります。なぜなら同じ$x$をパラメータを持つためです
結果BPによる$\delta$も同じになります。
$\delta_1^{(2)} = \delta_2^{(2)}$
最終的に
$\frac{\delta}{\delta\theta_{0,1}^{(1)}}J(\theta) = \frac{\delta}{\delta\theta_{0,2}^{(1)}}J(\theta)$
つまり
$\theta_{0,1}^{(1)} = \theta_{0,2}^{(1)}$
つまり
$a_1^{(2)} = a_2^{(2)} $になります。
こうしてこの関係が何度繰り返しても成り立つのです。
この対称性をランダム初期化で繰り返します。
code例
十分小さい値$\epsilon$を定義します。
$-\epsilon \leq \theta_{ij}^{(l)} \leq \epsilon$
theta1 = rand(10,11) * (2*INIT_EPSILON) - INIT_EPSILON;
theta2 = rand(1,11) * (2*INIT_EPSILON) - INIT_EPSILON;
まとめ
全体の手順として以下のように進めます
- $\theta$のランダム初期化
- FPによる$h_\theta(x^{(i)})実装$
- cost関数$J(\theta)$の実装
- BPによる偏微分の実装
- gdによる実装のチェック
- gdチェックに問題なければgd disclose
- $J(\theta)$の最小値を求める(学習の実行)