初めに
私と同じような英語が苦手なプログラマって多数派だと思うんです。
だってQiitaでいいね貰おうとしたら翻訳系が効率いいとの事
実際私のいいねも翻訳系が多数です。
でも大体Qiitaの投稿って(自分だけ?)放置しがちで何年か経つとと現行バージョンと合わなくなります。
でも流入率は高く未だにいいねをもらってしまったりします。
これって健全じゃないですし、悲しい事故をもたらします(2018/2の時点でReact.createClassを使ってしまうというような)
Reactの本家サイトを見ていれば、現在は上記関数の利用は推奨していないのは明らかなんですが、
古い翻訳が検索上位に来たりします。プログラマあるあるとして
古い翻訳を参考にして動かなくてハマるってありませんでした?
だったらこれを解決するプロダクトを作ってしまおうじゃないか。と考えました。
(何より自分がほしいんです。)
できれば原典の本家サイトの内容を同じレイアウトで日本語訳で読みたい。
ヒントは以下の記事から頂きました。ありがとうございました。
対訳を用意してDOM.textNodeの部分を上手く置き換えることができれば、本家サイトを直接日本語で読めそうです。
出来ればGithubのREADMEやissueも翻訳しながら読みたいです。
(Google翻訳が一番近いことができますが、気に入らない翻訳しかできない上に改善提案を試みても
その場では反映されず)
作ったツールの紹介
上記発想をもとに作ったのがこちらです。
こんな感じで翻訳していきます
taiyaqの使いかた pic.twitter.com/WD7qAesxG1
— Taiyaq.com (@taiyaq_com) 2018年2月27日
twitterだと画質がよくないのでyoutube版ものせておきます
翻訳したもの

翻訳例として作ったものを以下に並べます。
それとGithub内のプロジェクトのREADMEも翻訳できます。(Google翻訳ではできない!)
メリットとデメリット
メリット
原典を読める安心感
常に翻訳内容が英語で記述された公式ドキュメントと追従していることが目視で確認できます。
公式サイトの翻訳を探した時に、その翻訳は最新に追従しているか不安になることないですか?
この仕組みを使うと翻訳後に公式ドキュメントが変更された際に変更箇所だけが英語になり、変更がない箇所は日本語で翻訳されます。
少なくとも最新との差分がない箇所は翻訳ができるので、安心して日本語訳の部分を参照できます。
変更箇所は皆で翻訳を進めればいいのです。
デメリット
既に翻訳プロジェクトがあったら二重管理になる。
TODO: markdownでimport/exportする機能の実装。翻訳情報を再利用してもらおう/再利用させてもらおう
仕組み
わざわざ対訳を作るのには理由があります。
技術ドキュメントは全ての記述を変更することは多くありません。大抵幾つかの仕様が変更され、ドキュメントの修正が行われます。
事前にドキュメントを分割して翻訳しておけば、変更された部分以外に関しては翻訳が既存のものを流用できます。
対訳作成の流れについて
Taiyaq(今回作ったツール/サービス名) は、以下の手順で対訳の作成を進めていきます。
ある翻訳したいサイトがあります。そこで新規の対訳作成を選ぶと以下の手順が始まります。
翻訳対象の分割
翻訳対象サイト を一定単位で分割します。同じコンテンツは同じ分割方法に従い毎回同じように分割されます。
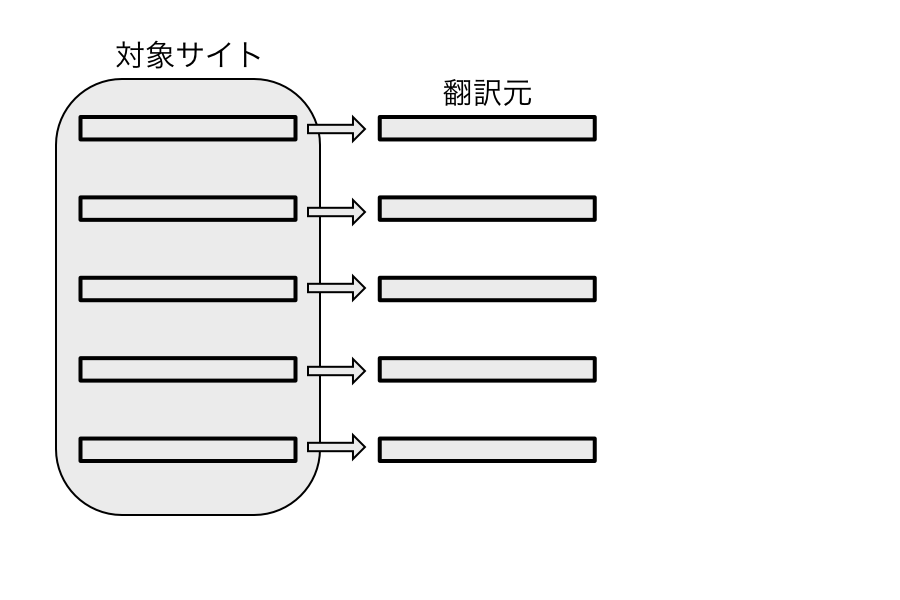
これによって翻訳対象を分割します。
分割情報のハッシュを作成する

対訳は前後の翻訳対象のハッシュも記憶しておきます。つまり 1 つの対訳は次の情報を対訳とは別に保持します。
- 翻訳対象のハッシュ
- 翻訳対象の 1 つ前のハッシュ
- 翻訳対象の 1 つ後ろのハッシュ
これは後述する翻訳処理で使われます。
対訳の作成
上記分割した翻訳情報を翻訳して対訳をつくっていきます。

この情報をもとに対象サイトの翻訳を行います。
翻訳の流れについて
Taiyaq は以下の手順によって翻訳を行います。
ある翻訳したいサイトがあります。そこで翻訳を実行すると以下の手順が行われます。
対象サイトの分割
翻訳対象サイト を一定単位で分割します。同じコンテンツは同じ分割方法に従い毎回同じように分割されます。(対訳作成の分割と同じ)

これによって翻訳元となる情報を作成します。
対応する対訳を使った翻訳を実行
翻訳を行います。但し前述したハッシュ情報を使い大きく3つのパターンに分けて翻訳を実行します。
対応する対訳の検出 (完全一致)
これは前後の翻訳元のハッシュと翻訳対のハッシュ(3 つのハッシュ)が完全一致した場合に翻訳されます。完全一致なので最優先で翻訳を実行します。

対応する対訳の検出 (2 箇所一致)
これは前後何れかのハッシュが一致しない場合に翻訳を実行されます。これは前後何れかの翻訳元が変更された場合に実行されます。
部分一致でも翻訳を行いますが完全一致の翻訳が全て終わり残った翻訳対象に対して実行されます。
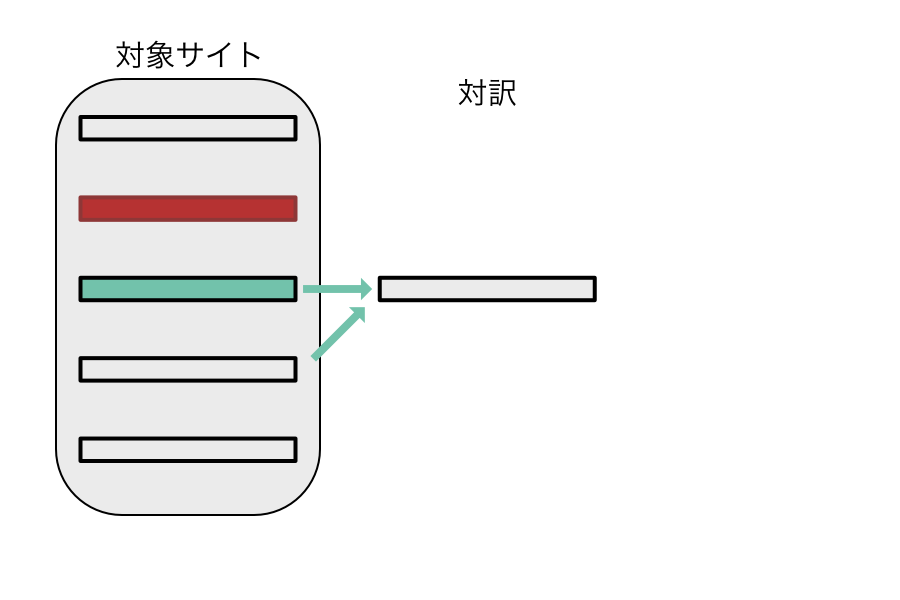
対応する対訳の検出 (前後不一致)
前後ともハッシュが一致しない場合に翻訳を実行しますこれは前述した完全一致, 2 個所一致 にて翻訳した残りの翻訳に対して実行されます。

対応する対訳の検出 (全不一致)
全てのハッシュが一致しない場合に翻訳をしません。その対訳はもはや翻訳対象外となります。

翻訳完了
上記ルールによって翻訳が実行されます。
TODO
今は翻訳情報をスマホから読めるようにreact-native関連のドキュメントを絶賛翻訳中です。
次の目標はスマホアプリ化ということですね。
最後に
まだまだベータリリース中です。ぜひご協力、ご意見いただければ幸いです。