こちらを参考に、Apache SparkのSpark Streamingを使用した、リアルタイムのTwitter構文解析処理を試した手順を纏めます。実行環境は次の通りです。
・CentOS 7.5
・Apache Spark 2.3.1
・Scala 2.12.6
・kuromoji 0.7.7
・Spark Streaming Twitter 2.10 rev 1.1.0
・Twitter4J 3.0.3
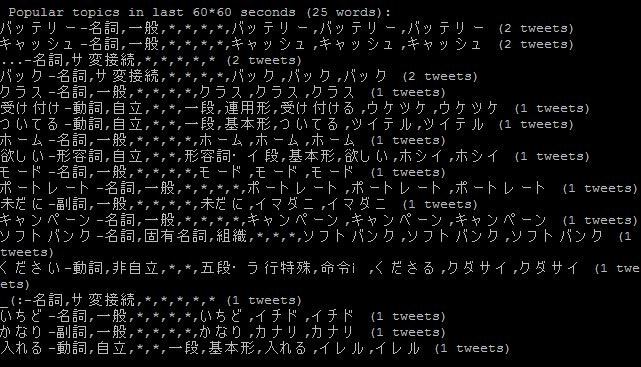
Twitter解析 実行結果
「iPhone6」が含まれるTweet中に出現する単語と、その頻度をカウント
Apache Spark、Scala、sbtのインストールは、こちらの手順で実施しました。
kuromojiのインストール
SPARK_HOMEへのkuromoji(日本語形態素解析エンジン)のダウンロードと展開
# cd /usr/local/lib/spark
# wget https://github.com/downloads/atilika/kuromoji/kuromoji-0.7.7.zip
# yum -y install unzip
# unzip kuromoji-0.7.7.zip
# rm kuromoji-0.7.7.zip
Twitter4J用 Spark Streaming関連ライブラリのダウンロード
こちらを参考に、必要モジュールをダウンロードし、展開
※logging.jarのダウンロードを上記手順に追加
# cd /usr/local/lib/spark
# mkdir twitter4j
# cd twitter4j
# wget https://repo1.maven.org/maven2/org/apache/spark/spark-streaming-twitter_2.10/1.1.0/spark-streaming-twitter_2.10-1.1.0.jar
# wget https://raw.githubusercontent.com/swordsmanliu/SparkStreamingHbase/master/lib/spark-core_2.11-1.5.2.logging.jar
# curl -O http://twitter4j.org/archive/twitter4j-3.0.3.zip
# unzip -j ./twitter4j-3.0.3.zip "lib/*.jar" (jarファイルのみ展開)
# rm twitter4j-3.0.3.zip
Spark-shellの起動
--jarsにて、Twitter用ライブラリ及びkuromojiを指定し読み込む
spark-shell --master local[2] --jars /usr/local/lib/spark/twitter4j/spark-streaming-twitter_2.10-1.1.0.jar,/usr/local/lib/spark/twitter4j/twitter4j-core-3.0.3.jar,/usr/local/lib/spark/twitter4j/twitter4j-media-support-3.0.3.jar,/usr/local/lib/spark/twitter4j/twitter4j-async-3.0.3.jar,/usr/local/lib/spark/twitter4j/twitter4j-examples-3.0.3.jar,/usr/local/lib/spark/twitter4j/twitter4j-stream-3.0.3.jar,/usr/local/lib/spark/twitter4j/spark-core_2.11-1.5.2.logging.jar,/usr/local/lib/spark/kuromoji-0.7.7/lib/kuromoji-0.7.7.jar
集計スクリプト(Twitter4Jを利用)の実行
今回はTwitterのJava用ライブラリのTwitter4Jを利用してアクセスする。
Twitter API Key(Access Tokenなど認証情報)の指定は、こちらを参考にKeyを取得する
(2018/7/24より)上記Keyの取得にあたって、Developer Portalにて、開発者用アカウントの登録が事前に必要となり、APIの利用目的等を英語300文字以上で記述の上でのアカウント登録が必須となっています。 ※参考
import org.apache.spark.streaming._
import org.apache.spark.streaming._
import org.apache.spark.streaming.twitter._
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.SparkConf
import java.util.regex._
import org.atilika.kuromoji._
import org.atilika.kuromoji.Tokenizer._
System.setProperty("twitter4j.oauth.consumerKey", "xxxxxxxxxxxxxxxxxxx")
System.setProperty("twitter4j.oauth.consumerSecret", "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
System.setProperty("twitter4j.oauth.accessToken", "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
System.setProperty("twitter4j.oauth.accessTokenSecret", "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")
val ssc = new StreamingContext(sc, Seconds(60))
val stream = TwitterUtils.createStream(ssc, None, Array("iPhone6"))
val tweetStream = stream.flatMap(status => {
val tokenizer : Tokenizer = Tokenizer.builder().build()
val features : scala.collection.mutable.ArrayBuffer[String] = new collection.mutable.ArrayBuffer[String]()
var tweetText : String = status.getText()
val japanese_pattern : Pattern = Pattern.compile("[\\u3040-\\u309F]+")
if(japanese_pattern.matcher(tweetText).find()) {
tweetText = tweetText.replaceAll("http(s*)://(.*)/", "").replaceAll("\\uff57", "")
val tokens : java.util.List[Token] = tokenizer.tokenize(tweetText)
val pattern : Pattern = Pattern.compile("^[a-zA-Z]+$|^[0-9]+$")
for(index <- 0 to tokens.size()-1) {
val token = tokens.get(index)
val matcher : Matcher = pattern.matcher(token.getSurfaceForm())
if(token.getSurfaceForm().length() >= 3 && !matcher.find()) {
features += (token.getSurfaceForm() + "-" + token.getAllFeatures())
}
}
}
(features)
})
val topCounts60 = tweetStream.map((_, 1)
).reduceByKeyAndWindow(_+_, Seconds(60*60)
).map{case (topic, count) => (count, topic)
}.transform(_.sortByKey(false))
topCounts60.foreachRDD(rdd => {
val topList = rdd.take(20)
println("\n Popular topics in last 60*60 seconds (%s words):".format(rdd.count()))
topList.foreach{case (count, tag) => println("%s (%s tweets)".format(tag, count))}
})
ssc.start()
ssc.awaitTermination()
※error: object atilika is not a member of package org が表示された場合は、
spark-shellの起動メッセージの見直し又は、kuromojiのインストールを再実行する
(その他のモジュールも同様)
実行結果
下記が集計結果イメージです。