Plotly ExpressとGapminder
**「FACTFULLNESS(ファクトフルネス)」という本が結構面白かったので、著者が作っている「Gapminder」**のHPにアクセスしたところ、データ可視化ツールが非常に直感的で使いやすかったのでPythonでも同様のことができないかTryしてみました。
[FACTFULNESS(ファクトフルネス) 10の思い込みを乗り越え、データを基に世界を正しく見る習慣]
(https://www.amazon.co.jp/FACTFULNESS-%E3%83%95%E3%82%A1%E3%82%AF%E3%83%88%E3%83%95%E3%83%AB%E3%83%8D%E3%82%B9-10%E3%81%AE%E6%80%9D%E3%81%84%E8%BE%BC%E3%81%BF%E3%82%92%E4%B9%97%E3%82%8A%E8%B6%8A%E3%81%88%E3%80%81%E3%83%87%E3%83%BC%E3%82%BF%E3%82%92%E5%9F%BA%E3%81%AB%E4%B8%96%E7%95%8C%E3%82%92%E6%AD%A3%E3%81%97%E3%81%8F%E8%A6%8B%E3%82%8B%E7%BF%92%E6%85%A3-%E3%83%8F%E3%83%B3%E3%82%B9%E3%83%BB%E3%83%AD%E3%82%B9%E3%83%AA%E3%83%B3%E3%82%B0/dp/4822289605)
[Gapminder tools]
(https://www.gapminder.org/tools/#$chart-type=bubbles)
[Gapminderの使い方、Google Motion Chartの作り方、Excel, JMP, R, SOCR での作成]
(http://www-b.uec.tmu.ac.jp/Gapminder/)
Googleでググったら下記のサイトに、Pythonでできるよ、と書かれていたため今回はそれをトレースしています。
[Recreating Gapminder Animation in 2 lines of Python with Plotly Express]
(https://towardsdatascience.com/recreating-gapminder-animation-in-2-lines-of-python-with-plotly-express-2060c73bedec)
Plotly Expressパッケージの導入
まず、「Plotly Express」 というパッケージを入れろ、ということだったのでanaconda経由でLinuxのコンソールにインストールします。
[Anaconda: plotly_express]
(https://anaconda.org/plotly/plotly_express)
conda install -c plotly plotly_express
次にjupyter notebookを立ち上げて、plotly_expressライブラリのインポート。
import plotly_express as px
次に、そのライブラリのサブモジュールに「Gapminder」データの一部が登録されているらしいのでそれを入手します。
[plotly_express.data]
(https://www.plotly.express/plotly_express/data/index.html)
data = px.data.gapminder()
print("data.shape =", data.shape)
print("data.columns =", data.columns)
data.head(20)
data.shape = (1704, 8)
data.columns =
Index(['country', 'continent', 'year', 'lifeExp', 'pop', 'gdpPercap',
'iso_alpha', 'iso_num'],
dtype='object')

データセットとしては、国名、 大陸、 データ取得年度、 寿命、 人口、 GDP per Cap、 iso_lpha(国の略称?), iso_num(国のひも付け番号?)の8つがあるようです。
このうち、5種類のデータ(国名、 データ取得年度、 寿命、 人口、 GDP per Cap)をひも付けた動くグラフを作ります。
(ちなみに私の使っているPCがボロPCなので表示にやや時間がかかりました・・・)
```python
px.scatter(data, x="gdpPercap", y="lifeExp", animation_frame="year", animation_group="country",
size="pop", color="country", hover_name="country",
log_x = True,
size_max=45, range_x=[100,100000], range_y=[25,90])
例えば、「データ取得年度」が1952年のグラフ。
X軸が「GDP per Cap」、Y軸が「寿命」、グラフ上の点の大きさが「人口」、を示しています。
そしてなんとなく想像がつくと思いますが、画面下のスライダーで「データ取得年度」を変えることができます。
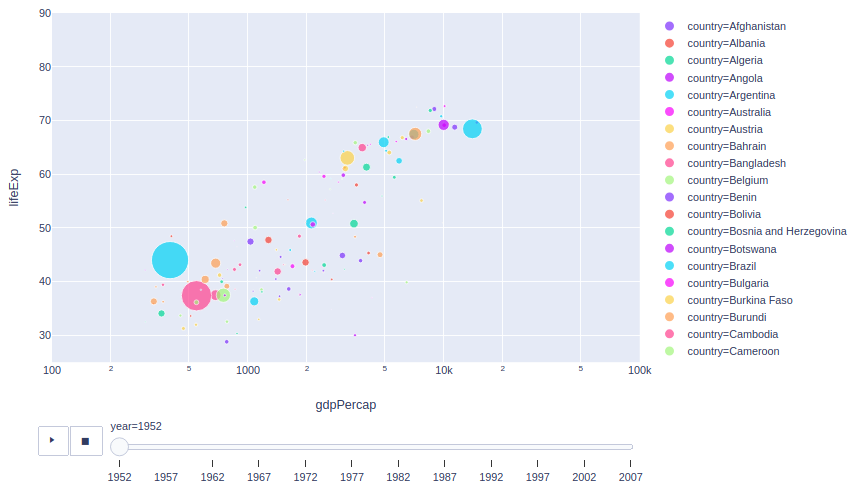
「データ取得年度」がバブル頃の1987年のグラフ。
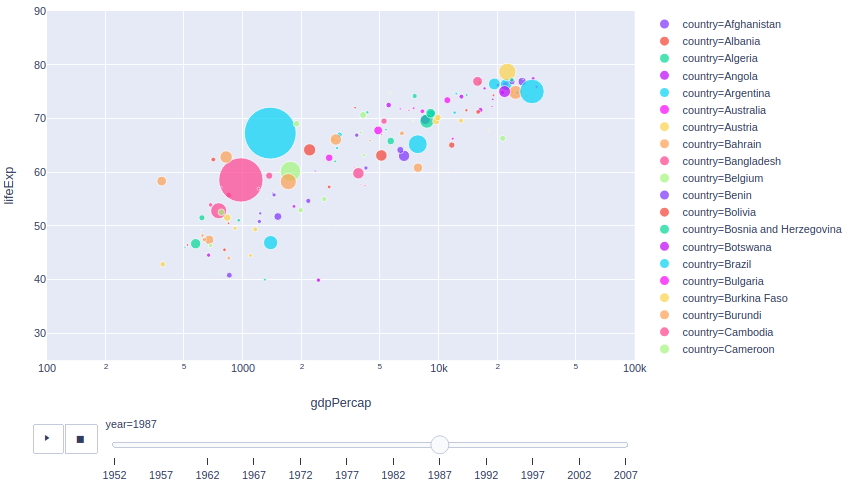
「データ取得年度」がこのデータセットでは最新の2007年のグラフ。
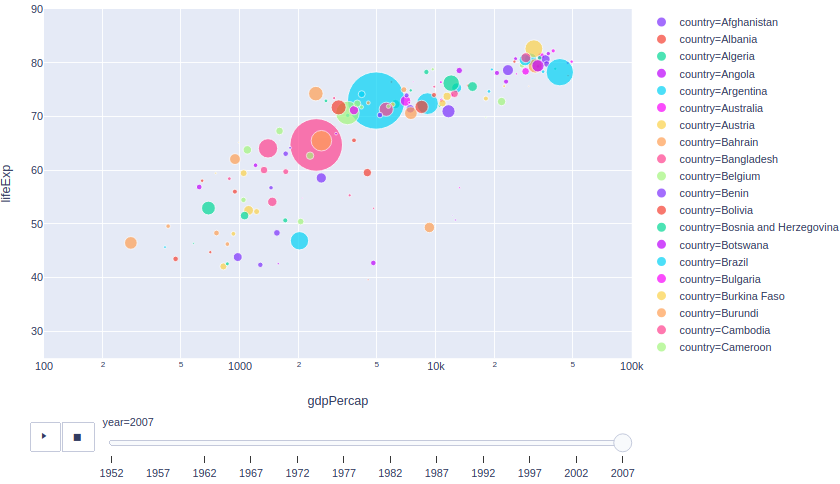
一部例外もありますが、おおよそ「人口」と「GDP per Cap(≒経済力の指標)」は比例関係にあることがわかります(例外とは、確か紛争とかだったような・・・詳しくは著書を読んでみてください)。
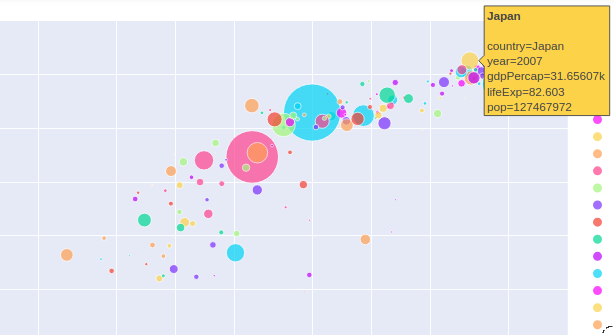
ちなみに下記のように興味のある点をポインタで指すと、その国がハイライトされたデータが表示されます。
これは便利ですね!
こう見ると、2007年の日本の経済競争力はかなり高かったんだなあ、としみじみ実感(もちろん流行りのデータ不正等がない限り)。
FACTFULLNESS(ファクトフルネス)データセットの解析
ただ、Plotly Expressパッケージに入っているデータセットは2007年までなのでやや古い印象です。
そして、Pythonで解析するより本家のHPでいじったほうが圧倒的に操作性は良かったです(-o-)。
ただ、それを言ってしまうと元も子もないので、本家のHPからデータをダウンロードして本書の有名な主張の一つ**「中国の一人っ子政策は解除されたとしても中国の人口は劇的に増加しない」**を検証してみます。
[Gapminder dataset]
(https://www.gapminder.org/data/)
上記から、「GDP/capita (US$, inflation-adjusted)」を示す「GDPpercapitaconstant2000US.xlsx」と、
「Crude birth rate (births per 1,000 population)」を示す「indicator_crude birth rate (births per 1000 population).xlsx」のデータセットをダウンロードします。
前者は国の経済力の指標、後者は出生率です。
import pandas as pd
import matplotlib.pyplot as plt
df1= pd.read_excel("indicator_crude birth rate (births per 1000 population).xlsx")
df1.head()
まずは国の経済力の指標を見てみます。
どこまであてになるかわかりませんが、216年分(...)のデータが示されています。
次に、出生率のデータを見てみます。
df2= pd.read_excel("GDPpercapitaconstant2000US.xlsx")
df2.head()
こちらはおよそ50年分のデータが示されています。
データの中身を解析してみたところ、後者のデータは2011年までだったため、とりあえず両データに共通する1960〜2011年までのデータを解析することにします。
今回の解析では、中国の対象国として、インド、日本、韓国、アメリカを含むデータに焦点を絞ります。
まず国の経済力の指標に関して。
df1_2 = df1.copy()
df1_2 = df1[df1['Crude birth rate (births per 1000 population)'].isin(['China','Japan',"South Korea","United States","India"])]
df1_3 = df1_2.copy()
### range関数でもっと簡単にかけるはずなのになぜかうまくいかないかったのでこんなコードに。。。
### 国名+1960〜2011年分の列データを抽出してるだけです。
count = [0]
for x in range(161, 213):
count.append(x)
df1_4 = df1_3.copy()
df1_4 = df1_4.iloc[:,count]
df1_4
端が切れてますが、2011年までのデータとなっています。
次に、出生率のデータに関して。
df2_2 = df2.copy()
df2_2 = df2_2[df2_2['Income per person (fixed 2000 US$)'].isin(['China','Japan',"South Korea","United States","India"])]
df2_3 = df2_2.copy()
count = [0]
for x in range(1, 53):
count.append(x)
df2_4 = df2_3.copy()
df2_4 = df2_4.iloc[:,count]
df2_4
以上で、2種類のデータ形式を揃えたので、各国の出生率と経済指標との関係性を図にプロットしてみます。
fig = plt.figure(figsize=(10,8))
# 中国
ax1 = plt.subplot2grid((2,3),(0,0))
ax1.set_title('<China>')
ax1.scatter(df2_4.iloc[0,1:], df1_4.iloc[0,1:])
ax1.set_ylabel('birth rate')
# インド
ax1 = plt.subplot2grid((2,3),(0,1))
ax1.set_title('<India>')
ax1.scatter(df2_4.iloc[1,1:], df1_4.iloc[1,1:])
# 日本
ax1 = plt.subplot2grid((2,3),(0,2))
ax1.set_title('<Japan>')
ax1.scatter(df2_4.iloc[2,1:], df1_4.iloc[2,1:])
# 韓国
ax1 = plt.subplot2grid((2,3),(1,0))
ax1.set_title('<South Korea>')
ax1.scatter(df2_4.iloc[3,1:], df1_4.iloc[3,1:])
ax1.set_xlabel('GDPpercapita')
# アメリカ
ax1 = plt.subplot2grid((2,3),(1,1))
ax1.set_title('<US>')
ax1.scatter(df2_4.iloc[4,1:], df1_4.iloc[4,1:])
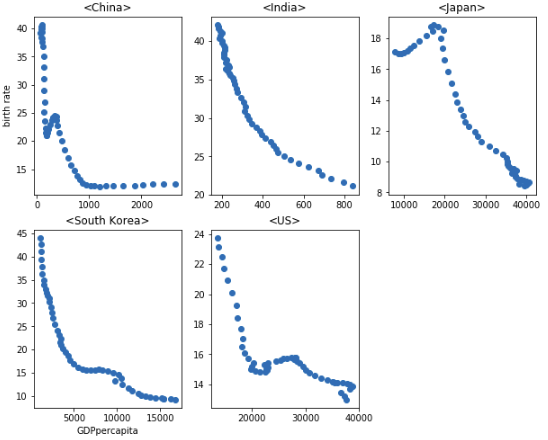
縦軸が出生率(生まれた数/人口1000人あたり)を表しており、いつもネットでよく見る指標に変換するには、これを(1/10)にすれば良いです。
例えば日本の出生率は人口100人あたりに直すと、1960年〜2011年の間では0.8〜2.0の間で推移しており、横軸のGPD per capitalが増加するにつれ、出生率の急激な減少が見られます。
FACTFULLNESS(ファクトフルネス)の著者の解析によると、GPD per capitalと出生率の関係は、程度の差こそあれどこの国も大差ないということです。それはつまり、人々が(見かけ上であっても)リッチになればなるほど、ライフスタイルの変化に伴い子供を産まなくなる可能性が高いことを示しています。
そしてこのグラフを見ると、各国の経済発展のレベルにより人口減少時期は異なっているものの、それを超えると基本的には出生率が減少していく傾向にあることがわかります。
しかしそうすると、いわゆる先進国の子育て政策というものは小手先の方法論ではもはや成り立たないということですね。。。よっぽど画期的な変化(戦争、抗生物質や新大陸の発見に相当するイベント)がない限り、傾向は変わらなそうです(可能性としては、再生医療の進化とか死に関する概念が変わったりすることくらいですかね・・・)。
中国の一人っ子政策について
さて本題(?)の中国の一人っ子政策の検証です。
Wikiによると、中国の一人っ子政策は主に1979年から2015年に実施されたようです。
[一人っ子政策-Wikipedia]
(https://ja.wikipedia.org/wiki/%E4%B8%80%E4%BA%BA%E3%81%A3%E5%AD%90%E6%94%BF%E7%AD%96)
しかし、一人っ子政策が開始された前後の中国の出生率を見てみると、確かにやや不自然な変動(戦争とかデータの取得精度の問題もあるかもしれません)はあるものの、その頃にはすでに人口減少基調に既に入っていたであろうことが予想されます。つまり、FACTFULLNESS(ファクトフルネス)の著者が言いたかったのは、中国の出生率の減少に与えた「一人っ子政策」の影響はそれほど大きくなかったであろう、ということです。
これは、インドの出生率の変化を見てもうなづける結果です。インドは別に出生を抑制する政策は取っていなかったと思いますが(取ってたらすみません)、それでもやはり出生率が低下し続けています。
そのため、「一人っ子政策」を解除しても、今後中国は大幅に人口が増加することはないでしょう(たぶん)。
中国がこれから未曾有の高齢化社会に向かうことはまあ間違いなさそうです(日本もですが)。
たぶん日本もそうですが、ある時期に、たまたまその当時インパクトのある政策が取られていた場合、実際にはその政策の影響はあまりなかったとしても、その政策が後世で「悪玉」にされる可能性があります。
そして、その「悪玉」に対する深淵な議論が長々と続くことがありますが、今回の一人っ子政策の例等を見てみると、それらの議論はデータドリブンで解析すれば本来不要だったりすることがかなりありそうですね。
自分への戒めとして覚えとこう・・・。
さておき、やはりFACTFULLNESS(ファクトフルネス)は良い本ですね(特に他意はありませんが)。
データセットも豊富ですし、社会化の授業(?)なんかに持って来いかも。
来年辺りどっかの入試で出てたりして。。。