作ったもの
SlackでWebページを渡すと要約してくれて、その後はURLを元に回答を生成してくれるアプリを作りました🤗
(難解なWebページとか読むのめんどくさい時用です)

インフラ構成
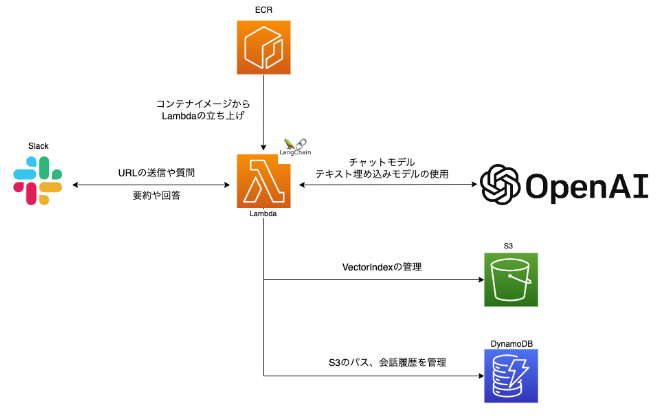
それぞれの役割

こんな感じの構成になっています。
LangChain周りのパッケージが重たすぎて、LambdaLayerのデプロイパッケージの制限(解凍後サイズ 250MB)を超えてしまうので、ECRにDockerイメージを保管しそこからLambdaを展開しています。
資料
イベント登壇時の資料です
コード
超特急で作ったので細かい所や汚いところは目を瞑ってください🥲
Dockerfile
FROM public.ecr.aws/lambda/python:3.8
# Upgrade pip
RUN python3 -m pip install --upgrade pip
COPY requirements.txt ./
RUN pip install -r requirements.txt
COPY handler.py ./
CMD ["handler.lambda_handler"]
requirements.tx
aiofiles==23.1.0
aiohttp==3.8.4
aiosignal==1.3.1
altair==5.0.0
anyio==3.6.2
async-timeout==4.0.2
attrs==23.1.0
beautifulsoup4==4.12.2
boto3==1.26.96
botocore==1.29.136
certifi==2023.5.7
cffi==1.15.1
charset-normalizer==3.1.0
click==8.1.3
contourpy==1.0.7
cryptography==40.0.2
cycler==0.11.0
dataclasses-json==0.5.7
faiss-cpu==1.7.4
fastapi==0.95.2
ffmpy==0.3.0
filelock==3.12.0
fonttools==4.39.4
frozenlist==1.3.3
fsspec==2023.5.0
geojson==2.5.0
gradio==3.23.0
greenlet==2.0.2
h11==0.14.0
httpcore==0.17.1
httpx==0.24.1
huggingface-hub==0.14.1
idna==3.4
Jinja2==3.1.2
jmespath==1.0.1
jsonschema==4.17.3
kiwisolver==1.4.4
langchain==0.0.126
linkify-it-py==2.0.2
markdown-it-py==2.2.0
MarkupSafe==2.1.2
marshmallow==3.19.0
marshmallow-enum==1.5.1
matplotlib==3.7.1
mdit-py-plugins==0.3.3
mdurl==0.1.2
multidict==6.0.4
mypy-extensions==1.0.0
numexpr==2.8.4
numpy==1.24.3
openai==0.27.2
openapi-schema-pydantic==1.2.4
orjson==3.8.12
packaging==23.1
pandas==2.0.1
pdfminer.six==20221105
pdfplumber==0.9.0
Pillow==9.5.0
pycparser==2.21
pydantic==1.10.7
pydub==0.25.1
pyowm==3.3.0
pyparsing==3.0.9
pyrsistent==0.19.3
PySocks==1.7.1
python-dateutil==2.8.2
python-multipart==0.0.6
pytz==2023.3
PyYAML==6.0
regex==2023.5.5
requests==2.30.0
s3transfer==0.6.1
semantic-version==2.10.0
six==1.16.0
sniffio==1.3.0
soupsieve==2.4.1
SQLAlchemy==1.4.48
starlette==0.27.0
tenacity==8.2.2
tiktoken==0.3.3
tokenizers==0.13.3
toolz==0.12.0
tqdm==4.65.0
transformers==4.29.2
typing-inspect==0.8.0
typing_extensions==4.5.0
tzdata==2023.3
uc-micro-py==1.0.2
urllib3==1.26.15
uvicorn==0.22.0
Wand==0.6.11
websockets==11.0.3
yarl==1.9.2
handler.py
import os
import json
import tempfile
import boto3
import openai
import langchain
import requests
import pdfplumber
import re
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.docstore.document import Document
from langchain.chains.summarize import load_summarize_chain
from langchain.prompts import PromptTemplate
from langchain.vectorstores import FAISS
from langchain.chains import ConversationalRetrievalChain
from langchain.memory.chat_message_histories import DynamoDBChatMessageHistory
from langchain.chains import LLMChain
from langchain.chains.question_answering import load_qa_chain
from langchain.chains.conversational_retrieval.prompts import CONDENSE_QUESTION_PROMPT
from urllib.parse import urljoin, urlparse
from bs4 import BeautifulSoup
from io import BytesIO
from datetime import datetime
URL_SUMMARIZER_ID = os.environ["URL_SUMMARIZER_ID"]
BUCKET_NAME = os.environ["BUCKET_NAME"]
SESSION_TABLE_NAME = os.environ["SESSION_TABLE_NAME"]
# S3の準備
s3 = boto3.resource('s3')
s3_bucket = s3.Bucket(BUCKET_NAME)
# ChatGPTの準備
openai.api_key = os.environ["OPENAI_API_KEY"]
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
embeddings = OpenAIEmbeddings()
url = ""
summarize_prompt_template = """以下の文章を簡潔に要約してください。:
{text}
要約:"""
qa_prompt_template = """
{context}
これを踏まえて、次の質問に日本語で答えてください。
質問: {question}
回答:"""
# Webページからテキストを抽出
def get_webpage_texts(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
text_list = []
main_div = soup.find('div', class_='main')
if main_div:
for string in main_div.stripped_strings:
text_list.append(string)
else:
body = soup.find('body')
if body:
for string in body.stripped_strings:
text_list.append(string)
return text_list
# PDFページからテキストを抽出
def get_pdf_text(url):
response = requests.get(url)
pdf_file = BytesIO(response.content)
text_list = []
with pdfplumber.open(pdf_file) as pdf:
for page in pdf.pages:
text_list.append(page.extract_text())
return text_list
# URLをS3フォルダ名に変更 domain-yyyymmddhhmmssの形にする
def modify_url_to_s3_path(url):
now = datetime.now()
timestamp = now.strftime("%Y%m%d%H%M%S")
parsed_url = url.split("/")
domain = parsed_url[2].replace(".", "-")
new_url = f"{domain}-{timestamp}"
return new_url
# S3にディレクトリを格納
def upload_dir_s3(dirpath, s3bucket, s3_path):
for root,dirs,files in os.walk(dirpath):
for file in files:
s3_key = os.path.join(root, file).replace(dirpath, s3_path, 1)
s3bucket.upload_file(os.path.join(root, file), s3_key)
# S3からディレクトリを取得
def download_dir_s3(dirpath, s3bucket):
for obj in s3bucket.objects.filter(Prefix = dirpath):
if not os.path.exists(os.path.join('/tmp/', os.path.dirname(obj.key))):
os.makedirs(os.path.join('/tmp/', os.path.dirname(obj.key)))
s3bucket.download_file(obj.key, os.path.join('/tmp/', obj.key))
return os.path.join('/tmp/', dirpath)
# DynamoDBへ保存処理
def write_to_dynamo(url, s3_path, summarize_result, channel_name, user_name):
dynamodb = boto3.resource('dynamodb')
table_name = os.environ["TABLE_NAME"]
table = dynamodb.Table(table_name)
now = datetime.now()
# データを書き込む
table.put_item(
Item={
'Url': url,
'AttributeType': "S3Key",
'AttributeValue': s3_path,
'ChannelName': channel_name,
'UserName': user_name,
'SummarizeResult': summarize_result,
'created_at': now.isoformat()
}
)
# DynamoDBからの取得処理
def get_from_dynamo(url):
if url == "":
return None
dynamodb = boto3.resource('dynamodb')
table_name = os.environ["TABLE_NAME"]
table = dynamodb.Table(table_name)
# データを取得する
response = table.get_item(
Key={
'Url': url,
'AttributeType': "S3Key"
}
)
# 取得した項目が存在するかを確認
if 'Item' in response:
return response['Item']
else:
return None
# DynamoDBから会話履歴処理
def get_history(session_id):
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table(SESSION_TABLE_NAME)
# データを取得する
response = table.get_item(
Key={
'SessionId': session_id
}
)
chat_history = []
# 取得した項目が存在するかを確認
if 'Item' in response and response['Item'].get("History") is not None:
# "History"の下のリストをループ処理してchat_historyを生成
human_content = ''
for history_item in response['Item']["History"]:
if history_item["type"] == "human":
human_content = history_item["data"]["content"]
elif history_item["type"] == "ai" and human_content:
ai_content = history_item["data"]["content"]
chat_history.append((human_content, ai_content))
human_content = ''
print(chat_history)
return chat_history
else:
print(chat_history)
return chat_history
# Slackへ返信する
def send_slack_message(channel, text, thread_ts):
SLACK_BOT_TOKEN = os.environ["SLACK_BOT_TOKEN"]
headers = {
"Content-Type": "application/json; charset=utf-8",
"Authorization": f"Bearer {SLACK_BOT_TOKEN}"
}
data = {
"token": SLACK_BOT_TOKEN,
"channel": channel,
"text": text,
"thread_ts": thread_ts
}
response = requests.post("https://slack.com/api/chat.postMessage", json=data, headers=headers)
return response
# VectorIndexを元にQA処理を行う
def exec_qa(item, query, thread_ts, channel, thread_head_ts):
print("DynamoDB item: " + json.dumps(item))
s3_download_path = item["AttributeValue"]
print("s3_download_path: " + s3_download_path)
# S3から保存済みのVectorIndexを取得
index_dir = download_dir_s3(s3_download_path, s3_bucket)
dbDownload = FAISS.load_local(index_dir, embeddings)
# QA処理
qa_prompt = PromptTemplate(
template=qa_prompt_template, input_variables=["context", "question"]
)
question_generator = LLMChain(llm=llm, prompt=CONDENSE_QUESTION_PROMPT)
doc_chain = load_qa_chain(llm, chain_type="stuff", prompt=qa_prompt)
# スレッドの過去発言を取得
message_history = DynamoDBChatMessageHistory(table_name=SESSION_TABLE_NAME, session_id=thread_head_ts)
chat_history = get_history(thread_head_ts)
# 無視という単語が入っていたらベクトルデータを参考にせずに質問させる
if "無視" in query:
dummy_index = download_dir_s3("dummy-empty-vectorindex", s3_bucket)
dummy_db = FAISS.load_local(dummy_index, embeddings)
qa = ConversationalRetrievalChain.from_llm(llm, dummy_db.as_retriever())
qa_result = qa({"question": query, "chat_history": []})
else:
qa = ConversationalRetrievalChain(retriever=dbDownload.as_retriever(), question_generator=question_generator, combine_docs_chain=doc_chain)
qa_result = qa({"question": query, "chat_history": chat_history})
print("qa_result: " + qa_result["answer"])
# DynamoDBにChatGPTの回答を保存
message_history.add_ai_message(qa_result["answer"])
send_slack_message(channel, qa_result["answer"], thread_ts)
# Slackのスレッドから元となる質問元となるURLを取得する
def get_thread_url(thread_ts, channel):
headers = {
'Authorization': 'Bearer ' + os.environ['SLACK_BOT_TOKEN'],
'Content-type': 'application/json; charset=utf-8'
}
# メッセージからURLを取得するために正規表現を用意
user_id_pattern = re.compile(re.escape(URL_SUMMARIZER_ID))
url_pattern = r'(https?://[^|>]+)'
next_cursor = None
while True:
params = {
'channel': channel,
'ts': thread_ts,
'cursor': next_cursor # ページネーションのためのcursorパラメータ
}
response = requests.get(
'https://slack.com/api/conversations.replies',
params=params,
headers=headers
)
response.raise_for_status() # 応答のステータスコードが200以外の場合にエラーを発生させる
data = response.json()
if not data.get('ok'):
raise RuntimeError(f"Slack API request failed: {data.get('error')}")
# 該当スレッドのメッセージ
messages = data['messages']
# メッセージを一つずつチェックしていく
for message in messages:
if re.search(user_id_pattern, message['text']) and re.search(url_pattern, message['text']):
url = re.search(url_pattern, message['text']).group(0)
print(f"Found URL: {url}")
return url
# 次のページが存在する場合、cursorを更新して再度リクエストを行う
next_cursor = data.get('response_metadata', {}).get('next_cursor')
if not next_cursor:
break
# URLが見つからなかった場合は空文字列を返却
return ""
# Slackチャンネル名を取得
def get_channel_name(channel_id):
headers = {
'Authorization': 'Bearer ' + os.environ['SLACK_BOT_TOKEN'],
'Content-type': 'application/json; charset=utf-8'
}
params = {
'channel': channel_id
}
response = requests.get(
'https://slack.com/api/conversations.info',
params=params,
headers=headers
)
response.raise_for_status() # 応答のステータスコードが200以外の場合にエラーを発生させる
data = response.json()
if data.get('ok'):
return data['channel'].get('name', 'Unknown channel')
else:
return 'Unknown channel'
# Slackユーザー名を取得
def get_user_name(user_id):
headers = {
'Authorization': 'Bearer ' + os.environ['SLACK_BOT_TOKEN'],
'Content-type': 'application/json; charset=utf-8'
}
params = {
'user': user_id
}
response = requests.get(
'https://slack.com/api/users.info',
params=params,
headers=headers
)
response.raise_for_status() # 応答のステータスコードが200以外の場合にエラーを発生させる
data = response.json()
if data.get('ok'):
user = data['user']
return user.get('real_name', user.get('name', 'Unknown user'))
else:
return 'Unknown user'
def lambda_handler(event, context):
print(f"Event: {json.dumps(event)}")
body = json.loads(event['body'])
# Slackの疎通確認用
if body['type'] == 'url_verification':
print("Slack challenge.")
return {
'statusCode': 200,
'body': body['challenge']
}
headers = event['headers']
# 処理に時間がかかりSlackに3秒以内にリクエストを返せないとリトライされる。Slackからのリトライは無視。
if 'x-slack-retry-reason' in headers or 'x-slack-retry-num' in headers:
print("Slack retry.")
return {
'statusCode': 200,
'body': "Slack retry. ok."
}
TEAM_ID = os.environ["TEAM_ID"]
API_APP_ID = os.environ["API_APP_ID"]
team_id = body['team_id']
api_app_id = body['api_app_id']
# 変なリクエストは弾く
if team_id != TEAM_ID or api_app_id != API_APP_ID:
print("Not authorized.")
print("team_id: " + team_id)
print("api_app_id: " + api_app_id)
return {
'statusCode': 400,
'body': json.dumps({
'error': {
'message': 'Invalid team ID or API app ID.',
'code': 'INVALID_REQUEST'
}
})
}
# メンション時
if body['event']['type'] == 'app_mention':
try:
# 呼び出しもとSlack情報
channel = body['event']['channel']
thread_ts = body['event']['ts']
text = body['event']['text']
channel_id = body["event"]["channel"]
user_id = body["event"]["user"]
print("text: " + text)
# Slack本文から正規表現を使ってURLを切り出し
url_pattern = r'(https?://[^|>]+)'
urls = re.findall(url_pattern, text)
if urls:
url = urls[0]
url_contain = True
print("url: " + url)
else:
url_contain = False
if url_contain:
# 対話を記憶させるためのテーブル準備 IDはSlackのスレッド頭のthread_tsにする
message_history = DynamoDBChatMessageHistory(table_name=SESSION_TABLE_NAME, session_id=thread_ts)
# 質問からメンションを削除してDynamoDBにユーザーの発言を保存
user_message = re.sub(re.escape(URL_SUMMARIZER_ID), '', text)
message_history.add_user_message(user_message)
item = get_from_dynamo(url)
if item is not None:
print("Already summarized.")
message = item["SummarizeResult"]
message_history.add_ai_message(message)
send_slack_message(channel, message, thread_ts)
else:
# 投稿にurlが含まれておりので要約を行う
print("Summarize start.")
processing_message = "データを学習して要約作成中です。"
send_slack_message(channel, processing_message, thread_ts)
# テキストを取得してtext_listに格納
text_list = []
if urlparse(url).path.endswith('.pdf'):
text_list.extend(get_pdf_text(url))
else:
text_list.extend(get_webpage_texts(url))
print("text_list: " + text_list[0])
# テキストを学習用に分割する
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_text(text_list)
docs = [Document(page_content=t) for t in texts[:3]]
# 要約処理
summarize_template = PromptTemplate(
template=summarize_prompt_template, input_variables=["text"])
chain = load_summarize_chain(llm, chain_type="map_reduce", map_prompt=summarize_template, combine_prompt=summarize_template)
summarize_result = chain.run(docs)
print("summarize_result: " + summarize_result)
# ベクトルデータ化してindexを作成する
dbCreate = FAISS.from_documents(docs, embeddings)
dbCreate.save_local("/tmp/tmp_index")
print("Vectorize done!")
# S3へアップロードする
s3_upload_path = modify_url_to_s3_path(url)
upload_dir_s3("/tmp/tmp_index", s3_bucket, s3_upload_path)
print("S3 uploaded: " + s3_upload_path)
# チャンネル名とユーザー名を取得
channel_name = get_channel_name(channel_id)
user_name = get_user_name(user_id)
# DynamoDBへアップロードする
write_to_dynamo(url, s3_upload_path, summarize_result, channel_name, user_name)
print("DynamoDB write done!")
# DynamoDBにChatGPTの回答を保存
message_history.add_ai_message(summarize_result)
send_slack_message(channel, summarize_result, thread_ts)
else:
# 投稿自体にurlが含まれていないので質問と判断
print("QA start.")
# 質問からメンションを削除する
query = re.sub(re.escape(URL_SUMMARIZER_ID), '', text)
print("query: " + query)
# 後から使うかもなので空VectorIndexでConversationalRetrievalChainを用意しておく
dummy_index = download_dir_s3("dummy-empty-vectorindex", s3_bucket)
dummy_db = FAISS.load_local(dummy_index, embeddings)
qa = ConversationalRetrievalChain.from_llm(llm, dummy_db.as_retriever())
# スレッドから対象となるURLを取得する
if 'thread_ts' in body['event']:
thread_head_ts = body['event']['thread_ts']
url = get_thread_url(thread_head_ts, channel)
print("QA url: " + url)
# 対話を記憶させるためのテーブル準備 IDはSlackのスレッド頭のthread_tsにする
message_history = DynamoDBChatMessageHistory(table_name=SESSION_TABLE_NAME, session_id=thread_head_ts)
# DynamoDBにユーザーの発言を保存
message_history.add_user_message(query)
else:
# スレッド内ではないメンション時にURLが入っていないことを想定
# DynamoDBにユーザーの発言を保存
message_history = DynamoDBChatMessageHistory(table_name=SESSION_TABLE_NAME, session_id=thread_ts)
message_history.add_user_message(query)
qa_result = qa({"question": query, "chat_history": []})
print("qa_result: " + qa_result["answer"])
# DynamoDBにChatGPTの回答を保存
message_history.add_ai_message(qa_result["answer"])
send_slack_message(channel, qa_result["answer"], thread_ts)
return
# DynamoDBから該当urlのベクトルデータが保存されているS3の情報を取得する
item = get_from_dynamo(url)
if item is not None:
# ChatGPTへQA処理
exec_qa(item, query, thread_ts, channel, thread_head_ts)
else:
# スレッド内でURL要約が行われていないのにメンションされたことを想定
print("DynamoDB item not found.")
chat_history = get_history(thread_head_ts)
qa_result = qa({"question": query, "chat_history": chat_history})
print("qa_result: " + qa_result["answer"])
send_slack_message(channel, qa_result["answer"], thread_ts)
except Exception as e:
# めんどくさいので一旦全てのエラーを拾う
print(e)
message = "予期せぬエラーが発生しました。エンジ森にお知らせください。"
send_slack_message(channel, message, thread_ts)
お世話になった参考資料
まだ記事が少ない中大変参考になりました!大感謝🤗