今日のテーマ
システムアラートが発報された時というのは、お客様への影響やシステムで何かしらの不具合が発生した時です。
もちろん、その影響度合いには大小あれど、いずれにせよアラートを受けた後運用者は、何かしらの処置を施す必要があります。
このときに大事なのが、 「焦らない・焦らせない」 気持ちだと思っています。
この記事では New Relic のアラート設定において 「焦らない・焦らせない」 ための工夫を紹介します。
前提
- アラートは Slack を経由して通知されます
- 監視対象のシステムは複数あり、それぞれ異なる保守ベンダーさんがいます
- 保守ベンダーさんは、New Relicの設定変更等は不要なので Basicユーザ です
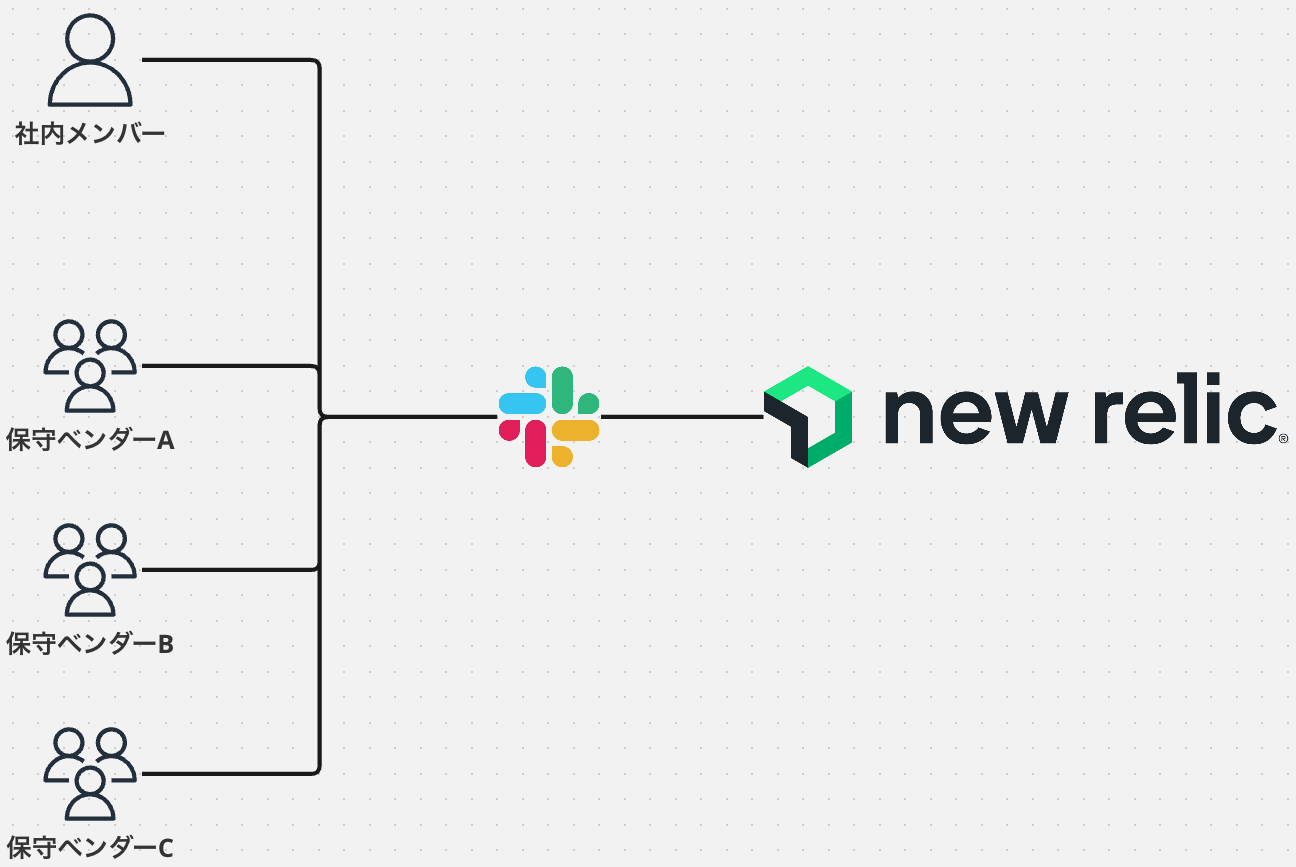
従って、Basicユーザしか見れない画面の中でどう工夫するか?も大事な要素であるという前提で読み進めてください。
「焦らない・焦らせない」とは
アラート対応時には、少なからずユーザ影響も発生している場合があることから当然「早く解消してユーザ影響をなくさねば!」という使命感に駆られます。
そうなると心拍数も上がって、普段しないようなミスが起こります。
僕はこの「心拍数が上がる」ということが「焦り」だと捉えているので、心拍数を下げる工夫をすることを念頭に置いています。
そして心拍数が上がる行動の要因として以下があると思っています。
- 画面遷移が多い
- 何をしたらいいのかわからない
- 「アラート」そのものに脅迫されているような気がする
このように、対応者自身が焦ってしまう要素と、アラート自体が対応者を焦らせる要素の2種類があるのではないかと考えています。
以下では、それぞれに対してどんな工夫をしているかご紹介します。
画面遷移が多い
よくあるフローはこんな感じかと思います。
- アラート通知を確認
- アラート自体のリンク先を確認して何が起こっているかを見る
- システム構成図等から関連するリソースを特定し、それらのメトリクスやログを確認する
- 原因が分かれば対処する
大抵の場合、「アラート自体のリンク先を確認して何が起こっているかを見る」で原因がわかることは稀です。
そもそも単一の原因で発生するようなアラートは内部の異常系処理で回避できる設計としていることが多いですよね。
結局は関連リソースの色々なメトリクスやログを画面をポチポチしながら確認していくことになります。
画面遷移、一つ一つは数秒だとしても、複数の画面を行ったり来たりするとこの待ち時間が地味にストレスです。
ストレスは焦りに繋がります。
ということで、関連するメトリクスやログデータは全て一つのダッシュボードに詰め込むことにしました。
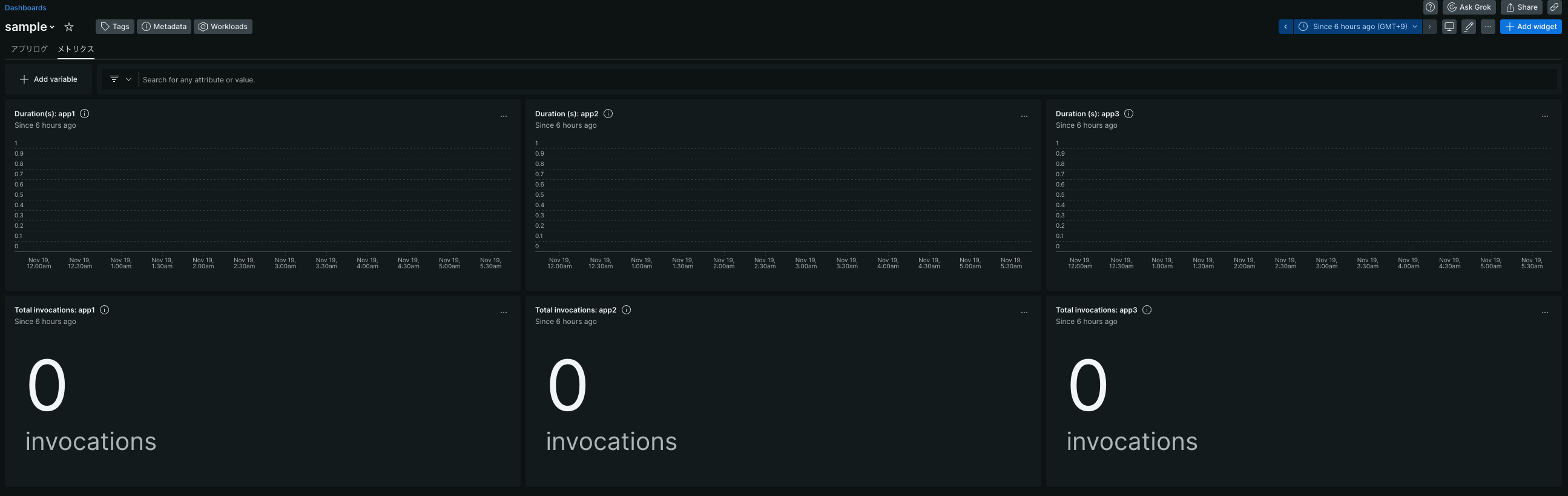
(上記は突貫で作ったものなのでメトリクスが何も取られてないですがご了承ください^^;)
ポイントは、「メトリクス」と「アプリログ」を別タブで同じダッシュボードに入れてある点です。
これは対象のシステムにもよると思うのですが、メトリクスとログに連動性がある場合には同じ画面にすべきと思いますし、そもそもタブの分け方もシステムによってそれぞれ検討の余地があると思います。
場合によっては、dev/stg/prdと環境ごとにタブを作るのも一つでしょうし、frontend/backendなどの種別によって分けるのも良いですね。
要するに、
- ダッシュボードで画面遷移の回数を1回にする(タブ間の移動はあれども)
- タブを活用して、クリック数を極力減らす
ことを意識しています。
さらに、ログの場合はEnrichdataも活用して、Slackへの通知にログを載せるようにしています。
ログは、アラート判定対象のログの前後も重要な調査ポイントなので。

何をしたらいいのかわからない
これもよくあります。
アラートが鳴ったはいいが、結局どこをどう調査すれば良いのか分からない。
そのシステムを開発した人や熟練エンジニアであれば、アラート内容からだいたいの調査ポイントの勘所は知っていると思いますが、システムのことは詳しく知らないが先にアラートに気付いてしまった人や新人エンジニアは右往左往してしまいます。
いわゆる、属人化を排除する取組にもなると思いますがこの基本は「プレイブック、ランブックを整備する」ことにあります。
New Relicにもアラートにランブックを設定できますよね。
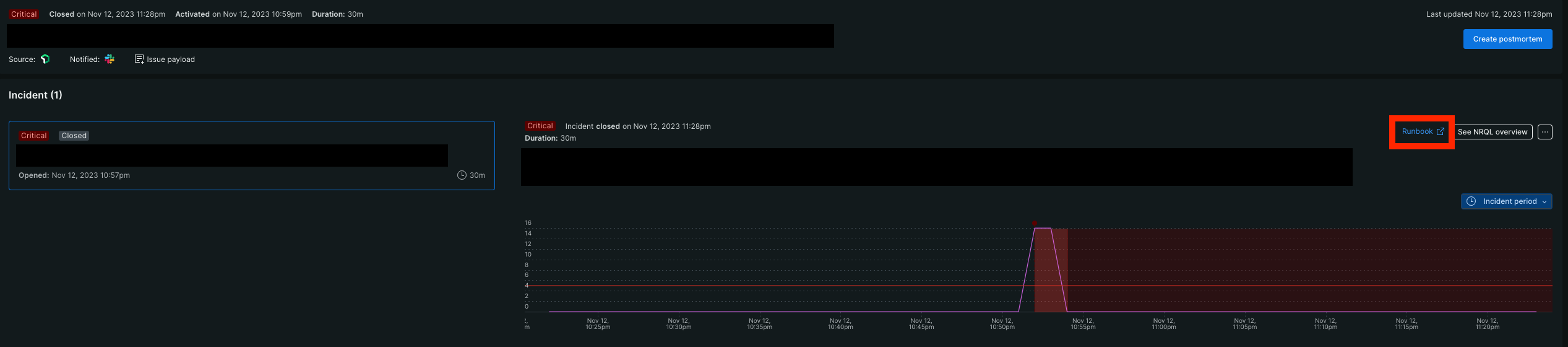
ただし、これは下記画像のように、アラートの詳細画面の隅にこっそりリンクが貼ってあるだけです。
ランブックなので、自動復旧していることが前提ということであえてこんな表記にしているとは思いますが、例えばプレイブックをここにリンクされるとかなり分かりづらいですね。
ということで、アラートの通知文にはプレイブックもしくはランブックのURLは記載するようにします。
記載が無い場合には、まだ手順が確立されていないことを表しているので、対応した際に順次作成して通知文を更新していく運用が良いと思います(はじめから100点なんて目指せないので。小さく始めて成長させることが重要)
以下は通知文のサンプルです。
◯◯システムのアプリケーションにおいてエラーが発生しました。
落ち着いて、手順に従って調査および対応を進めてください。
関連ダッシュボード: <ダッシュボードのリンク>
プレイブックURL: <プレイブックのリンク>
=====
参考情報
- 想定される影響ユーザ: ◯◯機能をご利用中のユーザ(おおよそXX名)
- 関連する外部アプリケーション: □□システム
冒頭の ◯◯システムのアプリケーション はリソースによって文言を変えています。
EC2インスタンス等特定リソースのメトリクスであれば ◯◯システムの EC2インスタンス △△ で のように具体的に書きます。
ポイントをまとめると
- アラートの通知文をフルに活用する
- ダッシュボードのURLやプレイブック・ランブックのURLなど見てほしいドキュメントのリンクはすべて貼る
- どこで何が起こっているかを具体的に記載する
「アラート」そのものに脅迫されているような気がする
既に一つ前のセクションで紹介した通知文の中に工夫が含まれているのですが、意識していることは
- 通知文は ですます調 にする
- 「落ち着いて」など、おせっかいかもしれないが焦らせないためのキーワードを入れておく
です。例えば、以下だと僕は無機質な感じがして怖くなります。アラート自体がそもそも怖いですし……
アラート発生。至急調査・復旧を実施せよ
- 対象システム/対象リソース: 〇〇システム
- 関連ダッシュボード: <ダッシュボードのリンク>
- プレイブックURL: <プレイブックのリンク>
=====
参考情報
- 影響ユーザ: 〇〇機能利用中のユーザ
- 関連外部アプリケーション: □□システム
書いている内容は全く同じなのですが、なんかすごく強迫観念に駆られます。。。
ただ、これは個人の感覚に依存する部分です。
緊急時は、端的に、本当に伝えるべき内容だけを記載したほうがいいのでむしろ「ですます調」はダメだ!という意見も理解できますので必ずしも万人受けする工夫では無いかなという感覚です。
まとめ
New Relicの便利機能の紹介!みたいなことではありませんでしたが、より泥臭い部分での工夫をご紹介しました。
Basicユーザは閲覧可能な範囲も制限されますので、運用者が本当に見たい情報は何か?何があると運用作業において嬉しいのか?を実際に会話しながら成長させていくことが大事だと思いますし、これからも継続して改善していく予定です。
やはりNRQLが強力でダッシュボードを作るのもとっても簡単!とか、Terraformでコード管理できる!とか色々と推したいTipsは多々あるのですがそれはまた別の機会に。
この工夫が誰かの役に立つことを願っています!!