tl;dr
floatやdoubleを四捨五入して整数化するケースは多々ある。C++11では、std::lroundが用意されている。でも、戻り値はlongで64bitのWindowsとlinuxではbit幅が同じでないので、どちらのOSでも32bitととなるintを返すiround関数がほしい!ということで作った!!他愛のない関数だが、自分でも毎回書くくらいならコピペできるようにpublicなサイトにあげてしまおうということが目的。一度、記事に仕立てたが、Nabetaniさんの指摘をうけて、大幅に加筆修正。Nabetaniさんに大感謝です。
本題
様々な実装で速度を計測してみた。実装としては
0)自前の実装(fast版)
1)自前の実装(高精度版)
2)std::roundベース
3)std::lroundベース
とした。
lroundを使う場合、実際にはbit幅とOSに応じてディレクティブを使って切り替えることになるが今回、64bit windowsのみ。
fast版と高精度版の違いは、浮動少数点の有効桁数をいっぱいに使っている数値の場合、fast版だと内部で0.5を足す分だけ桁あふれが発生し、std::lroundなどに対して誤差がでてしまう。
コード
# include <chrono>
# include <thread>
# include <cmath>
struct StopWatch
{
public:
StopWatch() { pre_ = std::chrono::high_resolution_clock::now(); }
///returns lap time in ms.
double lap()
{
auto tmp = std::chrono::high_resolution_clock::now(); //sotres time.
auto dur = tmp - pre_;
pre_ = tmp;
return std::chrono::duration_cast<std::chrono::nanoseconds>(dur).count() / 1000000.0;
}
private:
std::chrono::high_resolution_clock::time_point pre_;
};
//これが定義していあると、templateを使ったプログラミングに便利
template<class INTEGRAL_TYPE>
constexpr int fast_iround(INTEGRAL_TYPE v)
{
return static_cast<int>(v);
}
constexpr int fast_iround(float v)
{
if(v >= 0) {
return static_cast<int>(v + 0.5f);
} else {
return -static_cast<int>(-v + 0.5f);
}
}
constexpr int fast_iround(double v)
{
if(v >= 0) {
return static_cast<int>(v + 0.5);
} else {
return -static_cast<int>(-v + 0.5);
}
}
constexpr int fast_iround(long double v)
{
if(v >= 0) {
return static_cast<int>(v + 0.5l);
} else {
return -static_cast<int>(-v + 0.5l);
}
}
//これが定義していあると、templateを使ったプログラミングに便利
template<class INTEGRAL_TYPE>
constexpr int iround(INTEGRAL_TYPE v)
{
return static_cast<int>(v);
}
constexpr int iround(float _v)
{
double v = _v;
if(v >= 0) {
return static_cast<int>(v + 0.5);
} else {
return -static_cast<int>(-v + 0.5);
}
}
constexpr int iround(double _v)
{
long double v = _v;
if(v >= 0) {
return static_cast<int>(v + 0.5l);
} else {
return -static_cast<int>(-v + 0.5l);
}
}
//精度を維持するためにllroundを利用
inline int iround(long double v) { return static_cast<int>(std::llround(v)); }
//round関数がconstexprでないので、consteprにできない
inline int iround2(float v) { return static_cast<int>(std::round(v)); }
inline int iround2(double v) { return static_cast<int>(std::round(v)); }
inline int iround2(long double v) { return static_cast<int>(std::round(v)); }
//lround関数がconstexprでないので、consteprにできない
inline int iround3(float v) { return static_cast<int>(std::lround(v)); }
inline int iround3(double v) { return static_cast<int>(std::lround(v)); }
inline int iround3(long double v) { return static_cast<int>(std::lround(v)); }
template<class T>
void test()
{
using namespace std;
static constexpr int asize = 1024; //キャッシュに収まるサイズ
static constexpr int loop_count = asize * 1024;
using dest_t = std::array<int, asize>;
dest_t dest0;
dest_t dest1;
dest_t dest2;
dest_t dest3;
using src_t = std::array<T, asize>;
src_t src;
//実装した関数は、正負で条件分岐があるので投機的実行を抑制するために、
//正負双方で均一に乱数を作る
std::random_device seed_gen;
std::mt19937 engine(seed_gen());
std::uniform_real_distribution<T> dist(-10000.0, 10000.0);
std::generate(src.begin(), src.end(), [&] { return dist(engine); });
StopWatch sw;
sw.lap();
for(int z = 0; z < loop_count; z += 8) {
auto pd = &dest0[z % asize];
auto ps = &src[z % asize];
for(int j = 0; j < 8; j++) {
pd[j] = fast_iround(ps[j]);
}
pd += 8;
ps += 8;
}
auto e = sw.lap();
cout << "fast self implementation:" << e << " ms" << endl;
sw.lap();
for(int z = 0; z < loop_count; z += 8) {
auto pd = &dest1[z % asize];
auto ps = &src[z % asize];
for(int j = 0; j < 8; j++) {
pd[j] = iround(ps[j]);
}
pd += 8;
ps += 8;
}
e = sw.lap();
cout << "self implementation: " << e << " ms" << endl;
sw.lap();
for(int z = 0; z < loop_count; z += 8) {
auto pd = &dest2[z % asize];
auto ps = &src[z % asize];
for(int j = 0; j < 8; j++) {
pd[j] = iround2(ps[j]);
}
pd += 8;
ps += 8;
}
e = sw.lap();
cout << "round base: " << e << " ms" << endl;
sw.lap();
for(int z = 0; z < loop_count; z += 8) {
auto pd = &dest3[z % asize];
auto ps = &src[z % asize];
for(int j = 0; j < 8; j++) {
pd[j] = iround3(ps[j]);
}
pd += 8;
ps += 8;
}
e = sw.lap();
cout << "lround base: " << e << " ms" << endl;
; //最適化でdestが消えないため
cout << average(dest0) << endl;
cout << average(dest1) << endl;
cout << average(dest2) << endl;
cout << average(dest3) << endl;
}
void main()
{
cout << "float" << endl;
test<float>();
cout << endl << "double" << endl;
test<double>();
cout << endl << "long double" << endl;
test<long double>();
}
結果
SIMD化なし(コンパイラオプションで拡張命令なし)
float
fast self implementation:0.75 ms
self implementation: 0.78 ms
round base: 12.79 ms
lround base: 17.06 ms
13.61
13.61
13.61
13.61
double
fast self implementation:0.63 ms
self implementation: 0.92 ms
round base: 13.67 ms
lround base: 17.13 ms
14.74
14.74
14.74
14.74
long double
fast self implementation:0.66 ms
self implementation: 16.83 ms
round base: 13.41 ms
lround base: 16.64 ms
-274.10
-274.10
-274.10
-274.10
AVX2あり
float
fast self implementation:0.84 ms
self implementation: 1.04 ms
round base: 12.87 ms
lround base: 17.31 ms
-47.65
-47.65
-47.65
-47.65
double
fast self implementation:0.85 ms
self implementation: 0.85 ms
round base: 13.73 ms
lround base: 16.93 ms
-132.76
-132.76
-132.76
-132.76
long double
fast self implementation:0.85 ms
self implementation: 16.71 ms
round base: 13.37 ms
lround base: 16.82 ms
312.36
312.36
312.36
312.36
考察
少なくともVC16.0.4で作った64bitバイナリでは、自前で実装したケースが最速だが、速度はコンパイラオプションによる。拡張命令使用で遅くなることもある。基本的にはfast版が速いが、高精度版でもroundやlroundを使うケースと比べれば十分速い。
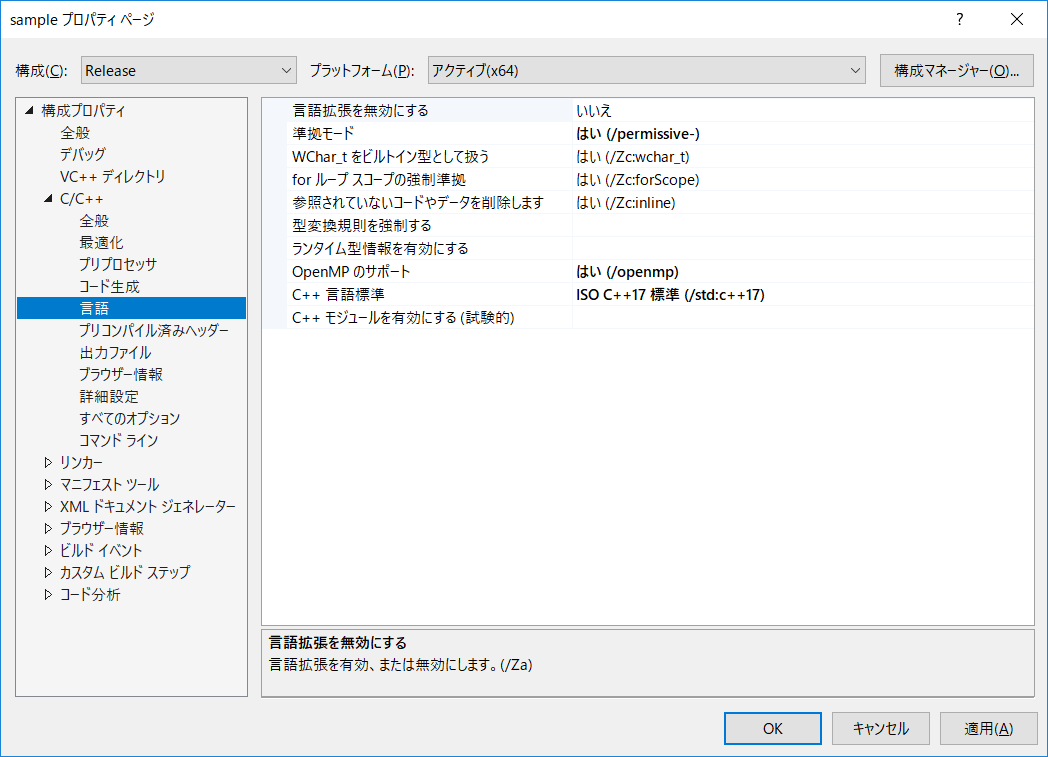
今回のコンパイラ設定に関しては巻末参照。
開発/実行環境
Visual Studio 2019 Community ver 16.0.4
Intel Core i7-8750H @2.2GHz 6CPU HTあり
Windows10 Pro 64bit
コンパイラ設定
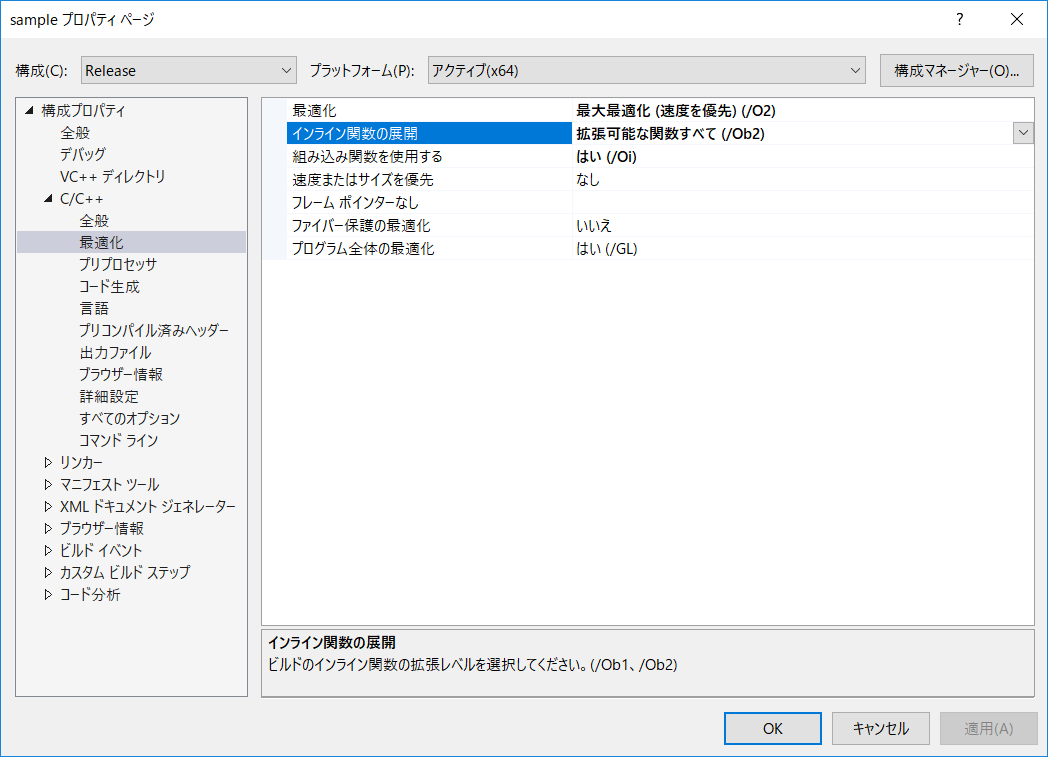
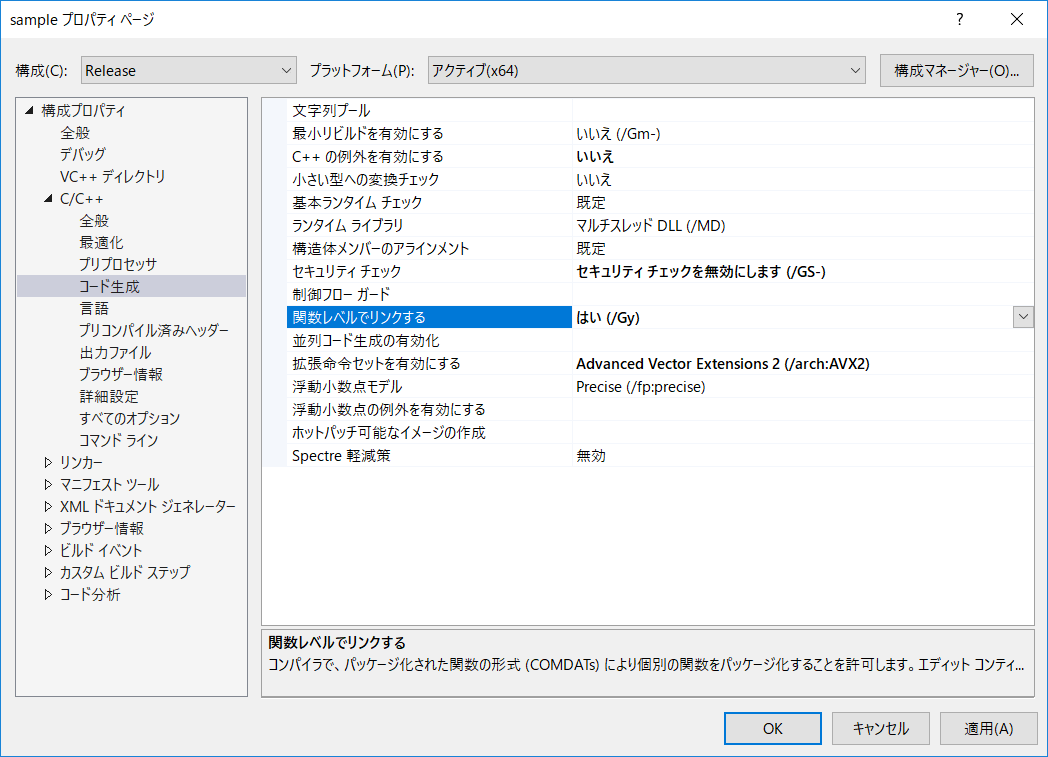
拡張命令セットは適宜変更
履歴
2019/5/5 初版
2019/5/5 iroundを自前で書いたコードを追加
2019/5/6 doubleの計算をfloatで計測していた誤りを修正、考察を微修正
2019/5/21 大幅に修正
2019/5/21 記載ミスがあり修正